cassandra 查询超时
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了cassandra 查询超时相关的知识,希望对你有一定的参考价值。
参考技术A在对某个表做count时出现如下错误(在做业务性测试,生产环境请不要简单粗暴做count操作,耗时还可能不准)
很奇怪,另外一个表应该是跟他相同条数的,都能直接count出来,但是当前表count一直报错,而且数据还差2两条(跟ES里面的数据对比后得知)
在网上可以直接查询相关问题,结果也出来了很多。其中我给出几个具有参考性的链接
其中第一个链接其实已经反映了我这次的问题,但是我第一眼看到这个答案并没有感觉到确切符合我当前的问题,然后后面看到第二个链接时,明白了去哪儿看日志。
在 cassandra system.log 看到了count产生的日志,前面后后观察了很长的日志,结果会出现如下一些情况
上面是3个有不同于常见日志的信息,下面是常见的日志信息
这个问题曾经以为被定位到问题,但是最终却发现还是无能为力。这里说下历程
第一次以为找到缘由
做count 操作操作时,就跟其他读操作一样,需要将数据加载到缓存中。数据来源包括 SSTables,tombstone标记,这些数据都放在缓存中。
缓存的大小由cassandra.yaml中的 file_cache_size_in_mb 设置控制。 默认大小为 512 MB
count出问题这张表是因为有一个字段存了很长的文本内容,count整个表时,将所有数据(完整的每行数据)加载到内存就导致内存不足。
第二次
根据上面的方式解决count超时不久后又发现超时,但这次却是不同之前说的两个表。这次没有再去调配置大小,而是在@玄陵 的指导下 跟踪了cpu idle 跟磁盘的 %util
在跟踪的过程中刚好出现 %util 达到 100% , 99% 的情况。然后他认为就是磁盘性能造成的超时。但是我跟踪了磁盘负载很高的时间刚好是定时任务在往cassandra里面写数据。那 %util 高应该是写入造成的,我在定时任务跑完然后再去执行count 也还是超时,所以我不太认同时磁盘性能造成count超时。当然,我们的确实存在磁盘性能,这个后续需要好好调优
无果
我之前执行count sql 时一直在 datagrip (一种cassandra的可视化管理)中操作。偶然想去cassandra 终端使用cqlsh执行,结果竟然有意外之喜
在cqlsh 首次执行也是超时,但是后面执行就能成功统计。而在datagrip中统计却一直出现超时错误。那这两个有什么表现不一样么
观察日志发现:在datagrip做操作时,system.log 会输出很多(全是查询的sql语句),而在cqlsh中进行统计时,发现system.log 竟然只有少量的日志输出,甚至没有常见的查询日志,也是异常奇怪。目前找不到更多原因,只能记录存档了。
对于这个问题花费了很多力气,查过缓存不足,tombstone太多,cpu, 硬盘。但最后我更倾向这个操作违反了cassandra的设计,cassandra 是分布式的,记录是分区存储。当在做 聚合查询 时 却没有带where 限制条件,那么很可能不能得到你预期的结果。count可以对一个数据量小小的table进行,但是数据量稍微大一点,可能就不能这么用了。
对于其他聚合查询请点击下面链接
解决
如果是业务层需要做count统计,需要根据分区键去做count
如果只是观察数据总条数,建议直接在cqlsh上进行统计(不要使用其他工具),当然这个也依然存在超时的问题。所以这里推荐 一个 非常好的统计工具 brianmhess/cassandra-count
这个工具通过使用numSplits参数拆分令牌范围,可以减少每个查询计数的数量并减少超时的可能性。
目前使用下来效果还非常不错
Cassandra优化之查询超时优化
节前将oracle数据迁移到cassandra后,查询表的总记录数(千万级以上),总会报超时错误,找了下相关资料,需要更改配置文件里的相关超时参数。
1、ReadTimeout-1200
cqlsh:spacewalk> select count(*) from rhnpackagecapability;
ReadTimeout: Error from server: code=1200 [Coordinator node timed out waiting for replica nodes‘ responses] message="Operation timed out - received only 1 responses." info={‘received_responses‘: 1, ‘required_responses‘: 1, ‘consistency‘: ‘ONE‘}
cqlsh:spacewalk> exit遇到此报错,只需增加以下几个参数的值:
[root@db03 ~]# vi /etc/cassandra/default.conf/cassandra.yaml
read_request_timeout_in_ms: 600000
range_request_timeout_in_ms: 600000
slow_query_log_timeout_in_ms: 600000
[root@db03 ~]# systemctl restart cassandra修改完成后,重启cassandra服务。再次查询,结果如下图: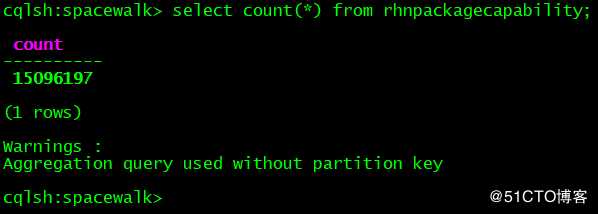
2、Client request timeout
系统默认的客户端请求时间是10秒,如果遇到此报错,需增加客户端请求超时。如下:
[root@db03 ~]# vi .cassandra/cqlshrc
...
[connection]
request_timeout = 600
....后续遇到类似错误还会继续更新此博文。
以上是关于cassandra 查询超时的主要内容,如果未能解决你的问题,请参考以下文章
即使在超时 10 秒后,当查询超过 10,000 行的键时,Cassandra 也会超时