使用DolphinScheduler调度Python任务
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用DolphinScheduler调度Python任务相关的知识,希望对你有一定的参考价值。
文章目录
概述
-
需求:在某个特定的时间运行Python(Anaconda)任务
方案1:crontab来定时调度
方案2:crontab没有便于操作的Web界面及报警等功能,于是引入DolphinScheduler -
Apache DolphinScheduler是一个分布式去中心化,易扩展的可视化DAG工作流任务调度平台
致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用
中文官网:https://dolphinscheduler.apache.org/zh-cn/
DolphinScheduler架构图
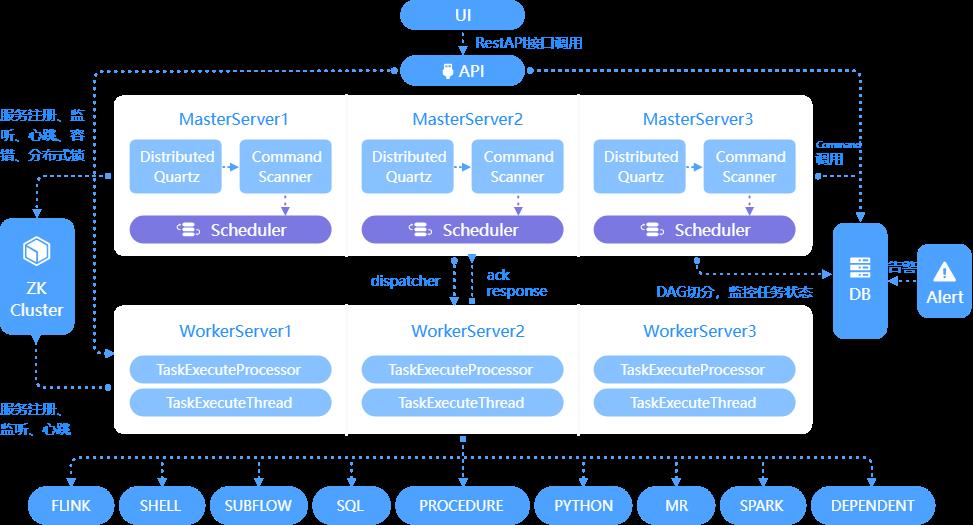
| 主要角色 | 主要职责 |
|---|---|
| MasterServer | DAG任务切分、任务提交监控;监听其它MasterServer和WorkerServer的健康状态 |
| WorkerServer | 任务的执行和提供日志服务 |
| ZK Cluster | MasterServer和WorkerServer启动时,会向Zookeeper注册临时节点 |
| Alter | 提供告警相关服务 |
| API | 处理前端UI层的请求 |
| UI | 提供Web操作界面 |
DolphinScheduler集群部署
| 部署规划 | hadoop105 | hadoop106 | hadoop107 | 备注 |
|---|---|---|---|---|
| MasterServer | 1 | 1 | 端口(非通信的)默认5678 | |
| WorkerServer | 1 | 1 | 1 | 端口(非通信的)默认1234 |
| LoggerServer | 1 | 1 | 1 | 日志服务,隶属WorkerServer 功能:日志分片查看、刷新、下载… |
| AlertServer | 1 | 告警服务,暂时仅支持单机 | ||
| ApiApplicationServer | 1 | 提供后端通信,端口默认12345 |
DS依赖Java,集群部署依赖ZooKeeper
另外,本文还配置DS元数据存储到mysql,资源存储到HDFS
准备工作
安装进程管理相关的命令,用于支持DolphinScheduler(每个节点都执行)
yum install -y psmisc
创建具有sudo权限的用户
https://yellow520.blog.csdn.net/article/details/115495027
集群用户免密登录
https://blog.csdn.net/Yellow_python/article/details/110143502
下载DolphinScheduler
wget https://dlcdn.apache.org/dolphinscheduler/2.0.3/apache-dolphinscheduler-2.0.3-bin.tar.gz
解压
tar -zxvf apache-dolphinscheduler-2.0.3-bin.tar.gz
配置DolphinScheduler元数据存储在MySQL
MySQL建库ds和用户dolphinscheduler,自设密码
mysql -uroot -p
-- 创建数据库
CREATE DATABASE ds DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
-- 创建用户和网络允许,并设置密码
CREATE USER 'dolphinscheduler'@'%' IDENTIFIED BY '密码';
-- 给用户赋予库的权限
GRANT ALL PRIVILEGES ON ds.* TO 'dolphinscheduler'@'%';
flush privileges;
下载MySQL驱动8.0.16,放到DolphinScheduler的lib
wget https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-8.0.16.tar.gz
tar -zxvf mysql-connector-java-8.0.16.tar.gz
cp mysql-connector-java-8.0.16/mysql-connector-java-8.0.16.jar apache-dolphinscheduler-2.0.3-bin/lib/
安装配置
cd apache-dolphinscheduler-2.0.3-bin
vim ./conf/config/install_config.conf
数据存储的配置(要和上面MySQL的一致)
# 数据库类型
DATABASE_TYPE="mysql"
# 数据库连接
SPRING_DATASOURCE_URL="jdbc:mysql://hadoop105:3306/ds?useUnicode=true&characterEncoding=UTF-8"
# 数据库用户及其密码
SPRING_DATASOURCE_USERNAME="dolphinscheduler"
SPRING_DATASOURCE_PASSWORD="密码"
基础配置
# 安装路径
installPath="/opt/module/dolphinscheduler"
# 配一个具有sudo权限的用户
deployUser="yellow"
# JAVA_HOME
javaHome="/opt/module/jdk"
# ZooKeeper地址
registryPluginName="zookeeper"
registryServers="hadoop105:2181,hadoop106:2181,hadoop107:2181"
集群服务的配置,只改节点,不改端口
vim ./conf/config/install_config.conf
ips="hadoop105,hadoop106,hadoop107"
masters="hadoop106,hadoop107"
workers="hadoop105:default,hadoop106:default,hadoop107:default"
alertServer="hadoop105"
apiServers="hadoop105"
pythonGatewayServers="hadoop105"
资源上传到HDFS的配置(可选)
vim ./conf/config/install_config.conf
# 资源类型
resourceStorageType="HDFS"
# 资源上传路径
resourceUploadPath="/dolphinscheduler"
# 资源的地址
defaultFS="hdfs://hadoop105:8020"
# HDFS用户
hdfsRootUser="yellow"
YARN队列的配置,端口8888不用改(可选)
# 非高可用RM设定此值为空
yarnHaIps=
# 单节点RM的主机名
singleYarnIp="hadoop106"
环境
vim ./conf/env/dolphinscheduler_env.sh
# Big Data:大数据根目录
export B_HOME=/opt/module
# Java
export JAVA_HOME=$B_HOME/jdk
# Hadoop
export HADOOP_HOME=$B_HOME/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# HIVE
export HIVE_HOME=$B_HOME/hive
# Spark
export SPARK_HOME1=$B_HOME/spark
export SPARK_HOME2=$B_HOME/spark
# Flink
export FLINK_HOME=$B_HOME/flink
# DataX
export DATAX_HOME=$B_HOME/datax
# Path
export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$FLINK_HOME/bin:$DATAX_HOME/bin:$PATH
安装
MySQL数据库初始化
./script/create-dolphinscheduler.sh
集群安装
./install.sh
启停
启动
./bin/start-all.sh
停止
./bin/stop-all.sh
启停某个服务,如:关闭Alter服务
./bin/dolphinscheduler-daemon.sh stop alert-server
DolphinScheduler启动后,浏览器访问http://hadoop105:12345/dolphinscheduler
初始用户名admin密码dolphinscheduler123,可去Web界面的安全中心处修改
DolphinScheduler使用
安全中心
用户是指DolphinScheduler的用户
| 用户分类 | 主要职责 |
|---|---|
| 管理员 | 创建普通用户并授权 通常管理员不执行工作流 Worker分组管理、环境管理 |
| 普通用户 | 创建项目、工作流 执行和监控工作流 |
租户对应的是Linux的用户,用于worker提交作业所使用的用户
若Linux没有该用户,就导致任务失败或创建该用户(参数:workerTenantAutoCreate)
队列对接YARN资源队列
在DolphinScheduler中创建队列,并不会影响到YARN调度器的队列配置
Worker分组
通常Python不适合做跨节点的分布式任务,建议配置某个节点专门跑Python任务
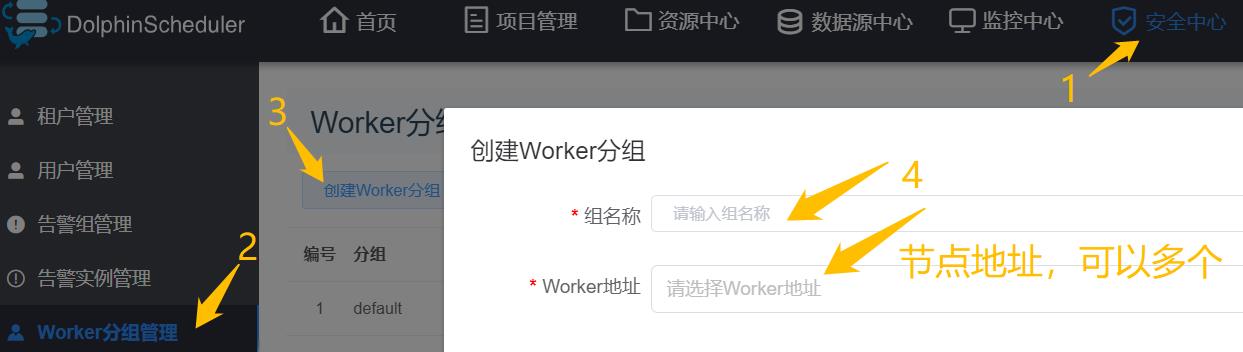
创建后,去对应节点的DS安装目录(之前在install_config.conf里配了installPath)改Python环境
cd /opt/module/dolphinscheduler
vim ./conf/env/dolphinscheduler_env.sh
# Python:export PYTHON_HOME=miniconda3安装路径/envs/虚拟环境的名称
export PYTHON_HOME=/home/miniconda/miniconda3
# Path
export PATH=$PYTHON_HOME/bin:$PATH
项目管理
- 一个项目下可以又多个工作流,一个工作流可以有多个节点,多个节点连接构成DAG
- 节点内可以绑定Worker分组和Python环境
- 工作流启动后,会生成1个工作流实例及其下的n个任务实例
调度Python工作的步骤
1、安全中心
- 创建用于跑Python的租户
- 创建普通用户,绑定租户
- 创建Worker分组,绑定专门跑Python的节点
- 切换到普通用户
2、资源中心
- 创建文件夹
- 进入文件夹
- 上传文件或创建文件
3、项目管理
- 创建项目
- 创建工作流
- 创建节点,绑定环境和Worker分组
3.1、跑单个Py文件:创建Python节点,把代码粘到代码区域
3.2、跑资源中心的Py代码:创建Shell节点,引用资源中心的Py代码 - 工作流上线
- 工作流调度
以上是关于使用DolphinScheduler调度Python任务的主要内容,如果未能解决你的问题,请参考以下文章
大数据任务调度工具 Apache DolphinScheduler
大数据任务调度工具 Apache DolphinScheduler