通俗易懂了解Hadoop
Posted 苏黎世的民谣
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通俗易懂了解Hadoop相关的知识,希望对你有一定的参考价值。
从本书第5、6、7、8章,学习云计算开发相关知识

这是第五章
文章目录
Hadoop:主流开源云架构
什么是分布式?
书中模拟了一个场景,提出了四个划时代的问题。
场景:我们现在有一些完全相同的计算机C1~Cn,每台计算机可以存5GB内容。另有两个均为2GB的文件f0和f1。
Q1:将f0和f1分别存入不同计算机,但对外显示存储在同一块硬盘;
Q2:另有一个6GB的文件f2,将它存入计算机,但对外显示为一个完整文件;
Q3:在Q1的前提下,统计f0和f1每个单词的出现次数(以下简称词频);
Q4:如果某个机器宕机,如何保证数据不丢失。
这四个问题,如果我们按照常规思路,似乎都是很难解决的。哎不对,Q3可以哦,只需要把f0复制到存储f1的计算机上,把它们放在一起统计即可,这确实没错。但如果是100个文件,每个文件1TB,就是复制文件这一步,我们都很难做到。这四个问题似乎没有了解决方法~

在这种情况下,分布式应运而生,下面是分布式思想来解决问题:
A1、A2:从这些相同的计算机中取出一台作为管理者,记为Master;其他计算机作为被管理者,记为Slave1~Slave(n-1)。Master中仅存储所有Slave机器的地址(也叫元数据),而不存储真实数据;所有Slave存储真实数据。这样设计,如果后期存储或计算需求增大,我们只需要在Master中再加入几个对应其他机器的地址映射,构建更庞大的集群,就可以完成需要。

如图,整个集群就像是一台机器Master、一片云。对外显示为一个硬盘空间,Q1、Q2解决。
A3:针对计算问题,Google提出“移动计算比移动数据更划算”,想想也是,数据动辄几个TB,代码一般就几个MB。基于此,我们假设f0存储在Slave0,f1存储在Slave1,先让两个文件在它们自己所在的机器中计算词频,将得到的结果在另一台机器中将同一个词的词频求和,就得到了这个词在两个文件中的词频,Q3解决(具体实现方法见MapReduce)。
A4:要想数据不丢失,唯一的办法就是备份。我们再取两台机器,记为Slave2和Slave3,Slave2存储文件f0,Slave3存储文件f1,将它们也归于Master管理。当Master启动计算时,四台机器同时工作,因为Slave0和Slave2的作用相同,当其中一台完成计算任务提交给Master,Master立即停止另一台的计算,使用前者提交的结果即可。
这样的话,我们岂不是白白浪费了很多资源?
确实是这样,但在绝大多数情况下,冗余存储和计算是必要的,因为数据丢失是不可逆过程,一旦出现,对企业甚至国家造成的影响太大了。
Hadoop体系架构
下面介绍它的四个组成成分:
Hadoop公共组件 -> Common
分布式文件系统 -> HDFS
分布式计算框架 -> MapReduce
分布式操作系统 -> Yarn
Common——制片人

可以说,没有Common,就没有这部“电影”。Common的定位是其他模块的公共组件,为其他模块提供公用API,观众看不到他,而他,一直在后台为剧组人员默默付出~
Common通过设计方式,降低了Hadoop设计的复杂性,减少了其他模块之间的耦合性,大大增强了Hadoop的健壮性。
HDFS——编剧
电影开拍前,HDFS会将所有的文件妥善存储,作为”剧本“,方便导演后期导戏。
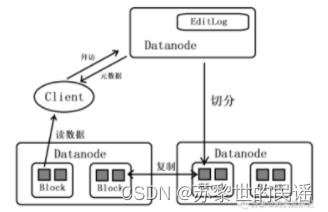
首先引入两个实体:namenode和datanode,Master运行主进程namenode,所有Slave运行从属进程datanode。namenode只存储元数据信息:文件块位置、大小、拥有者信息;datanode以块(block)为单位存储实际数据,这里的块通常为128MB,要存入的文件被切分成块,存入不同的datanode中。
当客户端(Client)要访问一个文件,先“拜访”namenode,问问数据在哪个datanode中?然后直接去相应的datanode读取数据。(不再需要namenode引荐)
事务日志(EditLog)记录HDFS元数据的变化,存储在namenode本地文件系统中。
MapReduce——导演
有了编剧的剧本,导演就可以用它开始工作了,MapReduce需要非常大的计算资源来最终完成这部电影。
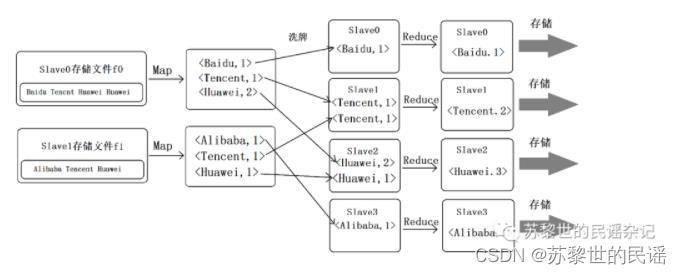
承接引例中的回答A3,下面说说MapReduce的详细过程(以统计词频为例)
假设文件f0和f1的内容分别为:
Baidu Tencent Huawei Huawei
Alibaba Tencent Huawei
引入“键值对”概念,即<key,value>,key表示单词,value为其出现次数。所以在单机中计算结果分别为:
<Baidu,1><Tencent,1><Huawei,2>
<Alibaba,1><Tencent,1><Huawei,1>
通过shuffle(洗牌)操作,将相同key的键值对放入同一台机器(这里需要4台),然后将value相加,此时得到的结果为:
<Baidu,1>
<Alibaba,1>
<Tencent,2>
<Huawei,3>
这个即为最终结果,将其存入分布式文件系统即可,下面附图详细过程:
MapReduce说白了就是Map和Reduce两个很简单的过程,别看它原理很简单,但应用范围非常广。
Yarn——后勤
正如后勤人员一样,Yarn管理着计算机资源并进行统一调配,同时提供用户程序访问系统资源的应用程序接口(API)。
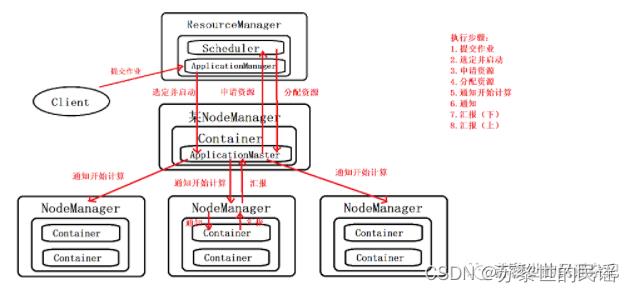
Yarn在执行时包含以下实体:
- Client:客户端,负责向集群提交作业;
- ResourceManager:集群的主进程,负责资源管理和任务调度;
- NodeManager:集群的从进程,管理和监视Containers,执行具体任务;
- Container:资源的独立单位;
- Scheduler:资源仲裁模块;
- ApplicationManager:选定,启动和监管ApplicationManager;
- ApplicationMaster:任务执行和监管中心。
工作过程如图:
通俗易懂的Spark基础之MapReduce和Hadoop
Spark前期基础预习
00
导语
参考课程
本文系列内容来自拉钩教育【即学即用的Spark实战44讲】课程,本人学习总结https://kaiwu.lagou.com/course/courseInfo.htm?courseId=71文章中的图大部分均来源于课程。
第01讲
MapReduce:计算框架和编程模型
起源:Google三驾马车
计算机科学包括人工智能、编程语言、系统以及理论,在系统领域有两大重要会议,一个是ODSI(USENIX conference on Operating Systems Design and Implementation),另一个是SOSP(ACM Symposium on Operating Systems Principles),这两个会议在业界享有很高的声誉。
Google从03年到06年在这两个会议上发表了三篇重要的论文,引起了业界在分布式系统的广泛讨论,并为Hadoop、HBase、Spark 等很快走上台前奠定了扎实的基础,大数据技术开始呈现出一个百花齐放的状态。
SOSP2003:The Google File System (讨论分布式文件系统)
ODSI2004:MapReduce: Simplifed Data Processing on Large Clusters (讨论分布式计算框架)
ODSI2006:Bigtable: A Distributed Storage System for Structured Data(开始揭开分布式的神秘面纱)
MapReduce
MapReduce有两个含义:
一般来说,在说到计算框架时,我们指的是开源社区的MapReduce计算框架,但随着新一代计算框架如Spark、Flink的崛起,开源社区的MapReduce计算框架在生产环境中使用得越来越少,主见退出舞台。
第二个含义是一种编程模型,这种编程模型来源于古老的函数式编程思想,在 Lisp 等比较老的语言中也有相应的实现,并随着计算机 CPU 单核性能以及核心数量的飞速提升在分布式计算中焕发出新的生机。
MapReduce 模型将数据处理方式抽象为map和reduce,其中map也叫映射,顾名思义,它表现的是数据的一对一映射,通常完成数据转换的工作。reduce被称为归约,它表示另外一种映射方式,通常完成聚合的工作,如下图所示:

圆角框可以看成是一个集合,里面的方框可以看成某条要处理的数据,箭头表示映射的方式和要执行的自定义函数,运用MapReduce编程思想,我们可以实现以下内容:
将数据集(输入数据)抽象成集合;
将数据处理过程用map与reduce进行表示;
在自定义函数中实现自己的逻辑。
并发和并行
Map和Reduce的自定义组合,在业务中的表现力是非常强的,下图举一个例子。
map端的用户自定义函数与map算子对原始数据人名进行了转换,生成了组标签:性别,reduce端的自定义函数与reduce算子对数据按照标签进行了聚合(汇总)。

MapReduce认为,再复杂的数据处理流程也无非是这两种映射方式的组合,例如map+map+reduce,或者reduce后面接map,等等,我们举个稍微复杂的例子。

现在,我们可以很容易的将第一个圆角方框想象成一个数十条数据的集合,它是内存中的集合变量,那么要实现上图中的变换,对于计算机来说,难度并不大,就算数据量再大些,我们也可以考虑将不同方框和计算流程交给同一台计算机的 CPU 不同的核心进行计算,这就是我们说的并行和并发。
当数据量的急剧扩大,背后工程实现的复杂度会成倍增加,当整个数据集的容量和计算量达到1台计算机能处理的极限的时候,我们就会想办法把图中方框所代表的数据集分别交给不同的计算机来完成,那么如何调度计算机,如何实现reduce过程中不同计算机之间的数据传输等问题,就是Spark基于MapReduce编程模型的分布式实现,这也是我们常常所说的分布式计算。
第02讲
Hadoop:集群的操作系统
Hadoop
Hadoop的出现,对于坐拥数据而苦于无法分析的用户来说,无疑是久旱逢甘霖,加之那段时间移动互联网的流行,数据呈几何倍数增长,Hadoop在很大程度上解决了数据处理的痛点。在很长的一段时间里,Hadoop是大数据处理的事实标准,直到现在,很多公司的大数据处理架构也是围绕Hadoop而建的。
Hadoop 1.0与2.0
Hadoop从问世至今一共经历了3个大版本,分别是1.0、2.0与最新的3.0,其中最有代表性的是1.0与2.0,3.0相比于2.0变化不大。Hadoop1.0的架构也比较简单,基本就是按照论文中的框架实现,其架构如下图所示。

其中,下层是 GFS 的开源实现 HDFS(Hadoop 分布式文件系统),上层则是分布式计算框架MapReduce,这样一来,分布式计算框架基于分布式文件系统,看似非常合理。但是,在使用的过程中,这个架构还是会出现不少问题,主要有 3 点:主节点可靠性差,没有热备;提交MapReduce作业过多的情况下,调度将成为整个分布式计算的瓶颈;资源利用率低,并且不能支持其他类型的分布式计算框架。
基于这些问题,社区开始着手Hadoop2.0的开发,Hadoop2.0最大的改动就是引入了资源管理与调度系统YARN(Yet Another Resource Negotiator),代替了原有的计算框架,而计算框架则变成了类似于YARN的用户,如下图:

YARN将集群内的所有计算资源抽象成一个资源池,资源池的维度有两个:CPU和内存。同样是基于HDFS,我们可以认为YARN管理计算资源,HDFS管理存储资源。上层的计算框架地位也大大降低,变成了YARN的一个用户,另外,YARN 采取了双层调度的设计,大大减轻了调度器的负担。
Hadoop 2.0 基本上改进了 Hadoop 的重大缺陷,此外 YARN 可以兼容多个计算框架,如 Spark、Storm、MapReduce 等,HDFS 也变成了很多系统底层存储,Hadoop以一种兼收并蓄的态度网罗了一大批大数据开源技术组件,逐渐形成了一个庞大的生态圈,如下图所示(该图只展示了一部分组件)。在当时,如果你要想搭建一个大数据平台,绝对无法绕过 Hadoop。
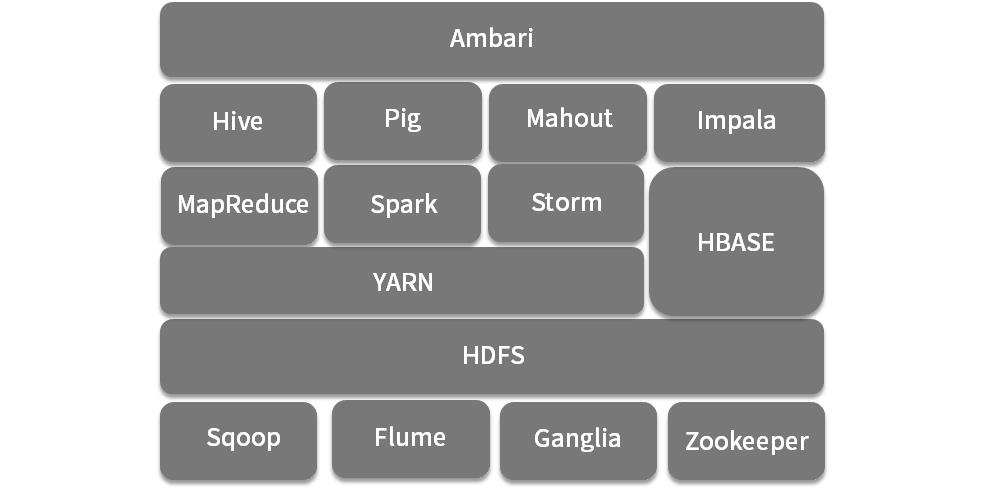
Hadoop大数据平台
当提及大数据平台的时候,我们要知道它首先是一个分布式系统,换句话说是由一组计算机构成的集群。所谓大数据平台,相当于把这个集群抽象成一台计算机,而底层的细节涉及不为人知,让用户使用这个平台时,像是在使用一台计算机,不会感觉到自己在使用一个分布式系统。
hadoop dfs -ls /ls /
第一条命令是浏览Hadoop文件系统(HDFS)的根目录,第二条命令是浏览 Linux本地文件系统的根目录,两条命令很像,没有很大的区别,也就是说Hadoop为用户提供了一套类似Liunx的环境,我们会用Linux的简单命令,也就会对Hadoop进行简单的操作,上手很快的。
因此,Hadoop可以理解为是一个计算机集群的操作系统,而Spark、MapReduce 只是这个操作系统支持的编程语言而已,HDFS 是基于所有计算机文件系统之上的文件系统抽象。同理,YARN是基于所有计算机资源管理与调度系统之上的资源管理与调度系统抽象,Hadoop是基于所有计算机的操作系统之上的操作系统抽象。所以如果你一定要进行比较的话,Hadoop应该和操作系统相比较。
第03讲
如何设计与实现统一资源管理与调度系统
统一资源管理与调度系统的设计
YARN的全称是 Yet Another Resource Negotiator,直译过来是:另一种资源协调者,但是它的标准名称是统一资源管理与调度系统,主要包含3个词:统一、资源管理、调度。YARN的资源管理有CPU和内存,下面我们谈一谈调度。
目前的宏观调度机制一共有3种:集中式调度器(Monolithic Scheduler)、双层调度器(Two-Level Scheduler)和状态共享调度器(Shared-State Scheduler)
集中式调度器全局只有一个中央调度器,计算框架的资源申请全部提交给中央调度器来满足,所有的调度逻辑都由中央调度器来实现,在高并发作业的情况下,容易出现性能瓶颈。
双层调度器将整个调度工作划分为两层:中央调度器和框架调度器。中央调度器管理集群中所有资源的状态,它拥有集群所有的资源信息,按照一定策略将资源粗粒度地分配给框架调度器,各个框架调度器收到资源后再根据应用申请细粒度将资源分配给容器执行具体的计算任务。在这种双层架构中,每个框架调度器看不到整个集群的资源,只能看到中央调度器给自己的资源。
状态共享式调度大大弱化了中央调度器,它只需保存一份集群使用信息,就是图中间的蓝色方块,取而代之的是各个框架调度器,每个调度器都能获取集群的全部信息。
YARN
简单来看看YARN的架构图,YARN的架构是典型的主从架构,主节点是 ResourceManger,也是我们前面说的主调度器,所有的资源的空闲和使用情况都由ResourceManager管理。ResourceManager也负责监控任务的执行,从节点是NodeManager,主要负责管理Container生命周期,监控资源使用情况等 ,Container是YARN的资源表示模型,Task是计算框架的计算任务,会运行在Container中,ApplicationMaster可以暂时认为是二级调度器,比较特殊的是它同样运行在Container中。

面试题哦:YARN 启动一个 MapReduce 作业的流程,如图所示:

第 1 步:客户端向 ResourceManager 提交自己的应用,这里的应用就是指 MapReduce 作业。
第 2 步:ResourceManager 向 NodeManager 发出指令,为该应用启动第一个 Container,并在其中启动 ApplicationMaster。
第 3 步:ApplicationMaster 向 ResourceManager 注册。
第 4 步:ApplicationMaster 采用轮询的方式向 ResourceManager 的 YARN Scheduler 申领资源。
第 5 步:当 ApplicationMaster 申领到资源后(其实是获取到了空闲节点的信息),便会与对应 NodeManager 通信,请求启动计算任务。
第 6 步:NodeManager 会根据资源量大小、所需的运行环境,在 Container 中启动任务。
第 7 步:各个任务向 ApplicationMaster 汇报自己的状态和进度,以便让 ApplicationMaster 掌握各个任务的执行情况
第 8 步:应用程序运行完成后,ApplicationMaster 向 ResourceManager 注销并关闭自己。
第04讲
解析Spark数据处理与分析场景
Spark应用场景
技术要在特定的场景下才能发挥作用,那么在数据科学与数据工程中,有哪些场景呢,下面来看看这张图,图中根据作业类型、需求确定性、结果响应时间将应用场景分为三大类,大概有所了解就可以。

第05讲
Spark编程语言选择及部署
【即学即用的Spark实战系列】---下一篇将介绍Spark的编程语言和环境部署,并手把手搭建环境,书写Spark的Hello world,一起学习。
AINLP与知识图谱旨在深度学习、自然语言处理、知识图谱、搜索推荐、大数据、相关竞赛等技术分享与解读。
你和我成长的加油站
成长的旅途是孤独,也是人生
分享一点,幸运多多,点击 在看 !
↘↘↘
以上是关于通俗易懂了解Hadoop的主要内容,如果未能解决你的问题,请参考以下文章