paddleocr训练自己的数据最简单方式软件一键训练
Posted FL1623863129
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了paddleocr训练自己的数据最简单方式软件一键训练相关的知识,希望对你有一定的参考价值。
paddleocr训练一般需要训练自己的文本检测模型或者文本识别模型,对于刚入门编程小白或者对paddleocr还不太熟悉的同学们很难短时间上手,也不知道怎么去配置让自己的数据集训练起来。为了解决paddleocr训练难的问题,FIRC最近开发了2个软件,可以轻松完成自己模型训练任务,支持文本检测或者文本识别模型.为了方便维护,软件分为文本检测版本和文本识别版本。文本检测版本截图如下:
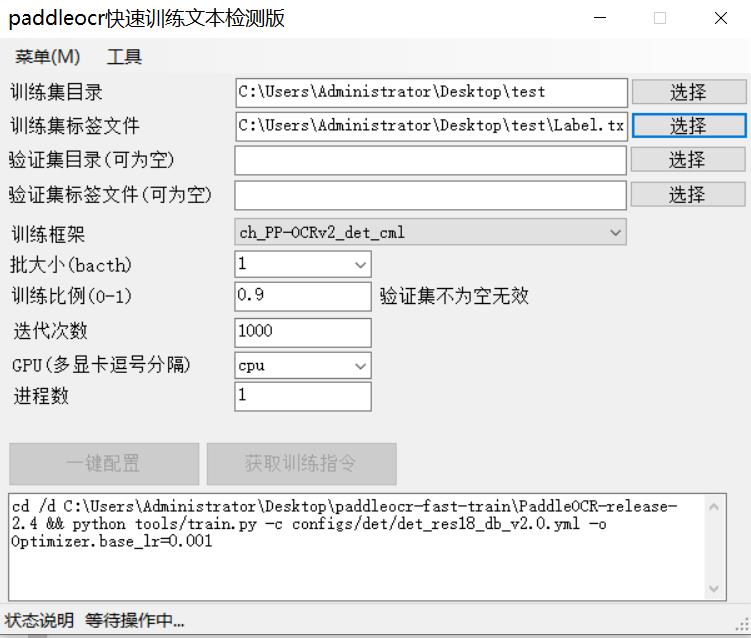
文本检测版本软件使用流程非常简单,只要你有数据集,也不用特意分割数据集。因为软件会自动分割数据集,如果自己想分割数据集也可以支持导入。那么你只需要在界面点点改改即可完成数据集配置参数自动配置,而你只需要粘贴到自己paddleocr的python环境即可开始训练。使用步骤如下:
(1)使用PPOCRLabel标注自己的数据集并且导出自己文本检测用的数据集。也可以自己编写脚本转换成paddleocr支持的数据集格式,paddleocr支持的文本检测数据集格式如下:
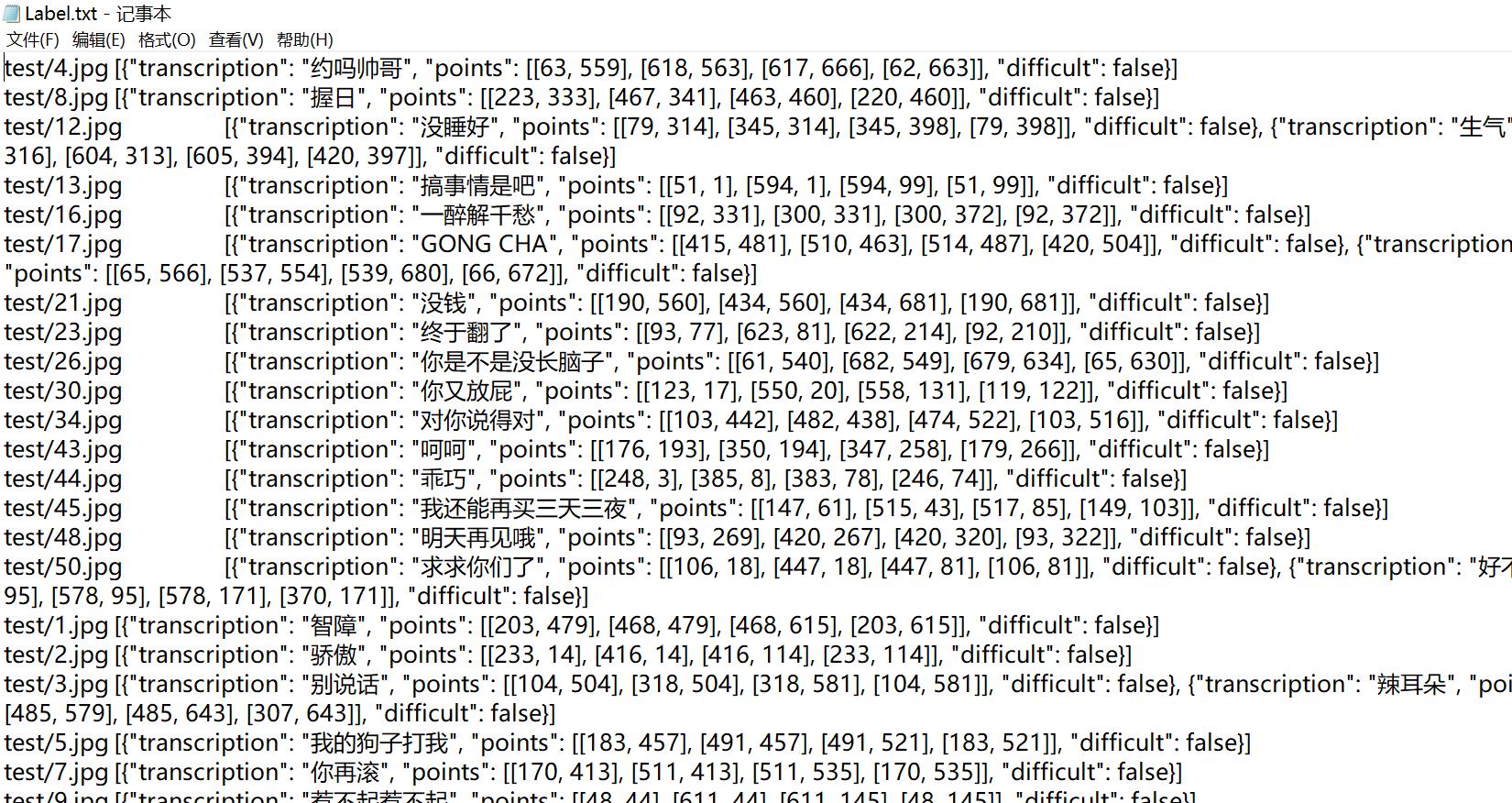
可以看出数据集格式为:
图片路径[TAB占位符]json格式数据集,json数据集格式具体看上图就知道了
(2)打开文本检测版本的软件后,将数据集图片路径和数据集txt标签分别导入训练集目录和训练集标签文件,然后保持验证集目录和验证集标签文件为空就行了,这时候软件会自动分割数据集为9:1,如果大家不想按照这个比例,则可以设置训练比例为自己想要的即可。注意必须是0到1之间,不能设置为0或者1.如果您想使用自己的验证集,则可以导入证集目录和验证集标签文件,这是训练比例设置就会失效。软件自动按照你的验证集和训练集进行配置。
(3)为了方便训练软件默认设置batchsize为1,大家训练起来后通过nvidia-smi查看自己显存占用如果小了可以调节大点。为了方便调节,软件不需要反复配置数据集,只需要通过按钮获取训练命令便可以快速配置文件且生成新的训练命令。
注意:使用软件前需要自己安装好自己的paddleocr环境,目前软件是在paddleocr2.4版本上进行开发,后续会同步开发,所以大家安装环境要对应为paddleocr2.4环境即可。软件只是提供方便训练,并不具有测试和转换功能,如果大家对于训练的模型要测试需要使用官方提供相关命令测试即可。
软件优点如下:
(1)不需要人工写代码转换数据集,不需要写代码和手动配置就可以快速训练自己的数据集
(2)支持智能分割数据集,软件会自动打乱数据集,这样保证均匀分布数据集去分割数据集
(3)软件支持标注自动检查,我们只需要在工具-检查数据集格式即可检查数据集格式是不是有问题
(4)软件支持自动记忆界面配置参数,即使再次打开软件依然可以获取到现在训练命令
(5)软件支持快速切换文本检测框架。软件可以在简单切换框架后,点击获取命令即可快速训练,非常更换模型结构训练自己的模型
更多更详细的信息可以参考官方提供的视频教程:paddleocr快速训练助手文本检测版使用教程_哔哩哔哩_bilibili
文本识别版本截图如下:
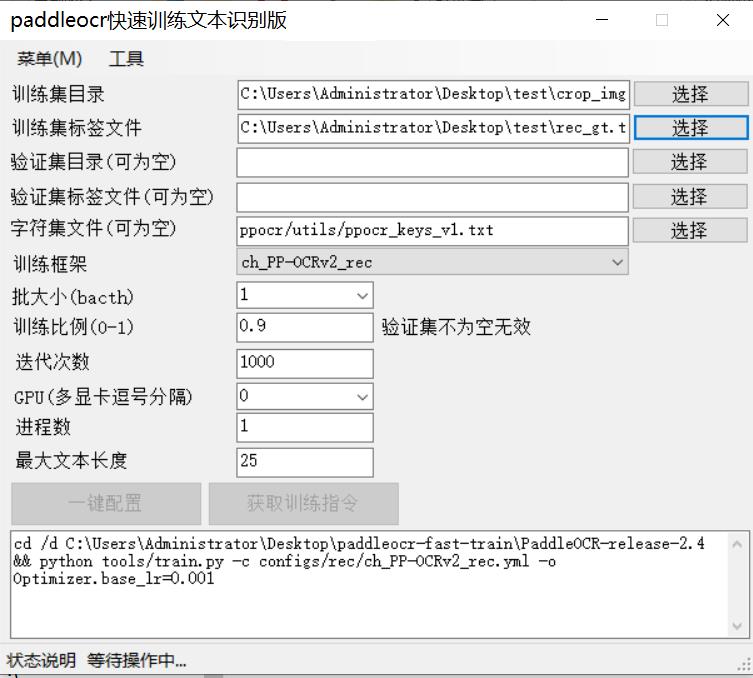
文本识别版本软件使用流程非常简单,只要你有数据集,也不用特意分割数据集。因为软件会自动分割数据集,如果自己想分割数据集也可以支持导入。那么你只需要在界面点点改改即可完成数据集配置参数自动配置,而你只需要粘贴到自己paddleocr的python环境即可开始训练。使用步骤如下:
(1)使用PPOCRLabel标注自己的数据集并且导出自己文本识别用的数据集。也可以自己编写脚本转换成paddleocr支持的数据集格式,paddleocr支持的文本识别数据集格式如下:

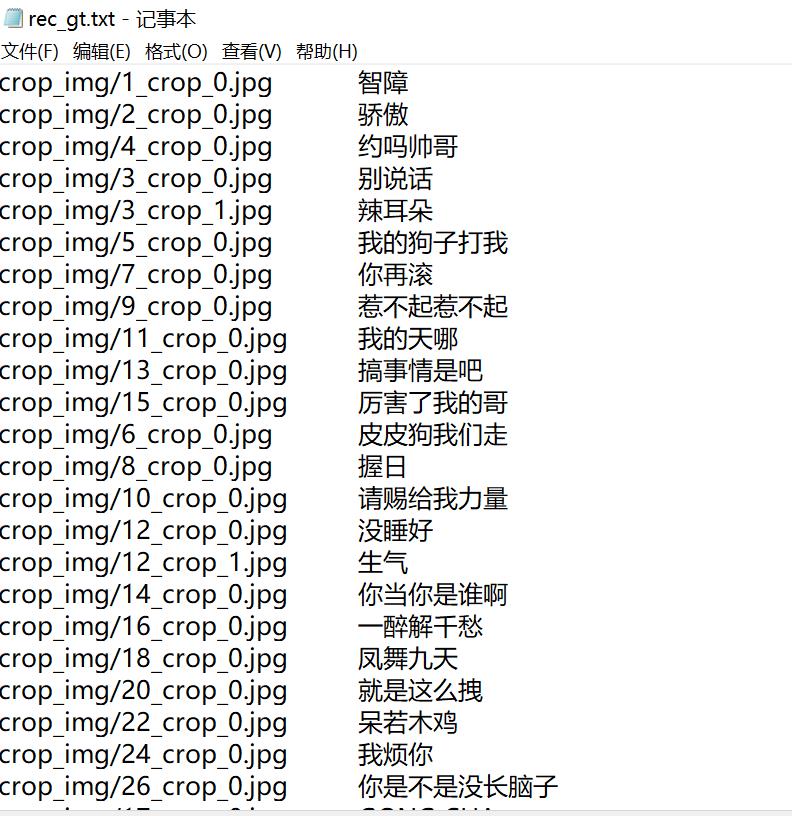
可以看出数据集格式为:
图片路径[TAB占位符]字符集
(2)打开文本识别版本的软件后,将数据集图片路径和数据集txt标签分别导入训练集目录和训练集标签文件,然后保持验证集目录和验证集标签文件为空就行了,这时候软件会自动分割数据集为9:1,如果大家不想按照这个比例,则可以设置训练比例为自己想要的即可。注意必须是0到1之间,不能设置为0或者1.如果您想使用自己的验证集,则可以导入证集目录和验证集标签文件,这是训练比例设置就会失效。软件自动按照你的验证集和训练集进行配置。
(3)为了方便训练软件默认设置batchsize为1,大家训练起来后通过nvidia-smi查看自己显存占用如果小了可以调节大点。为了方便调节,软件不需要反复配置数据集,只需要通过按钮获取训练命令便可以快速配置文件且生成新的训练命令。
注意:使用软件前需要自己安装好自己的paddleocr环境,目前软件是在paddleocr2.4版本上进行开发,后续会同步开发,所以大家安装环境要对应为paddleocr2.4环境即可。软件只是提供方便训练,并不具有测试和转换功能,如果大家对于训练的模型要测试需要使用官方提供相关命令测试即可。
软件优点如下:
(1)不需要人工写代码转换数据集,不需要写代码和手动配置就可以快速训练自己的数据集
(2)支持智能分割数据集,软件会自动打乱数据集,这样保证均匀分布数据集去分割数据集
(3)软件支持标注自动检查,我们只需要在工具-检查数据集格式即可检查数据集格式是不是有问题
(4)软件支持自动记忆界面配置参数,即使再次打开软件依然可以获取到现在训练命令
(5)软件支持快速切换文本检测框架。软件可以在简单切换框架后,点击获取命令即可快速训练,非常更换模型结构训练自己的模型
(6)软件支持字符集全自动生成或者手动导入,而且是否启用空格识别也是自动识别不需要手动在软件界面配置
(7)支持cpu或者GPU训练,只要你搭建好CPU环境选择cpu即可,如果搭建的是GPU环境选择自己对应的显卡即可。
更多更详细的信息可以参考官方提供的视频教程:paddleocr快速训练助手文本识别版使用教程_哔哩哔哩_bilibili
以上是关于paddleocr训练自己的数据最简单方式软件一键训练的主要内容,如果未能解决你的问题,请参考以下文章