大数据之Spark环境搭建
Posted 敲键盘的杰克
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据之Spark环境搭建相关的知识,希望对你有一定的参考价值。
文章目录
前言
#博学谷IT学习技术支持#
Spark是Apache开源的最顶级的框架,具有高性能等特点,本文主要介绍Spark的环境搭建,虚拟机用的是前几篇文章中搭建的Linux系统的虚拟机,详情请看Linux系统环境搭建,
另外再加上Spark框架使用到的的软件包地址:Spark软件包下载链接、Anaconda环境包
一、Spark软件安装
(一)安装包上传并解压
只需要将安装包上传到node1即可,后续操作都在node1节点上
cd /export/software
rz 上传
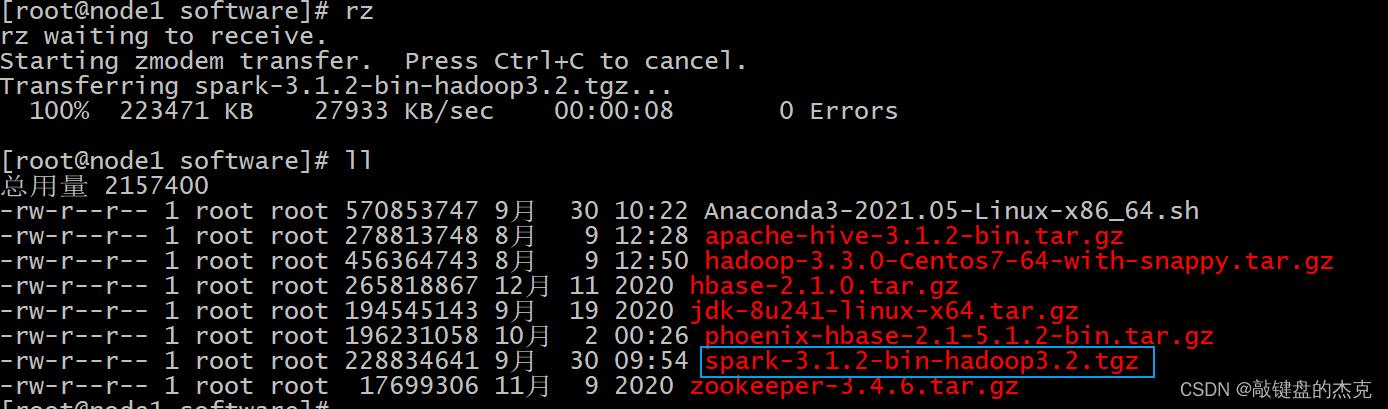
解压,将安装包解压到/export/server文件夹中
tar -zxf spark-3.1.2-bin-hadoop3.2.tgz -C /export/server/
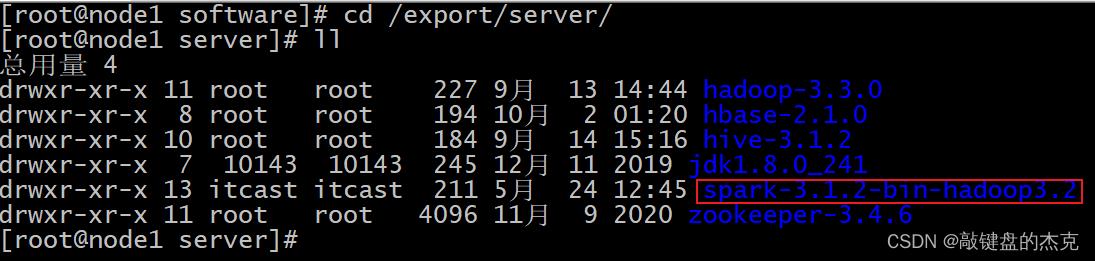
(二)Spark文件夹更名
为了后续方便访问spark文件夹,可以对文件夹进行更名,主要有两种方式,一种是创建软链接,另一种是修改文件夹名称,建议使用第一种方式,
先进入/export/server路径:cd /export/server
方式一:
软连接方案: ln -s spark-3.1.2-bin-hadoop3.2 spark
方式二:
直接重命名: mv spark-3.1.2-bin-hadoop3.2 spark
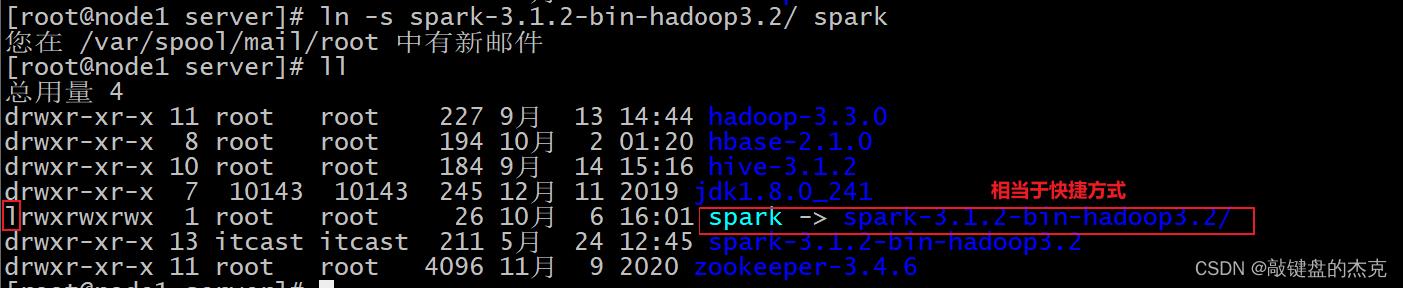
(三)目录结构说明
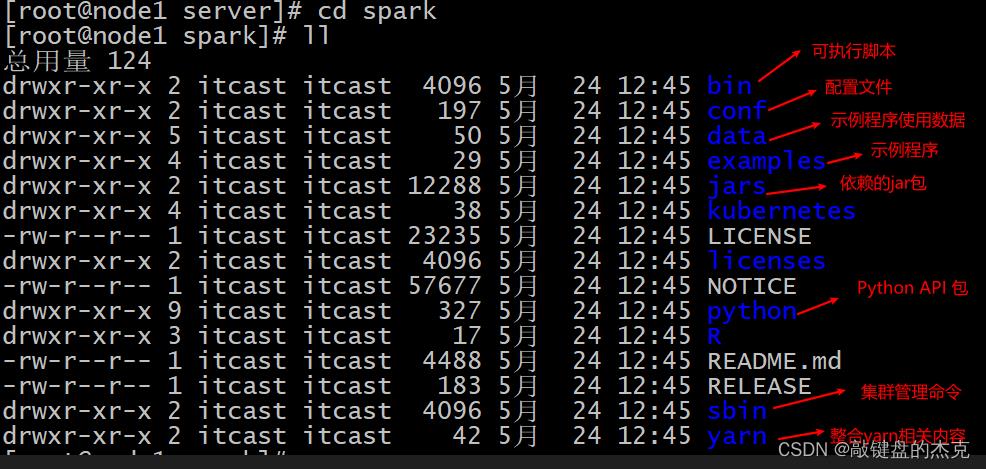
(四)测试
Spark的local模式, 直接启动spark路径中bin目录下的spark-shell脚本
cd /export/server/spark/bin
./spark-shell
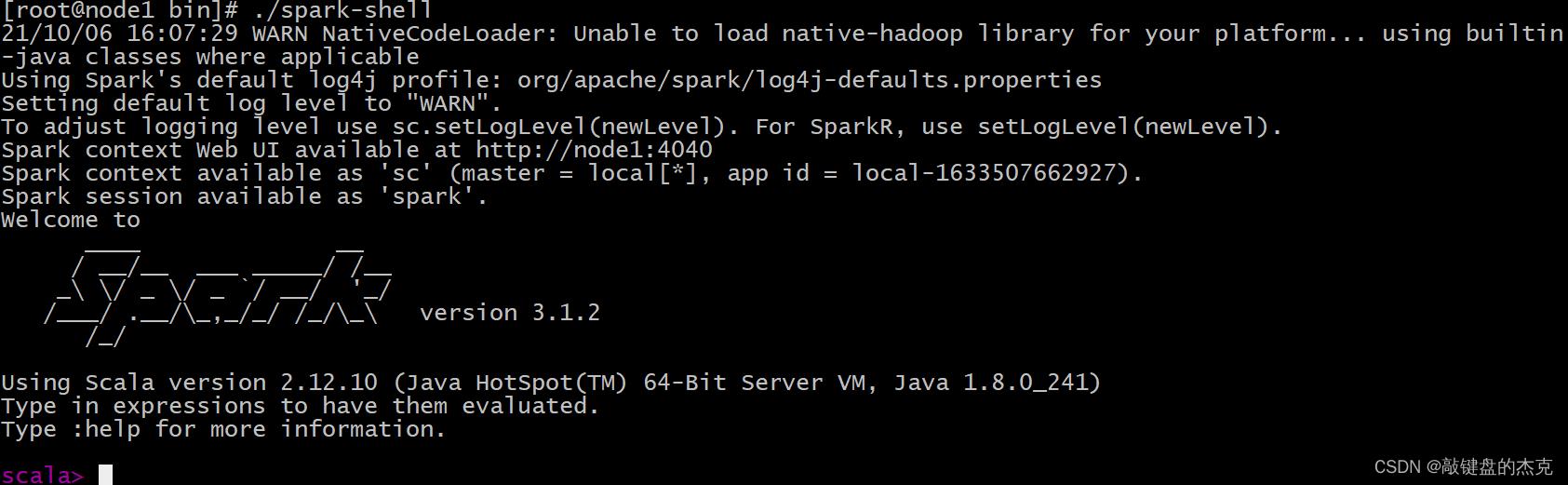
Spark的Web监控页面端口号为4040,可以通过浏览器访问

二、 PySpark环境安装
Spark是一个独立的框架,该框架支持Python和Java等较为主流的语言,我们主要使用python进行开发,需要安装PySpark库,该库主要供Python使用,类似Pandas一样,是一个库;同时还需要具备python环境,这里使用Anaconda环境。
(一)下载Anaconda环境包
Anaconda环境包可以直接从文章开头链接进行下载,也可以点击下方链接进行下载:Anaconda环境包,下载的文件名为:Anaconda3-2021.05-Linux-x86_64.sh
(二)安装Anaconda环境
Annconda环境三台节点都需要安装的, 以下演示在node1安装, 其余两台也是安装相同的步骤进行安装,
cd /export/software
rz 上传Anaconda脚本环境
执行脚本:bash Anaconda3-2021.05-Linux-x86_64.sh
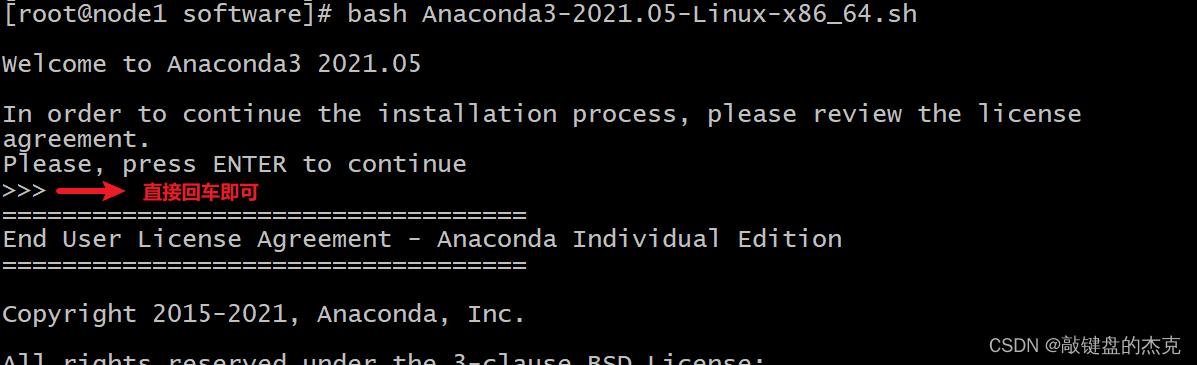
不断输入空格, 直至出现以下解压, 然后输入yes
此时, Anaconda需要下载相关的依赖包, 时间比较长, 耐心等待即可, 在等待中如果需要输入yes/no, 直接输入yes
配置anaconda的环境变量:
vim /etc/profile
##增加如下配置
export ANACONDA_HOME=/root/anaconda3/bin
export PATH=$PATH:$ANACONDA_HOME/bin
重新加载环境变量: source /etc/profile
修改bashrc文件
sudo vim ~/.bashrc
添加如下内容:
export PATH=~/anaconda3/bin:$PATH
(三)启动Anaconda并测试
注意,当前连接node1的节点窗口需要重新启动,否则无法识别
输入 Python启动:

(四)PySpark安装
三个节点可以都安装pySpark,本质上只需要在node1安装,后续主要基于node1来进行本地测试
安装PySpark主要有两种方式:
-
直接安装PySpark,安装如下
使用pip安装PySpark,也可以指定版本安装:pip install pyspark==3.1.2 或者 指定清华镜像pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark==3.1.2 或者本地安装:先将pyspark上传到node1 /export/software cd /export/software pip install pyspark-3.1.2.tar.gz实操效果图 :

-
创建Conda环境安装PySpark,从终端创建新的虚拟环境
conda create -n pyspark_env python=3.8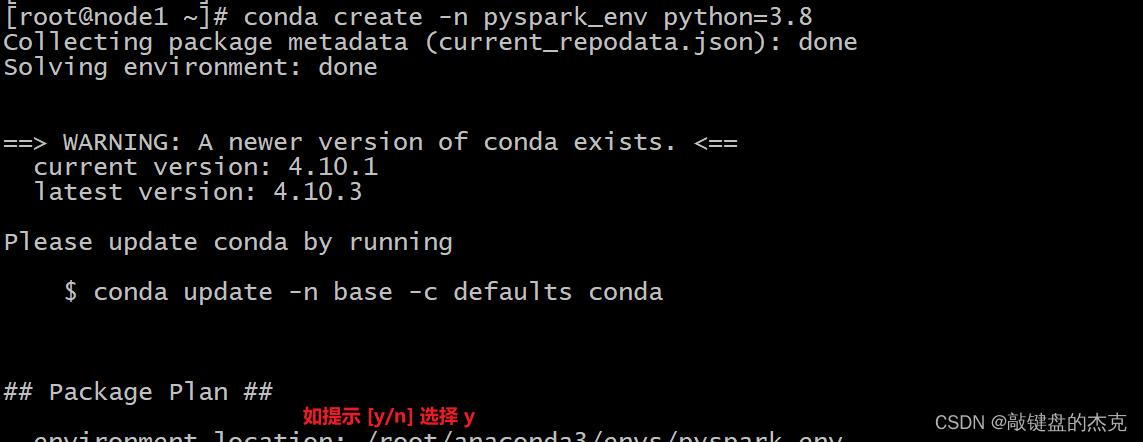 创建虚拟环境后,新环境在 Conda 环境列表下可见,可以使用命令查看
创建虚拟环境后,新环境在 Conda 环境列表下可见,可以使用命令查看conda env list
接着使用以下命令激活新创建的环境:source activate pyspark_env 或者 conda activate pyspark_env
可以在新创建的环境中通过使用pip安装PySpark,它将pyspark_env在上面创建的新虚拟环境下安装 PySpark。pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark==3.1.2 或者 可以从 Conda 本身安装 PySpark: conda install pyspark==3.1.2
三、Spark on YARN 环境搭建
我们主要使用5.Spark on YARN的环境进行开发,所以需要进行相对应的设定
(一)修改spark-env.sh
cd /export/server/spark/conf
cp spark-env.sh.template spark-env.sh
vim /export/server/spark/conf/spark-env.sh
添加以下内容:
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/
-Dspark.history.fs.cleaner.enabled=true"
同步到其他两台(单节点时候, 不需要处理)
cd /export/server/spark/conf
scp -r spark-env.sh node2:$PWD
scp -r spark-env.sh node3:$PWD
(二)修改hadoop的yarn-site.xml
cd /export/server/hadoop-3.3.0/etc/hadoop/
vim /export/server/hadoop-3.3.0/etc/hadoop/yarn-site.xml
添加以下内容:
<configuration>
<!-- 配置yarn主节点的位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 设置yarn集群的内存分配方案 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<!-- 开启日志聚合功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置聚合日志在hdfs上的保存时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 关闭yarn内存检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
将其同步到其他两台
cd /export/server/hadoop/etc/hadoop
scp -r yarn-site.xml node2:$PWD
scp -r yarn-site.xml node3:$PWD
(三)Spark设置历史服务地址
cd /export/server/spark/conf
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
添加以下内容:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1:8020/sparklog/
spark.eventLog.compress true
spark.yarn.historyServer.address node1:18080
配置后, 需要在HDFS上创建 sparklog目录
hdfs dfs -mkdir -p /sparklog
设置日志级别:
cd /export/server/spark/conf
cp log4j.properties.template log4j.properties
vim log4j.properties
修改以下内容:

若有多节点,则需要同步到其他节点
cd /export/server/spark/conf
scp -r spark-defaults.conf log4j.properties node2:$PWD
scp -r spark-defaults.conf log4j.properties node3:$PWD
(四)配置依赖spark jar包
当Spark Application应用提交运行在YARN上时,默认情况下,每次提交应用都需要将依赖Spark相关jar包上传到YARN 集群中,为了节省提交时间和存储空间,将Spark相关jar包上传到HDFS目录中,设置属性告知Spark Application应用;
hadoop fs -mkdir -p /spark/jars/
hadoop fs -put /export/server/spark/jars/* /spark/jars/
修改spark-defaults.conf
cd /export/server/spark/conf
vim spark-defaults.conf
添加以下内容:
spark.yarn.jars hdfs://node1:8020/spark/jars/*
同理,若有多节点,则需要同步到其他节点
cd /export/server/spark/conf
scp -r spark-defaults.conf root@node2:$PWD
scp -r spark-defaults.conf root@node3:$PWD
(五)启动服务
Spark Application运行在YARN上时,上述配置完成,运行Spark前需要启动以下服务:HDFS、YARN、MRHistoryServer和Spark HistoryServer,命令如下:
## 启动HDFS和YARN服务,在node1执行命令
start-dfs.sh
start-yarn.sh
或
start-all.sh
注意:在onyarn模式下不需要启动start-all.sh(jps查看一下看到worker和master)
## 启动MRHistoryServer服务,在node1执行命令
mr-jobhistory-daemon.sh start historyserver
## 启动Spark HistoryServer服务,,在node1执行命令
/export/server/spark/sbin/start-history-server.sh
Spark HistoryServer服务WEB UI页面地址:http://node1:18080/
(六)提交测试
我们还是使用圆周率PI程序进行测试,先将圆周率PI程序提交运行在YARN上,
SPARK_HOME=/export/server/spark
$SPARK_HOME/bin/spark-submit \\
--master yarn \\
--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \\
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \\
$SPARK_HOME/examples/src/main/python/pi.py \\
10
运行完成在YARN 监控页面截图如下:
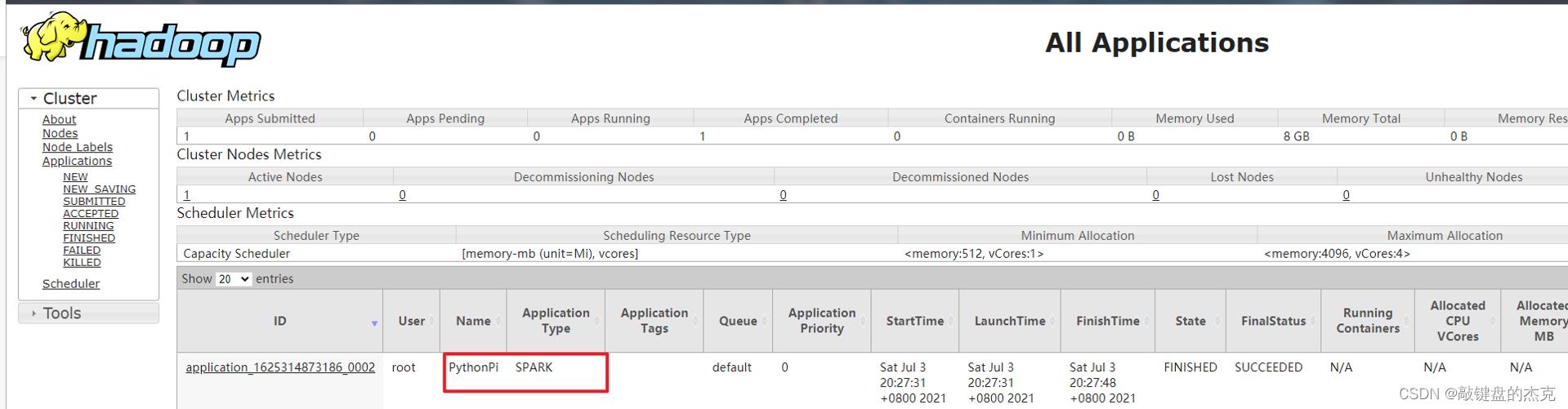
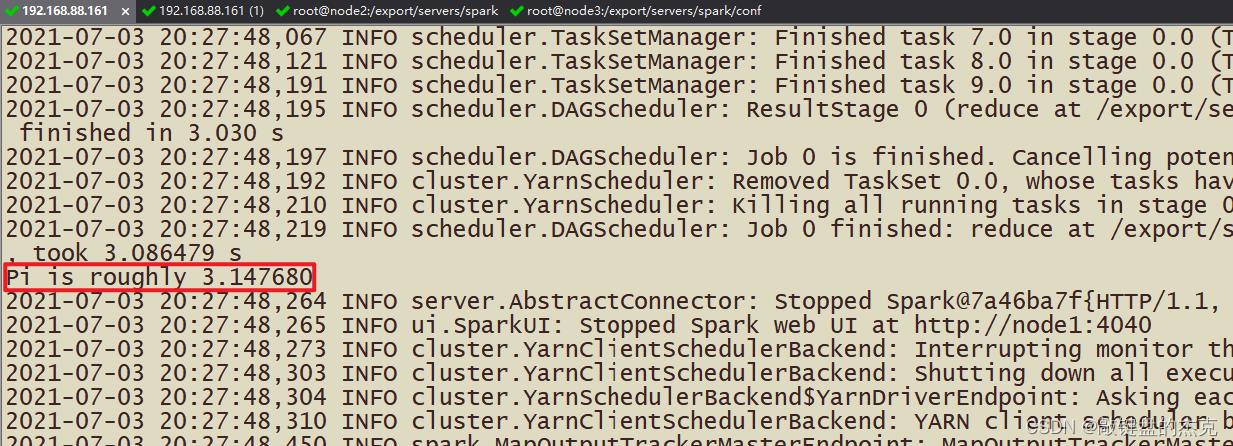
当pi应用在YARN上运行完成后,可以从8080 WEB 页面点击应用历史服务连接,查看应用运行状态信息。
大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言
在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合HBase,并且测试成功了。在之前的大数据学习系列之一 ----- Hadoop环境搭建(单机) : http://www.panchengming.com/2017/11/26/pancm55/ 中成功的搭建了Hadoop的环境,本文主要讲的是Hadoop+Spark 的环境。虽然搭建的是单机版,但是改成集群版的也相当容易,这点以后会写关于Hadoop+Spark+HBase+Hive+Zookeeper 等集群的相关说明的。
一、环境选择
1,服务器选择
本地虚拟机
操作系统:linux CentOS 7
Cpu:2核
内存:2G
硬盘:40G
2,配置选择
JDK:1.8 (jdk-8u144-linux-x64.tar.gz)
Hadoop:2.8.2 (hadoop-2.8.2.tar.gz)
Scala:2.12.2 (scala-2.12.2.tgz)
Spark: 1.6 (spark-1.6.3-bin-hadoop2.4-without-hive.tgz)
3,下载地址
官网地址:
JDK:
http://www.oracle.com/technetwork/java/javase/downloads
Hadopp:
http://www.apache.org/dyn/closer.cgi/hadoop/common
Spark:
http://spark.apache.org/downloads.html
Hive on Spark (spark集成hive的版本)
http://mirror.bit.edu.cn/apache/spark/
Scala:
http://www.scala-lang.org/download
百度云:
链接:https://pan.baidu.com/s/1geT3A8N 密码:f7jb
二、服务器的相关配置
在配置Hadoop+Spark整合之前,应该先做一下配置。
做这些配置为了方便,使用root权限。
1,更改主机名
首先更改主机名,目的是为了方便管理。
查看本机的名称
输入:
hostname 更改本机名称
输入:
hostnamectl set-hostname master注:主机名称更改之后,要重启(reboot)才会生效。
2,主机和IP做关系映射
修改hosts文件,做关系映射
输入
vim /etc/hosts添加
主机的ip 和 主机名称
192.168.219.128 master3,关闭防火墙
关闭防火墙,方便外部访问。
CentOS 7版本以下输入:
关闭防火墙
service iptables stopCentOS 7 以上的版本输入:
systemctl stop firewalld.service4,时间设置
输入:
date查看服务器时间是否一致,若不一致则更改
更改时间命令
date -s ‘MMDDhhmmYYYY.ss’三、Scala环境配置
因为Spark的配置依赖与Scala,所以先要配置Scala。
Scala的配置
1, 文件准备
将下载好的Scala文件解压
输入
tar -xvf scala-2.12.2.tgz然后移动到/opt/scala 里面
并且重命名为scala2.1
输入
mv scala-2.12.2 /opt/scala
mv scala-2.12.2 scala2.12,环境配置
编辑 /etc/profile 文件
输入:
export SCALA_HOME=/opt/scala/scala2.1
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:$PATH输入:
source /etc/profile使配置生效
输入 scala -version 查看是否安装成功

三、Spark的环境配置
1,文件准备
Spark有两种,下载的地址都给了,一种是纯净版的spark,一种是集成了hadoop以及hive的版本。本文使用的是第二种
将下载好的Spark文件解压
输入
tar -xvf spark-1.6.3-bin-hadoop2.4-without-hive.tgz然后移动到/opt/spark 里面,并重命名
输入
mv spark-1.6.3-bin-hadoop2.4-without-hive /opt/spark
mv spark-1.6.3-bin-hadoop2.4-without-hive spark1.6-hadoop2.4-hive
2,环境配置
编辑 /etc/profile 文件
输入:
export SPARK_HOME=/opt/spark/spark1.6-hadoop2.4-hive
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:$PATH
输入:
source /etc/profile使配置生效
3,更改配置文件
切换目录
输入:
cd /opt/spark/spark1.6-hadoop2.4-hive/conf4.3.1 修改 spark-env.sh
在conf目录下,修改spark-env.sh文件,如果没有 spark-env.sh 该文件,就复制spark-env.sh.template文件并重命名为spark-env.sh。
修改这个新建的spark-env.sh文件,加入配置:
export SCALA_HOME=/opt/scala/scala2.1
export JAVA_HOME=/opt/java/jdk1.8
export HADOOP_HOME=/opt/hadoop/hadoop2.8
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/opt/spark/spark1.6-hadoop2.4-hive
export SPARK_MASTER_IP=master
export SPARK_EXECUTOR_MEMORY=1G
注:上面的路径以自己的为准,SPARK_MASTER_IP为主机,SPARK_EXECUTOR_MEMORY为设置的运行内存。

五、Hadoop环境配置
Hadoop的具体配置在大数据学习系列之一 ----- Hadoop环境搭建(单机) : http://www.panchengming.com/2017/11/26/pancm55 中介绍得很详细了。所以本文就大体介绍一下。
注:具体配置以自己的为准。
1,环境变量设置
编辑 /etc/profile 文件 :
vim /etc/profile配置文件:
export HADOOP_HOME=/opt/hadoop/hadoop2.8
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH2,配置文件更改
先切换到 /home/hadoop/hadoop2.8/etc/hadoop/ 目录下
5.2.1 修改 core-site.xml
输入:
vim core-site.xml在<configuration>添加:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>5.2.2修改 hadoop-env.sh
输入:
vim hadoop-env.sh将${JAVA_HOME} 修改为自己的JDK路径
export JAVA_HOME=${JAVA_HOME}修改为:
export JAVA_HOME=/home/java/jdk1.85.2.3修改 hdfs-site.xml
输入:
vim hdfs-site.xml在<configuration>添加:
<property>
<name>dfs.name.dir</name>
<value>/root/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>need not permissions</description>
</property>5.2.4 修改mapred-site.xml
如果没有 mapred-site.xml 该文件,就复制mapred-site.xml.template文件并重命名为mapred-site.xml。
输入:
vim mapred-site.xml修改这个新建的mapred-site.xml文件,在<configuration>节点内加入配置:
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/root/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>3,Hadoop启动
注:如果已经成功配置了就不用了
启动之前需要先格式化
切换到/home/hadoop/hadoop2.8/bin目录下
输入:
./hadoop namenode -format格式化成功后,再切换到/home/hadoop/hadoop2.8/sbin目录下
启动hdfs和yarn
输入:
start-dfs.sh
start-yarn.sh启动成功后,输入jsp查看是否启动成功
在浏览器输入 ip+8088 和ip +50070 界面查看是否能访问
能正确访问则启动成功
六、Spark启动
启动spark要确保hadoop已经成功启动
首先使用jps命令查看启动的程序
在成功启动spark之后,再使用jps命令查看
切换到Spark目录下
输入:
cd /opt/spark/spark1.6-hadoop2.4-hive/sbin然后启动Spark
输入:
start-all.sh
然后在浏览器输入
http://192.168.219.128:8080/
正确显示该界面,则启动成功

注:如果spark成功启动,但是无法访问界面,首先检查防火墙是否关闭,然后在使用jps查看进程,如果都没问题的,一般就可以访问界面。如果还是不行,那么检查hadoop、scala、spark的配置。
那么本文到此结束,谢谢阅读!
如果觉得不错,可以点击一下赞或推荐。
版权声明:
作者:虚无境
博客园出处:http://www.cnblogs.com/xuwujing
CSDN出处:http://blog.csdn.net/qazwsxpcm
个人博客出处:http://www.panchengming.com
原创不易,转载请标明出处,谢谢!
以上是关于大数据之Spark环境搭建的主要内容,如果未能解决你的问题,请参考以下文章