大数据开发实习准备记录4
Posted daxina1978
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据开发实习准备记录4相关的知识,希望对你有一定的参考价值。
这是在学习大数据各种组件之后,开始系统的刷sql题和面试题的第四天!
在牛客上选择Sql必知必会系统刷题。
SQL:
1、子查询
select distinct cust_id
from Orders
where order_num in(
select order_num
from OrderItems
where item_price >= 10
) //也可以直接查两张表
select b.cust_id from OrderItems a, Orders b where a.order_num = b.order_num and a.item_price >= 10
select cust_email
from OrderItems a,Orders b,Customers c
where a.prod_id = 'BR01' and a.order_num = b.order_num
and b.cust_id = c.cust_id;
2、联合查询
select
cust_id,
(
select sum(item_price * quantity)
from OrderItems a
where a.order_num=b.order_num
) total_order
from Orders b
order by total_order desc //内部依赖于外部,外部查询每运行一行,内部查询的where都会运行一次
,所以不需要分组了
select prod_name,
(
select
sum(quantity)
from OrderItems
where Products.prod_id = OrderItems.prod_id
)from Products
SELECT
p.prod_name,
tb.quantity
FROM (
SELECT
prod_id,
SUM(quantity) quantity
FROM
OrderItems
GROUP BY
prod_id
) tb,
Products p
WHERE
tb.prod_id = p.prod_id; //此方法则是比较常规,从一个现成表和新表中查找
select
a.cust_name,
b.order_num,
d.OrderTotal
from Customers a,Orders b,
(
select order_num,
sum(quantity * item_price) OrderTotal
from OrderItems c
group by order_num
) d
where a.cust_id = b.cust_id and b.order_num = d.order_num
order by cust_name,order_num
select
cust_name,
total_price
from
(
select order_num,
sum(item_price * quantity) total_price
from OrderItems
group by order_num
having total_price >= 1000
)a
inner join Orders b on a.order_num = b.order_num
inner join Customers c on b.cust_id = c.cust_id
order by total_price //如果联合表中有需要聚合的字段,那么就需要分组过滤,注意分组时使用having
select cust_name,order_num
from Customers a left join Orders b
on a.cust_id = b.cust_id
order by cust_name //使用左外连接可将右表未匹配上的数据置为NULL
select
prod_name,
if (orders is null, 0, orders) orders //if语句可以加载选择字段中,返回一个具体字段
from
Products a
left join (
select
prod_id,
count(order_num) orders
from
OrderItems
group by
prod_id
) b on a.prod_id = b.prod_id
order by
prod_name
3、表的拼接
select prod_id,quantity
from OrderItems
where quantity=100
union //union--将两个表做行拼接,同时自动删除重复的行。union all---将两个表做行拼接,保留重复的行。
select prod_id,quantity
from OrderItems
where prod_id like 'BNBG%'
order by prod_id
面试题:
输入 www.baidu.com,怎么变成 https://www.baidu.com 的,怎么确定用HTTP还是HTTPS?
你访问的网站是如何自动切换到https的
一种是原始的302跳转,服务器把所有的HTTp流量跳转到HTTPS。但这样有一个漏洞,就是中间人可能在第一次访问站点的时候就劫持。
解决方法是引入HSTS机制,用户浏览器在访问站点的时候强制使用HTTPS。
HTTPS连接的时候,怎么确定收到的包是服务器发来的(中间人攻击)?
- 验证域名、有效期等信息是否正确。证书上都有包含这些信息,比较容易完成验证;
- 判断证书来源是否合法。每份签发证书都可以根据验证链查找到对应的根证书,操作系统、浏览器会在本地存储权威机构的根证书,利用本地根证书可以对对应机构签发证书完成来源验证;
- 判断证书是否被篡改。需要与 CA 服务器进行校验;
- 判断证书是否已吊销。通过 CRL(Certificate Revocation List 证书注销列表)和 OCSP(Online Certificate Status Protocol 在线证书状态协议)实现,其中 OCSP 可用于第3步中以减少与 CA 服务器的交互,提高验证效率
什么是对称加密、非对称加密?区别是什么?
- 对称加密:加密和解密采用相同的密钥。如:DES、RC2、RC4
- 非对称加密:需要两个密钥:公钥和私钥。如果用公钥加密,需要用私钥才能解密。如:RSA
区别:对称加密速度更快,通常用于大量数据的加密;非对称加密安全性更高(不需要传送私钥)
数字签名、报文摘要的原理
- 发送者 A 用私钥进行签名,接收者 B 用公钥验证签名。因为除 A 外没有人有私钥,所以 B 相信签名是来自 A。A 不可抵赖,B 也不能伪造报文。
- 摘要算法: MD5、SHA
GET与POST的区别?
- GET是幂等的,即读取同一个资源,总是得到相同的数据,POST不是幂等的;
- GET一般用于从服务器获取资源,而POST有可能改变服务器上的资源;
- 请求形式上:GET请求的数据附在URL之后,在HTTP请求头中;POST请求的数据在请求体中;
- 安全性:GET请求可被缓存、收藏、保留到历史记录,且其请求数据明文出现在URL中。POST的参数不会被保存,安全性相对较高;
- GET只允许ASCII字符,POST对数据类型没有要求,也允许二进制数据;
- GET的长度有限制(操作系统或者浏览器),而POST数据大小无限制
Session与Cookie的区别?
Session是服务器端保持状态的方案,Cookie是客户端保持状态的方案
Cookie保存在客户端本地,客户端请求服务器时会将Cookie一起提交;Session保存在服务端,通过检索Sessionid查看状态。保存Sessionid的方式可以采用Cookie,如果禁用了Cookie,可以使用URL重写机制(把会话ID保存在URL中)。
从输入网址到获得页面的过程 (越详细越好)?
浏览器查询 DNS,获取域名对应的IP地址:具体过程包括浏览器搜索自身的DNS缓存、搜索操作系统的DNS缓存、读取本地的Host文件和向本地DNS服务器进行查询等。对于向本地DNS服务器进行查询,如果要查询的域名包含在本地配置区域资源中,则返回解析结果给客户机,完成域名解析(此解析具有权威性);如果要查询的域名不由本地DNS服务器区域解析,但该服务器已缓存了此网址映射关系,则调用这个IP地址映射,完成域名解析(此解析不具有权威性)。如果本地域名服务器并未缓存该网址映射关系,那么将根据其设置发起递归查询或者迭代查询;
浏览器获得域名对应的IP地址以后,浏览器向服务器请求建立链接,发起三次握手;
TCP/IP链接建立起来后,浏览器向服务器发送HTTP请求;
服务器接收到这个请求,并根据路径参数映射到特定的请求处理器进行处理,并将处理结果及相应的视图返回给浏览器;
浏览器解析并渲染视图,若遇到对js文件、css文件及图片等静态资源的引用,则重复上述步骤并向服务器请求这些资源;
浏览器根据其请求到的资源、数据渲染页面,最终向用户呈现一个完整的页面。
HTTP请求有哪些常见状态码?
- 2xx状态码:操作成功。200 OK
- 3xx(重定向)表示要完成请求,需要进一步操作。通常这些状态代码用来重定向。301,永久性重定向,表示资源已被分配了新的 URL 302,临时性重定向,表示资源临时被分配了新的 URL 303,表示资源存在另一个URL,用GET方法获取资源 304,(未修改)自从上次请求后,请求网页未修改过。服务器返回此响应时,不会返回网页内容
- 4xx状态码:4xx(请求错误)这些状态码表示请求可能出错,妨碍了服务器的处理
400(错误请求)服务器不理解请求的语法
401表示发送的请求需要有通过HTTP认证的认证信息
403(禁止)服务器拒绝请求
404(未找到)服务器找不到请求网页 - 5xx状态码:服务端错误。500服务器内部错误;501服务不可用
什么是RIP (Routing Information Protocol, 距离矢量路由协议)? 算法是什么?
每个路由器维护一张表,记录该路由器到其它网络的”跳数“,路由器到与其直接连接的网络的跳数是1,每多经过一个路由器跳数就加1;更新该表时和相邻路由器交换路由信息;路由器允许一个路径最多包含15个路由器,如果跳数为16,则不可达。交付数据报时优先选取距离最短的路径。
优缺点
- 实现简单,开销小
- 随着网络规模扩大开销也会增大;
- 最大距离为15,限制了网络的规模;
当网络出现故障时,要经过较长的时间才能将此信息传递到所有路由器
PS:RIP 是应用层协议
计算机网络体系结构

- Physical, Data Link, Network, Transport, Application
- 应用层:常见协议:
- FTP(21端口):文件传输协议
- SSH(22端口):远程登陆
- TELNET(23端口):远程登录
- SMTP(25端口):发送邮件
- POP3(110端口):接收邮件
- HTTP(80端口):超文本传输协议
- DNS(53端口):运行在UDP上,域名解析服务
- 传输层:TCP/UDP
- 网络层:IP、ARP、NAT、RIP...
路由器、交换机位于哪一层?
路由器 网络层,根据IP地址进行寻址;
交换机 数据链路层,根据MAC地址进行寻址
IP地址的分类?
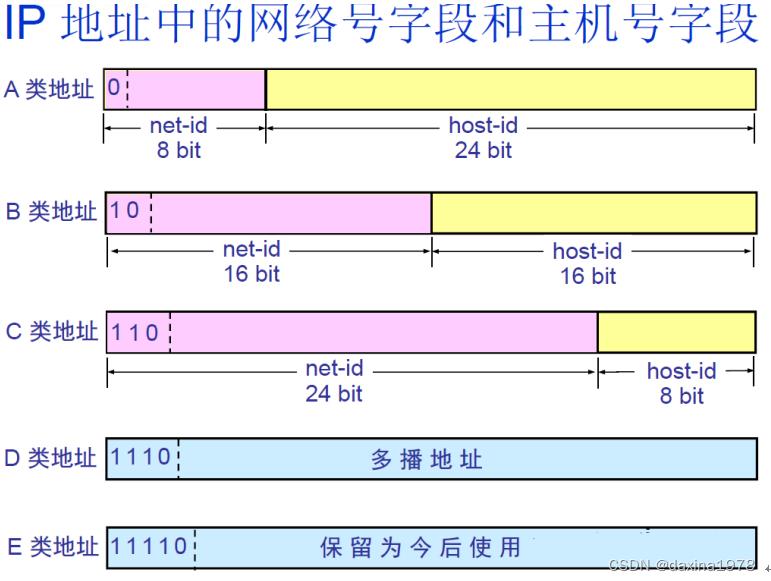
路由器仅根据网络号net-id来转发分组,当分组到达目的网络的路由器之后,再按照主机号host-id将分组交付给主机;同一网络上的所有主机的网络号相同。
什么叫划分子网?
从主机号host-id借用若干个比特作为子网号subnet-id;子网掩码:网络号和子网号都为1,主机号为0;数据报仍然先按照网络号找到目的网络,发送到路由器,路由器再按照网络号和子网号找到目的子网:将子网掩码与目标地址逐比特与操作,若结果为某个子网的网络地址,则送到该子网。
什么是ARP协议 (Address Resolution Protocol)?
ARP协议完成了IP地址与物理地址的映射。每一个主机都设有一个 ARP 高速缓存,里面有所在的局域网上的各主机和路由器的 IP 地址到硬件地址的映射表。当源主机要发送数据包到目的主机时,会先检查自己的ARP高速缓存中有没有目的主机的MAC地址,如果有,就直接将数据包发到这个MAC地址,如果没有,就向所在的局域网发起一个ARP请求的广播包(在发送自己的 ARP 请求时,同时会带上自己的 IP 地址到硬件地址的映射),收到请求的主机检查自己的IP地址和目的主机的IP地址是否一致,如果一致,则先保存源主机的映射到自己的ARP缓存,然后给源主机发送一个ARP响应数据包。源主机收到响应数据包之后,先添加目的主机的IP地址与MAC地址的映射,再进行数据传送。如果源主机一直没有收到响应,表示ARP查询失败。
如果所要找的主机和源主机不在同一个局域网上,那么就要通过 ARP 找到一个位于本局域网上的某个路由器的硬件地址,然后把分组发送给这个路由器,让这个路由器把分组转发给下一个网络。剩下的工作就由下一个网络来做。
什么是NAT (Network Address Translation, 网络地址转换)?
用于解决内网中的主机要和因特网上的主机通信。由NAT路由器将主机的本地IP地址转换为全球IP地址,分为静态转换(转换得到的全球IP地址固定不变)和动态NAT转换。
转自:https://www.jianshu.com/p/2a2ccb94f21a
面经 大数据开发实习 深信服
面试时间:2019年6月
深信服的效率是很快的,前一天晚上5点钟通知笔试,在7点就要进行笔试,9点笔试完11点钟通知第二天中午11点面试
所以我做完也没有来得及有所准备,就得去面试了
面经如下:
1.namenode和secondarynamenode的工作机制
2.谈谈对flume的理解,
flume有什么缺点,怎么去优化他,
如果和kafka整合应该kadka在前还是在后
3.mapreduce有什么缺点,怎么去优化?
mapreduce与spark的对比,各有什么优缺点
4.谈谈对storm的了解
5.hbase的了解,
怎么存储数据,
数据读写流程,
与关系型数据库的区别,
为什么列式存储能多一列或者少一列
6.zookeeper的工作原理,怎么实现高可靠
7.azkaban的工作原理
8.jvm调优
9.gc
10.锁机制,同步锁和乐观锁
11.一个进程切换到另外一个进程,要保存前一个进程的什么?
12.如果一个map较慢,是什么原因?
怎么排查,怎么解决
13.三种join方式
14.hdfs适合存大文件还是小文件,为什么?
16.算法题
(1)有n级楼梯,可以一次跳一级,也可以一次跳两级,一共有多少种跳法
(2)一篇文章,找出词频前五点多单词,不能用mapreduce
17.Linux系统较卡顿,怎么去排查原因?
18.项目是分布式环境吗?搭建环境时出现
过什么问题?
19.有没有对hive进行过调优,有没有修改过源码?
20.TCP的三次握手??
深信服的面试问的很全面,问的问题一般都是从基础切入然后深挖;
后来了解到该部门的工作主要是基于源码的开发,
换句话说:不仅仅是使用这些大数据框架和组件,而是在原有的大数据框架基础上开发出自己大数据框架和组件
深知当时的自己是无法胜任该岗位的,
不过算是给了我一个学习的目标吧。
以上是关于大数据开发实习准备记录4的主要内容,如果未能解决你的问题,请参考以下文章