《从0开始学大数据》学习后感
Posted 量子智能龙哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《从0开始学大数据》学习后感相关的知识,希望对你有一定的参考价值。
《从0开始学大数据》学习后感
- 方法论与哲学
- 大数据发展历史
- 分布式计算的核心思想——移动计算而非移动数据
- 大数据系统与大型网站系统设计思路的差异
- 从RAID到HDFS(存储)
- 作为计算模型的MR
- 为什么 HDFS 是系统,而 MapReduce 和 Yarn 则是框架?
- 从Hive-MR看数据仓库的局限与novel
- Spark到底为什么快
- 各个组件的在生态中的位置
- Lambda架构与大数据平台
- 大数据与物联网
方法论与哲学
了解来龙去脉形成思维体系,为什么是A而不是B?
当我写这篇文章的时候,心情比较急躁,也可能是焦虑。我同时想到了这句话

回想自己学习技术的时候,更多地是急躁的专注于手段而非目的(沉迷于工具忘记了目的是一件比较悲催的事情),没有去思考背后的原因是什么而是在讲XXX NB!没有形成一个自己的学习的模型。就像学了大数据没有从学科技术的大图景上去了解大数据发展的脉络只是将学习当做众多细节的背诵题。这个问题不仅仅在学习技术上有所体现,生活上的一些地方也有所体现。学习知识去默默的接受知识而没有自己的思考。
能够觉悟到这一点归功于考研一年多的关于数学的学习经验。现在看来可能归功于龙哥的思考题与吴金闪老师的概念地图。我不禁思考一个问题:技术迭代如此之快,互联网大厂的轮子早就造好了我学了这些东西(细节背诵题)有什么用?换一套知识又得重新学习!自己搭建一套去和大厂抗衡?简直是找死!读了专栏之后我也进行了一些反思,我目前认为学习就是为了学习解决问题的思维体系然后去应用。当然在这其中当然要问技术为什么会是现在这个样子。
具体的,给自己定一个原则就是以后在学习其他的技术或者是算法的时候要问自己以下的问题。思考是痛苦的,但是不去思考我相当于27岁死亡80岁入葬。
1.解决了什么问题?
2.核心的思路什么?
3.关键的细节是什么?
这个学习的模型来自于李老师专栏以下是专栏原文:
很多时候,我们不是不够努力,可是如果方向错了,再多努力似乎也没有用。阿里有句话说的是“方向对了,路就不怕远”,雷军也说过“不要用你战术上的勤奋,掩盖你战略上的懒惰”。这两句话都是说,要找好方向、找准机会,不要为了努力而努力,要为了目标和价值而努力。而王兴则更加直言不讳:“很多人为了放弃思考,什么事情都干得出来”。
其实我是希望你在学习大数据的时候,不要仅局限在大数据技术这个领域,能够用更开阔的视野和角度去看待大数据、去理解大数据。这样一方面可以更好地学习大数据技术本身,另一方面也可以把以前的知识都融会贯通起来。
计算机知识更新迭代非常快速,如果你只是什么技术新就学什么,或者什么热门学什么,就会处于一种永远在学习,永远都学不完的境地。前一阵子有个闹得沸沸扬扬的事件,有个程序员到 GitHub 上给一个国外的开源软件提了个 Issue“不要再更新了,老子学不动了”,就是一个典型例子。
如果这些知识点对于你而言都是孤立的,新知识真的就是新的知识,你无法触类旁通,无法利用过往的知识体系去快速理解这些新知识,进而掌握这些新知识。你不但学得累,就算学完了,忘得也快。
所以不要纠结在仅仅学习一些新的技术和知识点上了,构建起你的知识和思维体系,不管任何新技术出现,都能够快速容纳到你的知识和思维体系里面。这样你非但不会惧怕新技术、新知识,反而会更加渴望,因为你需要这些新知识让你的知识和思维体系更加完善。
我在学习新知识的时候会遵循一个5-20-2 法则,用 5 分钟的时间了解这个新知识的特点、应用场景、要解决的问题;用 20 分钟理解它的主要设计原理、核心思想和思路;再花 2 个小时看关键的设计细节,尝试使用或者做一个 demo。
抽象能力
老实说和上面的方法论有点相关但是还是记录下来。
以下是原文:
这种洞察力就是来源于他们对事物的抽象能力,虽然我不知道这种能力缘何而来,但是见识了这种能力以后,我也非常渴望拥有对事物的抽象能力。所以在遇到问题的时候,我就会停下来思考:这个问题为什么会出现,它揭示出来背后的规律是什么,我应该如何做。
从MR-Spark看产品思维
这里有一条关于问题的定律分享给你:我们常常意识不到问题的存在,直到有人解决了这些问题。一个事实就是当时人们认为大数据计算就是Hadoop-MR的样子直到Spark的出现。也正如当时iphone出现之前人们认为手机就应该是诺基亚的样子。
当你去询问人们有什么问题需要解决,有什么需求需要被满足的时候,他们往往自己也不知道自己想要什么,常常言不由衷。但是如果你真正解决了他们的问题,他们就会恍然大悟:啊,这才是我真正想要的,以前那些统统都是“垃圾”,我早就想要这样的东西(功能)了。
所以顶尖的产品大师(问题解决专家),并不会拿着个小本本四处去做需求调研,问人们想要什么。而是在旁边默默观察人们是如何使用产品(解决问题)的,然后思考更好的产品体验(解决问题的办法)是什么。最后当他拿出新的产品设计(解决方案)的时候,人们就会视他为知己:你最懂我的需求(我最懂你的设计)。
乔布斯是这样的大师,Spark 的作者马铁也是这样的专家。这个让我想起了李沐老师提到的novelty的例子,不要以为看到了结果觉得这个比较简单,但是当时就是没有人想出来,这就是一种novel。
我们在自己的工作中,作为一个不是顶尖大师的产品经理或工程师,如何做到既不自以为是,又能逐渐摆脱平庸,进而慢慢向大师的方向靠近呢?
有个技巧可以在工作中慢慢练习:不要直接提出你的问题和方案,不要直接说“你的需求是什么?”“我这里有个方案你看一下”。
直向曲中求,对于复杂的问题,越是直截了当越是得不到答案。迂回曲折地提出问题,一起思考问题背后的规律,才能逐渐发现问题的本质。通过这种方式,既能达成共识,不会有违常识,又可能产生洞见,使产品和方案呈现闪光点。
你觉得前一个版本最有意思(最有价值)的功能是什么?
你觉得我们这个版本应该优先关注哪个方面?
你觉得为什么有些用户在下单以后没有支付?
模式思维
知名大厂的大数据平台真的是大同小异,他们根据各自场景和技术栈的不同,虽然在大数据产品选型和架构细节上略有调整,但整体思路基本上都是一样的。
同一类问题的解决方案通常也是相似的。一个解决方案可以解决重复出现的同类问题,这种解决方案就叫作模式。模式几乎是无处不在的,一旦一个解决方案被证明是行之有效的,就会被重复尝试解决同类的问题。
对于有志于成为架构师的工程师来说,一方面当然是提高自己的编程水平,另一方面也可以多看看各种架构设计文档,多去参加一些架构师技术大会。在我看来,编程需要天分;而架构设计,真的是孰能生巧。
大数据发展历史
吴军老师在自己的专栏《科技史纲60讲》中找到了解释世界的两大线索,能量与信息。信息负责调度能量负责执行。数据是信息的一种编码而计算机信息系统就是处理数据的机器。当然包括现在的网站,数据库(数据仓库|数据湖)。大数据只是在数据的规模与维度增大之后的一种新诞生的处理数据的解决方案。
大数据起源于Google,Google的搜索引擎主要就做两件事情,一个是网页抓取,一个是索引构建,而在这个过程中,有大量的数据需要存储和计算。“三驾马车”其实就是用来解决这个问题的,一个文件系统、一个计算框架、一个数据库系统。
紧接着就是开源的实现:
1.同样是存储容量的扩展基于水平扩展的HDFS成本低效率高(并发读写)。
2.不同于传统的计算机软件系统的数据输入-计算-输出,大数据作业中移动计算的成本更加低廉所以诞生了移动计算而非移动数据的MR类计算框架。
3.刚开始计算框架使用的是Hadoop-MR框架,到了后来机器学习算法通常需要进行很多次的迭代计算,而 MapReduce 每执行一次 Map 和 Reduce 计算都需要重新启动一次作业,带来大量的无谓消耗。还有一点就是 MapReduce 主要使用磁盘作为存储介质,而 2012 年的时候,内存已经突破容量和成本限制,成为数据运行过程中主要的存储介质。Spark 一经推出,立即受到业界的追捧,并逐步替代 MapReduce 在企业应用中的地位。
…
他们的发展存在着很强的因果关系,**不要一味地说XXX技术已经过时他是个辣鸡,而是去分析背后的逻辑。**以上的发展可以总结为:1.论文奠定技术发展基石;2.业务催生技术不断突破;3.效率倒逼技术迭代更新。
分布式计算的核心思想——移动计算而非移动数据
传统的信息系统都是将数据输入然后进行计算最后输出。而到了大数据,数据移动的成本变得很大需要进行大量的磁盘IO与网络传输,这时才诞生了移动计算的思想。
以下是专栏内容:
移动程序到数据所在的地方去执行,这种技术方案其实我们并不陌生。从事 Java 开发的同学可能有过用反射的方式热加载代码执行的经验,如果这个代码是从网络其他地方传输过来的,那就是在移动计算。杀毒软件从服务器更新病毒库,然后在 Windows 内查杀病毒,也是一种移动计算(病毒库)比移动数据(Windows 可能感染病毒的程序)更划算的例子。
大数据系统与大型网站系统设计思路的差异
大型网站的思路
网站实时处理通常针对单个用户的请求操作,虽然大型网站面临大量的高并发请求,比如天猫的“双十一”活动。但是每个用户之间的请求是独立的,只要网站的分布式系统能将不同用户的不同业务请求分配到不同的服务器上,只要这些分布式的服务器之间耦合关系足够小,就可以通过添加更多的服务器去处理更多的用户请求及由此产生的用户数据。这也正是网站系统架构的核心原理。
大数据系统的思路
大数据计算处理通常针对的是网站的存量数据,也就是刚才我提到的全部用户在一段时间内请求产生的数据,这些数据之间是有大量关联的,比如购买同一个商品用户之间的关系,这是使用协同过滤进行商品推荐;比如同一件商品的历史销量走势,这是对历史数据进行统计分析。网站大数据系统要做的就是将这些统计规律和关联关系计算出来,并由此进一步改善网站的用户体验和运营决策。
从RAID到HDFS(存储)
RAID(独立磁盘冗余阵列)技术是将多块普通磁盘组成一个阵列,共同对外提供服务。主要是为了改善磁盘的存储容量、读写速度,增强磁盘的可用性和容错能力。在 RAID 之前,要使用大容量、高可用、高速访问的存储系统需要专门的存储设备,这类设备价格要比 RAID 的几块普通磁盘贵几十倍。
大数据技术主要是要解决大规模数据的计算处理问题。
HDFS事实上是RAID在集群上的使用,RAID本身是垂直伸缩(发生在一台计算机内部,但是从微观来看也是属于水平伸缩)而HDFS就是垂直伸缩。
作为计算模型的MR
以下为原文:
为什么说 MapReduce 是一种非常简单又非常强大的编程模型?
简单在于其编程模型只包含 Map 和 Reduce 两个过程,map 的主要输入是一对 <Key, Value> 值,经过 map 计算后输出一对 <Key, Value> 值;然后将相同 Key 合并,形成 <Key, Value 集合 >;再将这个 <Key, Value 集合 > 输入 reduce,经过计算输出零个或多个 <Key, Value> 对。
同时,MapReduce 又是非常强大的,不管是关系代数运算(SQL 计算),还是矩阵运算(图计算),大数据领域几乎所有的计算需求都可以通过 MapReduce 编程来实现。
为什么 HDFS 是系统,而 MapReduce 和 Yarn 则是框架?
老实说这一段文字我没有太听明白先记录下来。
以下是原文:
为什么 HDFS 是系统,而 MapReduce 和 Yarn 则是框架?
框架在架构设计上遵循一个重要的设计原则叫“依赖倒转原则”,依赖倒转原则是高层模块不能依赖低层模块,它们应该共同依赖一个抽象,这个抽象由高层模块定义,由低层模块实现。
所谓高层模块和低层模块的划分,简单说来就是在调用链上,处于前面的是高层,后面的是低层。我们以典型的 Java Web 应用举例,用户请求在到达服务器以后,最先处理用户请求的是 Java Web 容器,比如 Tomcat、Jetty 这些,通过监听 80 端口,把 HTTP 二进制流封装成 Request 对象;然后是 Spring MVC 框架,把 Request 对象里的用户参数提取出来,根据请求的 URL 分发给相应的 Model 对象处理;再然后就是我们的应用程序,负责处理用户请求,具体来看,还会分成服务层、数据持久层等。
在这个例子中,Tomcat 相对于 Spring MVC 就是高层模块,Spring MVC 相对于我们的应用程序也算是高层模块。我们看到虽然 Tomcat 会调用 Spring MVC,因为 Tomcat 要把 Request 交给 Spring MVC 处理,但是 Tomcat 并没有依赖 Spring MVC,Tomcat 的代码里不可能有任何一行关于 Spring MVC 的代码。
那么,Tomcat 如何做到不依赖 Spring MVC,却可以调用 Spring MVC?如果你不了解框架的一般设计方法,这里还是会感到有点小小的神奇是不是?
秘诀就是 Tomcat 和 Spring MVC 都依赖 J2EE 规范,Spring MVC 实现了 J2EE 规范的 HttpServlet 抽象类,即 DispatcherServlet,并配置在 web.xml 中。这样,Tomcat 就可以调用 DispatcherServlet 处理用户发来的请求。
同样 Spring MVC 也不需要依赖我们写的 Java 代码,而是通过依赖 Spring MVC 的配置文件或者 Annotation 这样的抽象,来调用我们的 Java 代码。
所以,Tomcat 或者 Spring MVC 都可以称作是框架,它们都遵循依赖倒转原则。
现在我们再回到 MapReduce 和 Yarn。实现 MapReduce 编程接口、遵循 MapReduce 编程规范就可以被 MapReduce 框架调用,在分布式集群中计算大规模数据;实现了 Yarn 的接口规范,比如 Hadoop 2 的 MapReduce,就可以被 Yarn 调度管理,统一安排服务器资源。所以说,MapReduce 和 Yarn 都是框架。
相反地,HDFS 就不是框架,使用 HDFS 就是直接调用 HDFS 提供的 API 接口,HDFS 作为底层模块被直接依赖。
从Hive-MR看数据仓库的局限与novel
以下问原文:
这些 SQL 引擎基本上都只支持类 SQL 语法,并不能像数据库那样支持标准 SQL,特别是数据仓库领域几乎必然会用到嵌套查询 SQL,也就是在 where 条件里面嵌套 select 子查询,但是几乎所有的大数据 SQL 引擎都不支持。
我的感受:
其实这就是数仓的一些中间表的来源,还有一点就是可以实现数据中间结果的重用。
以下为原文:
最后我们还是回到 Hive。Hive 本身的技术架构其实并没有什么创新,数据库相关的技术和架构已经非常成熟,只要将这些技术架构应用到 MapReduce 上就得到了 Hadoop 大数据仓库 Hive。但是想到将两种技术嫁接到一起,却是极具创新性的,通过嫁接产生出的 Hive 可以极大降低大数据的应用门槛,也使 Hadoop 大数据技术得到大规模普及。(也许这就是novelty)
Spark到底为什么快
同样都要经过 shuffle,为什么 Spark 可以更高效呢?
从计算模式上(减少了任务启动次数)
其实从本质上看,Spark 可以算作是一种 MapReduce 计算模型的不同实现。Hadoop MapReduce 简单粗暴地根据 shuffle 将大数据计算分成 Map 和 Reduce 两个阶段,然后就算完事了。而 Spark 更细腻一点,将前一个的 Reduce 和后一个的 Map 连接起来,当作一个阶段持续计算,形成一个更加优雅、高效地计算模型,虽然其本质依然是 Map 和 Reduce。但是这种多个计算阶段依赖执行的方案可以有效减少对 HDFS 的访问,减少作业的调度执行次数,因此执行速度也更快。
从存储方式上(减少了磁盘IO)
并且和 Hadoop MapReduce 主要使用磁盘存储 shuffle 过程中的数据不同,Spark 优先使用内存进行数据存储,包括 RDD 数据。除非是内存不够用了,否则是尽可能使用内存, 这也是 Spark 性能比 Hadoop 高的另一个原因。
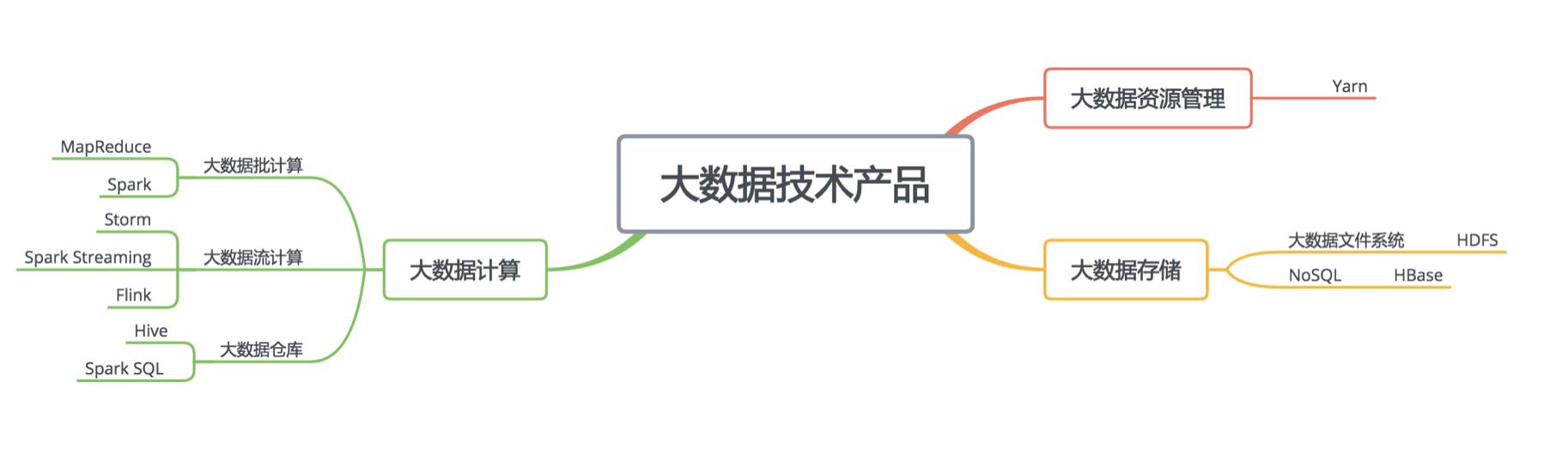
各个组件的在生态中的位置
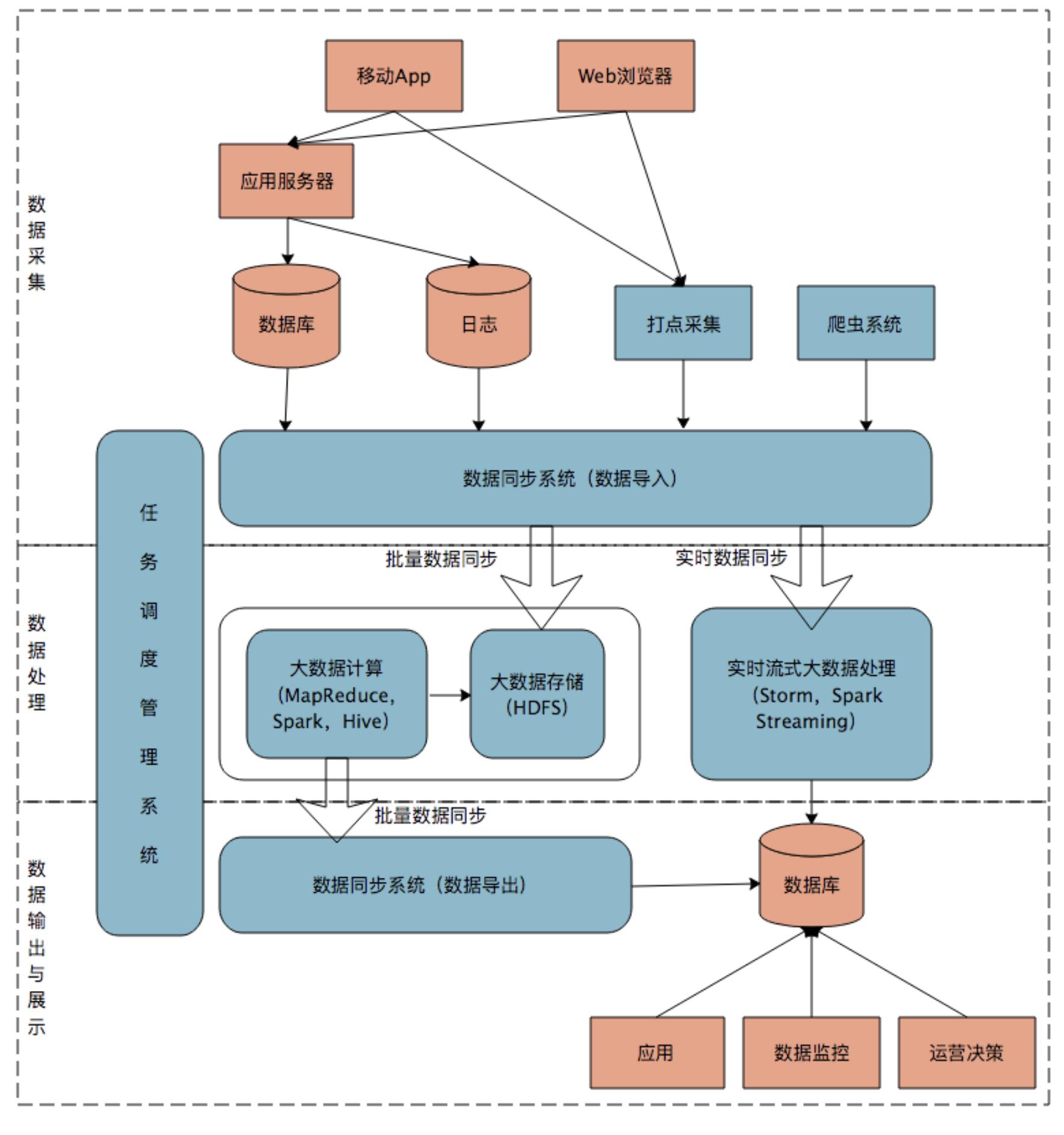
Lambda架构与大数据平台
大数据与物联网
总体的模式是端 - 云 - 端的架构。
计算的核心思想仍然是移动计算。比如说边缘计算要执行大量的逻辑运算,主要是对传感器数据进行处理和计算。运算逻辑代码和处理规则可能会经常变化,特别是规则配置,随时可能更新。比较好的做法就是参考大数据计算框架的做法,即移动计算,将执行代码和规则配置分发到智能网关服务器。
以上是关于《从0开始学大数据》学习后感的主要内容,如果未能解决你的问题,请参考以下文章