深入jvm字节码
Posted 野生java研究僧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入jvm字节码相关的知识,希望对你有一定的参考价值。
深入jvm字节码
- 1.深入剖析class文件结构
- 2.字节码基础
- 3.字节码进阶
- 4.javac编译原理
- 5.从字节码的角度看Kotlin语言
- 6.ASM和javassist字节码操作工具
- 7.java Instrumentation 原理
- 8.JSR 269 插件注解化处理原理
- 9.软件破解和防破解
1.深入剖析class文件结构
1.1初探class文件
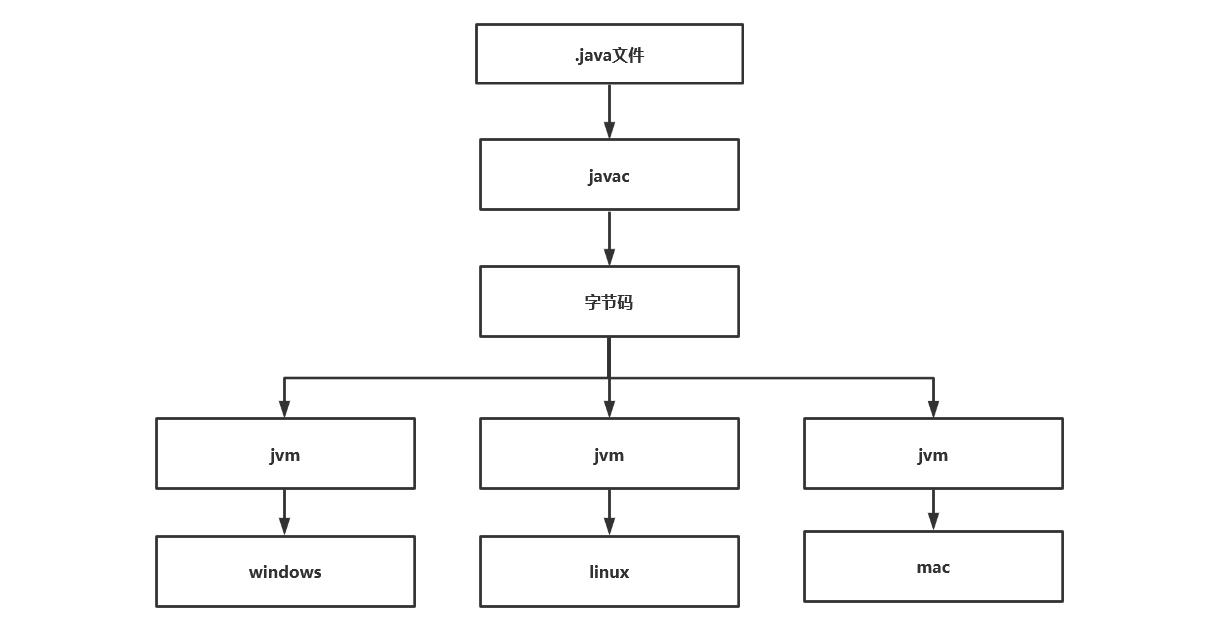
java声称一次编译,到处运行,这与他的jvm实现有关,java语言是和平台无关的,是可以跨操作系统的,但是jvm缺不能,不同的jvm帮我们屏蔽了不同的操作系统,java语言编写的同一份代码,不同的jvm虚拟机实现,会帮我们编译成不同的二进制文件。
下面我们一输出hello world 来开始我们的class文件探索之旅。
public class Hello
public static void main(String[] args)
System.out.println("hello world");
使用javac 命令编译 Hello.java即可得到class文件,然后再用16进制显示文件内容即可得到下面的内容。可以使用 EditPlus.exe 然后查看的时候选择utf-8的编码格式,然后点击菜单栏中的HX即可查看Hello.class的16进制文件内容。
CA FE BA BE 00 00 00 34 00 1D 0A 00 06 00 0F 09
00 10 00 11 08 00 12 0A 00 13 00 14 07 00 15 07
00 16 01 00 06 3C 69 6E 69 74 3E 01 00 03 28 29
56 01 00 04 43 6F 64 65 01 00 0F 4C 69 6E 65 4E
75 6D 62 65 72 54 61 62 6C 65 01 00 04 6D 61 69
6E 01 00 16 28 5B 4C 6A 61 76 61 2F 6C 61 6E 67
2F 53 74 72 69 6E 67 3B 29 56 01 00 0A 53 6F 75
72 63 65 46 69 6C 65 01 00 0A 48 65 6C 6C 6F 2E
6A 61 76 61 0C 00 07 00 08 07 00 17 0C 00 18 00
19 01 00 0B 68 65 6C 6C 6F 20 77 6F 72 6C 64 07
00 1A 0C 00 1B 00 1C 01 00 49 63 6F 6D 2F 73 6D
61 72 74 70 6C 67 2F 67 6F 75 72 64 2F 63 6C 6F
75 64 2F 67 67 66 77 2F 64 65 63 6C 61 72 65 2F
6F 66 66 69 63 65 4E 65 77 49 6E 73 75 72 65 64
2F 73 65 72 76 69 63 65 2F 69 6D 70 6C 2F 48 65
6C 6C 6F 01 00 10 6A 61 76 61 2F 6C 61 6E 67 2F
4F 62 6A 65 63 74 01 00 10 6A 61 76 61 2F 6C 61
6E 67 2F 53 79 73 74 65 6D 01 00 03 6F 75 74 01
00 15 4C 6A 61 76 61 2F 69 6F 2F 50 72 69 6E 74
53 74 72 65 61 6D 3B 01 00 13 6A 61 76 61 2F 69
6F 2F 50 72 69 6E 74 53 74 72 65 61 6D 01 00 07
70 72 69 6E 74 6C 6E 01 00 15 28 4C 6A 61 76 61
2F 6C 61 6E 67 2F 53 74 72 69 6E 67 3B 29 56 00
21 00 05 00 06 00 00 00 00 00 02 00 01 00 07 00
08 00 01 00 09 00 00 00 1D 00 01 00 01 00 00 00
05 2A B7 00 01 B1 00 00 00 01 00 0A 00 00 00 06
00 01 00 00 00 08 00 09 00 0B 00 0C 00 01 00 09
00 00 00 25 00 02 00 01 00 00 00 09 B2 00 02 12
03 B6 00 04 B1 00 00 00 01 00 0A 00 00 00 0A 00
02 00 00 00 0A 00 08 00 0B 00 01 00 0D 00 00 00
02 00 0E
1.2 class文件结构解析
java虚拟机规定用u1,u2,u4三种数据结构来表示1,2,4字节无符号整数,相同若干条数据用集合表的形式来存储,表是一个变长结构,由表长度的表头n和紧随的n个数据组成,class文件采用类似c语言的结构体进行存储,如下图所示:
字节码结构:
| 类型 | 名称 | 说明 | 长度 | 数量 |
|---|---|---|---|---|
| u4 | magic | 识别Class文件 | 4byte | 1 |
| u2 | minor_version | 服版本号 | 2byte | 1 |
| u2 | major_version | 主版本号 | 2byte | 1 |
| u2 | constant_pool_count | 常量池计数器 | 2byte | 1 |
| cp_info | constant_pool[constant_pool_count-1] | 常量池表 | N byte | constant_pool_count-1 |
| u2 | access_flags | 访问标识 | 2byte | 1 |
| u2 | this_class | 类索引 | 2byte | 1 |
| u2 | super_class | 父类索引 | 2byte | 1 |
| u2 | interfaces_count | 接口计数器 | 2byte | 1 |
| u2 | interfaces[interfaces_count] | 接口索引集合 | 2byte | interfaces_count |
| u2 | fields_count | 字段计数器 | 2byte | 1 |
| filed_info | fields[fields_count] | 字段表 | N byte | fields_count |
| u2 | methods_count | 方法计数器 | 2byte | 1 |
| method_info | methods[methods_count] | 方法表 | N byte | methods_count |
| u2 | attributes_count | 属性计数器 | 2byte | 1 |
| attribute_info | attributes[attributes_count] | 属性表 | N byte | attributes_count |
classFile
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count]
u2 attributes_count;
attribute_info attributes[attributes_count];
class文件由下面10个部分组成:

1.2.1 魔数
前4个字节表示是否是java类型的class类型文件。我们通常根据文件名来区分文件的类型,比如: .txt,.png,.jpg等使用文件名来区分文件类型这显然不靠谱,因为文件名可以随意被更改,但是使用文件内容来做文件类型的区分是怎么做到的呢?java使用前4个字节表示java文件,CA FE BA BE 就表示这是一个java文件,也就是class文件的标识。如果clas文件不是以 CA FE BA BE 开头的那么在虚拟机加载的时候,就会抛出,java.lang.ClassFoormatError错误。
1.2.2 版本号
4~7 字节,表示类的版本 00 34(十进制52) 表示是 Java 8,次版本在这里没有体现,版本兼容,jdk版本向下兼容
我们需要注意的是开发环境中的jdk版本和线上环境的jdk版本是否一致
虚拟机jdk颁布为1.k(k>=2)时,对应的Class文件格式的版本范围为:45.0-44+k.0(含两端)
| jdk版本 | 主版本(10进制) |
|---|---|
| JDK 1.1 | 45 |
| JDK 1.2 | 46 |
| JDK 1.3 | 47 |
| JDK 1.4 | 48 |
| JDK 1.5 | 49 |
| JDK 1.6 | 50 |
| JDK 1.7 | 51 |
| JDK 1.8 | 52 |
1.2.3 常量池
| Constant Type | Value | 描述 | |
|---|---|---|---|
| CONSTANT_Class | 7 | 类或接口的符号引用 | |
| CONSTANT_Fieldref | 9 | 字段的符号引用 | |
| CONSTANT_Methodref | 10 | 类中方法的符号引用 | |
| CONSTANT_InterfaceMethodref | 11 | 接口中方法的符号引用 | |
| CONSTANT_String | 8 | 字符串类型字面量 | |
| CONSTANT_Integer | 3 | 整形字面量 | |
| CONSTANT_Float | 4 | 浮点字面量 | |
| CONSTANT_Long | 5 | 长整形字面量 | |
| CONSTANT_Double | 6 | 双精度浮点字面量 | |
| CONSTANT_NameAndType | 12 | 字段或方法的符号引用 | |
| CONSTANT_Utf8 | 1 | UTF-8编码的字符串 | |
| CONSTANT_MethodHandle | 15 | 表示方法句柄 | |
| CONSTANT_MethodType | 16 | 标志方法类型 | |
| CONSTANT_InvokeDynamic | 18 | 表示一个动态方法调用点 |
在版本号之后跟的是常量池的数量。已经若干个常量池表项。常量池计数器从1开始而不是从0开始。常量池表项中用于存放编译时期生成的各种字面量和符号引用,这部分内容将在类加载后进入运行时常量池。常量池计数器就是用于记录常量池中有多少项。
为了满足后面某些常量指向常量池的索引值的数据在特定情况下需要表达 不引用常量池中的任何一项,这种情况索引值用0来表示
常量池大小:常量池是class文件中第一个出现变长的结构,既然是池,也就有大小,常量池由2个字节表示,假设常量池大小为N,常量池真正的有效索引号是1N9,也就是说如果 constant_pool_count为10,那么constant_pool数组的有效索引是1~9,0属于特殊索引,可供特殊情况下使用。
常量池项:最大包含N-1个元素,为什么是最多呢?long和double常量会占用2个索引位置,如果常量池中包含了这两种类型的元素,实际的常量池项的元素个数比N-1要小。
1.2.4 Access flags
紧随常量池区域后的是访问标记,用于标识一个类是否是 final,abstract等,由2个字节来表示,总共有16个标记为可以使用,目前只使用了其中8个如下图表格所示:
| 访问标记名 | 十六进制值 | 描述 |
|---|---|---|
| ACC_PUBLIC | 1 | 是否为public |
| ACC_FINAL | 10 | 是否为final |
| ACC_SUPER | 20 | 不在使用 |
| ACC_INTERFACE | 200 | 标识是类还是接口 |
| ACC_ABSTRACT | 400 | 是否为abstract |
| ACC_SYNTHETIC | 1000 | 编译器自动生成,不是用户源代码编译而成 |
| ACC_ANNOATATION | 2000 | 是否为注解类 |
| ACC_ENUM | 4000 | 是否为枚举类 |
1.2.5 this_class,super_name,interfaces
这三部分用来确认继承关系,this_class标识类索引,super_name表示直接父类的索引,interfaces表示类或者接口的直接父接口。
1.2.6 字段表
紧随接口索引表之后的是字段表,类中所有的字段都会被存储到这个集合中,包括静态字段和非静态字段。字段表也是一个变长的结构,filed_counts表示field的数量接下来的fileds表示字段集合,共有fileds_count个。
字段结构分为4个部分,第一部分表示access_flags表示字段访问标识,用来表示权限修饰符和static,final等,第二部分是name_index,用来表示字段名,指向常量字符串中的常量,第三部分description_index是字段描述符的索引,指向常量池中的字符串常量,最后的attributes_count,attribute_info表示属性的个数和属性集合。

**字段访问标记:**字段与类一样也有访问标记,而且比类的访问标记更加丰富共有9种。
| 访问标记名 | 十六进制值 | 描述 |
|---|---|---|
| ACC_PUBLIC | 0X0001 | 声明为public |
| ACC_PRIVATE | 0X0002 | 声明为private |
| ACC_PROTECET | 0X0004 | 声明为protected |
| ACC_STATIC | 0X0008 | 声明为static |
| ACC_FINAL | 0X0010 | 声明为final |
| ACC_VOLATILE | 0X0040 | 声明为volatile,解决内存可见性问题 |
| ACC_TRANSINENT | 0X0080 | 声明为transient表示不需要被序列化 |
| ACC_SYNTHETIC | 0X1000 | 编译器自动生成,不是用户源代码编译而成 |
| ACC_ENUM | 0X4000 | 表示这是一个枚举变量 |
字段描述符: 在jvm中定义一个int类型的变量不是用字符串int表示,而是用一个更加精简的字母I表示。
根据数据类型不同,分为三类:
- 原始类型:byte int char float double,long
- 引用类型:用L来进行表示,为了防止多个引用连续出现混乱,都用;号来进行分割比如String的描述符为:Ljava/lang/String;
- jvm使用 ‘[’ 来表示是一个数组,如果是多多维数组,也只是多加了一个 ‘[’ 而已。比如 String[ ] 的表示方式为:‘[ Ljava/lang/String;’
字段描述符映射表:
| 描述符 | 类型 |
|---|---|
| B | byte 类型 |
| C | char 类型 |
| D | double 类型 |
| F | float 类型 |
| I | int 类型 |
| J | long类型 |
| S | short 类型 |
| Z | boolean 类型 |
| L | 引用 类型 “L” + 对象全限定名+‘;’ |
| [ | 一维数组 |
**字段属性:**与字段相关的属性包括Constant Value ,Synthetic,Deprecated,Runtime-VisibleAnnotation和RuntimeInVsibleAnnotations和RuntimeInvisibleAnnotation这6个,比较常见的是Constant Value 属性,用来表示一个常量字段的值,具体在1.2.8在详细解释。
1.2.7 方法表
方法表和前面介绍的字段表非常类似,类中定义的所有方法都在这个表中,这里的表也是一个变长结构。
方法结构: 方法结构分为4个部分,第一部分表示access_flags表示字段访问标识,用来表示权限修饰符和static,final等,第二部分是name_index,用来表示方法名,指向常量字符串中的常量,第三部分description_index是方法描述符的索引,指向常量池中的字符串常量,最后的attributes_count,attribute_info表示属性的个数和属性集合。包含了很多有用的信息,比如方法内部字节码。
**方法访问标记:**方法访问标记类型更加丰富一共有12种
方法访问标记映射表:
| 方法标记 | 十六机制值 | 描述 |
|---|---|---|
| ACC_PUBLIC | 0X0001 | 声明为 public |
| ACC_PRIVATE | 0X0002 | 声明为 private |
| ACC_PROTECTED | 0X0004 | 声明为 protected |
| ACC_STATIC | 0X0008 | 声明为 static |
| ACC_FINAL | 0X0010 | 声明为 final |
| ACC_SYNCHRONIZED | 0X0020 | 声明为 synchronized |
| ACC_BRIGDE | 0X0040 | 声明为 birdge 方法 ,由编译器生成 |
| ACC_VARAGS | 0X0080 | 方法包含可变长参数,如: String args … |
| ACC_NATIVE | 0X0100 | 声明为 native |
| ACC_ABSTRACT | 0X0400 | 声明为 abstract |
| ACC_STRICT | 0X0800 | 声明为 strict ,表示使用IEEE-754规范精确浮点数 |
| ACC_STNTHETIC | 0X1000 | 这个方法由编译器自动生成,不是用户源代码生成 |
方法名与描述符:
紧随方法访问标记的是方法索引 name_index,指向常量池中的CONSTANT_Utf8_info类型的常量字符串,方法索引描述descriptor_index也是指向常量池中CONSTANT_Utf8_info类型的常量字符串,比如方法 Object foo(int i,double d,Thread t)的描述符为:“(IDLjava/lang/Thread;)Ljava/lang/Object;”
方法属性表: 方法属性表是method_info结构的最后一部分,前面介绍了方法的访问标记和方法签名,还有一些重要的细节没有出现,比如方法声明抛出的异常,方法的字节码,方法是否标记为deprecated等,属性表就是用来存储这些信息的,与方法相关的属性很多,其中比较重要的就是code和Exceptions属性,其中细节在1.2.8中进行详细介绍。
1.2.8 属性表
在方法表之后class结构的最后一部分是属性表,属性出现的地方比较广泛,不止出现在字段和方法中,在顶层class中也会出现,相比于常量池固定的14中类型,属性表类型更加灵活,不同的java虚拟机实现厂商可以自定义属性。
与其他结构类似,属性表使用2个字节表示属性的个数 attributes_count ,接下来是若干属性项的集合,可以看做为一个数组,每个属性项的attribute_info结构如下图所示:
attribute_info
u2 attribute_name_index;
u2 attribute_length;
u1 info[attribute_length];
attribute_name_index是指向常量池的索引,根据这个索引可以得到attribute的名字,接下来两部分表示info数组长度和byte内容。虚拟机预定义了20多种属性,接下来我们挑选字段表相关的ConstantValue属性和方法表相关的COde进行介绍。
1.ConstantValue: ConstantValue属性出现在field_info中,用来表示静态变量的初始值,他的结构如下图所示:
ConstantValue_attribute
u2 attribute_name-index;
u4 attribute_length;
u2 constantValue_index;
其中attribute_name-index是指向常量池只能值为“ConstantValue”的字符串常量项,attribute_length固定大小值为2,因为接下来的内容只会有2个字节大小,constantValue_index指向常量池中具体索引值,根据变量类型不同,constantvlaue_index指向不同类型的常量,如果变量为long类型,则 constant_index 指向CONSTANT_Loing_info类型的常量项。
2.code属性: code属性是class文件中最重要的组成部分,他包含了方法的字节码,除native和abstract方法以外,每个method都有一个code属性。他的结构如下:
Code_attribute
u2 attribute_name_index;
u4 attribute_length;
u2 max_stack;
u2 max locals;
u2 code_length;
u1 code[cdoe_length];
u2 exception_table_length;
u2 start_pc;
u2 end_pc;
u2 handler_pc;
u2 cache_type;
exception_table[exception_table_length];
u2 attribute_count;
attribute_info attributes[attributes_count];
下面开始介绍code各个属性字段含义:
1.属性名索引(attribute_name_index):占用2个字节,指向常量池中CONSTANT_Utf8_info常量,表示属性的名字。
2.属性长度 (attribute_length):占用2个字节,表示属性值长度大小。
3.操作数栈最大深度(max_stack):方法执行的任意期间操作数栈的深度不会超过这个值,他的计算规则是有入栈指令,stack增加,有出栈指令stack减少,在整个过程中,stack的最大值就是max_stack,减少和增加一般都是1,但也有列外,LONG和DOUBLE相关指令入站会加2,VOID相关指令则为0;
4.局部变量表大小(max_locals):他的值并不等于方法中所有的局部变量数之和,当一个局部作用域结束,他内部局部变量占用的位置就可以被接下来的局部变量重复使用。
5.code_length和code用来表示字节码相关的信息,其中code_length表示字节码指令长度,占用4个字节,code是长度为code_length的字节数组,存储真正的字节码指令。
6.exception_table_length和exception_table用来表示代码内部的异常信息,如我们属性的tr-catch语法就会生成对应异常表,exception_table_length表示接下来exception_table数组的长度,每个异常项包含四个部分,可以用下面的结构表示。‘
u2 start_pc;
u2 end_pc;
u2 handler_pc;
u2 cache_type;
其中start_pc,end_pc,handler_pc,都是指向code自己数组的所有值,start_Pc和end_pc表示异常处理覆盖的字节码开始和结束的位置,是嘴比右开区间[start_pc,end_pc]包含start_pc不包含end_pc,handler_pc表示异常处理handler在code自己数组的起始位置,异常被捕获以后该跳转到何处继续执行。
catch_type表示需要处理的catch异常是什么类型,他用2个字节码表示,执行常量池中类型为CONSTANT_Class_info的常量项,如果catch_type等于0,则表示可以处理任意异常,可以用来实现finally。
当jcm执行到这个方法[start_pc,end_pc]范围内的字节码发生异常时,如果发生的异常是这个catch_type对应的异常或者是他的子类,则跳转到code自己数组handler_pc处继续处理。
7.attributes_count和attributes[]用来表示Code属性相关的附属属性,java虚拟机规定Code属性只能包含中四种可选属性:LineNumberTable,LocalVaribleTable,LocalVariableTypeTable,StackMaoTable,以LineNumberTable为例 ,LineNumberTable用来存放源码的行号和字节码偏移量之间对应的关系,属于调试信息,不是雷文娟运行的必须属性,默认情况下都会生成,如果没有这个属性,那么在调试时就没有办法在源码中设置断点,也没有办法在代码中抛出异常的是在堆栈错误信息中显示出错的行号。
1.3使用javap查看类文件
让我们直接去阅读16进制的class文件难度比较大,而且不利于阅读,我们可以使用jdk提供的javap工具进行查看编译后的class字节码。他的使用方式如下:
javap [options ]
用法: javap <options> <classes>
其中, 可能的选项包括:
-help --help -? 输出此用法消息
-version 版本信息
-v -verbose 输出附加信息
-l 输出行号和本地变量表
-public 仅显示公共类和成员
-protected 显示受保护的/公共类和成员
-package 显示程序包/受保护的/公共类
和成员 (默认)
-p -private 显示所有类和成员
-c 对代码进行反汇编
-s 输出内部类型签名
-sysinfo 显示正在处理的类的
系统信息 (路径, 大小, 日期, MD5 散列)
-constants 显示最终常量
-classpath <path> 指定查找用户类文件的位置
-cp <path> 指定查找用户类文件的位置
-bootclasspath <path> 覆盖引导类文件的位置
2.字节码基础
2.1字节码概述
java虚拟机的指令由一个字节长度的操作码(opcode)和紧随其后的可选操作数构成。如下所示:
<opcode> [<operand1>,operand2]
比如将整形常量是100的压入栈顶的指令是 bipush 100 ,其中bipush是操作码,100是操作数,字节码的由来是操作码的长度用一个字节来表示,因为操作码的长度只有一个字节长度,这使编译后的字节码文件非常小巧紧凑,但是也现在了JVM字节码指令最多只能有256个,目前已经使用超过200个。
大部分字节码指令是和操作类型相关的,比如ireturn 指令用于返回一个int类型的数据,dreturn指令用于反会一个double类型的数据,freturn用于返回一个float类型的数据,这也使得实际的指令类型远小于200个。
字节码使用大端序进行表示(Big-Endian)表示,即高位在前,低位在后的方式,比如字节码 getfield 00 02,表示的是 getfield 0x00<<8 | 0x02(getfield #2)
字节码并不是cpu的机器码,而是一种介于源码和机器码中的一种抽象表示方法,不过字节码可以通过JIT技术可以进一步翻译为机器码。
根据字节码的不同作用,大概可以分为如下几类:
- 加载和存储指令:比如iload将一个int类型的整形数值从局部变量表中加载到操作数栈。
- 控制转移指令:比如条件分支 ifeq;
- 对象操作:比如创建对象指令 new
- 方法调用:比如invokevirtual指令用于调用对象实例的方法;
- 运算指令和类型转换:比如加法指令 iadd
- 线程同步:monitorenter 和 monitorexit 这两条指令用于支持Synchronized关键字
- 异常处理: athrow 显示抛出异常;
2.2java虚拟机栈和栈帧
java虚拟机实现的方式比较常见的有2种,分别是基于栈和寄存器,典型的虚拟机Hotspot就是基于栈的方式进行实现的,而典型的寄存器虚拟机有LuaVm和Goole开发的android虚拟机DalvikVM;
两者有什么不同呢?举一个两数相加的列子
java源代码如下:
int my_add(int a,int b)
return a+b;
使用javap查看字节码如下:
0: iload_1
1: iload_2
2: iadd
3: ireturn
实现相同的功能,使用lua代码如下:
local function my_add(a,b)
return a+b;
end
使用 luac -l -L -v -s test.lua查看lua的字节码如下所示:
[1] ADD R2 E0 R1 ; R2:Ro+R1
[2] Return R2 2 ; return R2
[3] Return R0 1 ; return
基于寄存器和栈的架构各有有点:
- 基于栈:栈的指令级的优点是移值性更好,指令更短,但不能随机访问堆栈中的元素,完成相同功能所需的指令数一般会比基于寄存器架构的要多,需要频繁的入站和出栈,不利于代码优化。
- 基于寄存器:寄存器的指令集的有点是速度快,可以充分利用寄存器,有利于程序做速度优化,但操作数需要显示指定,指令比较长。
栈帧: 在写递归程序的过程中,如果忘记写递归结束条件,就会出现 堆栈溢出异常,
Hotspot JVM是基于栈的虚拟机,每一个线程都有一个虚拟机栈来存储栈帧,创建和销毁,当线程请求分配的栈容量超过java虚拟机栈运行的最大深度时,就会抛出StackOverflowError异常,可以使用JVM命令虚拟机参数来调整栈深度大小,-Xss来指定栈的大小。
每个线程都有自己的java虚拟机栈,一个线程应用会拥有多个java虚拟机栈,每个栈都拥有自己的栈帧,栈帧是用于支持虚拟机进行方法调用和执行的数据结构,每个栈帧都拥有自己的局部变量表,操作数栈和常量池的引用
局部变量表: 每个栈帧内都包含一个局部变量表,局部变量表的大小是在编译期间就已经确定,对应class文件中方法Code属性的Max_locals字段,java虚拟机会根据max_locals字段来分配方法执行过程所需要分配的最大局部变量表容量。
操作数栈: 每个栈帧内都包含一个称为操作数栈先进后出的(LIFO),栈的大小同样也是在编译期间确定,java虚拟机提供很多字节码指令用于从局部变量表或者对实例对象的字段中复制常量或者变量到操作数栈,也有一些指令用于从操作数栈取走数据。
2.3 字节码指令
2.3.1 加载和存储指令
加载(load)和存储(store)相关的指令是使用的醉频繁的指令。分为load类和store和常量加载这三种。
- load类指令是将局部变量加载到操作数栈,比如iload_0是将局部变量表中下标为0的int类型变量加载到操作数栈上,根据不同类型的变量,还有lload,fload,dload,aload这些指令,分别表示,long,float。double,引用类型的变量。
- store类指令是将栈顶的数据存储到局部变量表中,比如istore_0,将操作数栈顶的元素存储到局部变量表中下标为0的位置,这个位置元素类型为int,根据不同类型变量的指令还有Istore,fstore,dstore,astore这些指令。
- 常量加载相关的指令,常见的有const类,push类,Ldc类,const,push类指令是将常量值直接加载到操作数栈顶,毕业iconst_0表示将整数为0加载到操作数栈上,bipush 100 是将int类型常量100加载到操作数栈上,Ldc指令是从常量池中加载对应的常量到操作数栈顶,比如Ldc#10是将常量池中下标为10的常量加载到操作数栈上。
- 为什么同时int类型常量,需要加载怎么多类型呢?这是因为使字节码更加紧凑,int了下常量是根据n的范围,使用指令如下规则:
- 若n在[-1,5]的范围内,使用iconst_n的方式,操作数栈和操作码加在一起是只占用一个自己,比如iconst_2对应的十六进制为0x05,-1比较特殊,对应的指令为iconst_m(0x02)。
- 若n在[-128-127]范围内,使用的是bipush的方式,操作数和操作码一起只占用2个字节,比如n的子为100(0x64)时 bipush 100 对应十六进制1位0x1064;
- 若n在[-32768,32767]范围内,使用sipush的方式操作数和操作码占用三个字节,比如n的值为1024(0x0400)时,对应的字节码为sipush 1024 (0x110400)
- 若n在其他范围内,使用Ldc的方式,将这范围内整数放在常量池中,比如n的值为40000时,40000被存储到常量池中,加载的指令为Ldc#i,i为常量池的索引值。
存储指令列表:
| 指令名称 | 描述 |
|---|---|
| aconst_null | 将null入栈到栈顶 |
| iconst_ml | 将int类型值-1加入到栈顶 |
| iconst_ | 将int类型值n(0-5)加入到栈顶 |
| Iconst_ | 将int类型值n(0-1)加入到栈顶 |
| fconst_ | 将int类型值n(0-2)加入到栈顶 |
| dconst_ | 将int类型值n(0-1)加入到栈顶 |
| bipush | 将范围在-128-127的整形值压入栈顶 |
| sipush | 将范围在-32768-32767的整形值压入栈顶 |
| Ldc | 将int,float,string类的常量值从常量池压入栈顶 |
| Ldc_w | 作用同Ldc,不同的是Ldc操作码是一个字节,Ld_w操作码是2个字节,即Ldc只能寻255个常量池索引值,ldc_w能寻址2个字节长度,可以覆盖常量池所有值。 |
| Ldc_2w | ldc_2w将long或double类型常量值从常量池压栈到栈顶,它的寻址范围为2个字节 |
| load | 将局部变量表中特定位置的类型为T的变量到栈顶,T可以是:i,l,f,d,a;分别表示int,long,float ,double,引用类型 |
| load | 将局部变量表中下标为n(0-3)的类型为T的变量加载到栈上T可以是:i,l,f,d,a; |
| aload | 将指定数组中指定位置的类型为T的变量加载到栈顶上,T可以为:i,l,f,d,a,b,c,s;分别表示:int,long,float,double,引用类型,boolean或者byte,char,short类型 |
| store | 将栈顶为T类型的数据存储到局部变量表的指定位置,T可以是:i,l,f,d,a; |
| store_ | 将栈顶为T类型的数据存储到局部变量表中下标为n(0-3)的位置,T可以为:i,l,f,d,a; |
| astore | 将栈顶为T的数据存储到数组的指定位置,T可以为:i,l,f,d,a,b,c,s;分别表示:int,long,float,double,引用类型,boolean或者byte,char,short类型 |
2.3.2 操作数栈指令
常见的操作数栈指令由 pop。dup,swap;
操作数栈指令:
| 指令名称 | 字节码 | 描述 |
|---|---|---|
| pop | 0x57 | 将栈顶的元 以上是关于深入jvm字节码的主要内容,如果未能解决你的问题,请参考以下文章 |