MySql中InnoDB锁注意事项
Posted Leo Han
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySql中InnoDB锁注意事项相关的知识,希望对你有一定的参考价值。
通过前面分析,
Mysql事务级别,锁的级别分类,redo log和undo log,事务实现机制
我们知道mysql中有多中锁类型,那么这些锁是怎么作用的呢?
总结下来如下(在InnoDB RR级别下):
1. mysql中锁都是基于索引的,RR级别上默认就是使用next-key lock
2. 原则 1:加锁的基本单位是 next-key lock。
3. 原则 2:查找过程中访问到的对象才会加锁。
4. 优化 1:索引上的等值查询,给唯一索引加锁的时候,如果找到匹配记录,next-key lock 退化为行锁。
5. 优化 2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。
6. 一个 bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止。
我们通过如下例子分析,首先建表如下:
create table test(
a int primary key,
b int ,
c int,
key idx_b (b)
);
create unique index u_idx_c on test(c);
当前事务级别为:

数据库中有如下记录:

主键索引等值查询
| 事务A | 事务B | 事务C |
|---|---|---|
begin;update test set c=c+1 where a=7 | begin; insert into test values(,8,8,8)(阻塞等待) | begin;update test set c=c+1 where a =10(不阻塞,执行成功) |
这时候,按照上面说的,上来加的是next-key lock技术,但是这时候并没有7这条记录,这里是使用a主键进行查找的,在主键的索引上,这时候next-key lock对应几个锁为 (无穷,0],(0,5],(5,10],(10,15],(15,20],(20,25],(25,无穷]
这时候a=7在(5,10]这个next-key lock上,但是由于是做等值查询,这时候下一个记录10时不匹配的,这时候退化为gap-lock,即在(5,10)的区间,所以事务B阻塞,事务C执行成功。这时记录里面是没有a=7这条记录的,如果我们查询的是begin;update test set c=c+1 where a=5那么后面事务B,事务C都是可以执行的,这时候我们匹配到条件,并且是在主键索引上,这时候next-key lock变为记录锁。
非唯一索引等值匹配
| 事务A | 事务B | 事务C |
|---|---|---|
begin;select a from test where b=5 lock in share mode | begin;update test set c=c+1 where a=5(不阻塞,执行成功) | begin;insert into test values(7,7,7)(阻塞等待) |
这里查询使用是普通非唯一索引idx_b,首先等值匹配数据库里idx_b有5这条记录,这时候idx_b上5这条记录加锁,另外还需要间隙锁,(0,5]会增加next-key lock,同时由于idx_b不是唯一索引,这时候不知道往右还有没有记录,所以还要往后查,需要加(5,10]的next-key lock,直到c=10才放弃,这时候由于查询是等值匹配,c=10这条记录匹配不上,(5,10]的next-key lock退化为(5,10)的gap-lock,
只有访问到的才会加索引,事务A由于只查了a,通过idx_b(而非聚簇索引上都包含了主键,这时候不需要才去主键索引上查,直接通过idx_b就能查到所需要的,覆盖索引),因此只用对idx_b加索引,对idx_b上(0,10)这个区间加锁,而事务B是直接通过主键索引查的,这时候主键索引上没有任何锁,可以随便执行,而事务C插入的时候是需要更新idx_b索引的,这时候这个区间的数据已经被锁了,只能阻塞等待
锁是加在索引上的,如果想要使用lock in share mode来加读锁的话,为了避免覆盖索引的优化,在查询的字段中加入索引不存在的字段(非主键索引都包含了主键),如果上面事务A改成begin;select c from test where b=5 lock in share mode这时候事务B和事务C都会被阻塞
主键索引范围查询
| 事务A | 事务B | 事务C |
|---|---|---|
begin;select * from test where a>=10 and a<11 for update | begin;insert into test values(13,13,13)(阻塞等待) | begin;update test set c=c+1 where a=15(阻塞等待) |
首先上来使用next-key lock对(5,10]加锁,然后由于等值查找主键,退化为对id=10加记录锁
范围查找继续查找,下一个记录时15,满足id<11的条件,对(10,15]加next-key lock
因此,事务A对id=10加记录锁和(10,15]的next-key lock.
非唯一索引范围查询
| 事务A | 事务B | 事务C |
|---|---|---|
begin;select * from test where b>=10 and b<11 for update | begin;insert into test values(8,8,8)(阻塞等待) | begin;update test set c=c+1 where a=15(阻塞等待) |
首先上来根据b=10,对索引idx_b加(5,10] next-key lock,由于索引c是非唯一索引,没有优化规则(退化为记录锁),后面还需要继续向右找,直到15这条记录,匹配了c=10 and b<11的条件,这时候需要对(10,15]加next-key lock,所以事务A会对(5,10]和(10,15]加next-key lock。
在MySql官网在RR级别下,锁的使用如下:
REPEATABLE READ
This is the default isolation level for InnoDB. Consistent reads within the same transaction read the snapshot established by the first read. This means that if you issue several plain (nonlocking) SELECT statements within the same transaction, these SELECT statements are consistent also with respect to each other. See Section 14.7.2.3, “Consistent Nonlocking Reads”.
For locking reads (SELECT with FOR UPDATE or LOCK IN SHARE MODE), UPDATE, and DELETE statements, locking depends on whether the statement uses a unique index with a unique search condition or a range-type search condition.
For a unique index with a unique search condition, InnoDB locks only the index record found, not the gap before it.
For other search conditions, InnoDB locks the index range scanned, using gap locks or next-key locks to block insertions by other sessions into the gaps covered by the range. For information about gap locks and next-key locks, see Section 14.7.1, “InnoDB Locking”.
MySql中的锁都是基于索引的,如果字段没有索引,那么就会扫描全表,也就是会使用表锁,我们通过explain也可以看到,mysql查询走的是全表扫描还是索引。
Mysql中对于插入还有插入意向锁(Insert Intention lock),其类似gap lock,为了防止出现缓读而诞生,这几个锁的兼容情况如下
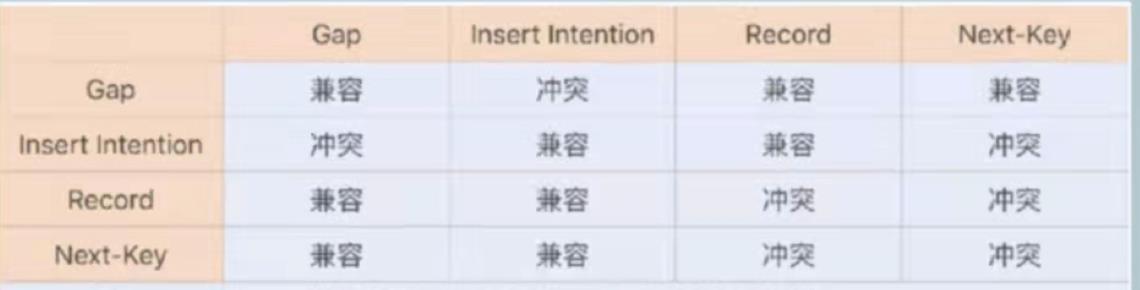
以上是关于MySql中InnoDB锁注意事项的主要内容,如果未能解决你的问题,请参考以下文章
Mysql加锁过程详解-innodb下的记录锁,间隙锁,next-key锁
Mysql加锁过程详解-innodb下的记录锁,间隙锁,next-key锁