排序 - 将句子转化为数据 2 NLP 零到英雄 Sequencing - Turning sentences into data
Posted AI架构师易筋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了排序 - 将句子转化为数据 2 NLP 零到英雄 Sequencing - Turning sentences into data相关的知识,希望对你有一定的参考价值。











import tensorflow as tf
from tensorflow import keras
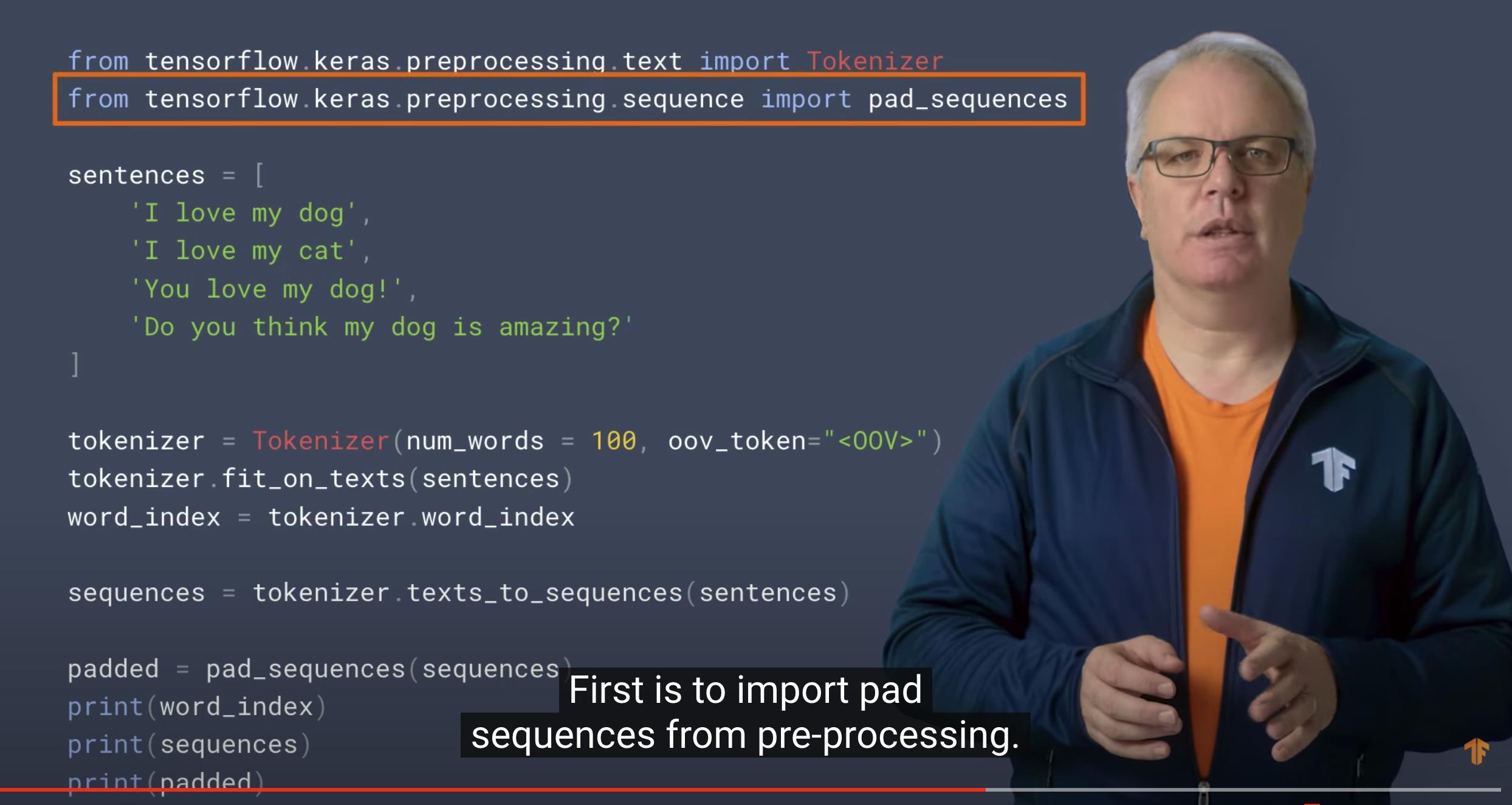
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
sentences = [
'I love my dog',
'I love my cat',
'You love my dog!',
'Do you think my dog is amazing?'
]
tokenizer = Tokenizer(num_words = 100, oov_token="<OOV>")
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(sentences)
padded = pad_sequences(sequences, maxlen=5)
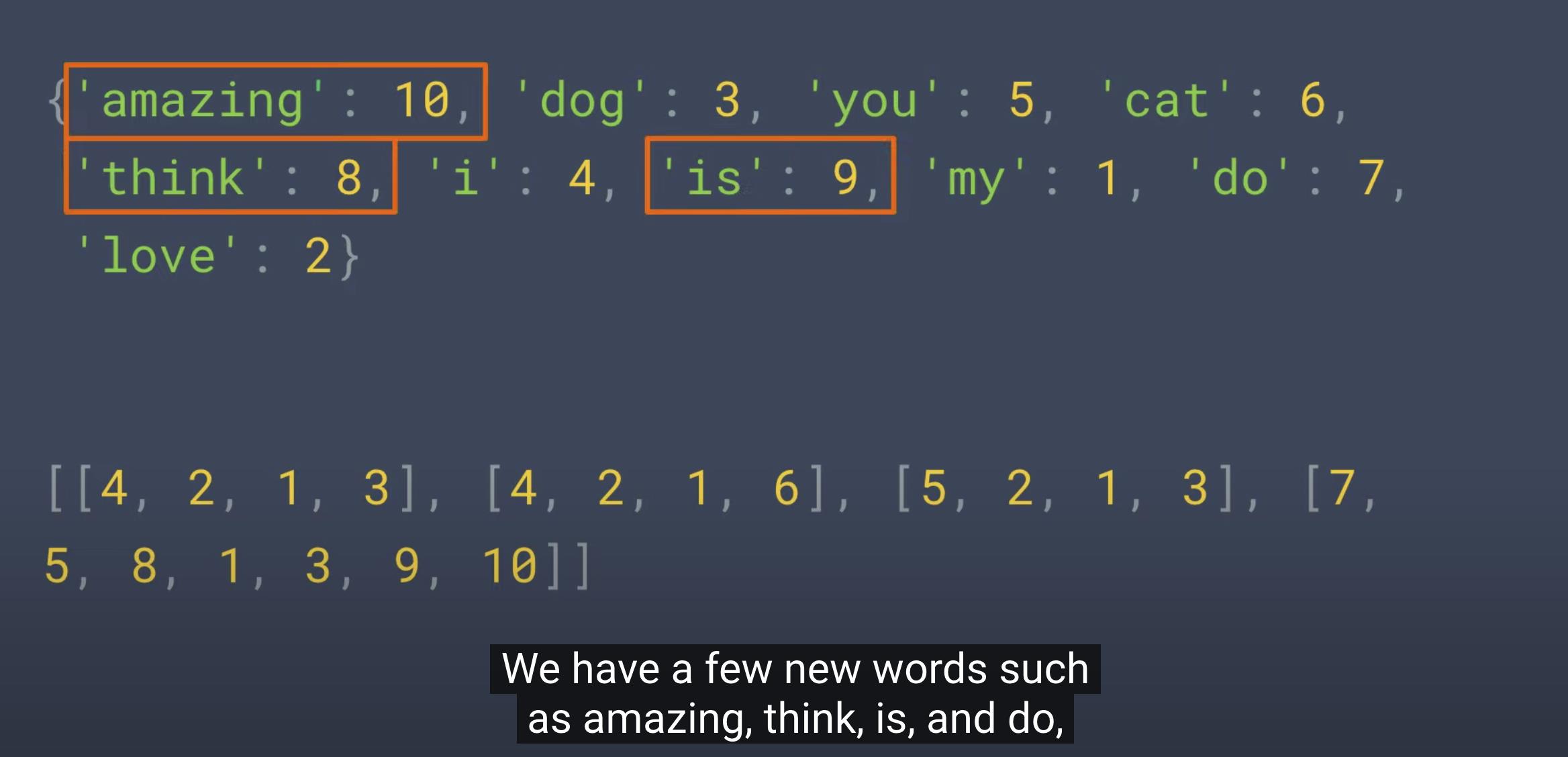
print("\\nWord Index = " , word_index)
print("\\nSequences = " , sequences)
print("\\nPadded Sequences:")
print(padded)
# Try with words that the tokenizer wasn't fit to
test_data = [
'i really love my dog',
'my dog loves my manatee'
]
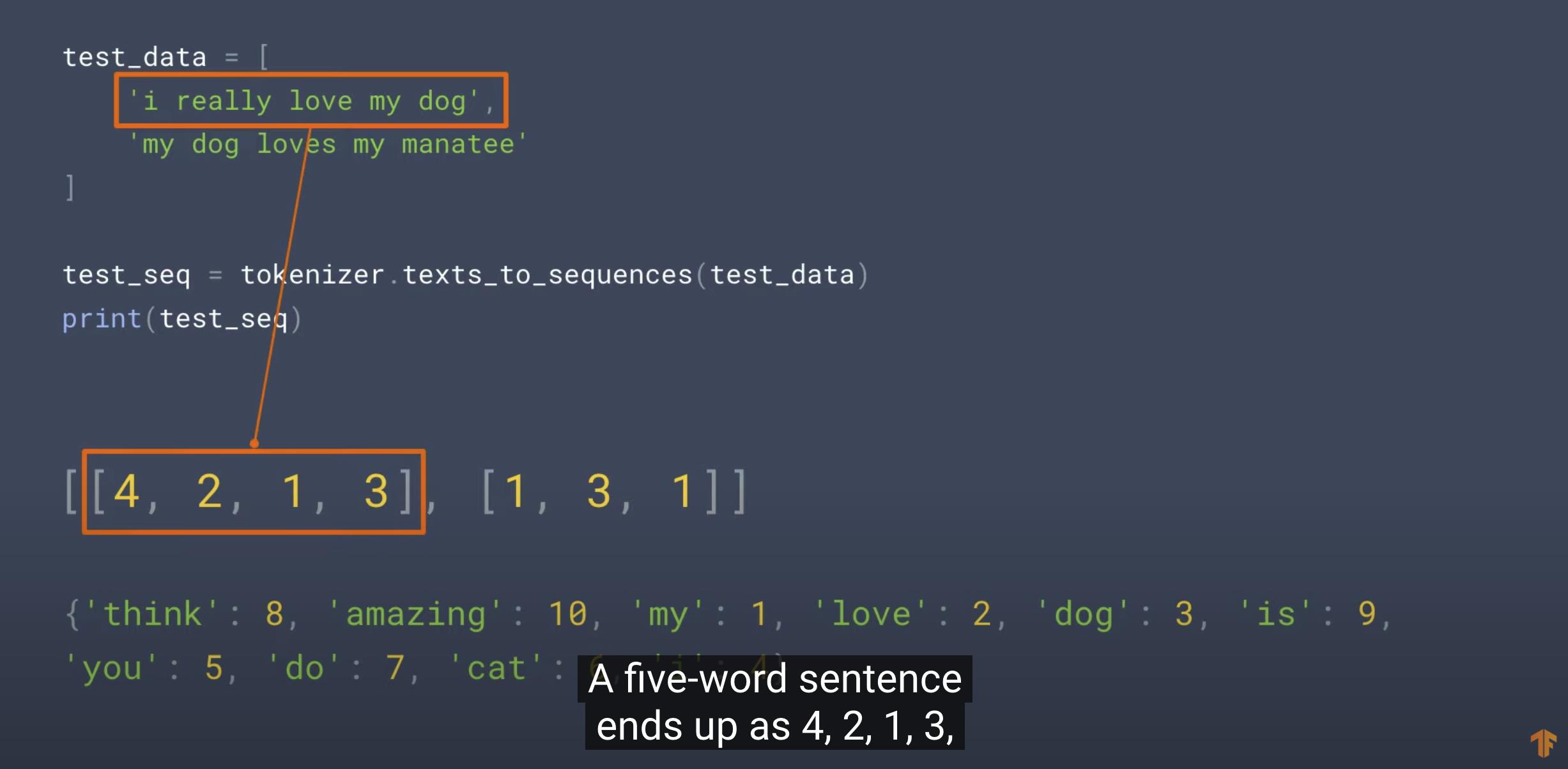
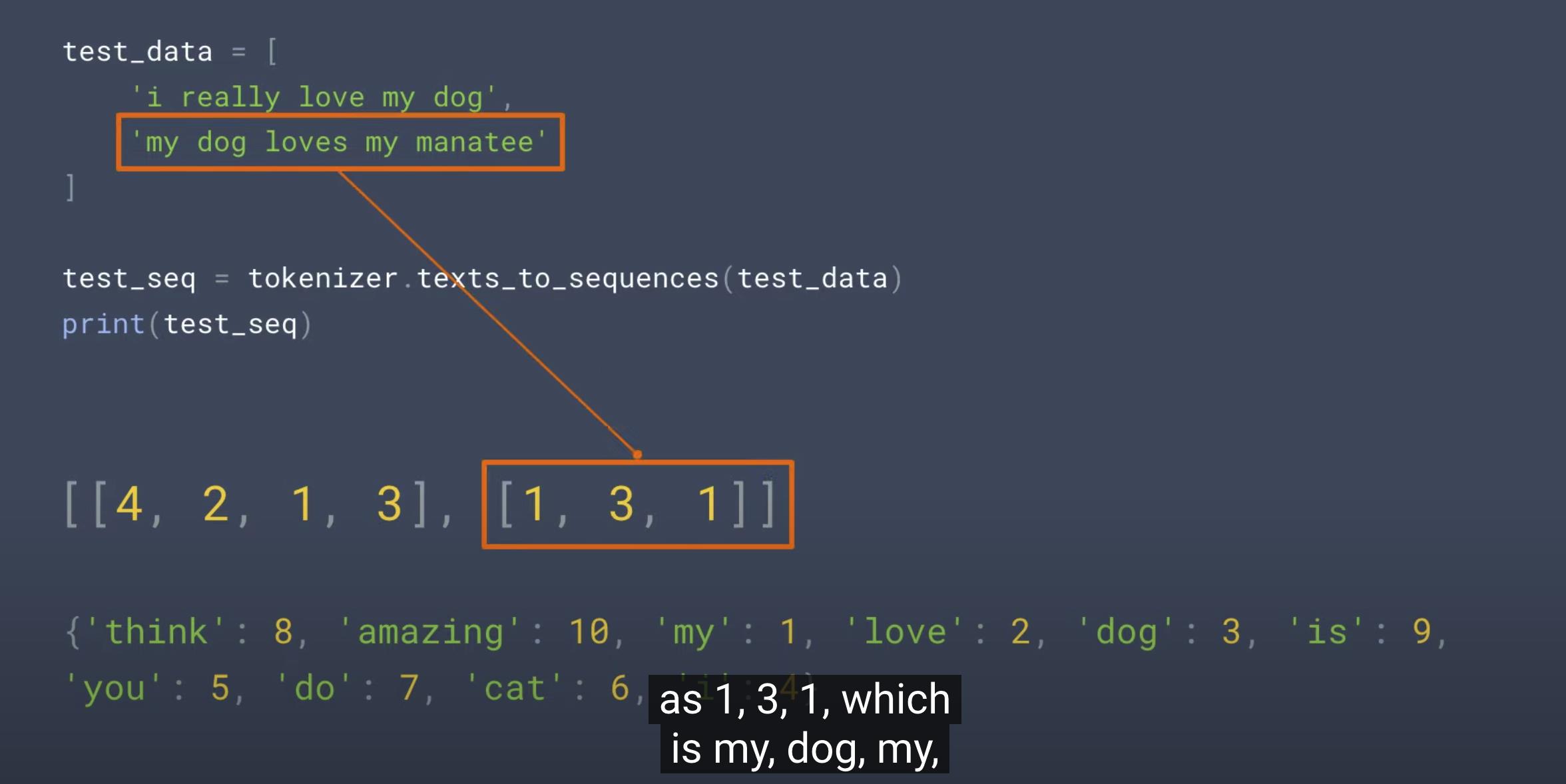
test_seq = tokenizer.texts_to_sequences(test_data)
print("\\nTest Sequence = ", test_seq)
padded = pad_sequences(test_seq, maxlen=10)
print("\\nPadded Test Sequence: ")
print(padded)
output
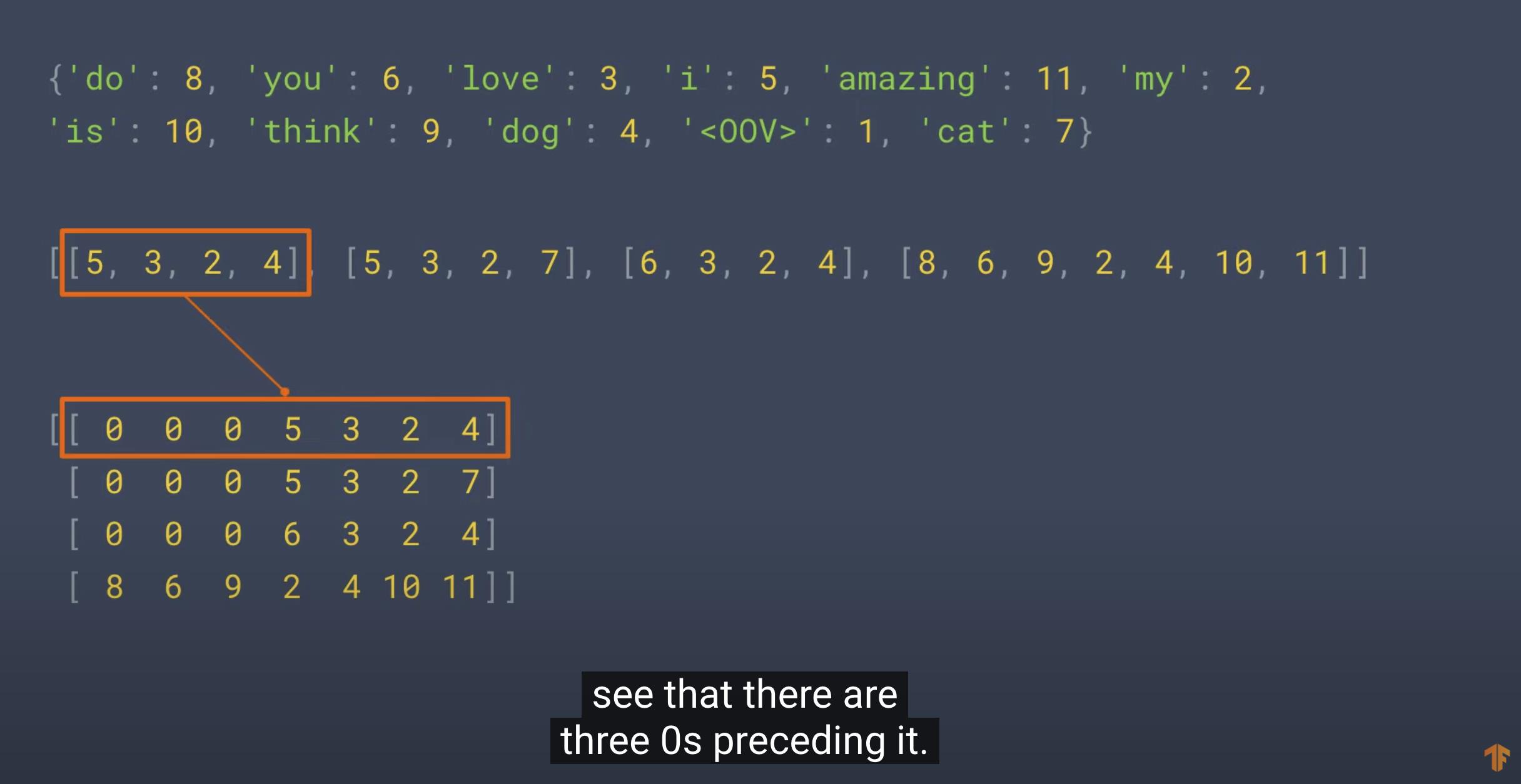
Word Index = '<OOV>': 1, 'my': 2, 'love': 3, 'dog': 4, 'i': 5, 'you': 6, 'cat': 7, 'do': 8, 'think': 9, 'is': 10, 'amazing': 11
Sequences = [[5, 3, 2, 4], [5, 3, 2, 7], [6, 3, 2, 4], [8, 6, 9, 2, 4, 10, 11]]
Padded Sequences:
[[ 0 5 3 2 4]
[ 0 5 3 2 7]
[ 0 6 3 2 4]
[ 9 2 4 10 11]]
Test Sequence = [[5, 1, 3, 2, 4], [2, 4, 1, 2, 1]]
Padded Test Sequence:
[[0 0 0 0 0 5 1 3 2 4]
[0 0 0 0 0 2 4 1 2 1]]
参考
https://youtu.be/r9QjkdSJZ2g
以上是关于排序 - 将句子转化为数据 2 NLP 零到英雄 Sequencing - Turning sentences into data的主要内容,如果未能解决你的问题,请参考以下文章