处理自动化多进程执行自动化时,企业微信报告通知触发多条
Posted 七月的小尾巴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了处理自动化多进程执行自动化时,企业微信报告通知触发多条相关的知识,希望对你有一定的参考价值。
前言
原先开源的框架中,多进程执行自动化脚本时,如假设我程序中开启了三个进程,执行用例为100条,此时企业微信通知,会随着所设置的进程数量发送三次,如下截图,实际我自动化场景只是跑了一次,但是执行完成时,给我推送了三条通知
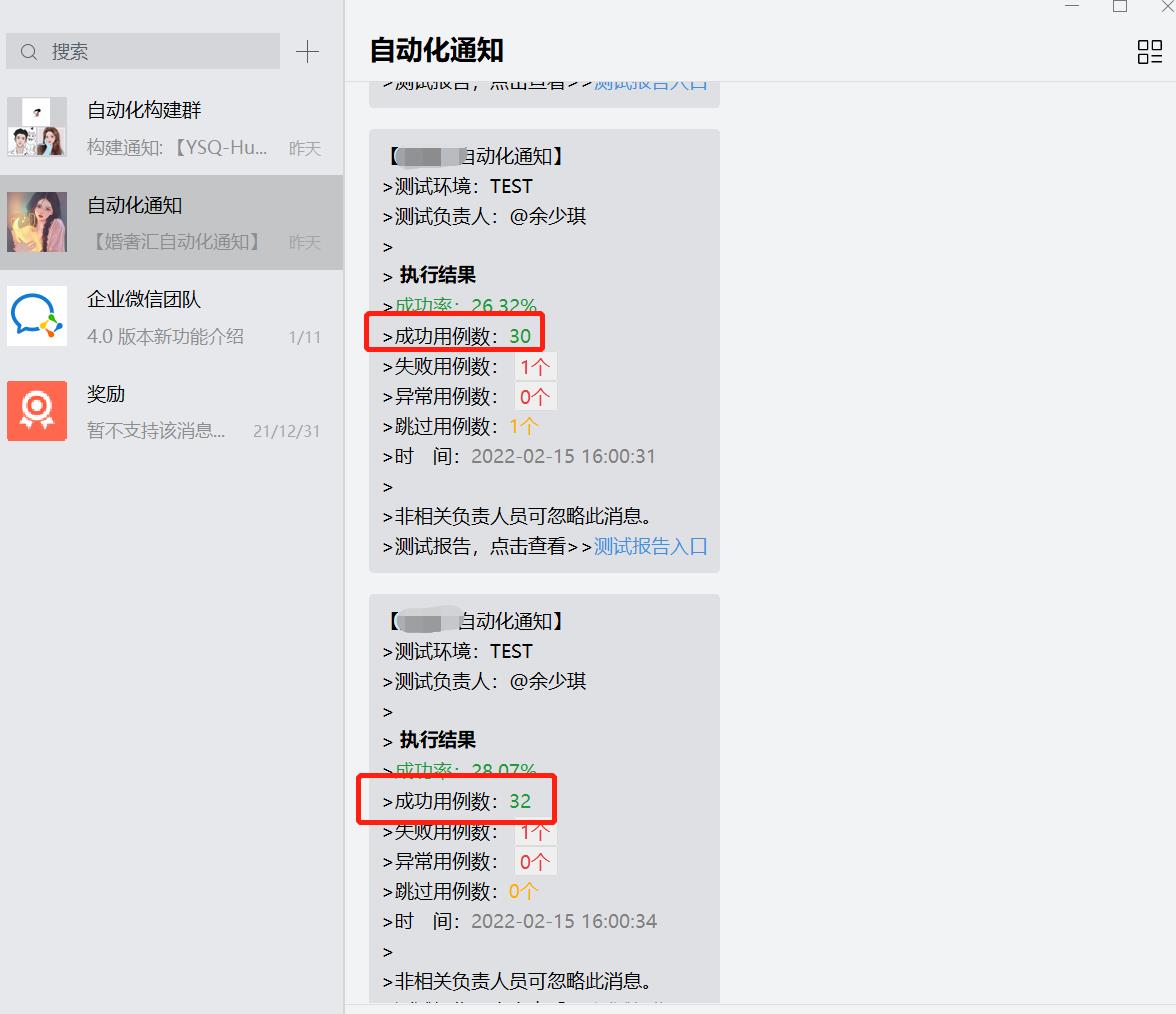
这里我希望哪怕是多进程执行,但是每次触发jenkins任务时,通知只需要发送一次,并且汇总整个自动化的执行情况。
处理思路
这里的处理思路,我采用的是存储到redis缓存中:
1、首先程序执行之前,使用pytest提供的钩子函数 pytest_runtest_makereport,收集每次用例的执行情况
2、每次收集的用例,存入redis缓存中
3、程序执行完成,读取redis中的缓存数据,触发企业微信通知,发送报告内容
4、每次触发自动化任务时,初始化缓存数据
处理代码
既然有思路之后,下面我们来封装所需要的代码,首先是redis读取的封装,创建一个命名为
RedisContorl.py 的文件
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2022/1/11 18:35
# @Author : 余少琪
import redis
class RedisHandler:
""" redis 缓存读取封装 """
def __init__(self):
self.host = ''
self.port = 6379
self.db = 0
self.password = ''
self.charset = 'UTF-8'
self.redis = redis.Redis(self.host, port=self.port, password=self.password, decode_responses=True, db=self.db)
def set_string(self, name: str, value, ex=None, px=None, nx=False, xx=False) -> None:
"""
缓存中写入 str(单个)
:param name: 缓存名称
:param value: 缓存值
:param ex: 过期时间(秒)
:param px: 过期时间(毫秒)
:param nx: 如果设置为True,则只有name不存在时,当前set操作才执行(新增)
:param xx: 如果设置为True,则只有name存在时,当前set操作才执行(修改)
:return:
"""
self.redis.set(name, value, ex=ex, px=px, nx=nx, xx=xx)
def incr(self, key):
"""
使用 incr 方法,处理并发问题
当 key 不存在时,则会先初始为 0, 每次调用,则会 +1
:return:
"""
self.redis.incr(key)
def get_key(self, name) -> str:
"""
读取缓存
:param name:
:return:
"""
return self.redis.get(name)
def set_many(self, *args, **kwargs):
"""
批量设置
支持如下方式批量设置缓存
eg: set_many('k1': 'v1', 'k2': 'v2')
set_many(k1="v1", k2="v2")
:return:
"""
self.redis.mset(*args, **kwargs)
def get_many(self, *args):
"""获取多个值"""
results = self.redis.mget(*args)
return results
def del_all_cache(self):
"""清理所有现在的数据"""
for key in self.redis.keys():
self.del_cache(key)
def del_cache(self, name):
"""
删除缓存
:param name:
:return:
"""
self.redis.delete(name)
if __name__ == '__main__':
pass
封装好读取缓存的方法之后,我们在单独创建一个名称为 CaseCountCountrol.py
这个方法的作用主要是:
1、每次执行脚本之前,清除上次执行脚本的缓存数据
2、统计每次执行任务的数量情况:通过、失败、跳过数量
3、统计用例成功率以及总数
from tools.redisControl import RedisHandler
class CaseCountName:
ERROR: str = "errorCount"
FAILED: str = "failedCount"
PASSED: str = "passedCount"
SKIP: str = "skippedCount"
TOTAL: str = 'totalCount'
class CaseCount:
"""
redis 缓存统计用例执行情况
"""
def __init__(self):
self.Redis = RedisHandler()
def init_process(self):
"""
初始化进度、总数、成功数、失败数、
:return:
"""
self.Redis.set_string(CaseCountName.SKIP, 0)
self.Redis.set_string(CaseCountName.PASSED, 0)
self.Redis.set_string(CaseCountName.FAILED, 0)
self.Redis.set_string(CaseCountName.TOTAL, 0)
def failCount(self) -> int:
"""失败总数"""
return int(self.Redis.get_key(CaseCountName.FAILED))
def passedCount(self) -> int:
"""通过用例数"""
return int(self.Redis.get_key(CaseCountName.PASSED))
def skipCount(self) -> int:
"""跳过用例数"""
return int(self.Redis.get_key(CaseCountName.SKIP))
def totalCount(self) -> int:
"""用例总数"""
return int(self.Redis.get_key(CaseCountName.TOTAL))
def passRate(self):
"""用例成功率"""
# 四舍五入,保留2位小数
try:
passRate = round((self.passedCount() + self.skipCount()) / self.totalCount() * 100, 2)
return passRate
except ZeroDivisionError:
raise "执行失败,程序中未检测到用例执行数量."
def totalCountAdd(self):
"""
用例执行完成,计算用例总数
:return:
"""
totalCount = self.Redis.get_many(CaseCountName.PASSED,
CaseCountName.FAILED, CaseCountName.SKIP, CaseCountName.ERROR)
num = 0
for i in totalCount:
num += int(i)
# redis中写入总数
RedisHandler().set_string(CaseCountName.TOTAL, num)
这两个方法都创建好之后,我们在pytest的 conftest.py 中封装 pytest_runtest_makereport的钩子函数
@pytest.hookimpl(hookwrapper=True, tryfirst=True)
def pytest_runtest_makereport(item, call):
"""统计用例执行数量"""
# 获取钩子方法的调用结果
out = yield
# 从钩子方法的调用结果中获取测试报告
report = out.get_result()
# 执行一个用例的时候,该钩子函数会调用三次,因为有三个阶段,这里指定call阶段即可
if report.when == 'call':
# 将用例执行情况数量写入缓存中
# outcome: "Literal['passed', 'failed', 'skipped']"
if report.outcome == 'passed':
RedisHandler().incr(CaseCountName.PASSED)
if report.outcome == 'failed':
RedisHandler().incr(CaseCountName.FAILED)
# 跳过的用例,不会走call,直接统计teardown
if report.when == "setup":
if report.outcome == 'skipped':
RedisHandler().incr(CaseCountName.SKIP)
# 程序执行结束之后,将所有用例数量汇总
CaseCount().totalCountAdd()
这里在封装的时候,有踩一个坑,因为执行一个用例的时候,该钩子函数会调用三次,因为有三个阶段,分别是 setup、 call、 teardown ,原先我只统计了 call 阶段,刚好碰巧我在用例中是有 skip 跳过的用例,统计的时候,跳过的用例没有统计上。
通过 debug 调试中发现,skip 的用例,他只有 setup、 teardown这两个阶段,所以 skipped 我是通过 setup 这个阶段判断的。
代码都封装好之后,记得在你们主程序中调用 CaseCountCountrol.py 文件中的 init_process() 方法,在程序之前,将所有缓存数据初始化
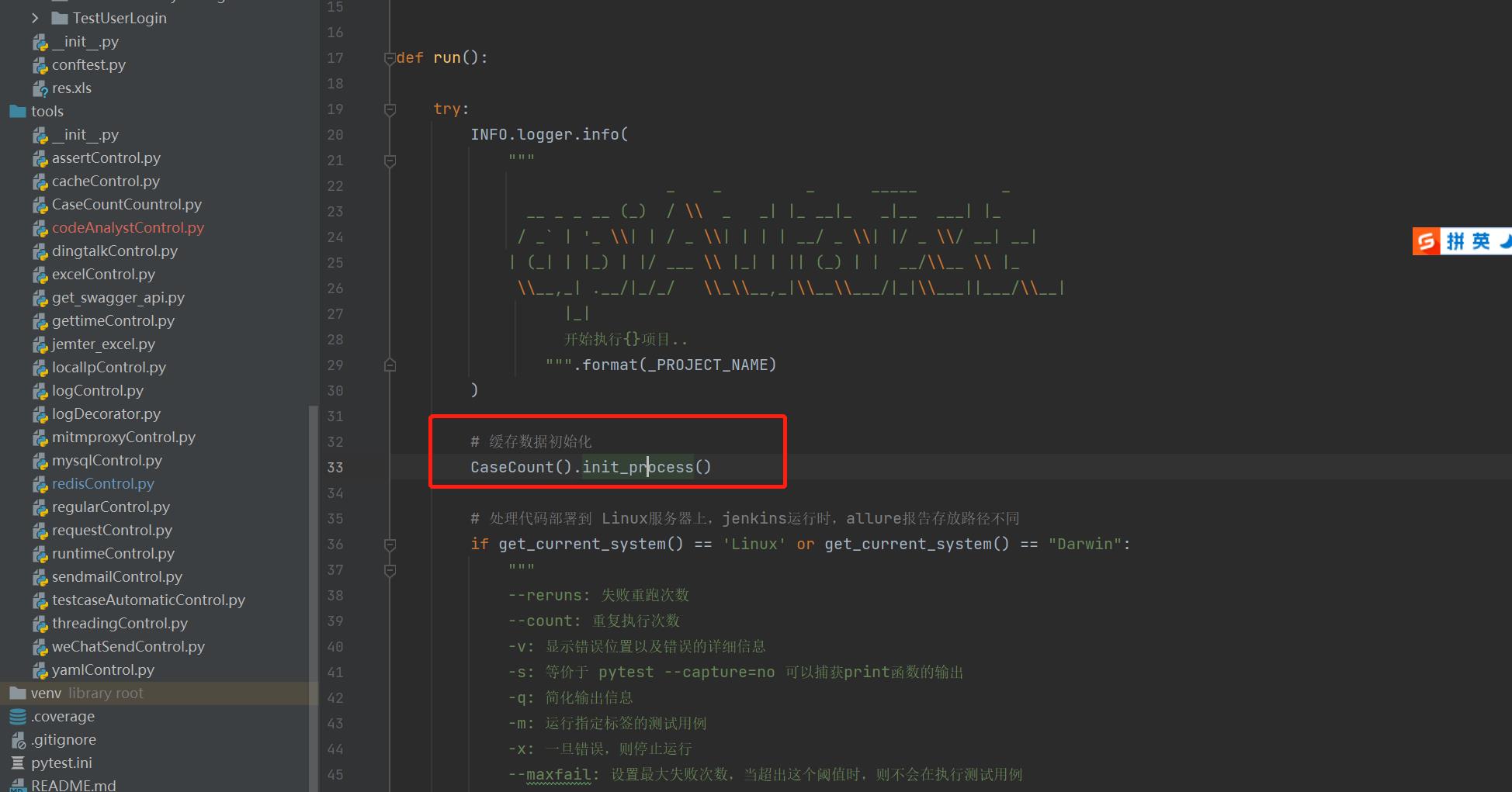
缓存写入避坑
这里之前我看到有些人,他们虽然将执行结果写入缓存了,这个缓存思路确认没错,但是他们每次执行用例的累计数量,是通过python程序中新增的。比如我 passCount 现在是1个,然后新增通过数时,有些朋友是直接在python passCount += 1,直接在python中计算通过数。
这个方式如果在单进程情况下,是没有问题的,但是如果是多进程时,会出现资源竞争的情况,导致最终统计的用例数会小于实际的用例数量。需要使用redis提供的 incr方法处理。
以上是关于处理自动化多进程执行自动化时,企业微信报告通知触发多条的主要内容,如果未能解决你的问题,请参考以下文章