深度学习在视频分析中的架构算法及应用
Posted LiveVideoStack_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习在视频分析中的架构算法及应用相关的知识,希望对你有一定的参考价值。

直播与短视频业务的兴起,代表了一种内容交互方式的变化,更加追求强交互,这种变化催化了很多技术和架构的转型,由传统的传输、存储优先演进为计算与智能。本文是由360人工智能研究院视频大数据组技术负责人陈强在LiveVideoStackCon 2017上的演讲整理而成,分享了深度学习在视频业务中的一些实践案例,并由点及面介绍了相应的实现架构、算法与应用。
演讲 / 陈强
整理 / LiveVideoStack
首先进行下自我介绍,我是360人工智能研究院的陈强,我的工作更偏向于AI方向,从趋势上来看AI的落地会跟音视频紧密结合,本次的分享将在两者的交叉点,以及基础技术、产品的应用等方面,跟大家进行交流,希望能和大家相互交流,碰撞出火花。
一、前言
今天主要分享的主题是深度学习在视频分析中的应用与基础算法,先来介绍一下为什么要做这个方向。首先从目前360的主要业务方向来说:
第一点众所周知是安全,360从08、09年就开始用机器学习、人工智能的方法去做网络安全。最近几年开始做Safety的一些问题,即将线上安全转移到线下安全。线下安全很多都涉及到摄像头,比如在摄像头(监控)中遇到的异常事件和行为:家中老人跌倒、商店里进来了陌生人或小偷,这些需要用AI的方法实时对视频内容进行分析等等。
第二点是为了360内容服务业务,包括搜索、广告等一些传统的互联网产业的产品。这两年比较火的直播业务种,比如花椒直播,也使用了很多视频分析的技术。在2017年,360的重点内容方向也转为了短视频产品——从生产到分发的整个产业链的内容。这其中也涉及到了很多音视频的内容分析。做短视频的分析,实际上是要知道该视频本身在讲什么事情——一个社会类新闻或者场景化的直播类小视频,需要可以推荐给合适的人。这也是AI在音视频在内容分析的应用场景。
目前360人工智能研究院基于这两个方面跟各个业务线的合作非常紧密,研究院更多承担是技术上的支持。而我所在的是360人工智能研究院下面的视频大数据组,主要负责两块内容:
一是结合IOT和短视频等业务线场景做视频内容的分析,将场景分析、人脸人形检测等技术结合实际的业务场景来解决产品需求。
二是大数据技术,我们主要是利用深度学习技术来结合业务部门的实际数据进行有效建模和优化,以提升业务指标为目的。过去两年,主要精力放在了搜索的排序、广告的CTR预估,而现在更多是在做短视频的推荐等关键技术问题上。
今天的分享主要围绕视频分析来展开。我们视频分析以及大数据系统整个技术栈都依赖于深度学习这种比较新的方法,这样不会有太多的历史包袱。而过去两年中,我们花了很大精力在公司做了一个跨部门、跨平台的深度学习平台,包括从文本分析、到音频分析、到视频分析将之合并为360NET。另外我们在公司层面做了大规模的GPU集群,以及和公司的系统部合作开发了一个系统调度平台。
二、视频分析
视频内容分析是要对视频内容有一个比较完整的理解,它是通过摄像头或者通过视频,要站在机器的角度去看而不是以人的身份区理解和分析视频内容。我们主要的业务落地场景可大致区分为云端和移动端两种模式。云端对计算的复杂度要求相对没有那么严苛,更多的是系统latency问题。而移动端的任务往往技术难度更大。因为在移动端我们面临着有限的计算资源,对算法和系统结构提出的要求会更严苛。从数据角度来首,我们会根据数据将业务场景拆分成几个核心的技术问题:检测、识别、分割以及跟踪,针对这些问题以持续去做优化。
1.核心问题
因为今天很多朋友来自于音视频编码及传输领域,我先简单介绍一些基本概念。我们经常所说的识别问题:也就是对整个视频或者整个图像做一个抽象化的描述,它可以是物体级别、的也可以是一个场景级别的、甚至可以抽象为一个style。识别是告诉我们视频中大致的主体内容,如果想要知道视频中更细节的内容,比如商标或者里面人物,那么就必须要落到检测去定位物体在视频中的位置。再进一步,如果能够做到分割(语义级别的分割),就可以知道视频中每个pixel都会发生什么事情,这样想象空间就会特别大。而往往越是细致的信息的更有价值和具有想象空间:比如要在视频中插播广告,就可以通过分割来找到合适的位置插入相匹配的广告内容。

上图显示的是移动端实时的数据处理,我们需要实时知道路上发生了什么事情,包括车道线、前面的行人、车流量、路牌等等,这是一个综合检测和跟踪技术的实践。
2.算法基础
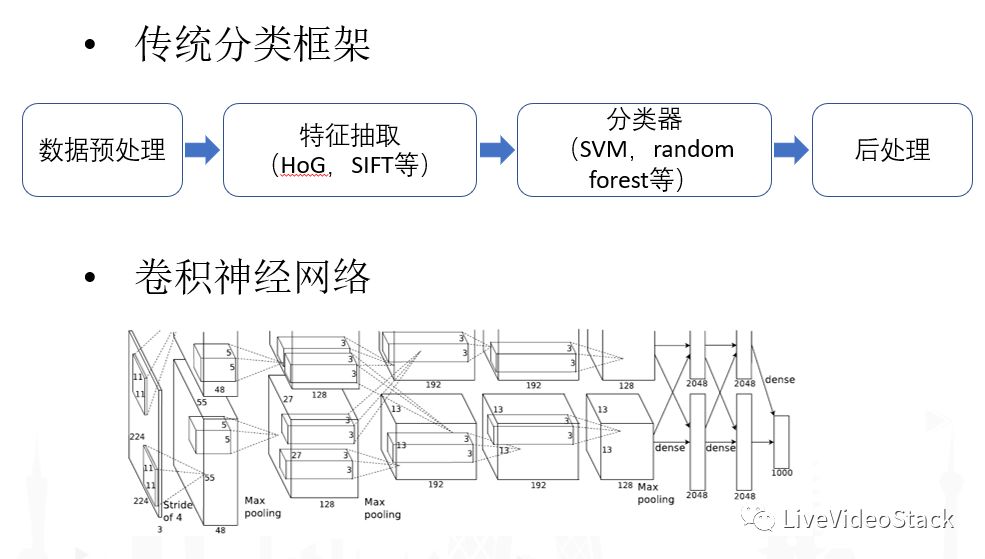
接下来介绍算法基础,首先要谈到传统算法和深度学习算法的区别。传统算法中,音视频处理中我们经常在开始时会有很多数据预处理,比如图像裁减、音视频平衡化等等,按照传统分类框架会提取各种特征:点特征、边缘特征、轮廓特征等等,音频中会有频谱特征以及一些实际特征。特征提取完成之后,需要串联一个比较强的分类器(SVM、random forest等)以及各种算法,针对各种问题再加入一些后处理,来进行分类识别。
现在比较常见的方式是直接用端到端(数据到目标)的卷积神经网络,完整替代前面说的四个步骤。对于数据端而言,所需要的数据最好不是人抽象化的数据,而是原始数据:例如对于视频来说就是RGB的值,对于AlphaGo围棋来说则是每次落子的位置,而不再需要抽象化的盘面特征预估。对于学习的目标端,需要能够把各种损失函数和优化目标定义清楚。给定了数据和优化目标,深度学习的过程就是一个自我迭代,逐步优化收敛的过程。
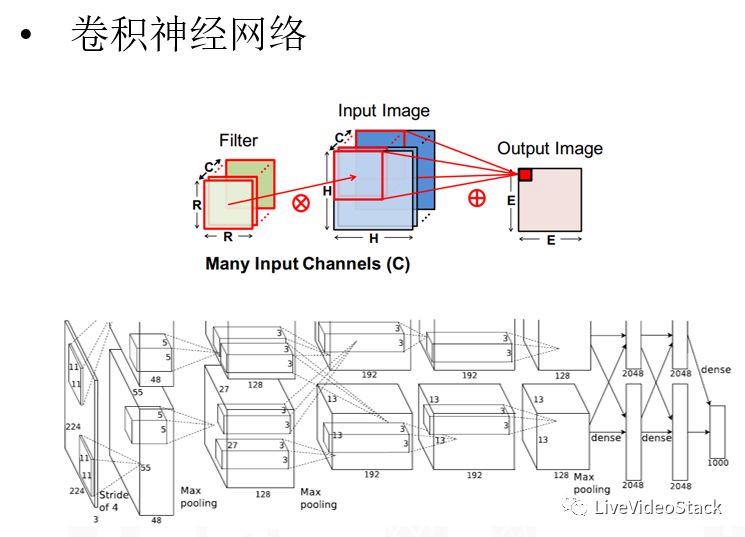
以CNN为例子,CNN从直觉上来说它就是一个Filter,比如对一个K×K或者R×R这样一个小的二维片面,用filter对新来的图片进行整体的卷积,卷积完成后输出Output Image,所以从前端的Filter到中间的输入数据,产生一个新的Channel。最近流行的卷积神经网络,和90年代的CNN还是有比较大的区别:现在我们不单单只有一个Filter,可能是M个Filter(M会很大),这样最后输出的Channel数也会很多,同样是M的级别。另外一个比较大的特点就是中间会加入各种非线性层,最经典的来说会加各种pooling层,在时序上或者空间上对它进行各种抽样化的概念;另外会使用各种非线性转移化的方程,比如最经典的sigmoid方程,现在比较流行的ReLU以及各种演化版本。目前的CNN模型往往是将多层卷积进行多层串并联以获得最大的拟合能力。
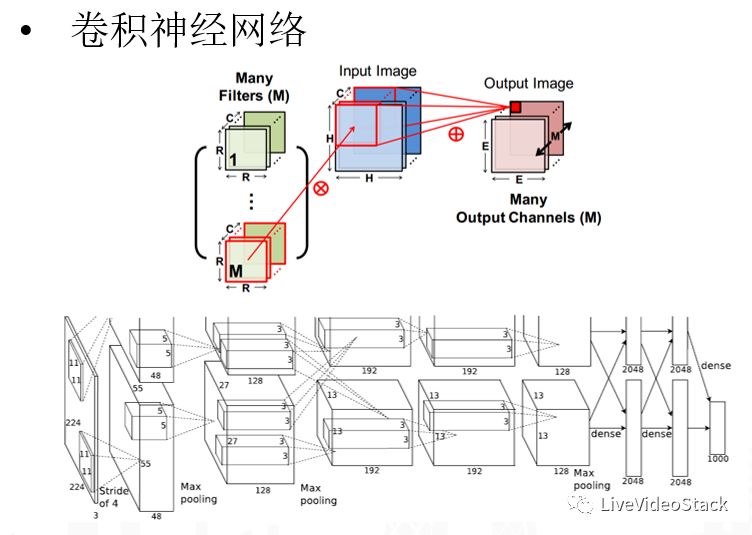
总结来说,卷积神经网络相比传统机器学习网络不同的特点:首先它是一个深层非线性系统的一个叠加,传统方法会更浅、拟合性能也更差,而卷积神经网络提供了一种方式——能够用理论性比较强、较稳定的方式训练出非线性系统;第二个好处在于它是一个端到端的系统,不需要再人为去设计各种特征,可以将精力都放在数据和模型两个层面。由此也带来第三个好处——低层次和高层次的特征级别,比如从视觉角度来说,将十层CNN拿出来具像化地去看,可以很明显看到,它第一层其实是low lever的特征,比如点、线等小局部的特征,而高层则会显现出一些结构化的特征,比如眼睛的样子、圆形、方形的概念,同样的在音频中也是如此。
3.算法框架
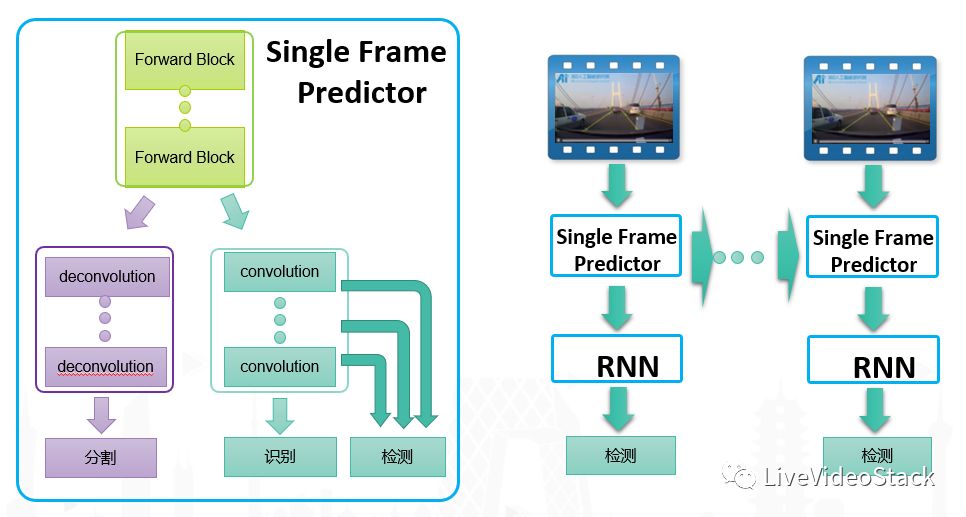
接下来介绍一下我们如何利用cnn进行视频分析:我们是把各种任务在inference层次做了参数共享和并对多任务进行了multi task learning。见上图, Forward Block是CNN的基本Blok,针对分割问题需要做Deconvolution的操作;对于识别问题,会在大的CNN架构上加一些Local CNN structure去做识别问题;而检测问题其实是识别问题在图像层面做进行遍历滑动;对应到视频分析,还需要进行物体跟踪。我们做了一个比较通用的模型,每一帧都有一些信息产生,我们将它们串联在一起,这里使用的是现在比较流行的RNN算法去做时序之间的拟合,最后总的输出就能够达到最后需要的全场景化的识别框架。
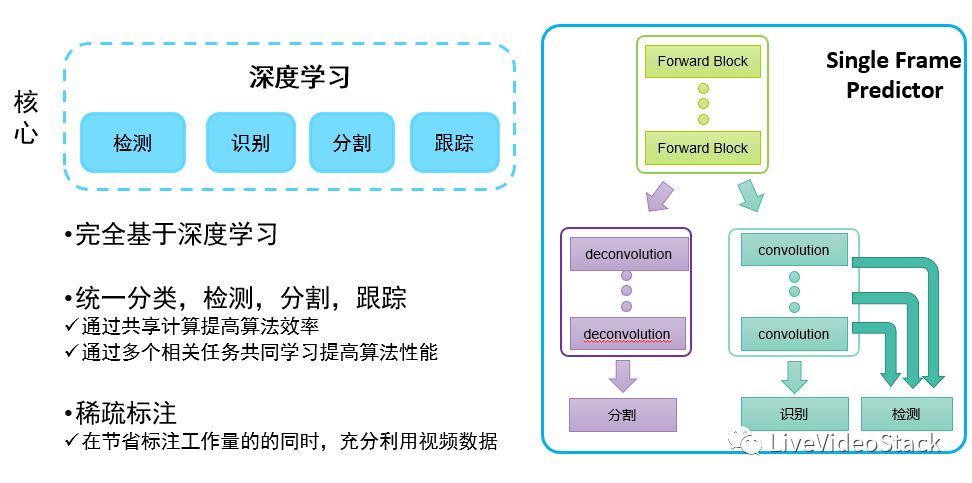
这样能带来几个好处:首先它的结构特别清晰,不是针对各个业务层来做的,更多是把它抽象成为几个核心的技术模块,这样就能极大效果的按照各种计算调优的方式来解决问题;第二点从实际经验来说,因为很多参数本身就是共享的,而所有视频进来都能够一次forward得到所有的结果,因此通过共享计算能够提高算法效率,并且通过多个相关任务共同学习来提高算法性能;最后对于视频分析来说比较大的一个问题是标注,视频级别的分析所需要数据的标注量很大,统一框架之后只需要做关键帧的标注就可以,因为在训练的过程中就会把数据前后帧串联起来。
4.三个核心维度——小、快、准
上面提到的框架可能大家都会在做,我这里特别提下人工智能研发的三个核心维度,这些问题可能更多是针对业务性的:首先是在移动端如何把模型变小,前两年用的比较多的方法是用低秩直接分解,而近两年一些新的网络架构本身效率各方面提升了很多;第二点是线上速度要快,毕竟对于直播来说,如果反映效果超过一分钟,可能监管层面就会有问题;第三个是核心指标问题,也就是inference效果必须要准,预测层肯定是从数据和模型两方面来去做优化,数据层面我们会更多希望业务部门来共享数据,而我们则侧重于模型的调优。总体而言,从目前AI核心研发纬度上来看,我们还是相信深度学习已经逐步取代各种传统方法。
5.深度学习原创的贡献
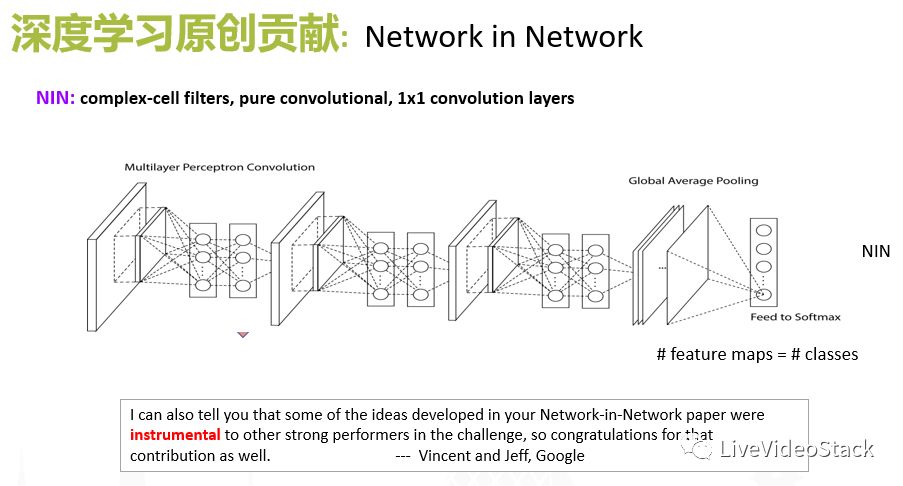
针对前面提到的问题,我们从13年开始做视频分析到现在也有一些比较原创的积累:首先是我们提出的NIN的structure,之前介绍经典的CNN的structure,它是输入层-卷积层-输出层-输入层……这样一个Building block,每层之间只有一层非线性层,在NIN中,我们将中间的每个卷积层都看作一个小的网络,也就是卷积操作不再是一个单层的卷积操作,将其定义成小的一个NewWork,在此过程中,它局部拟合的能力就大为增强了。在具体实现来说,我们可以把卷积操作并联到N个1×1的卷积,来合成比较大的一个小的NetWork。
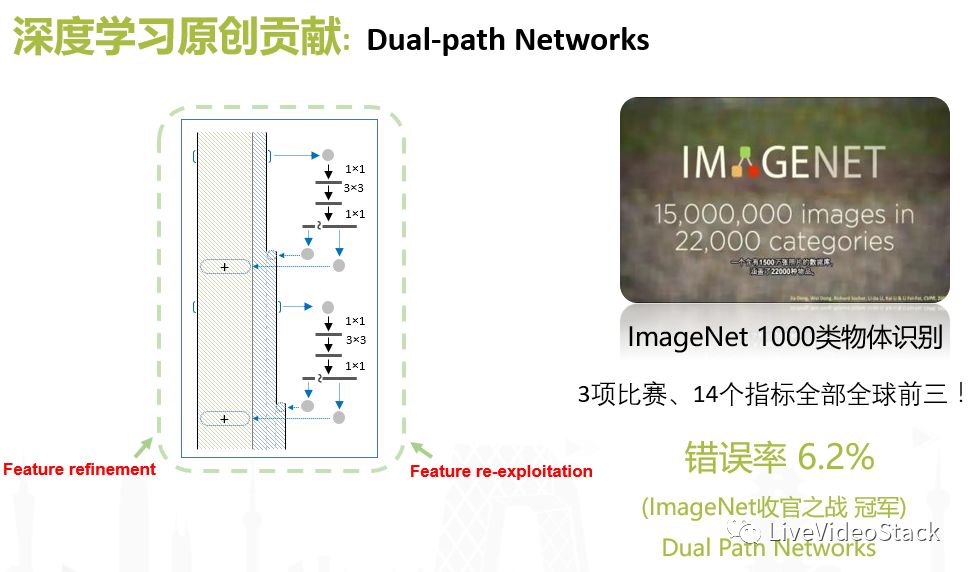
在2016-2017,我们提出了Dual-path NetWork,这是建立在此前其他研究的基础上,把ResNeXt Network和Dense Network两条Path合并在一起。在实验和理论分析上,我们发现Res Network特别容易凝聚到具体概念上,缺少较好的泛化能力,因此我们在上下层之间引入了DenseNet,使得模型对特征的利用更加充分,我们把这个structure叫做双通路的神经网络,并利用他参加了今年的ImageNet定位竞赛。最后的定位检测任务错误率是6.2%,也就是一个图片中可能存在有一千种物体,对其中任意三个或者五个进行判断错误可能是6.2%,而头部指标会更低。
三、业务结合
1.人工智能与短视频业务
介绍完技术层面的实现,我们接下来一同看下实际业务的结合,360一直在布局短视频业务,大体分为几个层次:首先是短视频生产,我们需要提供比较便利的工具给UGC、PGC的生产者,这里会有一个快卷积的工具性产品,包括移动端和Web端。
生产完成后,从消费者角度来说需要各种分层性的问题,这时我们做了花椒相机增强现实类,提供美容、美颜、抠图等等功能,目前我们的重点更多慢慢转移到视频理解方面,这也是差异化的地方,理解层会细分为几个问题:人的识别、场景识别,包括对视频内容做标签化。到具体应用场景还会再做细分,比如针对分发任务来说,我们一个移动端APP快视频,并不需要做很直接、很明确的语义理解,它更多的是需要知道用户共性的问题,而用户共性来自于视频共性,因此所要做的就是把视频共性体现出来即可,那么我们的侧重点就不在于各种语义化标签,而是把共性问题体现出来。再往下比如短视频的理解上升到如何去做商业化的问题。
2.视觉相关研发
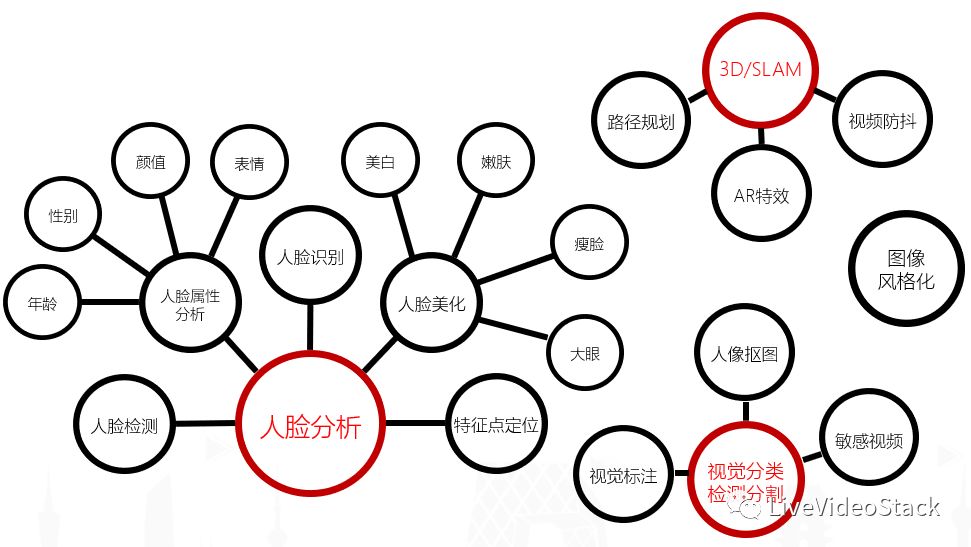
上图是视觉相关研发的总览,从我们内部来说现在分为几个大的业务块:首先是人脸分析,它也是在直播和短视频应用中最广泛的,因为人永远是视频和直播的一个主题,因此我们做了比较细致的人物属性分析比如性别、年龄、颜值、表情等,另外也在有美化或增强这些问题上进行核心攻坚。
另一部分是视频内容分析,即上面提到的检测、分割,而我们认为最重要的一部分内容是抠图,因为它提供了一个虚拟化的场景,可以把人和背景分割出来,给产品够提供很多想象的空间,而且这也是AR主打的概念——来源于生活,但比现实更丰满。此外我们也做了一些3D和SLAM相关的内容,这里就不做重点介绍。
图像识别

接下来我们结合例子来讲技术算法具体实现,这张图来自于ImageNet,它是一个标准的数据集——有一千多个类别、每个类别有一千到十万不同级别的视频图像数量,我们的目标是给定任何一张图都能够把它的标签找出来,知道图片里的内容是是什么,这就是一个标准数据集的问题。我们通过原图提取前面提到的卷积特征做预测,具体到业务场景来说,可能需要判断里面是否是一个黄色网站或是黄色图片,那么可以标注一堆图然后给出反例,通过制作和管理资源模型最后得到这样的效果。
但这样的方式带到视频分析中并不是特别合适,这里有一个比较明显的问题:因为前面提到的数据集其实是已经花费很大力气整理出来的,但在现实中业务数据很难对外公开,也没法找很多人来进行标注,尤其视频内容是非常难标注的。
视频分析——Tags
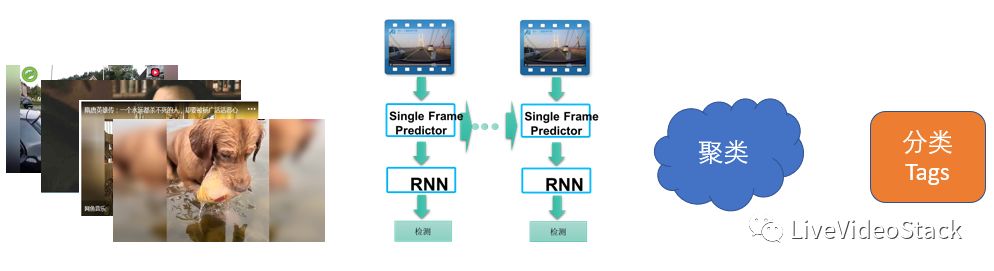
针对上面提出的问题,我们首先想到的方式是如何能够加快视频标注,当给定一组视频到通过模型最后产生数据,我们所需要的不是最后产出层的内容,而是用中间层的特征来做聚类模型,通过聚类出来的效果就可以看到共性,这样通过几十万级别的聚类效果去做各种标注,再对标注的数据做分类tag,这样就解决了两个问题:一是缺乏标注数据,二是没有良好的标注体系。目前我们已经用到短视频分发平台上,对推进指标提升的效果还是挺明显的。
人脸分析
我们在花椒直播做了人脸检测,首先是人脸上67个关键点的检测,这里比较难的是无法对主播进行控制,因为他会有各种姿态、遮挡、表情,并且主播来源也不同,那么在这个过程中要鲁棒的时刻跟踪到这67个点是很难的,我们当时更多是局部采样、局部增强。而有了这67个点就可以衍生出很多好玩的功能,比如换脸,而最常用的就是人脸识别。
短视频风格化

此外我们还在做短视频的风格化,比如给定一个真实的场景——可能是图片、也可能是视频,通过选定一些Style把两者结合变成虚拟化的、增强化的图像或视频,相比于每一种风格都要重新渲一个模型来说,它在产品化上的体验就比较差,因为每一个模型或模板都需要两三兆,而我们在后台只需要一个模型,通过给定不同参数来变化风格,而参数可能只有几百K,这里需要把用户自定义的风格图片上传到云端,通过云端训练完成后下载到手机本地做inference,整个过程从用户体验上来说是一个会是一个很实时,很顺畅的感觉。
以上是我今天的分享,大概从360的业务场景介绍了一些基础的视频分析算法和应用。希望后面能跟大家进行更深入的交流,谢谢。
WebRTCon 2018 8折报名
WebRTCon希望与行业专家一同分享、探讨当下技术热点、行业最佳应用实践。如果你拥有音视频领域独当一面的能力,欢迎申请成为讲师,分享你的实践和洞察,请联系 speaker@livevideostack.com。
点击阅读原文了解大会详情。

以上是关于深度学习在视频分析中的架构算法及应用的主要内容,如果未能解决你的问题,请参考以下文章