ChatGPT是如何回答问题的?它与搜索引擎的区别在哪里?
Posted ·a柒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ChatGPT是如何回答问题的?它与搜索引擎的区别在哪里?相关的知识,希望对你有一定的参考价值。
在阅读本篇文章,我推荐大家先观看下面链接的视频,而本文章的内容基本上视频都有提及,只不过在此做一下进一步的知识整理和总结,方便大家对相关知识的回顾。同时也建议大家关注一下视频Up,他的视频极具深度,能够带给大家新的启发和思考。
 https://www.bilibili.com/video/BV1MY4y1R7EN/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=fe81b6bdf8b81519f6d7d59ca0843546
https://www.bilibili.com/video/BV1MY4y1R7EN/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=fe81b6bdf8b81519f6d7d59ca0843546当今,随着人工智能技术的不断发展,自然语言处理技术也变得越来越先进。在这样的背景下,ChatGPT是一个备受关注的话题。ChatGPT是一个基于GPT-3.5架构的大型语言模型,由OpenAI开发。它具有强大的自然语言处理和对话生成能力,可以对用户提出的问题和语句进行理解和回答,同时还能生成高质量的文本。ChatGPT在各种领域的应用潜力巨大,如教育、娱乐、医疗、金融等。它可以与人类进行自然而流畅的对话,并根据用户的需求提供个性化的服务和信息。而对于这样一个足以影响整个世界的技术却没有对国内开发,通用媒体又缺少相应的知识,Up主YJango特意做了一期视频,向普通大众全面科普了ChatGPT的原理,并提供了一个独特的视角,让大家意识到它为何如此重要,让那些没有机会了解这件事的人也能应对即将到来的变革!所以还希望大家能够观看视频,一键三连!
抛出问题
1.ChatGPT是如何回答问题的?
2.它是怎么被制造的,为什么它不是搜索引擎?
3.它有哪些惊人能力,为什么它不只是聊天机器人
4.它将给社会带来什么样的冲击(视频中有介绍)
5.我们该如何维持未来的竞争力(视频中有介绍)
1.GPT的底层原理
1.1实质功能
四个字概括:单字节龙
什么是单字节龙:给它任意长的上文,它会用【自己的模型】生成任意长的下一个字。
那它又是如何回答长文的呢?
其实道理很简单,它是通过生成了下一个字后于之前的字继续组成上文,继续根据自己的模型生成下一个字,不断重复,就可以生成任意长的下文。 该过程也称为『自回归生成』。
影响GPT生成的回答主要有两个因素:『上文』和『模型』模型相当于ChatGPT的大脑,即:把不同的上文送给不同的模型,由于思考方式不同,因此得到的结果也不同。
为了让ChatGPT生成我们想要的结果,而不是随便胡乱生成,因此就需要对ChatGPT的模型进行训练。
1.2训练方式
简单概括:遵照所给的『学习材料』来做『单字节龙』,并不断的调整模型。
举个例子:
一个没有训练的GPT和一个以《床前明月光》作为』学习材料『训练过的GPT,给到相同的上文:床前。
没有训练的GPT就会随便生成:床前一双鞋...床前一个人....
训练过的GPT则会根据训练后的模型生成:床前明月光
>抛出问题:如果』学习材料『特别多,而给出的上文满足多个材料,该如何生成?答案是抽样!
举个例子:
同时有『白日依山尽『和』白日何短短『,那给出上文:白日,下一个字究竟『依』还是『何』,将会进行抽样。
其实说到这里,ChatGPT就已经有能力回答问题了。因为提问和回答都是文字,那么就可以将提问和回答组成一个『回答范例』来给到GPT进行学习,这样GPT的回答会更加的标准规范。
>抛出问题:提问-回答的组合成千上问,因人而异,难道要要将所有的组合都作为『学习材料』交给ChatGPT来学习吗?
其实并不需要,因为训练的目的并不是记忆,而是学习。以『单字接龙』的方式来训练『模型』,并仅仅是让模型记住某一个『提问-回答组合』,而是去学习『提问和回答的通用规律』,这样,当模型遇到没有记忆过的提问组合也能够利用所学的规律生成用户想要的回答,这种举一反三的目的也叫做:泛化。
『误区』很多人(包括我)在一开始会认为,ChatGPT会像搜索引擎一样,实在庞大的数据库中通过超高的运算速度,找到最接近的内容,然后进行一系列的比对和拼接操作得到最终的内容。ChatGPT并不具备那种搜索能力,因为在训练过程中,『学习材料』(也就是我们说的数据库)并没有保存在ChatGPT的模型中,学习材料的作用只是为了调整模型,以得到一个更优质的通用模型,为的就是能处理『未被数据库记忆的情况』,所有结果都是通过『所学的模型』根据上文进行单字节龙,逐字生成。因此,ChatGPT也被称为生成模型。
1.3长板
生成模式于搜索引擎非常不同,搜索引擎无法给出『未被记忆的数据』(数据库中没有的数据),但生成语言模型可以,还能创造不存在的文本,这就是生成模型的长板。
1.4短板
生成模型同样有着搜索引擎没有的短板-『混淆记忆』和『无中生有』。
主要由两个原因导致:
首先,搜索引擎不会混淆记忆,但是它有可能。为了应对未被记忆的的情况,它会学习语言单位(如单词、短语、句子等)之间的规律,用学到的规律生成答案,这也意味着,如果出现了『实际不符但却碰巧符合同一规律的内容』,模型就非常有可能混淆它,ChatGPT就有可能对不存在的内容进行『合乎规律的混合捏造』。
举个例子:
问:为什么M78星云科技那么发达,奥特曼为什么不侵略地球?
ChatGPT:M78星云科技是奥特星人所掌握的高科技,他们是保护和平的战士,以保护宇宙中的各种生命形式为使命。他们不会侵略地球,而是会派遣奥特曼来保护地球不受外来的威胁。
这也是为什么很多用户在问它一些事实性问题时会发现它在胡说八道的原因之一。
另一个原因就是,ChatGPT无法对『所记住的信息进行』增删改查,无论是ChatGPT所记忆的信息还是所学到的规律都是以同一个模型的形式表达的,因此我们无法像操作数据库一样对这些内容进行增删改查。
这会导致两个问题:
- 第一:由于我们很难理解它所构建的规律,又无法查看它记住了什么,学到了什么,只能通过多次的提问和猜测来评估它的所及所学,其决策缺乏可解释性,这难免在使用时会带来一定的安全风险。
- 第二:由于只能通过再次调整模型(即再次训练)来增加、删除和修改它的所及所需学,这难免在更新时会降低效率。
就比如它回答的奥特曼的问题,只有通过『奥特曼是虚构的....』等学习材料来调整模型,但是这样的调整如何、是否会导致一些其他的问题,又只能通过多次提问来评估,容易顾此失彼,效率低下。
还有个特点是:ChatGPT高度依赖数据,也就是所说的学习材料,想要让ChatGPT能够应对无数未遇见情况,就必须提供足够多的、种类足够丰富、质量足够高的学习材料,否则它将无法学到通用规律,给出的回答以偏概全。此外,ChatGPT存在的胡编和混淆也需要通过学习资料来修正,由此可见学习材料的重要性。
1.5总结:
- ChatGPT的实质功能是单字接龙
- 长文由单字接龙的自回归所生成
- 通过提前训练才能让它生成人们想要的问答
- 训练方式是让它按照问答范例来做单字接龙
- 这样训练是为了让它学会「能举一反三的规律」
- 缺点是可能混淆记忆,无法直接查看和更新所学,且高度依赖学习材料
以上都只是GPT的原理。而ChatGPT则是在GPT的基础上被扩展至超大规模,再加以人类的引导的产物。
2.ChatGPT的实现
三大学习阶段
机器理解人类语言的一大难点在于:同一个意思,可以有不同的表达方式,可以用一个词或者是一段描述。而同一个表达,在不同的语境中又有着不同的含义。
对于这个问题,需要通过三个学习阶段来实现。
第一阶段:开卷有益-无监督学习
该阶段,需要让机器学习各种『语义关系』和『语法规律』,以便来明白『哪些表达实际上是同一个意思』。对此ChatGPT的办法是:让模型看到尽可能多、尽可能丰富的『语言范例』(也就是学习材料),使其能有更多机会构建出能举一反三的语言规律,来应对无数『从未见过的语言』。
GPT中的G代表Generative-生成,T代表Transform-模型结构,P-Pre-training-预先学习,而这里的P就是指的第一阶段的无监督学习阶段。
| OpenAI | 学习材料 | 参数 |
| GPT-1 | 5GB | 1.17亿 |
| GPT-2 | 40GB | 15亿 |
| GPT-3 | 45TB | 1750亿 |
第二阶段:模板规范-有监督学习
在学习了容量如此大的学习材料后,ChatGPT的回答将不受约束,因为它学的太多了,它就像一个脑容量超级大的鹦鹉,听过了海量的电视界面,会不受控制的乱说,丑话、脏话全部有可能蹦出来,难以与人类交流,那么该如何解决这个问题呢?使用『对话模板』去矫正它在『开卷有益』时所学到的不规范习惯。具体做法是:不再用随便的互联网文本,而是把人工专门写好的『优质对话范例』给开卷有益后的ChatGPT-3,让它再去做单字节龙,从而学习『如何组织符合人类规范的回答』。
例如:ChatGPT无法联网,当用户问到最新新文时,就不应该让它接着去胡编乱造,而是直接回答『不知道该信息』。
当用户提问本身就存在错误时,也不应该让它胡编乱造,而是指出错误。
当提问『xxxx是不是』的时候,让它不单单只回答是或者不是,还要加以原因进行解释。因此还要提供提问-回答-原因的模型进行训练。
还有相关非法、有害等相关内容,也应该做出相应的防范。
但是完全使用模板化去训练GPT,这会导致ChatGPT的回答过于模板化,从而成为一个高度模板化的复刻机器,从而失去了创新性。所谓:科文有标准答案,但是人文领域的问题是没有标准答案。我们也希望ChatGPT可以跳出模板,提供仍符合人类对话模式和价值取向的创新性回答。
>抛出问题:那么如何在维持人类对话模式和价值取向的前提下,提高ChatGPT的创新性呢?
第三阶段:创意引导-强化学习
该阶段,不在要求它按照我们提供的对话范例做单字接龙,而是直接向它提问,再让它自由回答,如果回答的秒,就给予奖励,如果回答的不佳,就降低奖励。利用人类评分去调整ChatGPT的模型。在这一阶段不会使用现有的模板去限制它,又可以引导它创造出符合人类认可的回答。
ChatGPT就是在ChatGPT3.5的基础上先后经历了开卷有益-无监督学习、模板规范-监督学习、创意引导-强化学习三个阶段的训练后得到的生成语言模型。可以说ChatGPT把机器学习的几大训练模式都用到了
总结:
ChatGPT的三个训练阶段:
『开卷有益』阶段:让ChatGPT对海量互联网文本」做单字接龙,以扩充模型的词汇量、语言知识、世界的信息与知识。使ChatGPT从『哑巴鹦鹉』变成『脑容量超级大的懂王鹦鹉。
『模板规范』阶段:让ChatGPT对「优质对话范例]做单字接龙,以规范回答的对话模式和对话内容。使ChatGPT变成"懂规矩的博学鹦鹉『
『创意引导』阶段:让ChatGPT根据[人类对它生成答案的好坏评分]来调节模型,以引导它生成人类认可的创意回答。使ChatGPT变成『既懂规矩又会试探的博学鹦鹉』。
此外:当单字节龙模型的规模达到一定程度后,就会涌现出『理解指令』『理解例子』『思维链』的能力
>附文
涌现现象
(这段科普来自微博博主木遥):这是过去两年来人们最大的发现之一。只要神经网络的复杂性和训练样本的多样性超过一定规模,就会有抽象的推理结构在神经网络里突然自发涌现出来。这个过程像所有的复杂性系统一样是非线性的。去年十月份 Google 的一篇论文 Emergent Abilities of Large Language Models 对这个现象做了很好的综述。简单地说:量变导致质变。
(另一方面,由于涌现是非线性的,这也使得要预测它的发展极为困难。如果今天的模型暂时还不能解决某一类任务,你无法估计模型要再扩张多少才能涌现出新的能力去解决这些任务。可能永远不行,可能下一个阈值会超出硬件的能力极限,可能你需要的全新的网络架构。所有这些问题都无法用简单的外推来回答。这种非线性也是人工智能波浪形发展的根源:你会在好几年里觉得一事无成(比如前几年大量声音说大模型已死),接着忽然迎来一个剧烈爆发的增长,然后可能又进入下一个等待期。
但重点在于,今天的大语言模型已经在很多方向上确定无疑地迈过了某个重要的阈值。这使得整个关于模型能力的认知都需要迅速重估。最典型的就是 in-context learning:今天你可以给 AI 看几个例子,然后它就在这些例子的基础上举一反三,针对没见过的样本做出正确的推理,并且这个过程中【不需要】重新训练模型权重。——人们暂时还不知道能冲破多少此前一直卡着的瓶颈,但这个飞跃本身已经打开了一片新天地。
人类自己的进化史上语言的诞生被认为是个重要的节点,这意味着大脑的复杂程度决定性地超越了此前的近亲,然后语言又反过来给大脑的发育带来巨大的压力,迫使它走上了一条所有其他动物都没走过的演化道路。
今天很可能是 AI 演化史上的类似时刻。
ChatGPT爆火!它如何回答 Python 相关问题
近期OpenAI发布了全新的聊天机器人模型ChatGPT,没想到一经上线,就因其高质量的回答、高效获取信息的方式、以及上瘾式的交互体验而迅速出圈。
不少体验过的人都惊呼,ChatGPT可能一举消灭记者、程序员和搜索引擎。就连马斯克也忍不住发推表示,ChatGPT厉害得吓人,我们距离危险而强大的AI不远了。
ChatGPT的交互界面简洁,只有一个输入框,AI将根据输入内容进行回复,并允许在一个语境下持续聊天。笔者尝试问了ChatGPT 十个 Python 相关问题,并与之前发布的文章作为对比参考。
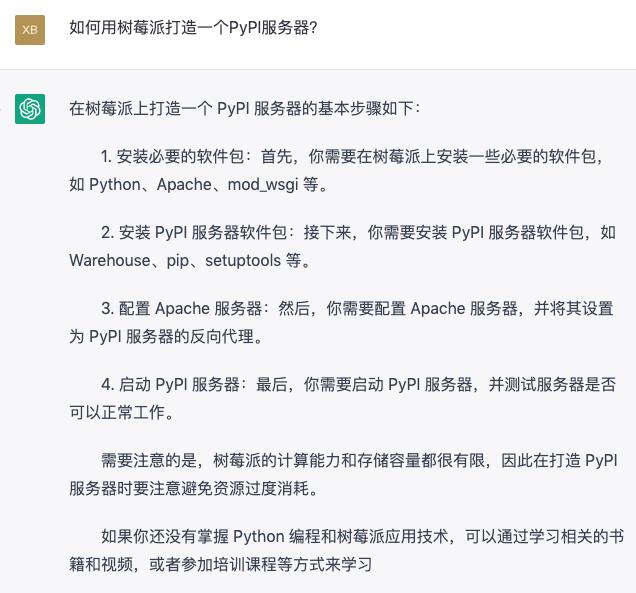
一、如何用树莓派打造一个PyPI服务器?
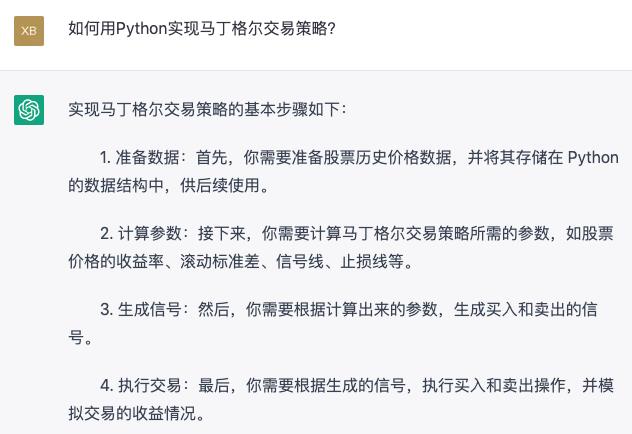
二、如何用Python实现马丁格尔交易策略?
三、如何用机器学习方法预测bilibili美股股价走势?

四、写一段Python代码,通过雅虎财经获取股票数据

五、Python 3.10 有哪些新特性?

六、写一段Python代码,用蒙特卡洛方法模拟预测股票收益

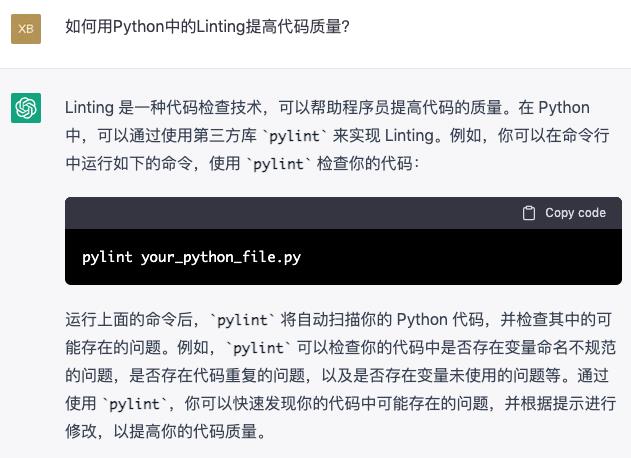
七、如何用Python中的Linting提高代码质量
八、写一段Python代码,通过web3.py存取以太坊
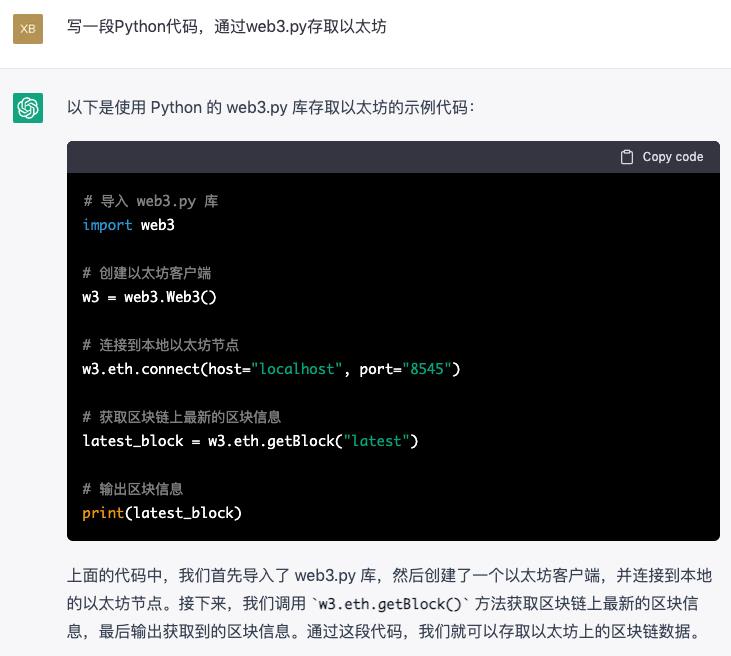
《通过 web3.py 用 Python 存取 Ethereum》
九、用20行Python代码实现加密通信


十、如何熟练掌握Python编程语言?Python开发工程师的未来发展前景如何?


- 点击下方阅读原文加入社区会员 -
以上是关于ChatGPT是如何回答问题的?它与搜索引擎的区别在哪里?的主要内容,如果未能解决你的问题,请参考以下文章