Java开发 - ELK初体验
Posted CodingFire
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java开发 - ELK初体验相关的知识,希望对你有一定的参考价值。
前言
前面我们讲过消息队列,曾提到消息队列也具有保存消息日志的能力,今天要说的EL看也具备这个能力,不过还是要区分一下功能的。消息队列的日志主要指的是Redis的AOF,实际上只是可以利用了消息队列来保存,却并不是消息队列本身的能力。ELK是当今非常流行的日志采集保存和查询的框架,然而他们俩各有用处,可以说互不干扰使用,且都是必须的,下面,我们来了解ELK。
ELK
什么是ELK
ELK是如今比较流行的一套框架,主要用于日志的采集保存和查询。线上情况,我们不能通过控制台来实时查看,但却可以通过日志输出来定位问题,查看必要的信息。如果保存成文件,也必然是极庞大的体量,并不适合我们去翻看,查找信息,这才有了ELH,其实对于ELK,大家也并不陌生,其中的E,就是我们前段时间学习的ES,全名Elasticsearch,中文名:全文搜索引擎。是不是很惊喜和意外?所以当然,L和K也是两个单独的系统,他们统称为ELK,下面,我们将逐一介绍这三个东西是什么。
E
E是我们前段时间学习的ES,全名Elasticsearch,中文名:全文搜索引擎。额~这个还要继续说吗?我觉得不用了吧?下面贴个前面的博客链接,大家点进去详细了解吧。
L
L全称logstash,是一套日志采集工具,我们在前面没有讲过,它是一款开源的日志采集,处理和输出的软件,每秒可以处理上条数据,并且可以同时从多个数据来源采集并转换数据,然后将数据输出到指定的存储单元中(官方推荐的存储单元为Elasticsearch)。
数据来源可以是任何可存储数据的东西,如数据库,日志,redis等。
LogStash处理过程分为三步:
- input:数据输入,即数据的采集过程;
- filter:和过滤器一样哎,明显是采集完数据后可以在中间对数据进行一定的处理;
- output:处理完的数据当然是要输出啦,输出到指定的存储位置;
logstash和ES的关系很密切,一个常用的功能就是完成数据库和ES数据的同步,免去了我们手动同步的麻烦。
我们通过配置logstash,来监听数据库中单表,多表的更新变化,它本质上是一个定时器,实现简单,MQ实现ES与数据库同步则是实时性的、复杂性更高的、一致性强的。此处,我收回前言中提到的,Redis通过MQ来保存日志不是MQ本身功能的话,这话欠妥了。因为保存日志虽然是logstash的功能,但它也是通过封装一些实现来完成这个功能的。
在监听数据表变化的时候,我们需要规范的数据表结构。这段话我看到很多人都有说,博主觉得也对,但也不对,logstash在工作的时候确实需要监控表中某字段变化,但也不是说名字要固定为某字段,其实这个column是可以在配置中指定的,毕竟每一个人对数据的定义都不一样,出现名字不同的情况时有发生。
不过在使用logstash的时候也出现了一些不一样的声音。Logstash运行内存较大,占用CPU过高,影响性能,其还没有消息队列缓存,有数据丢失的隐患。基于此,出现了两种情况:
一类人选择对logstash进行调优,推荐这篇博客可以看看:ELK下之Logstash性能调优(从千/秒=>万/秒=>10万/秒
另一类人选择ELK + Filebeat,Filebeat会将日志数据收集并结构化后传输到Logstash上,如果filebeat直接传输给es,就会占用掉es的大量资源。这种工作方式推荐这篇博客看:基于ELK搭建网站实时日志监控平台
怎么办,感觉那两篇博客写的都比博主写的好啊,还更详细,如果有用,博主也不介意大家过去看哈,学习的目的是学会,而不是为了流量。即使如此,博主还是要硬着头皮把这篇博客写完。突然想到,要是我不去搜集资料,大家也看不到这么优秀的博文,我就是那个引路人,我太棒了。
K
K是Kibana,是ES的可视化工具,日志系统总不能一个个文件打开来看,这很不友好,这个可视化工具可以很好的帮到我们,我们可以在里面对需要的信息进行筛选过滤,快速查抄需要的有效信息。
Kibana的安装并不复杂,但有一个条件,需要和ES的版本保持一致。logstash则没有这样的要求,但为了好看,也保持一致吧。
L和E的那些事
都写到这里了,要给大家提一嘴,ELK不需要添加任何Java代码,全部通过配置完成。
当安装好软件,做好配置之后,logstash会自动监听配置中指定的表的字段,只要该字段发生变化,logstash就会收集变化行的信息,并周期性的向ES进行提交,ES中的数据就会自动和数据库中的变化数据同步了。
logstash的监听是通过Mybatis拦截器统一处理监听字段,一般是更新时间字段,在字段变化时就可以被监听到,这个可以解决监听非时间字段时,修改某数据时监听不到的的情况。
以上数据同步功能在ES中我们没有讲过,实际上这个问题也是很麻烦,不通过ELK,就需要手动去完成数据的同步,这是非常麻烦的。
除了上面提到的,还有一个很有意思的功能,比如我们有多个字段做了分词,当需要搜索某个词的时候需要对这几个做了分词的字段分别进行搜索关键词操作,logstash则简化了此步骤,它会将做了分词的几个字段合并成一个叫search_text的字段,所以在使用了ELK时,搜索关键词时,直接搜索search_text字段即可。
安装使用
E
关于ES的Docker安装启动,可在Docker中搜索elasticsearch,选择8.5.2版本,pull,下载完之后打开终端,输入:
docker run --name es -d -e ES_JAVA_OPTS="-Xms1g -Xmx1g" -e "discovery.type=single-node" -p 9200:9200 -p 9300:9300 elasticsearch:8.5.2ES_JAVA_OPTS="-Xms1g -Xmx1g" 配置启动时内存大小,不配置的话默认是2G。
L
关于logstash的Docker安装启动,可在Docker中搜索logstash,选择8.5.2版本,pull,下载完之后打开终端,输入:
docker run -d --name logstash -p 4560:4560 logstash:8.5.2
k
关于kibana的Docker安装启动,可在Docker中搜索kibana,选择8.5.2版本,pull,下载完之后打开终端,输入:
docker run --name kb -d -p 5601:5601 kibana:8.5.2登录kibana
登录kibana时会提示如下问题:

且我们也没设置过账号密码,提示需要去配置kibana.yml文件?博主跟着网上做了一大堆配置,发现最后都没有用,所以暂时不要去动他们的yml文件,就用原来的,先配置好基础的信息再说,点击forget password,弹出提示信息让我们在es中设置密码,在终端输入:
docker exec -it es /bin/bash
bin/elasticsearch-reset-password --username kibana

会给你生成一个New value,上面账号填kibana,密码就是这个新的New value,点Conform按钮,就出现了下面的配置成功页面:
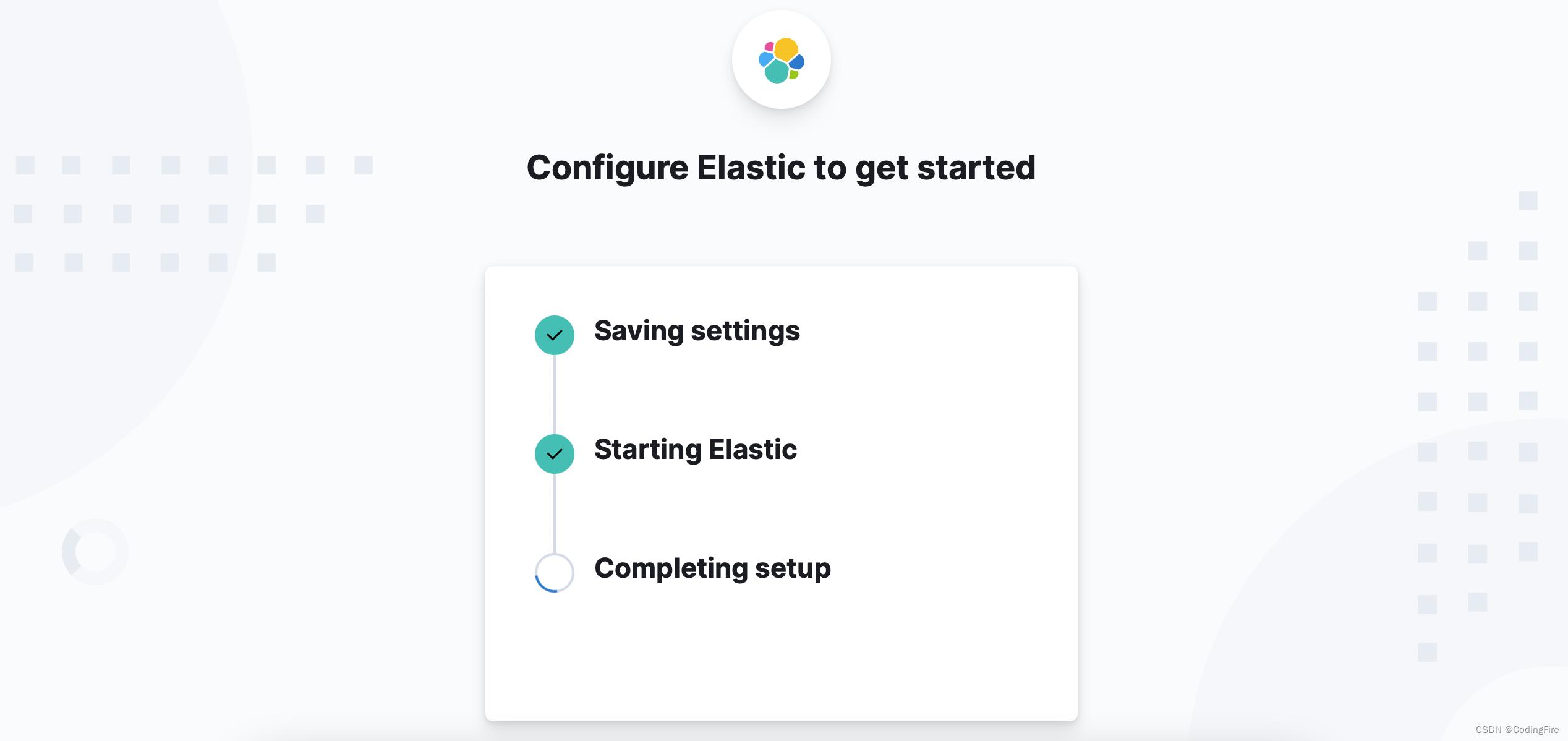
配置成功后,又出现问题了:
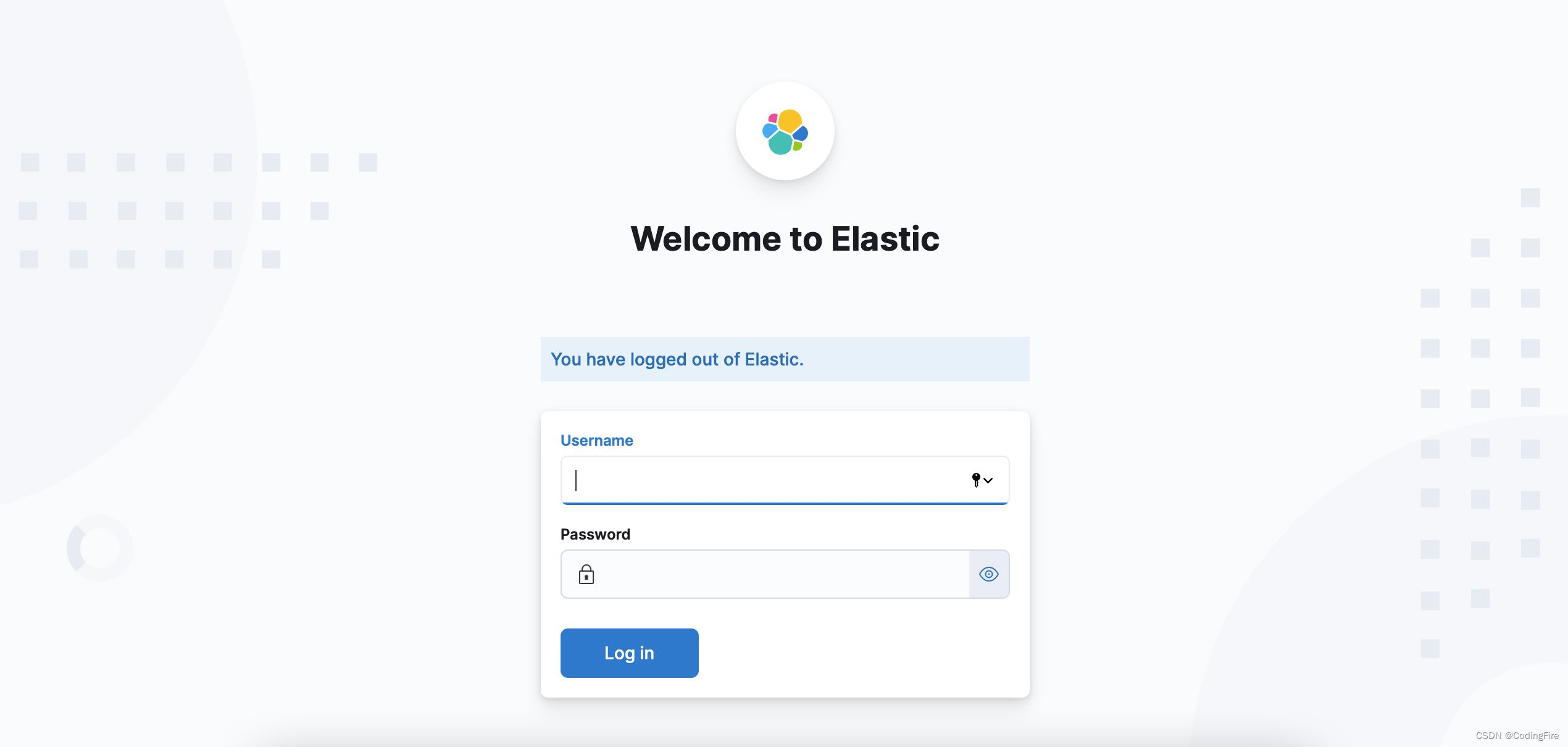
怎么又出现了一个登录页面,我们真的没有设置密码呀,这时候,只能去添加密码了,发现了一个问题,后面再说,先说添加密码。其实在es启动时,就生成了一个elastic的超级用户,密码我们需要用同样的方式直接生成:
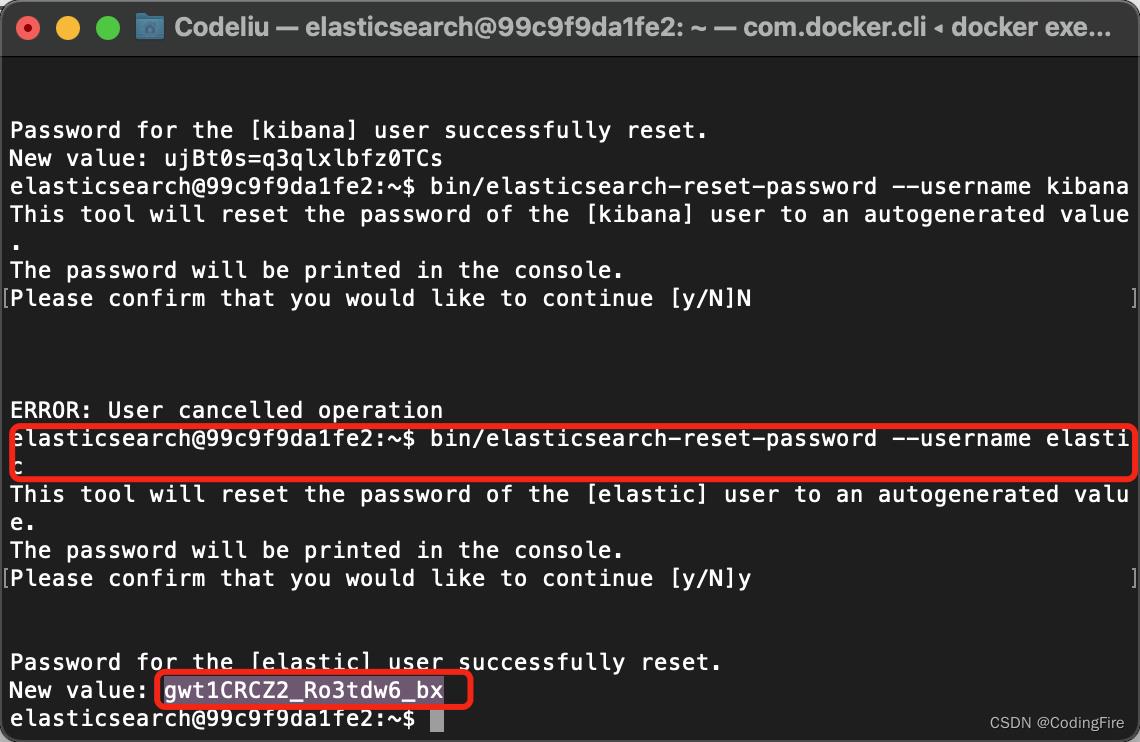
用这个用户和密码登录:
天可怜见,终于进来了。现在说说刚刚的问题是啥,通过官方的博客:Elastic:使用 Docker 安装 Elastic Stack 8.x 并开始使用
发现我们和官方进入的方式不太一样:
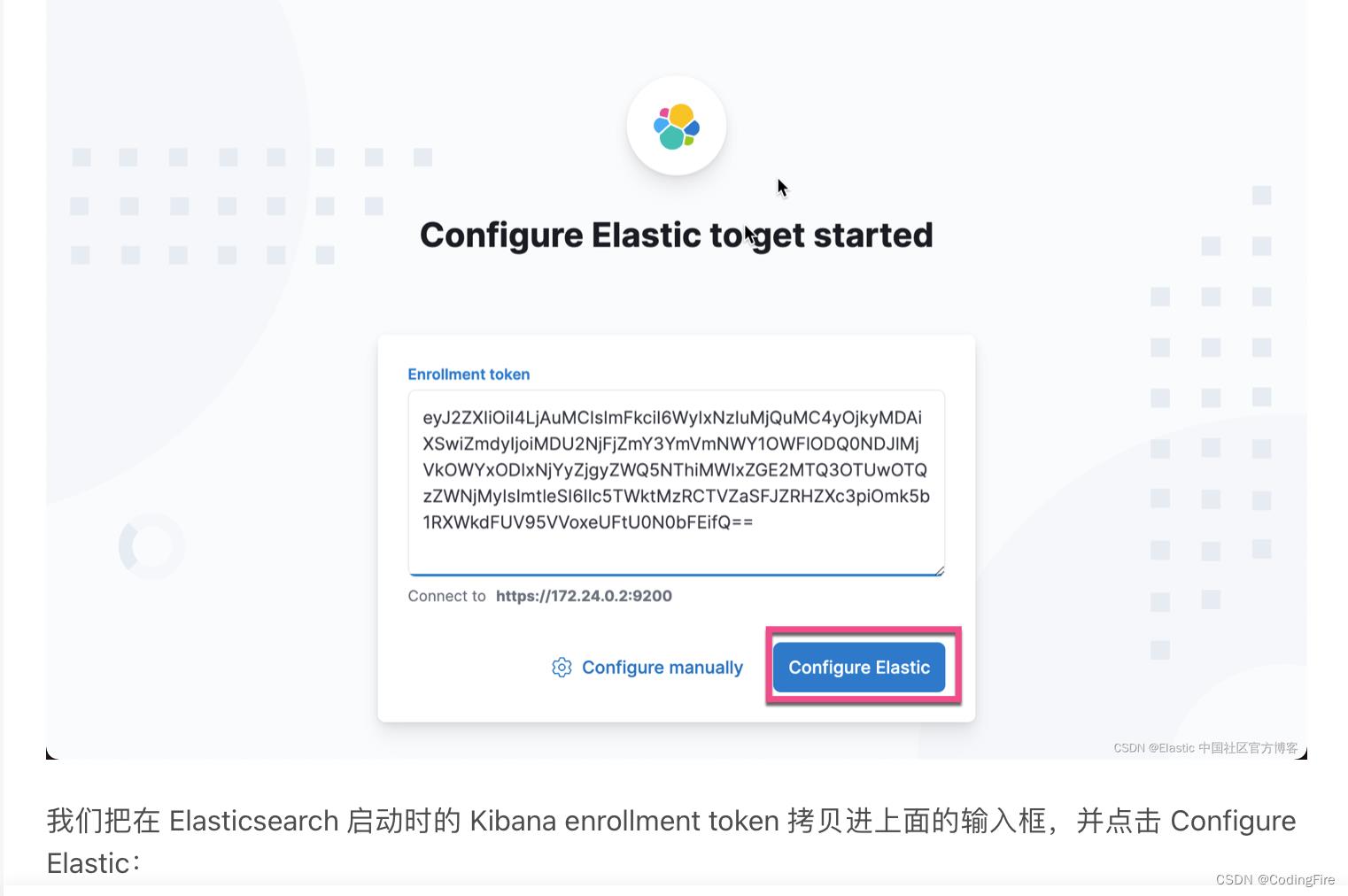
官方是通过token令牌完成配置的,而我们是通过设置kibana进来的,不知道这两种有什么差别,猜测应该属于登录后自动获取的登录令牌进来的,大家知道的可以留言告诉博主。
关于这个问题,我们在后台的用户管理列表发现了一点端倪:
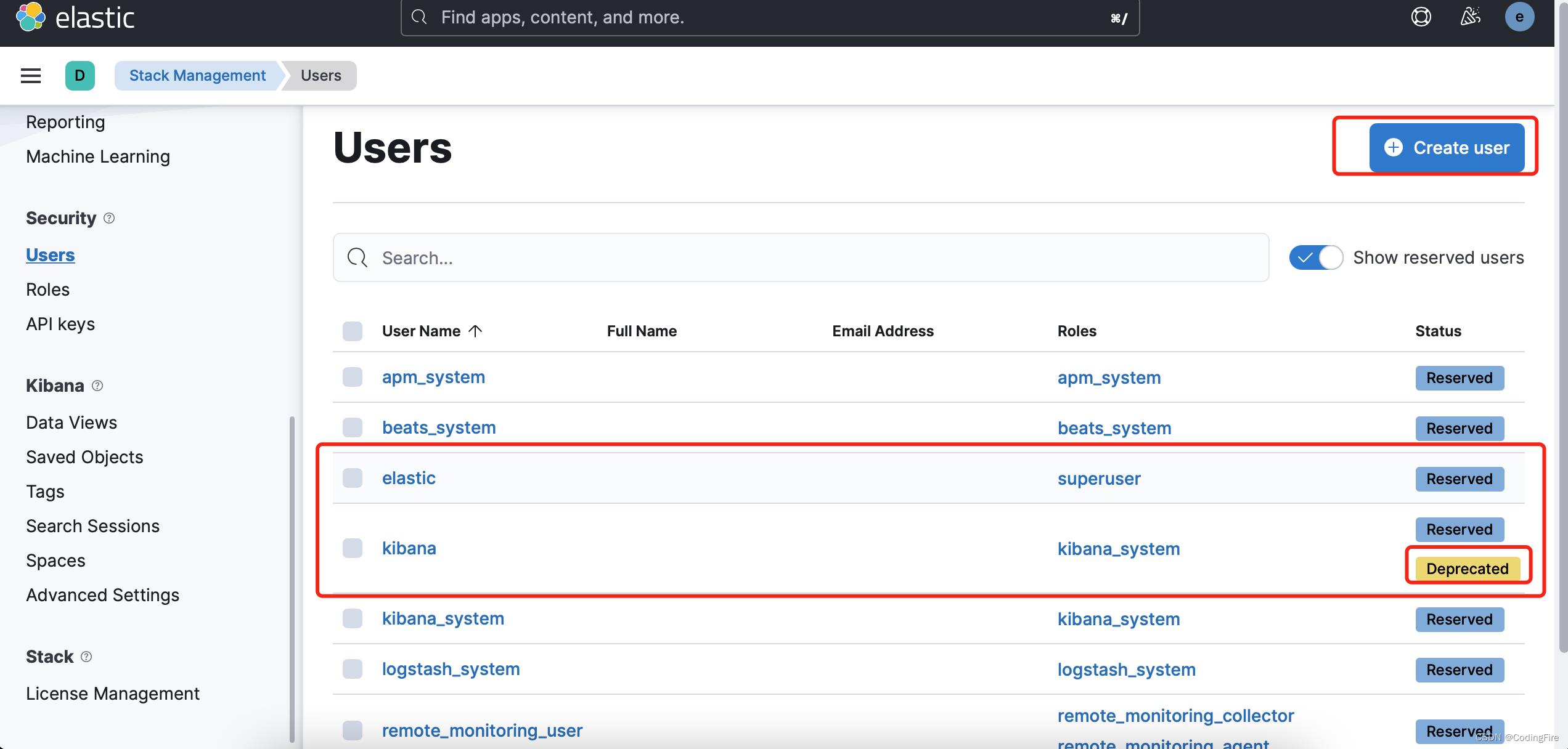
kibana用户已经被禁止使用了,在这里我们也可以手动添加用户,而已经存在的用户则是不能进行编辑的,应该是留给其他服务用的默认账户密码,官方不希望我们修改,怕引起其他的错误。
结语
如果自己做,还是推荐官方的做法。到此,他们之间的安装和基础配置算是完成了。关于kibana的使用,可以参见上面那篇博客,博主试了下可以的,更多使用方式,大家可自行查找,博主后期也会出一些详细案例教程出来,真是不容易啊,各种坑,对了如果实在要修改yml文件,你会遇到几个问题,顺带说下:
vim文件无法打开yml文件,需要安装vim,安装时提示你没有权限,这时候进入容器要通过此命令:
docker exec -it -u 0 xxxxx /bin/bash
介入后安装vim:
docker stop es-node01
docker stop kib-01
这时候就可以通过vim打开yml文件了,比较坑的是,每个容器都需要这么做一遍,目前还没找到好的解决办法,有好的解决办法的小伙伴请不吝赐教。
关于ELK,也是博大精深的东西啊,微服务中每一项都不可小觑,是在下孟浪了,学无止尽,学无止尽啊,你我共勉。
Java开发 - 配置中心初体验
目录
前言
前文讲了ELK,ELK说简单也简单,说复杂也复杂,但说实话,微服务里这么些个东西,从部署角度来看,比起Dubbo,Nacos这些,ELK算是比较难的一个了,上一篇博客博主也只是简单的讲解了安装,关于具体使用还差得很远。所以里面推荐了官方的账号,官方的账号里面内容很多很大,需要耐心去学习。博主还是推荐大家去官方的c站账号下学习,又具体又全面,而且还不会有问题。开始新的学习前,那喊两声:ELK牛逼,ELK真难,加油!加油!
配置中心介绍
配置中心我们也是针对微服务来说的,所以这个配置中心当然是微服务的配置中心,下面,我们就来说说什么是配置中心。
什么是配置中心
就像文字描述的那样,配置中心主要用来解决配置问题,在微服务项目中,我们的配置一般是写在yml文件或者properties文件中的,这是我们所熟知的一种写法。
有时候,多个子项目共用一个配置的时候,当需要修改时,往往需要去修改每一个子项目的配置,搞不好还会改错,这时候,如果能有一个地方可以统一修改,全部生效,那该是多么轻松啊,这就是配置中心的作用。
总结一下就是:配置中心能够达到高效修改各模块配置的作用。
Nacos配置中心
Nacos我们都知道,我们前面微服务中已经学过,我们知道Nacos是注册中心,所有的子项目都在Nacos服务器上留下了自己的身份信息,所以Nacos就可以尝试对已知的服务器做一些管理,比如配置。
Nacos作为配置中心支持的文件格式很多,除了我们所熟悉的properties,yml,还支持txt,json,xml等,实际我们可能用不到那么多。
数据结构
Nacos数据结构,简单分,可以分为三个部分,分别是:命名空间,分组,服务。
命名空间
命名空间又命Namespace,是Nacos提供的最大的数据结构,一个Nacos可以有多个命名空间,命名空间也可以有多个分组,命名空间在Nacos中可自行创建,创建方法见下方:

我们创建的命名空间叫:

要注意,默认的public命名空间不能删除和修改,你也无法删除和修改。只要自己创建了命名空间,注册Nacos时就可以指定可注册到的命名空间名称了。好处就是,多个命名空间可以对项目起到隔离的作用,使他们之间互不干扰。
要切换命名空间,请看下图:
分组
命名空间中,我们说,一个命名空间可以有多个分组,分组的作用就是对他们做进一步的隔离,不需要额外的分组时,分组名可自定义,我们一般推荐使用:DEFAULF_GROUP。细心的小伙伴会发现,这在我们微服务项目中也是有使用的。
服务
当命名空间和分组名称都确定之后,就可以添加服务和配置了,我们微服务中的各模块就是服务,默认保存在public命名空间下,下面我们就用配置中心功能来修改下配置的位置,设置了命名空间,其实就是设置命名空间ID,这在我们的命名空间截图中是有体现的,大家可以翻上去看一看。
值得一提的是,配置中心的优先级高于项目中已有的yml等配置文件的优先级。这一点,我们在下面会继续讲他们的优先级,这决定了他们的生效顺序。
配置中心添加配置
下面,我们来添加一下配置,就以我们前面学的微服务项目中的cart模块为例,下面开始添加配置:
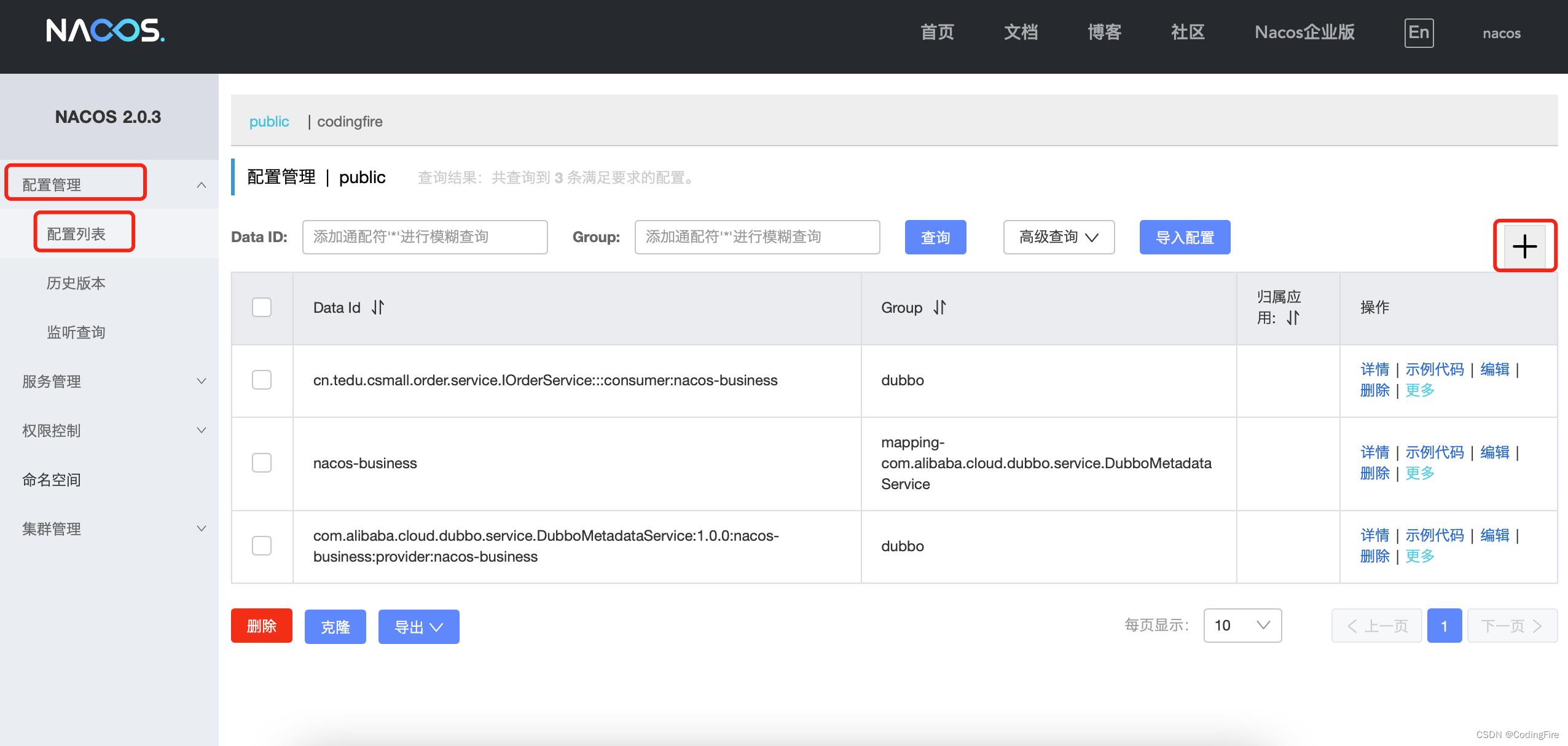
配置管理-配置立列表-右上方+号,点击后进入下面的页面:
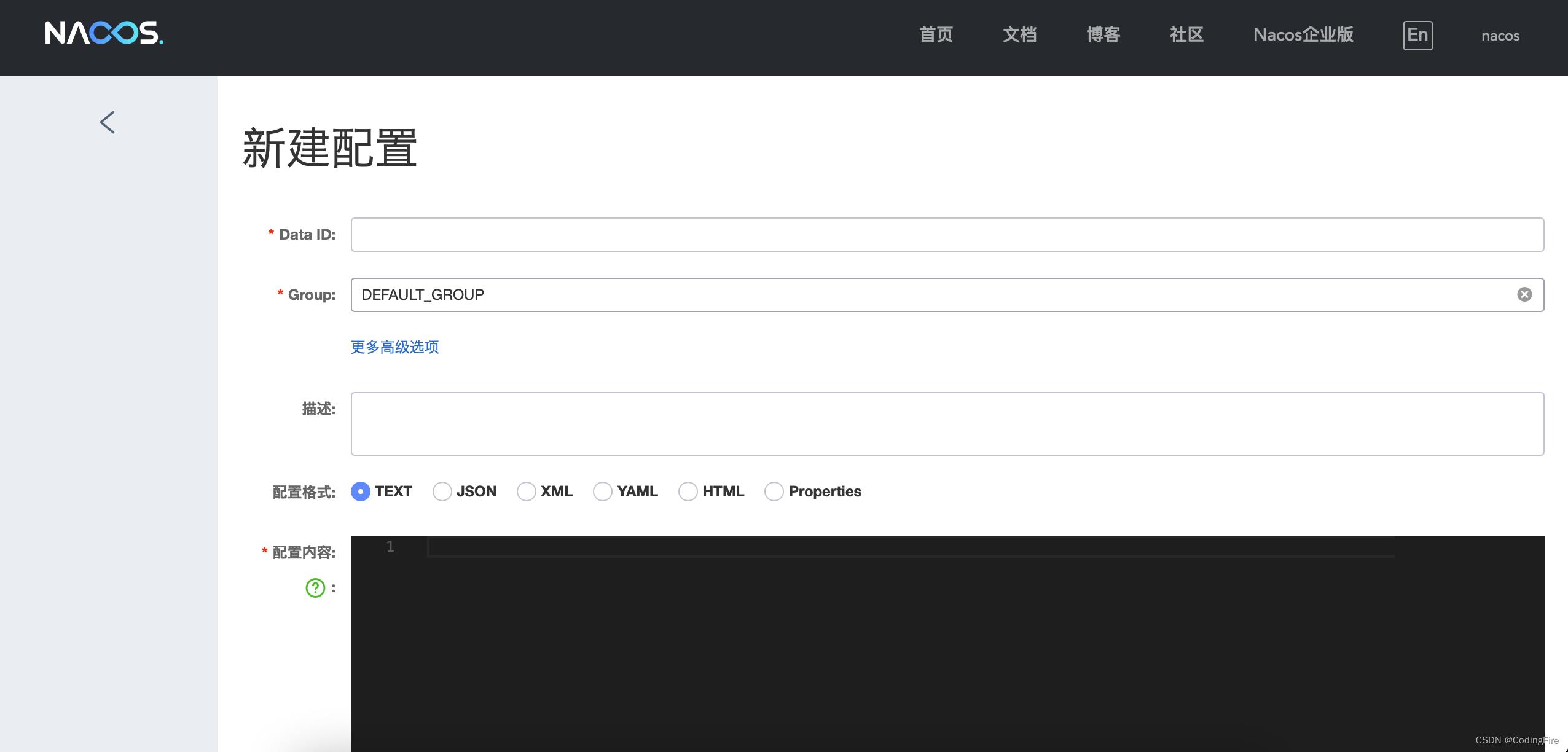
Data ID就是该配置的名字,可自定义,建议名称格式:nacos-cart.yaml。
Group默认为我们推荐的名称,没有其他分组的情况建议使用默认的,避免搞乱。
配置格式我们建议选YAML,这种格式的层级效果明显,便于观察,主要是现在仅支持YAML和Properties。
配置内容,根据需要把我们本地的配置文件中的内容填写进来。
这里为了测试效果,我们不会把整个配置文件都贴进去,其实贴进去也可以,但为了看效果,我们只把数据库链接部分的配置贴进去,同时把本地文件中数据库部分删除。
像这样:

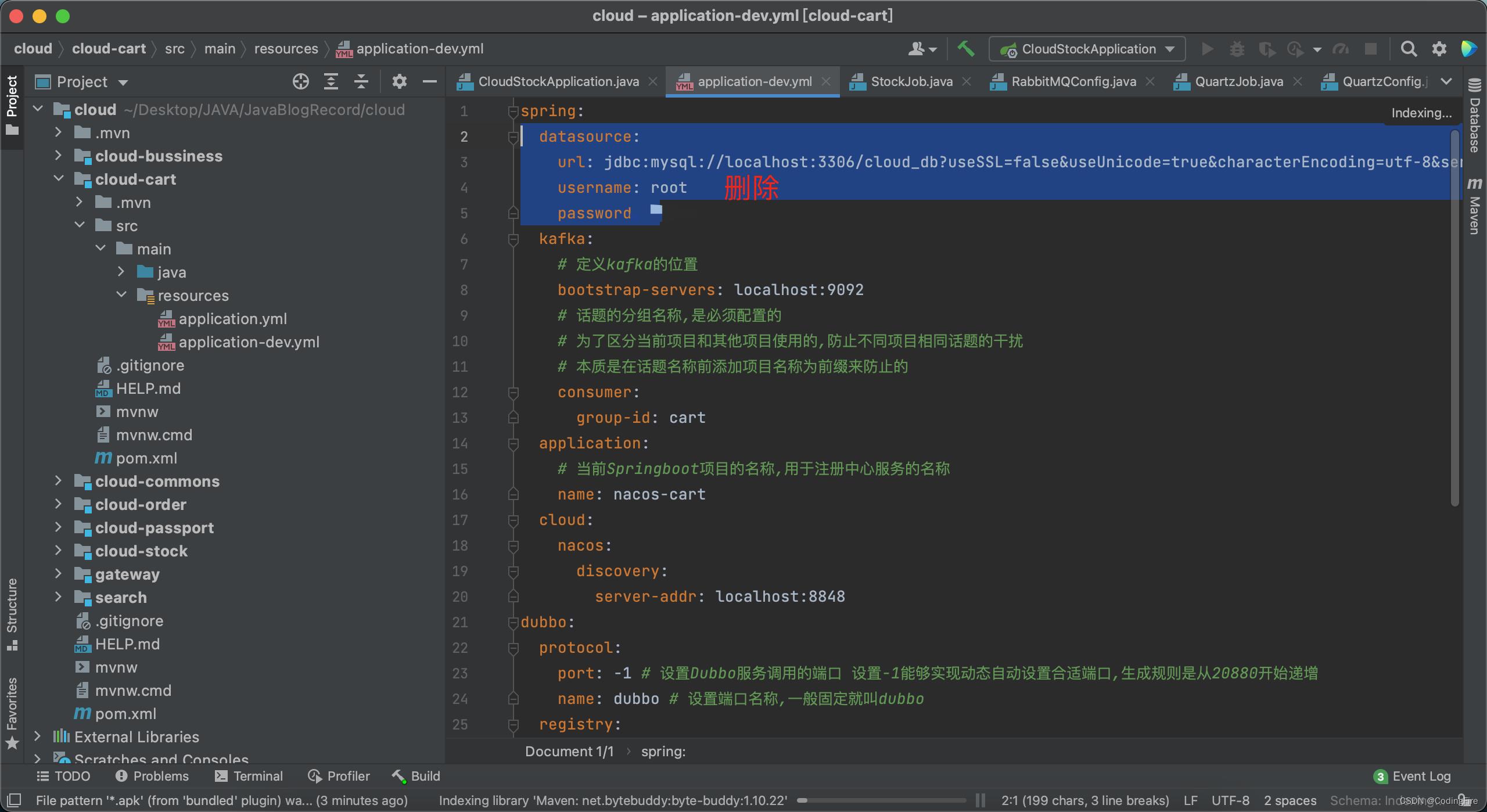
读取配置
做完这些还不够,配置中心还不能够正常工作,还需要两步来完成读取配置,让配置中心工作。万丈高楼平地起,虽然前期麻烦一点,但是后面香啊。
本地添加依赖
<!-- 配置中心的依赖 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!-- 支持SpringCloud加载系统配置文件的依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
本地添加配置
添加配置时,需要我们新建一个file,名字叫bootstrap.yml,千万别写错了,创建成功后前面的logo也是一片叶子,不同的是右下角是个云的标志:
接着在这个文件中添加配置信息:
spring:
cloud:
nacos:
discovery:
server-addr: localhost:8848
config:
# 指定配置中心的位置
server-addr: localhost:8848
# 指定配置文件所在的组名(命名空间默认public不需要指定)
group: DEFAULT_GROUP
# 设置配置文件的后缀名
# 默认情况下会加载[项目名].[后缀名]为DataId的配置
# 当前项目名称为nacos-cart所以默认加载的DataId为:nacos-cart.yaml
file-extension: yaml
这里里面的文字部分,很重要,特别是group和文件扩展名:
不要纠结这个名字,如果你想要,你可以随便写名字,然后在配置中配置名字:
spring:
cloud:
nacos:
config:
name: xxxxx
最后一定要点击发布:

发布成功后会有如下提示,接下来就可以准备测试环节了:

测试
测试很简单,运行你的功能就可以了,在此之前,请启动需要开启的服务,如Nacos,seata等,看自己项目需要开启。运行后,只要cart模块能正常运行并工作,你的测试就是成功的,我们在cart中引入了knife4j,它能正常工作,就代表测试是成功的,不再贴测试结果了,请大家严格自行完成测试。
优先级说明
简单来说,bootstrap.yml>bootstrap.properties>application.yml>application.properties。这是从项目启动到启动完成过程中,配置文件生效的先后顺序,可以看到,yml的优先级永远高于properties,bootstrap.yml优先级最高。
bootstrap这组配置文件有点特殊,一般是专门用于加载系统级别的配置,这些配置一般不会轻易修改。
特别注意,只有SpringCloud项目才能加载bootstrap的配置,加载这组配置也是需要依赖的,上面已经给出:spring-cloud-starter-bootstrap,不过我们给出的依赖是2020年之后的依赖,之前的依赖不是这个,是什么我就不说了,避免误导大家,感兴趣的可以查下。
结语
配置中心的使用整体上算是比较简单的,操作性也不强,只要细心一点就可以完成,难度指数只能算是一颗星了,想起上篇ELK博主就不免心中叹息,只怪博主ELK也没学到家,还不能够用最简洁的方式让大家快速学会,革命尚未成功,同志仍需努力,一起加油吧,童鞋们!
以上是关于Java开发 - ELK初体验的主要内容,如果未能解决你的问题,请参考以下文章