03Hadoop框架HDFS Shell 命令
Posted liangzai2048
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了03Hadoop框架HDFS Shell 命令相关的知识,希望对你有一定的参考价值。
文章目录
HDFS Shell命令
详细启动脚本介绍
- 第一种:全部启动集群所有进程
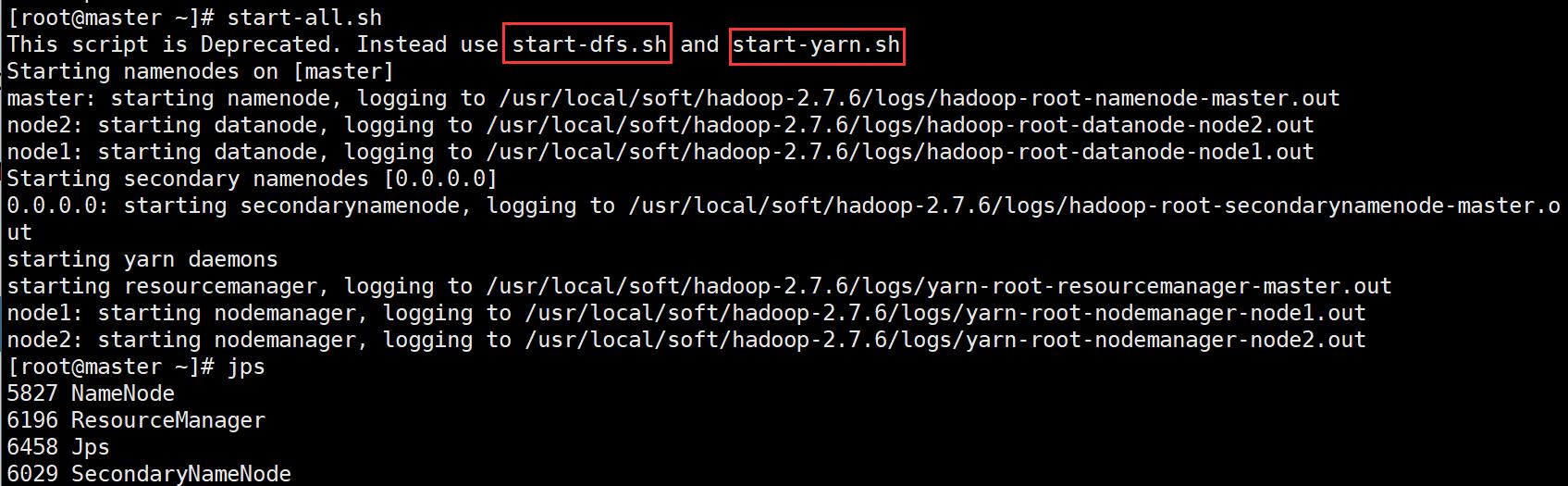
启动:sbin/start-all.sh
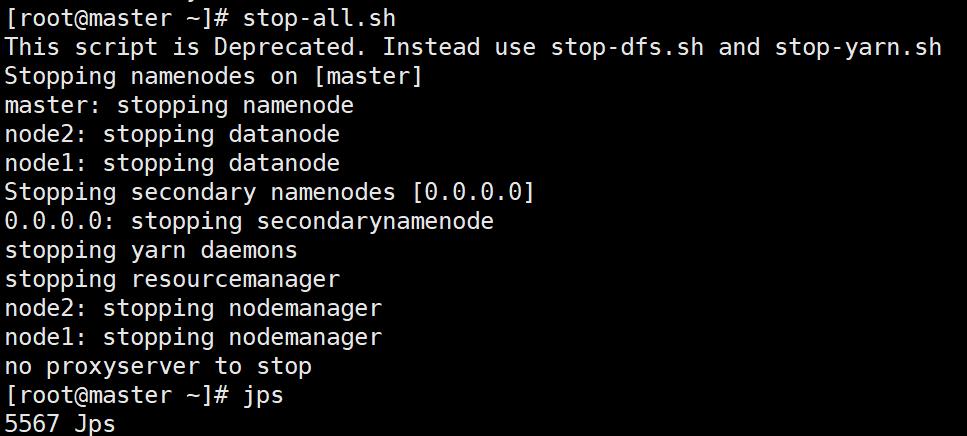
停止: sbin/stop-all.sh
*启动
- 停止
- 第二种:单独启动hdfs【web端口50070】和yarn【web端口8088】的相关进程
启动:sbin/start-dfs.sh sbin/start-yarn.sh
停止:sbin/stop-dfs.sh sbin/stop-yarn.sh
每次重写启动集群的时候使用
- 第三种:单独启动某一个进程
启动hdfs:sbin/hadoop-daemon.sh start (namenode | datanode)
停止hdfs:sbin/hadoop-daemon.sh stop (namenode | datanode)
启动yarn:sbin/yarn-daemon.sh start (resourcemanager | nodemanager)
停止yarn:sbin/yarn-daemon.sh stop(resourcemanager | nodemanager)
用于当某个进程启动失败或者异常down掉的时候,重启进程
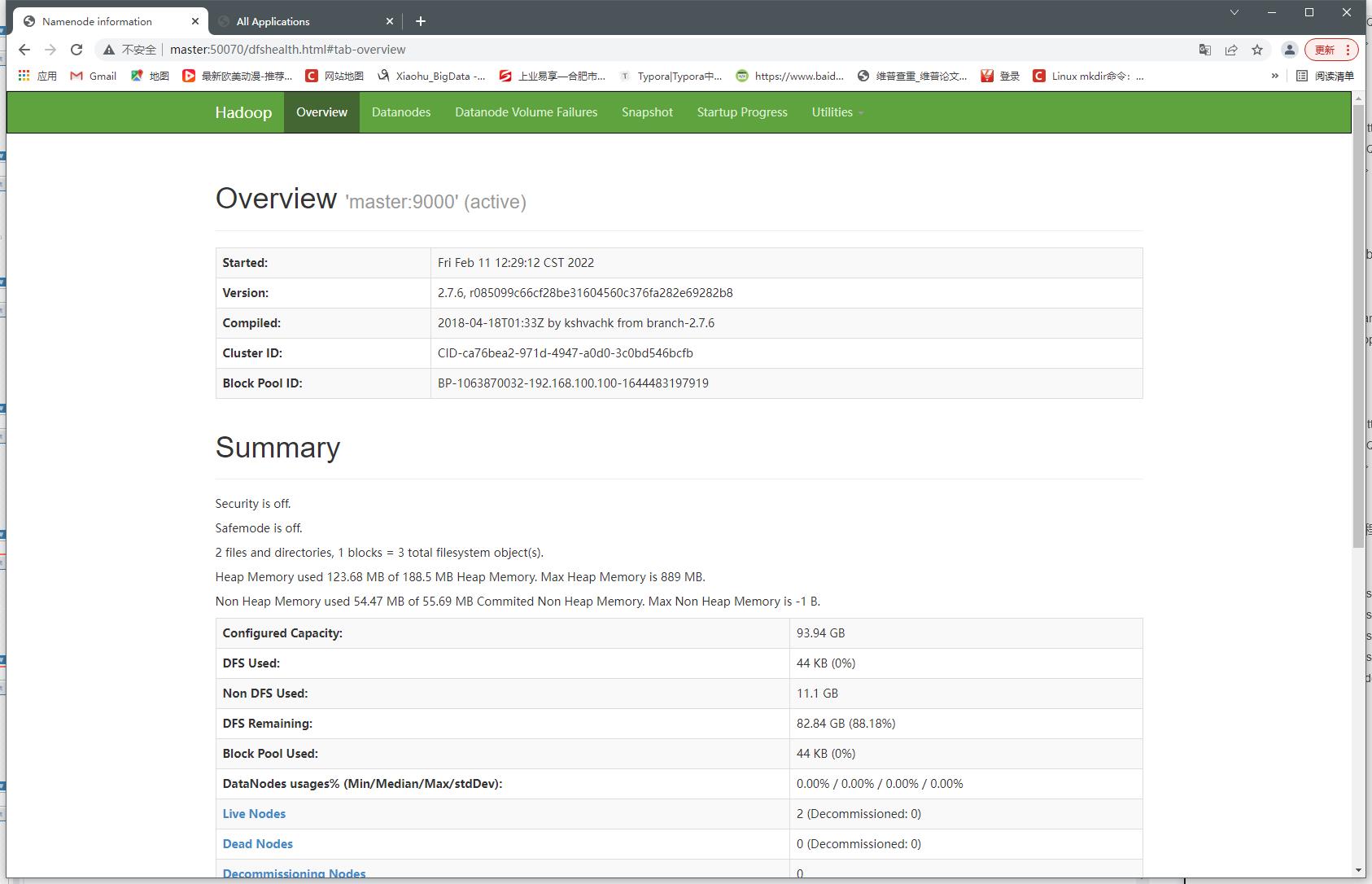
- HDFS web端口50070
- yarn web端口8088
HDFS Shell 介绍
调用文件系统(FS) Shell命令应使用 bin/hdfs dfs -XXX 的形式
所有的FS Shell 命令使用URI路径作为参数
URI格式是scheme://authority/path
HDFS的scheme是hdfs,对本地文件系统,scheme是file
其中scheme和authority参数都是可选的,如果未加指定,就会使用配置中指定的默认scheme。
例如:/parent/child可以表示成
hdfs://namenode:namenodePort/parent/child,或者更简单的/parent/child(假设配置文件是namenode:namenodePort)
大多数FS Shell命令的行为和对应的Linux Shell命令类似
HDFS Shell 常用操作
调用文件系统(FS)Shell 命令应使用 bin/hdfs dfs -XXX 的形式。【更多命令解释请见下面备注】
-ls 查看hdfs上目录,如 hdfs dfs -ls /
-put 将本地文件上传到hdfs,如 hdfs dfs -put 本地文件路径 hdfs路径
-get 将hdfs文件下载到本地,如 hdfs dfs -get hdfs 文件路径 本地文件路径
-mkdir 在hdfs上创建文件夹,如 hdfs dfs -mkdir/test
-cp 将hsfs文件或目录复制 如 hdfs dfs -cp /test.txt /a/
-cat 查看hdfs上文件内容 如hdfs dfs -cat /test.txt
-mkdir
hdfs dfs -mkdir /input

-ls
hdfs dfs -ls /

运行word count 实例
1、首先进入mapreduce目录下
/usr/local/soft/hadoop-2.7.6/share/hadoop/mapreduce
2、创建一个words.txt文件
vim words.txt
3、编辑words.txt
java java python
c c++ javascript html css
hadoop hibe hbase
hadoop hibe hbase
hadoop hibe hbase
hadoop hibe hbase
scala spark flink
scala spark flink
scala spark flink
scala spark flink
kafka
flume sqoop datax flinkx kettle canal
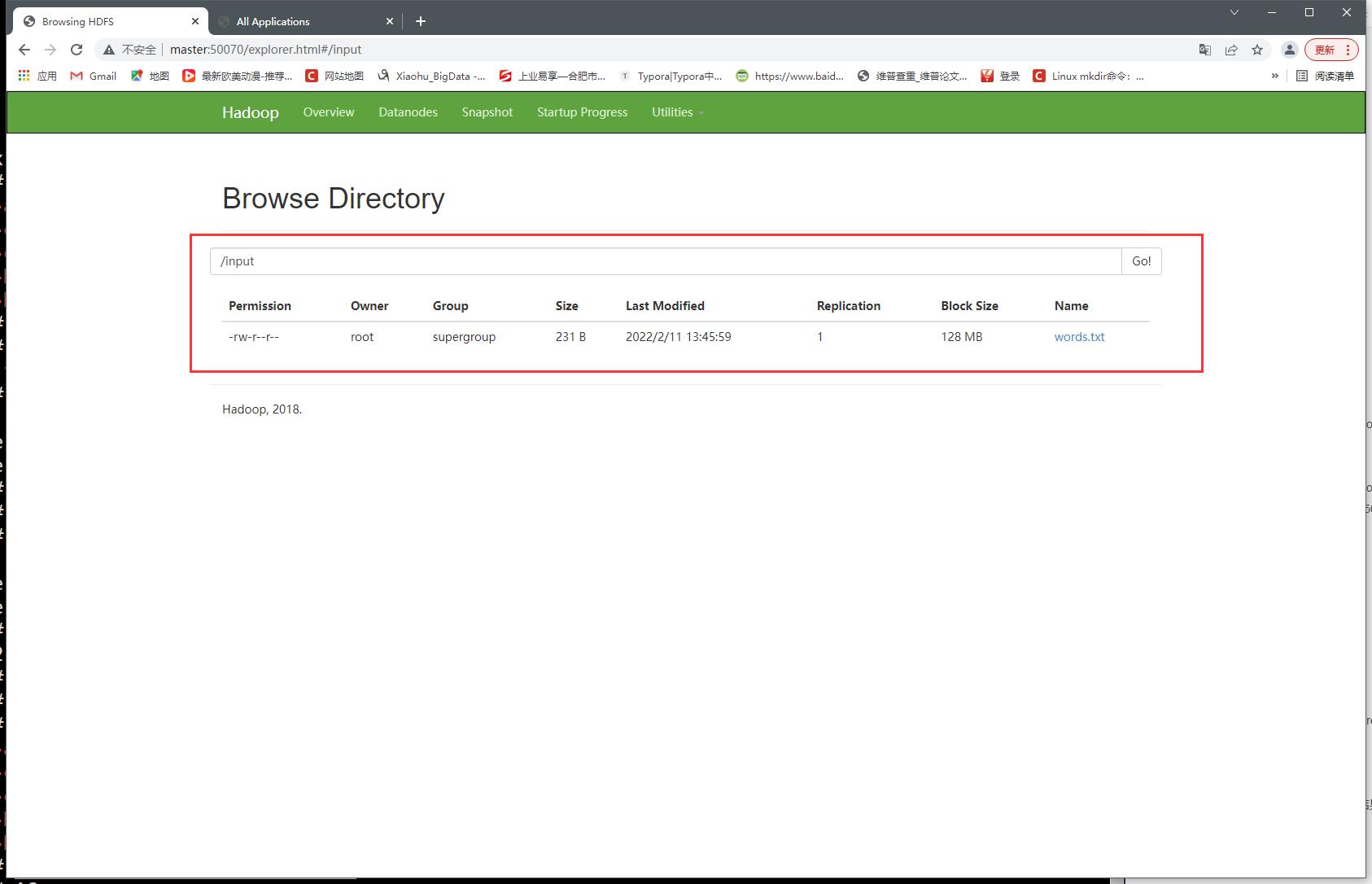
4、创建一个input目录
hdfs dfs -mkdir /input

5、上传到hdfs
hdfs dfs -put words.txt /input
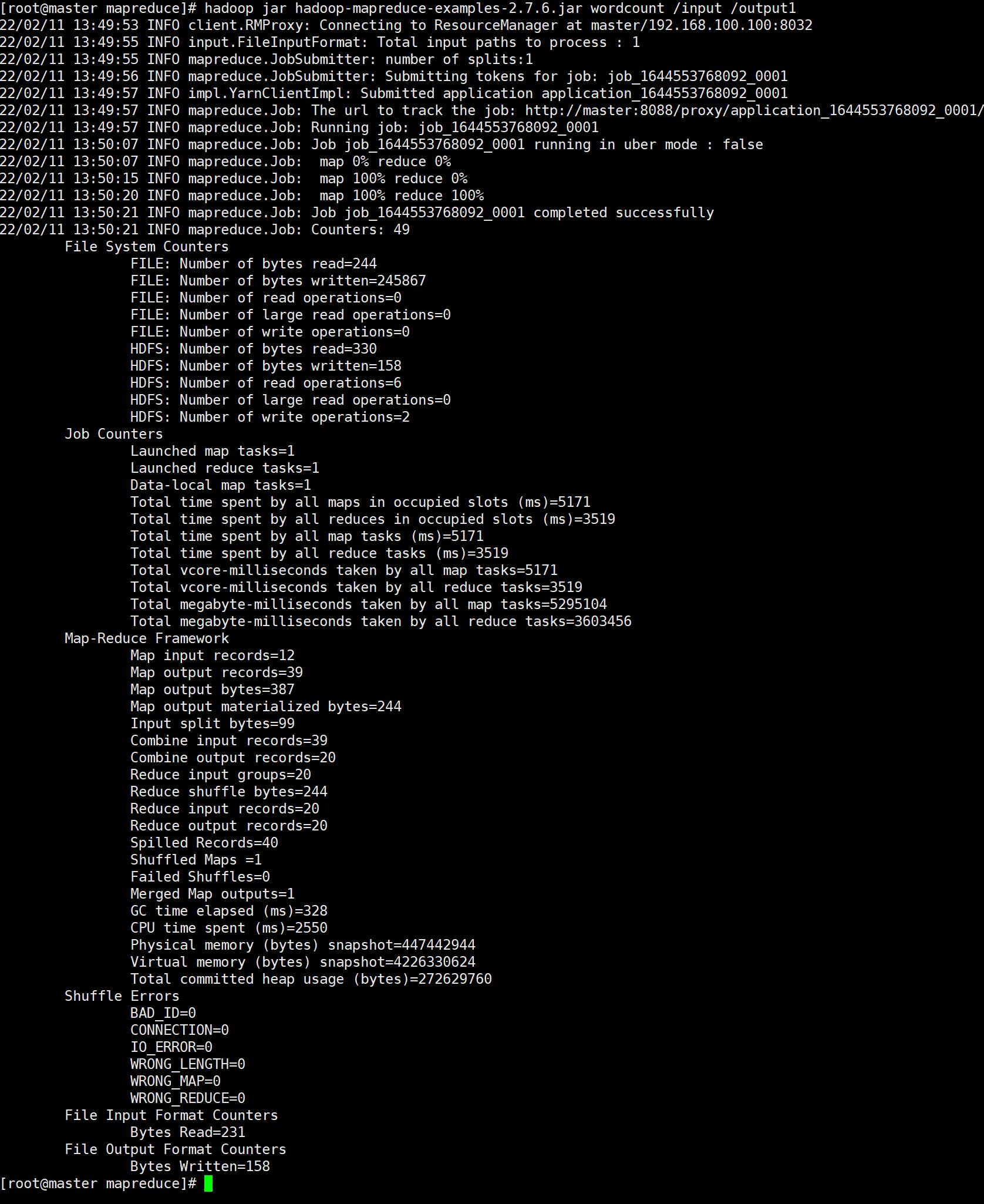
6、运行wordcount
hadoop jar hadoop-mapreduce-examples-2.7.6.jar wordcount /input /output1
- inputpath :是指hdfs上输入文件路径
- outpath : 是指hdfs上程序运行输出结果所在路径
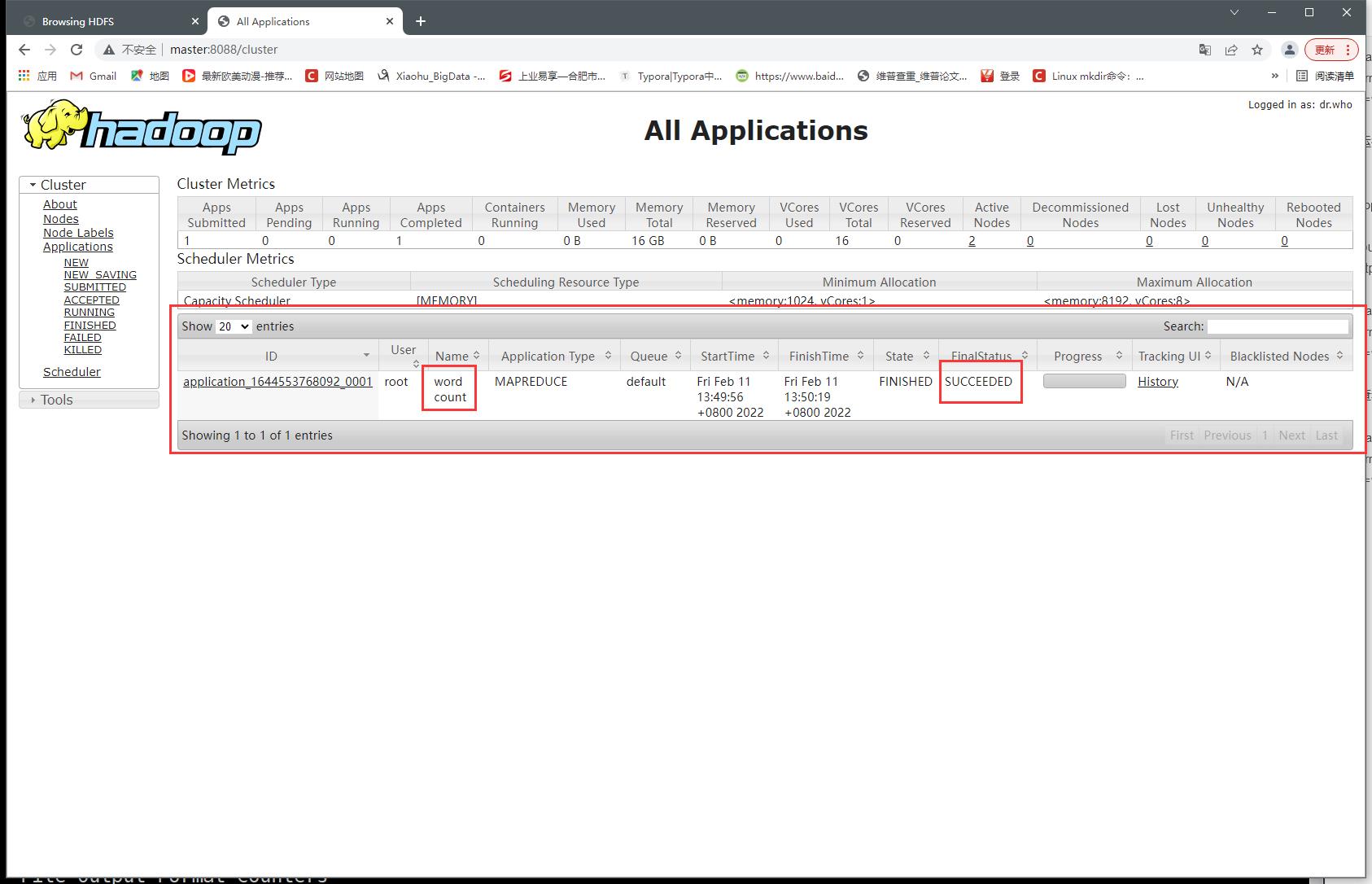
7、查看yarn web端口8088
- RUNNING
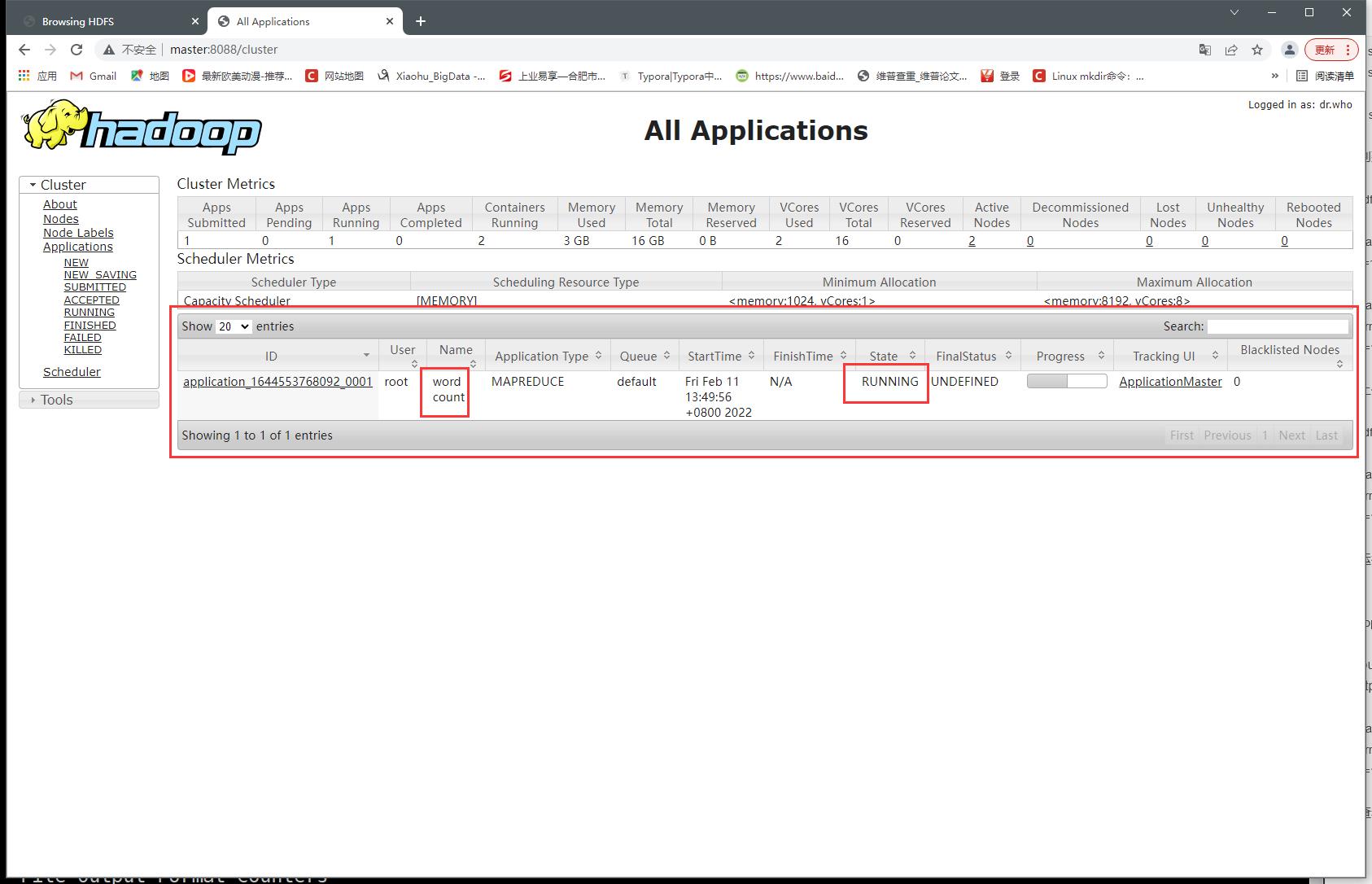
- SUCCEEDED
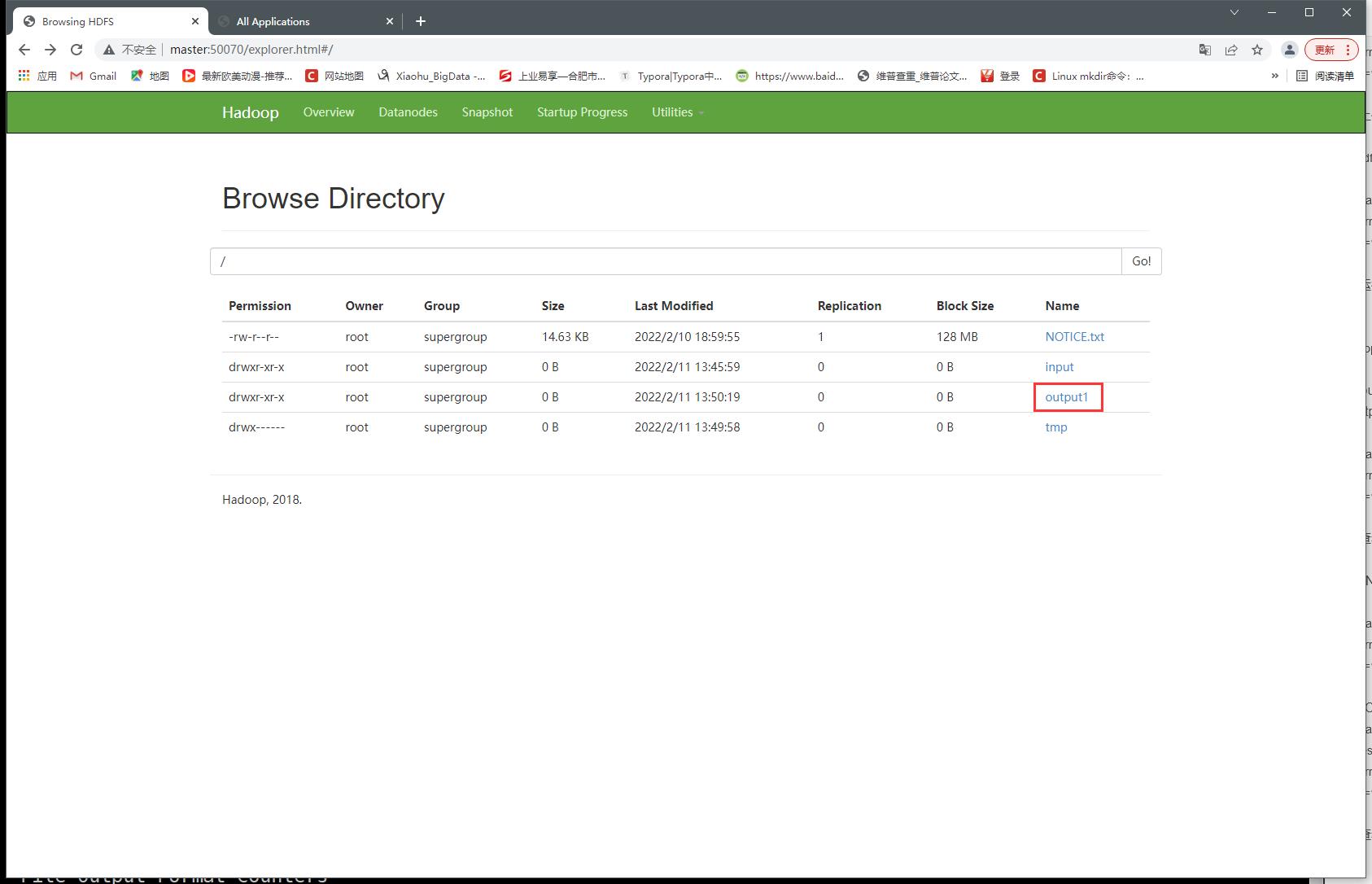
8、查看HDFS web端口50070
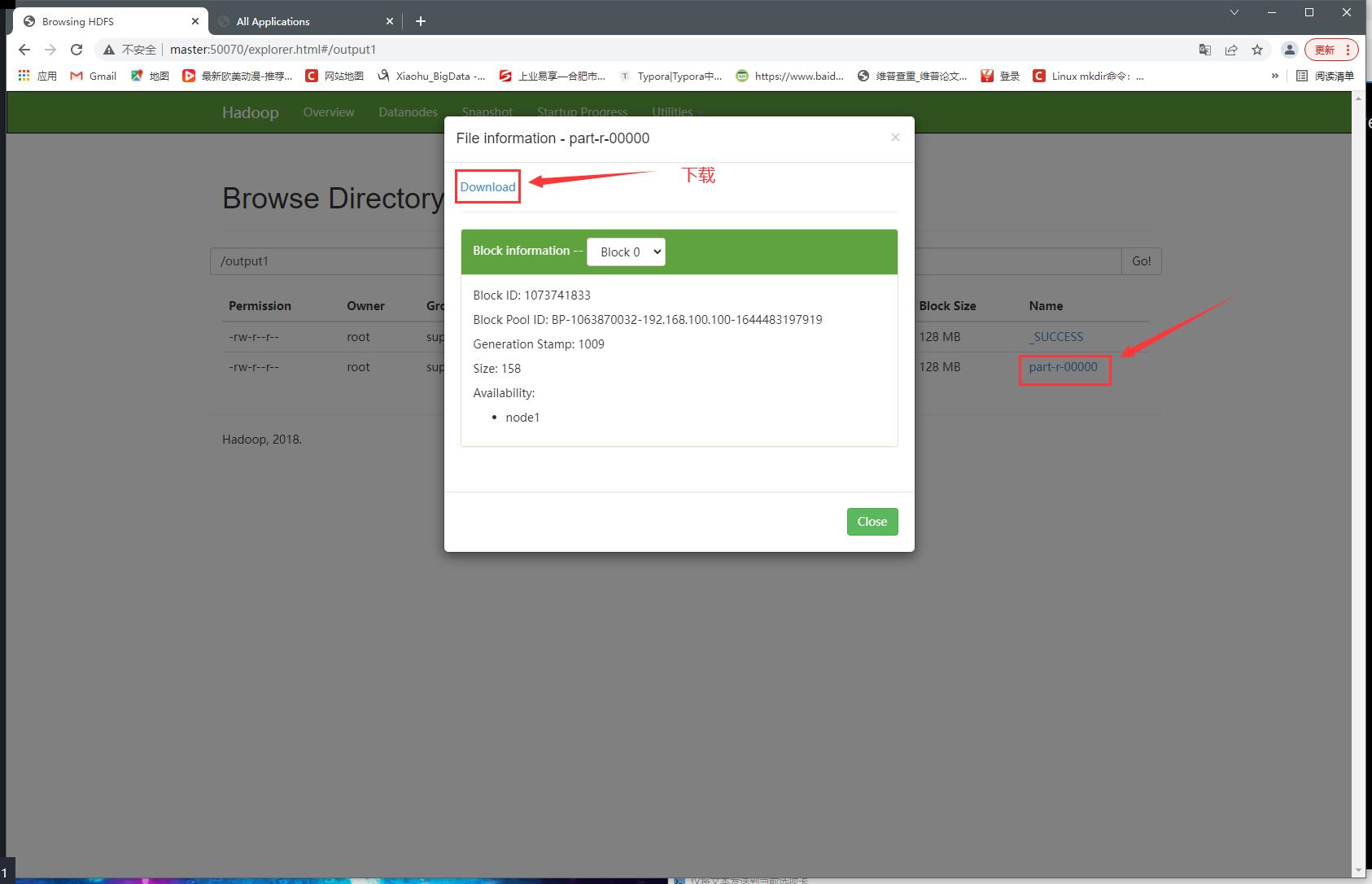
9、下载运行后的文件
10、打开查看运行后的结果
c 1
c++ 1
canal 1
css 1
datax 1
flink 4
flinkx 1
flume 1
hadoop 4
hbase 4
hibe 4
html 1
java 2
javascript 1
kafka 1
kettle 1
python 1
scala 4
spark 4
sqoop 1
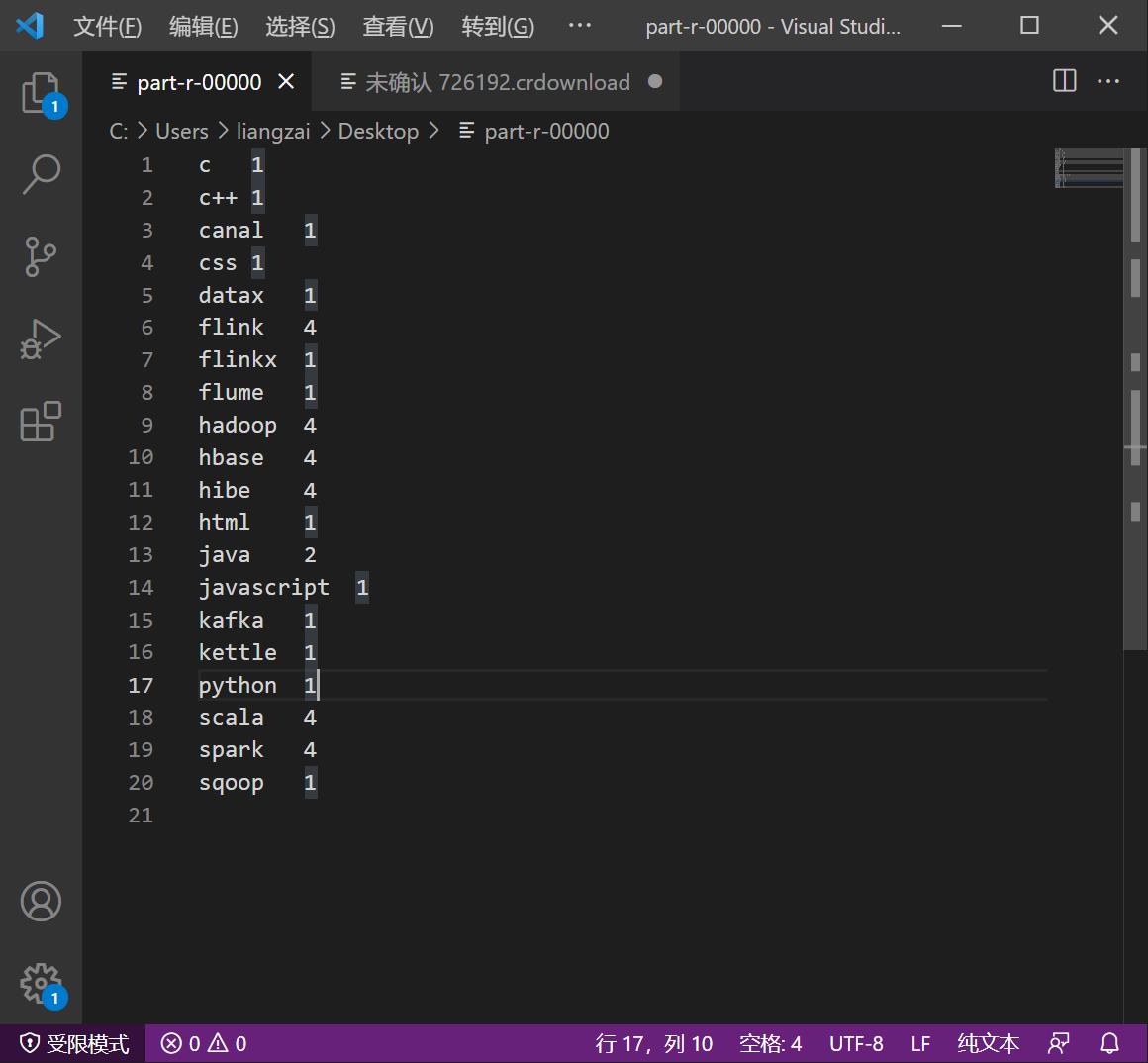
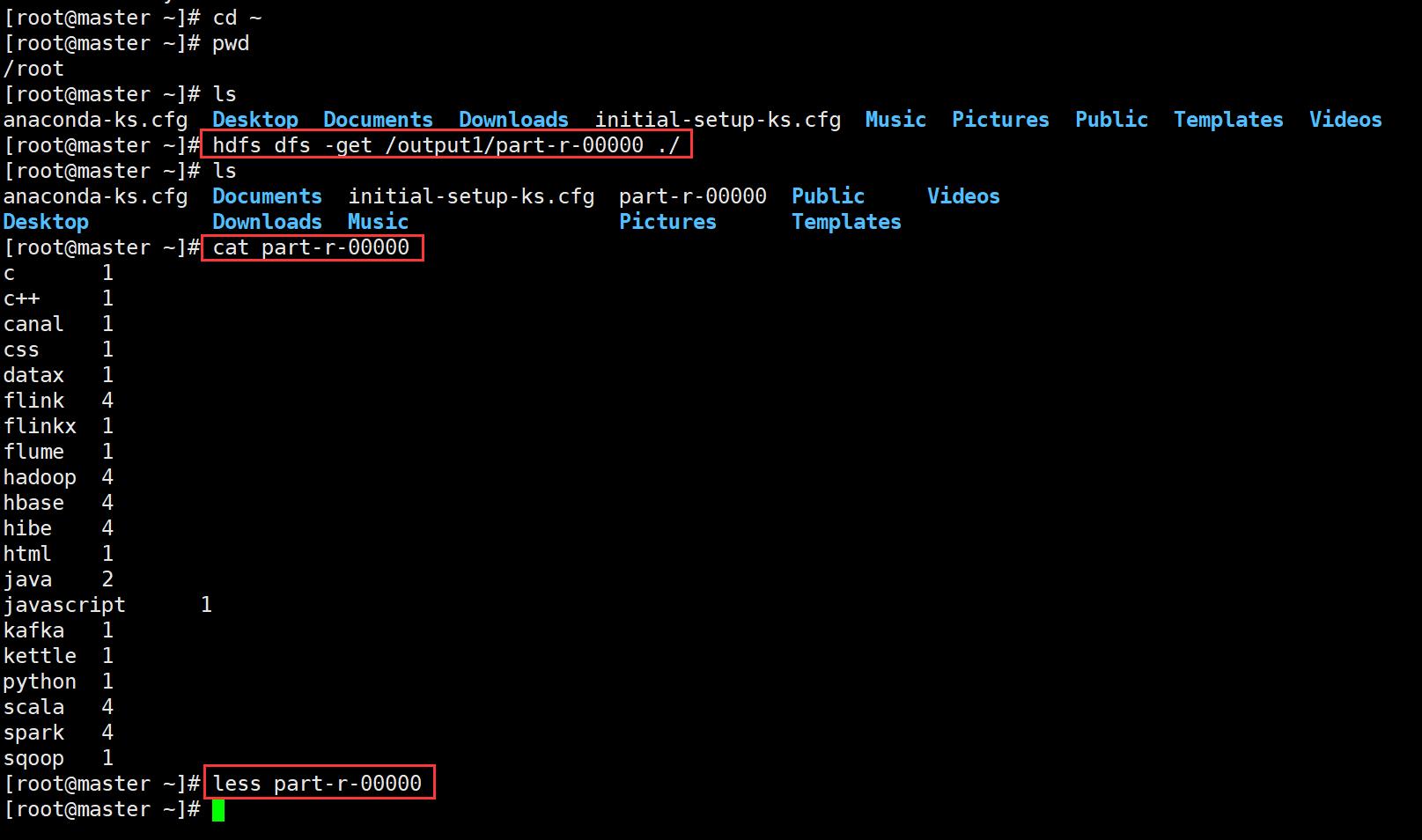
这就是mapreduce的wordcount运行的结果
使用hdfs命令下载上传的文件
#使用hdfs命令下载
[root@master ~]# hdfs dfs -get /output1/part-r-00000 ./
#使用cat命令查看
[root@master ~]# cat part-r-00000
#使用less命令查看
[root@master ~]# less part-r-00000
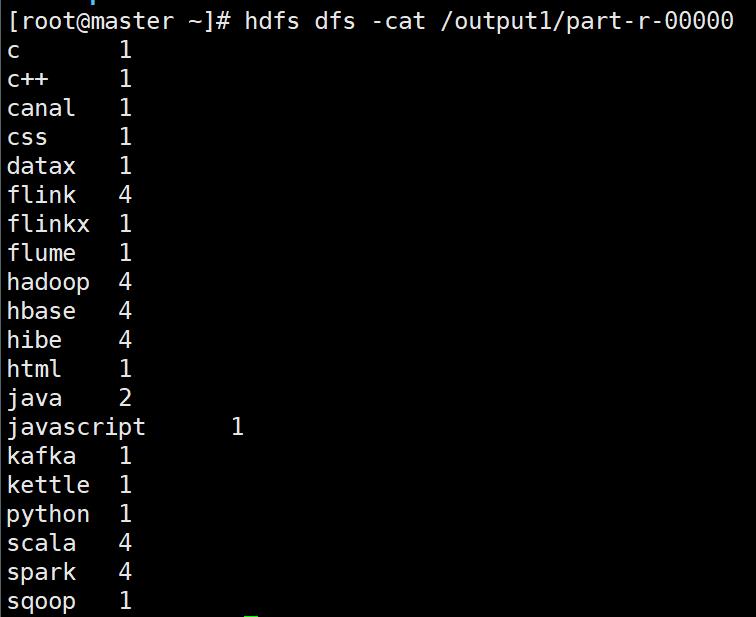
使用hdfs命令查看上传的文件
[root@master ~]# hdfs dfs -cat /output1/part-r-00000
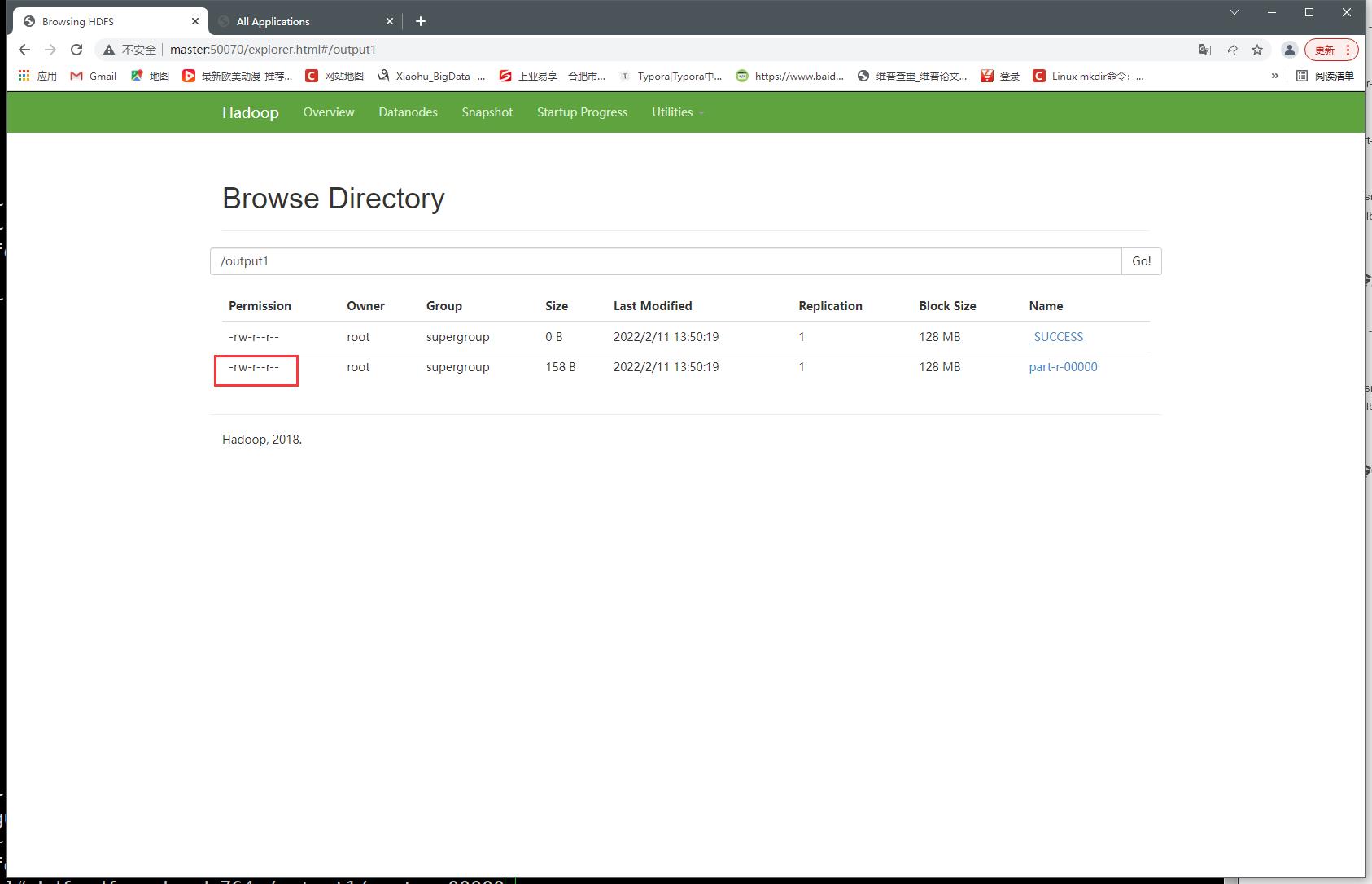
使用hdfs命令修改上传文件权限
- 未修改前
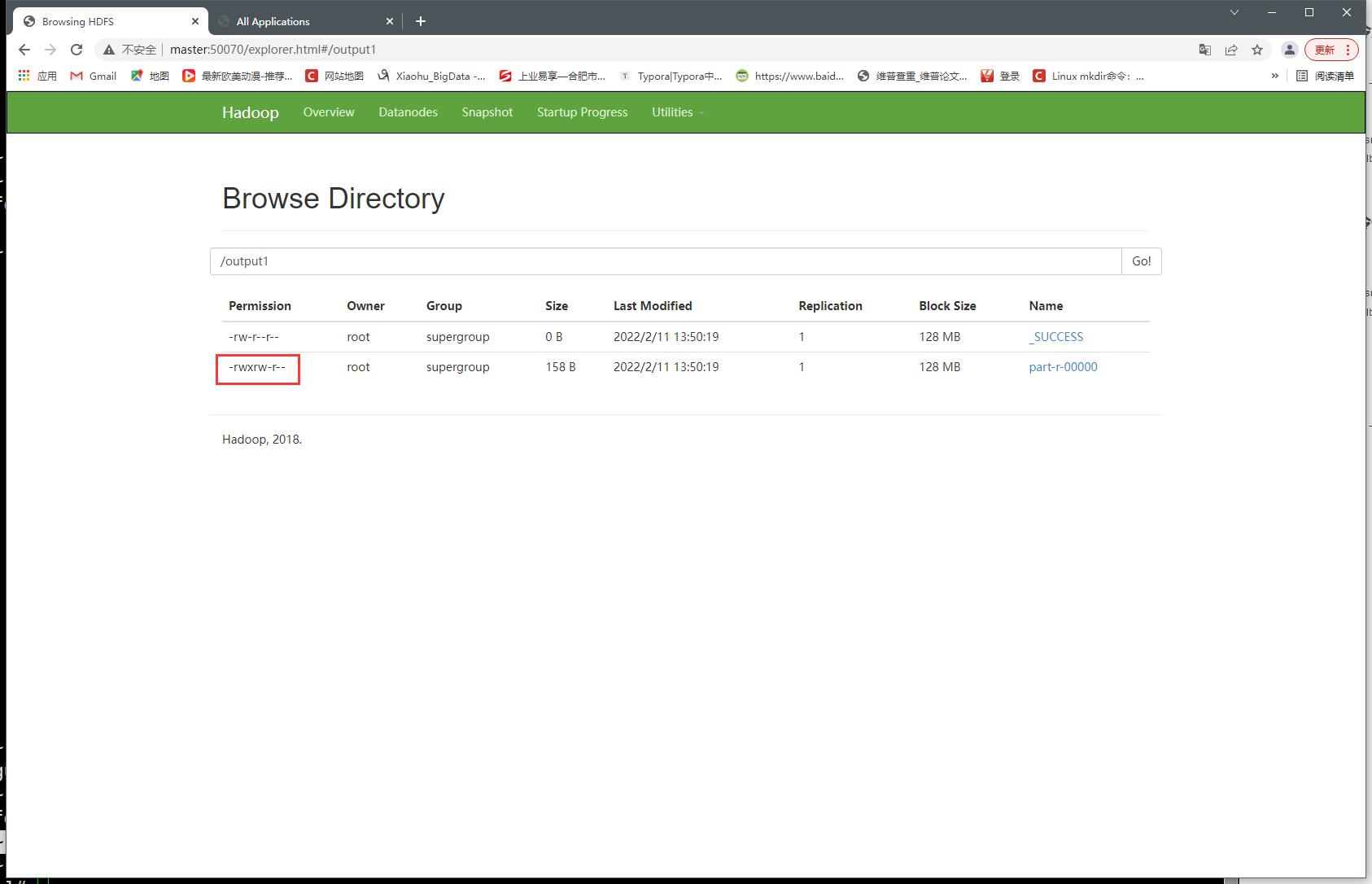
- 修改后
[root@master ~]# hdfs dfs -chmod 764 /output1/part-r-00000
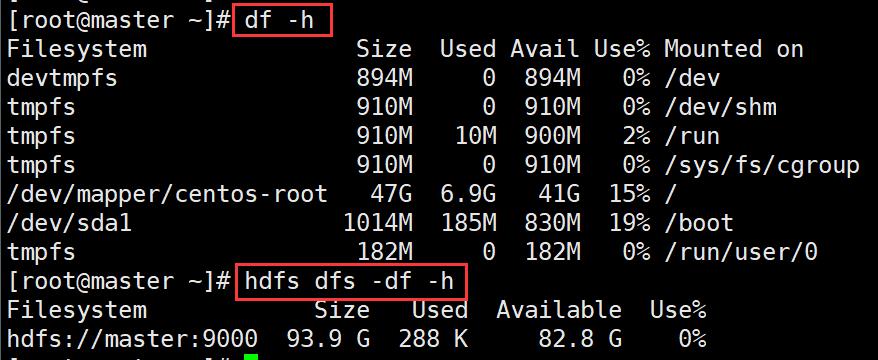
查看磁盘使用情况
#Linux查看磁盘使用情况
[root@master ~]# df -h
#hdfs查看磁盘使用情况
[root@master ~]# hdfs dfs -df -h
修改用户权限
#创建一个用户
[root@master ~]# useradd liangzai
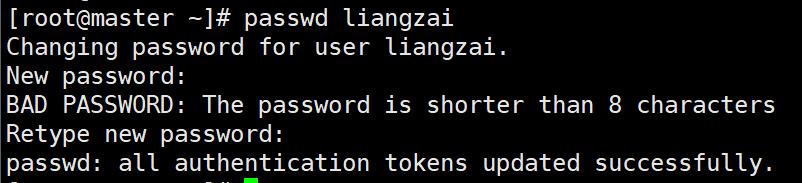
#修改用户密码
[root@master ~]# passwd liangzai
123456
123456
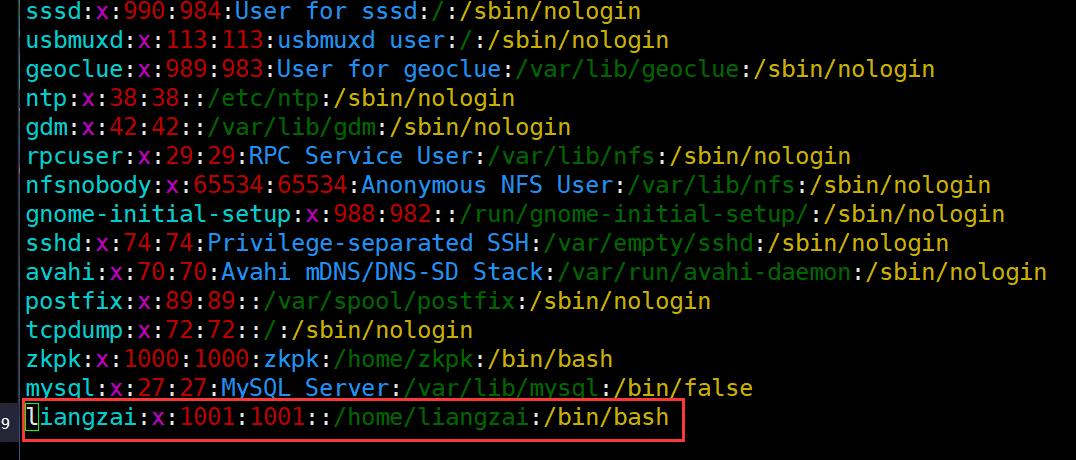
#查看新增用户
[root@master ~]# vim /etc/passwd
#添加用户组
[root@master ~]# usermod -a -G root liangzai
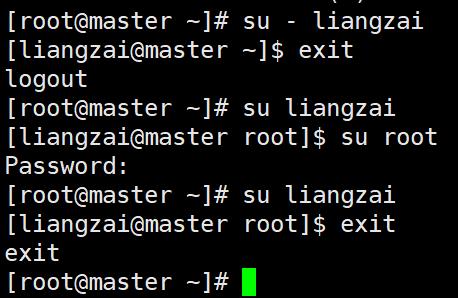
#切换用户(加 - 表示环境变量一起切换)
[root@master ~]# su - liangzai
[liangzai@master ~]$ exit
#切换用户
[root@master ~]# su liangzai
[liangzai@master root]$ exit
#改变用户组
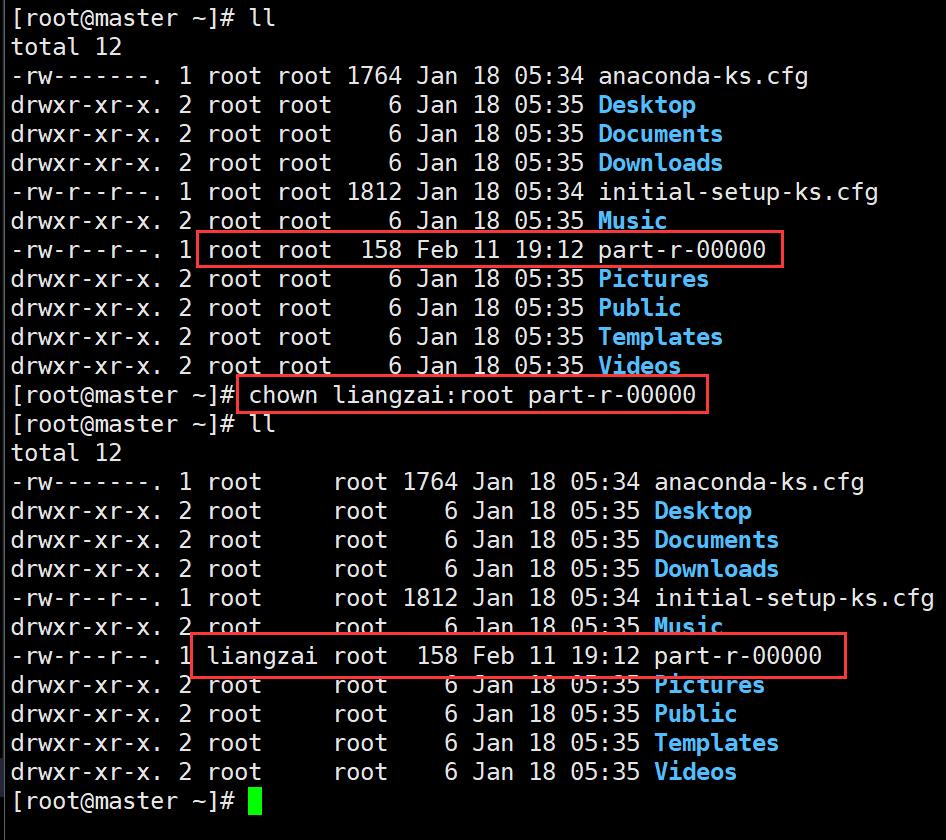
[root@master ~]# chown liangzai:root part-r-00000
#hdfs改变用户组
[root@master ~]# hdfs dfs -chown liangzai /output1/part-r-00000
- 修改用户密码
- 查看新增用户
- 切换用户
- 改变用户组
- hdfs改变用户组
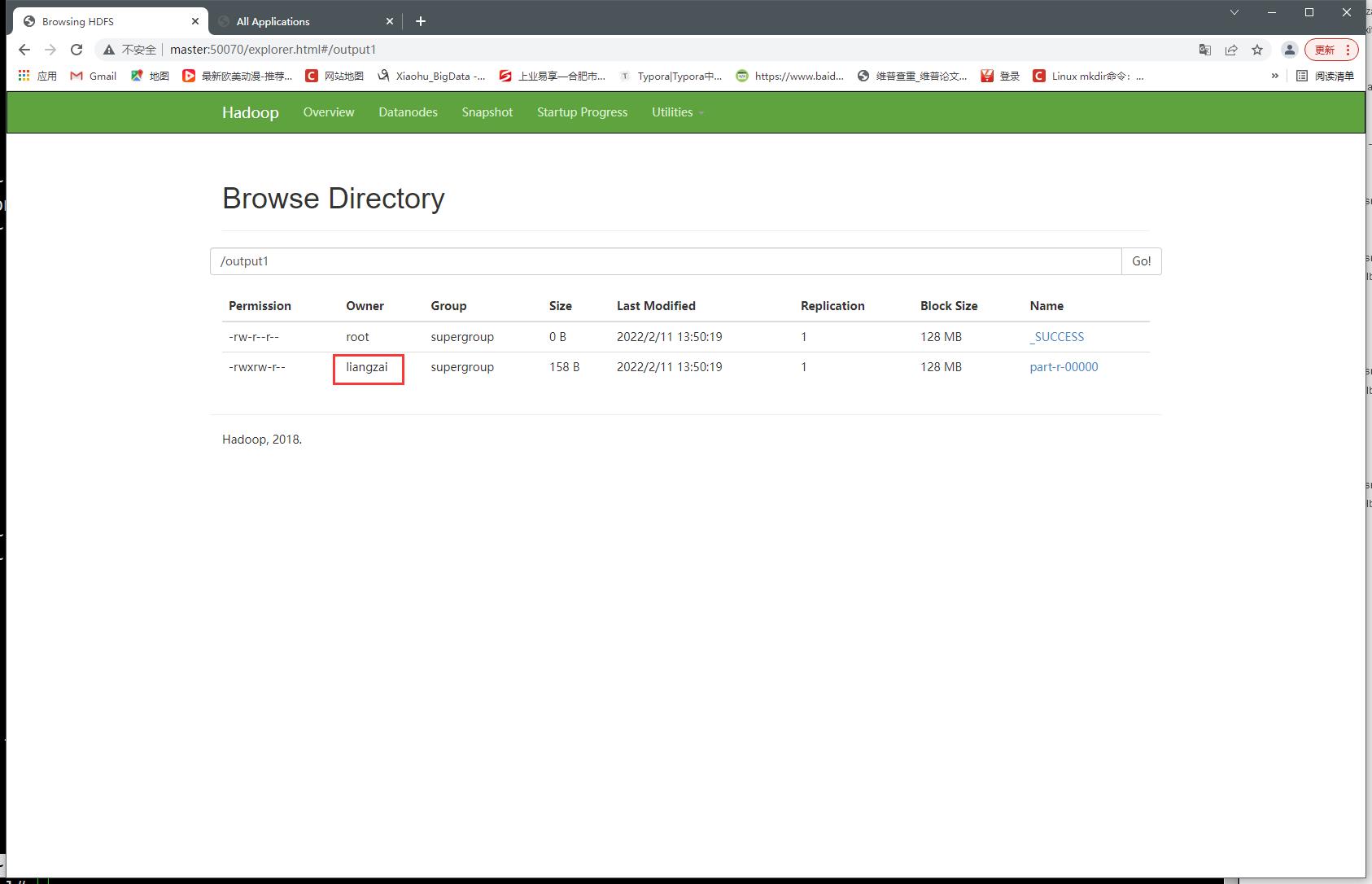
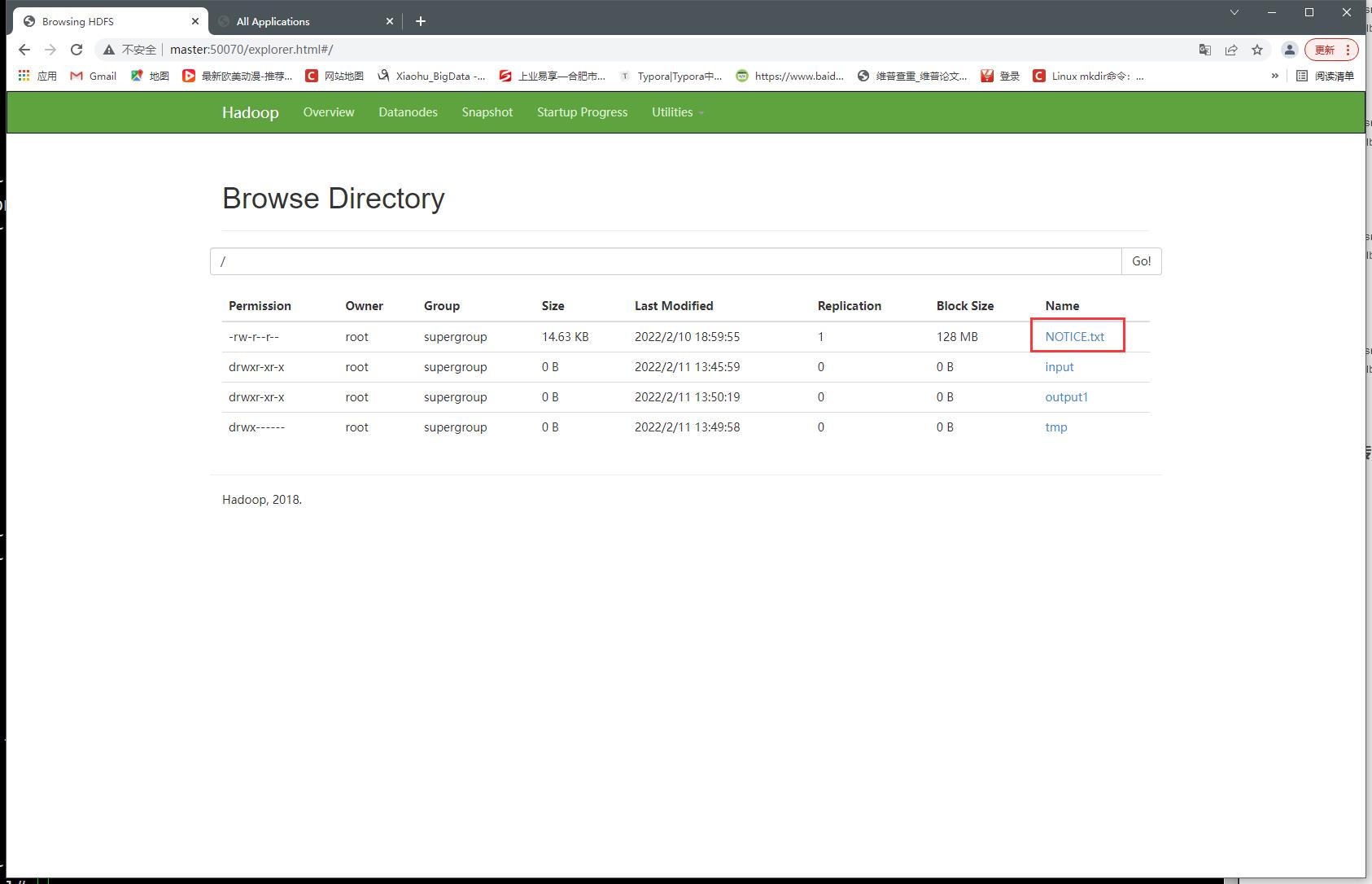
删除hdfs上传的文件或目录
- 删除NOTICE.txt
- 删除前
- 删除后
[root@master ~]# hdfs dfs -rm /NOTICE.txt

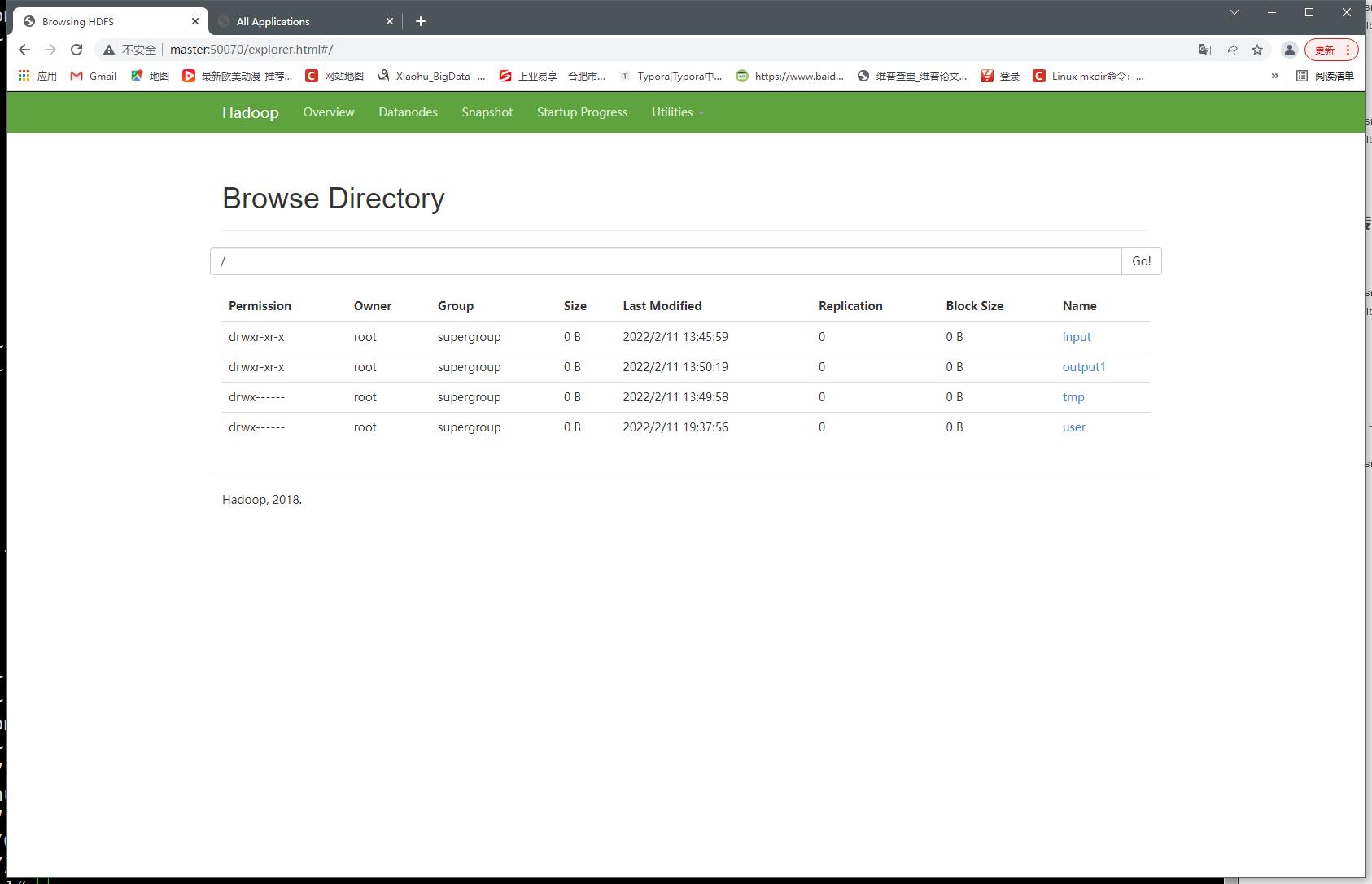
将hdfs上的文件Moved到.Trash/Current/NOTICE.txt垃圾回收站保留1440 minutes (一天后删除)
- 删除tmp目录
创建的tmp一般保存日志文件,在资源不够的时候可以考虑删除
# 删除目录需要加上 -r
[root@master ~]# hdfs dfs -rm -r /tmp
删除hdfs上传的文件目录,不放入回收站
-skipTrash表示跳过回收站
- 删除input目录不放入回收站
#-skipTrash表示跳过回收站
[root@master ~]# hdfs dfs -rm -r -skipTrash /input

不建议使用这个命令,直接删除恢复不了,没有后悔的余地
也可以不跳过,然后将.Trash回收站删掉
到底啦!觉得靓仔的文章对你学习Hadoop有所帮助的话,一波三连吧!q(≧▽≦q)
以上是关于03Hadoop框架HDFS Shell 命令的主要内容,如果未能解决你的问题,请参考以下文章