scikit-learn : GBR (Gradient boosting regression)
Posted 搬砖小工053
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scikit-learn : GBR (Gradient boosting regression)相关的知识,希望对你有一定的参考价值。
背景
梯度提升回归(Gradient boosting regression,GBR)是一种从它的错误中进行学习的技术。它本质上就是集思广益,集成一堆较差的学习算法进行学习。有两点需要注意:
- 每个学习算法准备率都不高,但是它们集成起来可以获得很好的准确率。
- 这些学习算法依次应用,也就是说每个学习算法都是在前一个学习算法的错误中学习
准备模拟数据
我们还是用基本的回归数据来演示GBR:
import numpy as np
from sklearn.datasets import make_regression
X, y = make_regression(1000, 2, noise=10)GBR原理
GBR算是一种集成模型因为它是一个集成学习算法。这种称谓的含义是指GBR用许多较差的学习算法组成了一个更强大的学习算法:
from sklearn.ensemble import GradientBoostingRegressor as GBR
gbr = GBR()
gbr.fit(X, y)
gbr_preds = gbr.predict(X)很明显,这里应该不止一个模型,但是这种模式现在很简明。现在,让我们用基本回归算法来拟合数据当作参照:
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X, y)
lr_preds = lr.predict(X)有了参照之后,让我们看看GBR算法与线性回归算法效果的对比情况。图像生成可以参照第一章正态随机过程的相关主题,首先需要下面的计算:
gbr_residuals = y - gbr_preds
lr_residuals = y - lr_preds%matplotlib inline
from matplotlib import pyplot as pltf, ax = plt.subplots(figsize=(7, 5))
f.tight_layout()
ax.hist(gbr_residuals,bins=20,label='GBR Residuals', color='b', alpha=.5);
ax.hist(lr_residuals,bins=20,label='LR Residuals', color='r', alpha=.5);
ax.set_title("GBR Residuals vs LR Residuals")
ax.legend(loc='best');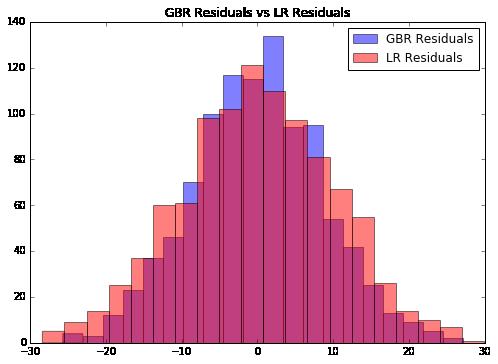
看起来好像GBR拟合的更好,但是并不明显。让我们用95%置信区间(Confidence interval,CI)对比一下:
np.percentile(gbr_residuals, [2.5, 97.5])array([-17.14322801, 17.05182403])
np.percentile(lr_residuals, [2.5, 97.5])array([-19.79519628, 20.09744884])
GBR的置信区间更小,数据更集中,因此其拟合效果更好;我们还可以对GBR算法进行一些调整来改善效果。我用下面的例子演示一下,然后在下一节介绍优化方法:
n_estimators = np.arange(100, 1100, 350)
gbrs = [GBR(n_estimators=n_estimator) for n_estimator in n_estimators]
residuals =
for i, gbr in enumerate(gbrs):
gbr.fit(X, y)
residuals[gbr.n_estimators] = y - gbr.predict(X)f, ax = plt.subplots(figsize=(7, 5))
f.tight_layout()
colors = 800:'r', 450:'g', 100:'b'
for k, v in residuals.items():
ax.hist(v,bins=20,label='n_estimators: %d' % k, color=colors[k], alpha=.5);
ax.set_title("Residuals at Various Numbers of Estimators")
ax.legend(loc='best');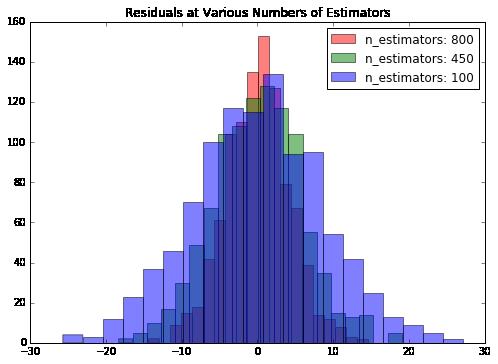
图像看着有点混乱,但是依然可以看出随着估计器数据的增加,误差在减少。不过,这并不是一成不变的。首先,我们没有交叉检验过,其次,随着估计器数量的增加,训练时间也会变长。现在我们用数据比较小没什么关系,但是如果数据再放大一两倍问题就出来了。
GBR参数设置
上面例子中GBR的第一个参数是n_estimators,指GBR使用的学习算法的数量。通常,如果你的设备性能更好,可以把n_estimators设置的更大,效果也会更好。还有另外几个参数要说明一下。
你应该在优化其他参数之前先调整max_depth参数。因为每个学习算法都是一颗决策树,max_depth决定了树生成的节点数。选择合适的节点数量可以更好的拟合数据,而更多的节点数可能造成拟合过度。
loss参数决定损失函数,也直接影响误差。ls是默认值,表示最小二乘法(least squares)。还有最小绝对值差值,Huber损失和分位数损失(quantiles)等等。
以上是关于scikit-learn : GBR (Gradient boosting regression)的主要内容,如果未能解决你的问题,请参考以下文章