❥关于C++之ASCII/Unicode/ISO10646及wchar_t/char16_t/char32_t
Posted itzyjr
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了❥关于C++之ASCII/Unicode/ISO10646及wchar_t/char16_t/char32_t相关的知识,希望对你有一定的参考价值。
ASCII、Unicode、ISO 10646
Unicode提供了一种表示各种字符集的解决方案——为大量字符和符号提供标准数值编码,并根据类型将它们分组。
例如,ASCII码为Unicode的子集,因此在这两种系统中,美国的拉丁字符(如A和Z)的表示相同。然而,Unicode还包含其他拉丁字符,如欧洲语言使用的拉丁字符、来自其他语言(如希腊语、西里尔语、希伯来语、切罗基语、阿拉伯语、泰语和孟加拉语)中的字符以及象形文字(如中国和日本的文字)。到目前为止,Unicode可以表示109000多种符号和90多个手写符号(script),它还在不断发展中。
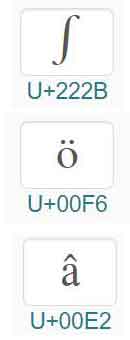
Unicode给每个字符指定一个编号—码点。Unicode码点通常类似于下面这样:U+222B。其中U表示这是一个Unicode字符,而222B是该字符(积分正弦符号∫)的十六进制编号。
通用多八位编码字符集(Universal Multiple-Octet Coded Character Set)也叫通用字符集(Universal Character Set, UCS),是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。
国际标准化组织(ISO)建立了一个工作组,专门开发ISO 10646——这也是一个对多种语言文本进行编码的标准。
通用多八位编码字符集包括了其他所有字符集。它保证了与其他字符集的双向兼容,即,如果你将任何文本字符串翻译到UCS格式,然后再翻译回原编码,你不会丢失任何信息。
ISO 10646小组和Unicode小组从1991年开始合作,以确保ISO 10640与Unicode的标准同步。
对于ISO 10646这种通用字符名用法类似于转义序列。\\u后面是8个十六进制位,\\U后面则是16个十六进制位。这些位表示的是字符的ISO 10646码点。
ö的ISO 10646码点为00F6;
â的ISO 10646码点为00E2。
可以在52 Unicode网上通过码点查找字符:
int k\\u00F6rper;
cout << "Let them eat g\\u00E2teau.";
变量名为:körper(德语:身体的意思)
打印输出为:Let them eat gâteau.(gâteau是法语:蛋糕的意思)
请注意:C++使用术语“通用编码名”,而不是“通用编码”,这是因为应将\\u00F6解释为“Unicode码点为U+00F6的字符”。支持Unicode的编译器知道,这表示字符ö,但无需使用内部编码00F6。无论计算机使用是ASCII还是其他编码系统,都可在内部表示字符T;同样,在不同的系统中,将使用不同的编码来表示字符ö。在源代码中,可使用适用于所有系统的通用编码名,而编译器将根据当前系统使用合适的内部编码来表示它。
wchar_t、char16_t、char32_t
8位char可以表示基本字符集,另一种类型wchar_t(宽字符类型)可以表示扩展字符集。wchar_t类型是一种整数类型,它有足够的空间,可以表示系统使用的最大扩展字符集。对底层类型的选择取决于实现,因此在一个系统中,它可能是unsigned short,而在另一个系统中,则可能是int。
cin和cout将输入和输出看作是char流,因此不适于用来处理wchar_t类型。iostream头文件的最新版本提供了作用相似的工具——wcin和wcout,可用于处理wchar_t流。另外,可以通过加上前缀L来指示宽字符常量和宽字符串。
下面的代码将字母P的wchar_t版本存储到变量bob中,并显示单词tall的wchar_t版本:
wchar_t bob = L'P';
wcout << L"tall";
如果在支持两字节wchar_t的系统中,上述代码将把每个字符存储在一个两个字节的内存单元中。宽字符类型使用的很少,但应知道有这种类型,尤其是在进行国际编程或使用Unicode或ISO 10646时。
随着编程人员日益熟悉Unicode,类型wchar_t显然不再能够满足需求。事实上,在计算机系统上进行字符和字符串编码时,仅使用Unicode码点并不够。具体地说,进行字符串编码时,如果有特定长度和符号特征的类型,将很有帮助,而类型wchar_t的长度和符号特征随实现而已。因此,C++11新增了类型char16_t和char32_t,其中前者是无符号的,长16位,而后者也是无符号的,但长32位。C++11使用前缀u表示char16_t字符常量和字符串常量,如u‘C’和u“be good”;并使用前缀U表示char32_t常量,如U‘R’和U“dirty rat”。类型char16_t与\\u00F6形式的通用字符名匹配,而类型char32_t与\\U0000222B形式的通用字符名匹配。
前缀u和U分别指出字符字面值的类型为char16_t和char32_t:
char16_t ch1 = u'q';// 字符q的16-bit形式
char32_t ch2 = U'\\U0000222B';// 通用字符名的32-bit形式
与wchar_t一样,char16_t和char32_t也都有底层类型——一种内置的整型,但底层类型可能随系统而已。
以上是关于❥关于C++之ASCII/Unicode/ISO10646及wchar_t/char16_t/char32_t的主要内容,如果未能解决你的问题,请参考以下文章