AI上推荐 之 YouTubeDNN模型(工业界推荐系统的灯火阑珊)
Posted Miracle8070
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI上推荐 之 YouTubeDNN模型(工业界推荐系统的灯火阑珊)相关的知识,希望对你有一定的参考价值。
1. 写在前面
这个系列很久没有更新了, 主要是前段时间经历了一波秋招, 后面的方向可能稍微偏数据挖掘和cv多一些,所以向这两块又稍微延展了一下,没来得及看推荐相关的论文,这次借着和如意大佬整理fun-rec项目的机会, 才重新又看起了之前一直想整理的经典模型, 对于推荐, 还是想把之前学习的知识沉淀下来的, 当然,可能后面的整理比较适合像我一样的初学者了吧,想法还是以经典paper解读为主, 学习一些新思想,并进行NLP, 推荐,cv, ML和DL等各种知识的串联。
关于后面的整理, 我也梳理了一个思维框架:

这是我经过了实习和学习推荐相关理论知识后,按照自己的理解对工业推荐系统需要的硬性知识做的一个思维导图
“热追"推荐算法的特色是从实际应用的角度去梳理推荐系统领域目前常用的一些关键技术,主要包括召回粗排,精排,重排以及冷启动,这几个差不多撑起了工业界推荐系统的流程。召回的目的是根据用户部分特征,从海量物品库,快速找到小部分用户潜在感兴趣的物品交给精排,重点强调快,精排主要是融入更多特征,使用复杂模型,来做个性化推荐,强调准, 但有时候,排序环节的速度是跟不上召回的,所以往往也可以在这两块直接加一个粗排,用少量用户和物品特征,对召回结果再先进行一波筛选。 而重排侧,主要是结合精排的结果,再加上各种业务策略,比如去重,插入,打散,多样性保证等,主要是技术产品策略主导或改善用户体验的。 所以这四个环节组合起来,以"迅雷不及掩耳漏斗之势”,组成了推荐系统的整个架构。
这个漏斗架构在YoutubeDNN这篇paper中见到了雏形,借着寒假在家的这段时间, 这个系列想继续学习,继续完善,争取把它沉淀好。 主要包括两大块吧:
- 理论知识方面: 按照上面的思维导图, 继续整理一些非常重要的推荐模型,重点还是以学习思想为主, 知其然以及所以然, 比如这次整理的YouTubeDNN, 王喆老师都称其为神文, 还要精排侧一些多目标的模型(MMOE, ESSM),以及召回侧其他的一些模型,比如经典的双塔结构, MIND等, 我觉得这些paper里面的精华在于思想,即使后面不做推荐,做数据挖掘甚至cv, 思考问题的方式本质上应该是差不多的
- GitHub模型代码复现方面: 这块打算这个假期进行优化, 首先数据集方面采用一个统一的稍微正规的数据集(新闻推荐数据集原数据,原数据8个多G), 这样可以使得所有的精排模型或者召回模型都可以在这上面做实验,这样也能对比各个模型之间的效果。 另外一个是代码上, 每个模型首先是代码上重新优化,有伙伴帮我指出了Pytorch版本的一些模型实现上有问题,另外就是尽量给出tf和Pytorch版本的基础版本,这个版本的目的是更好的看模型结构以及如何工作的,然后再给出基于deepctr的掉包版本,方便实际中使用。 这一块主要是锻炼coding能力。
ok, 铺垫结束, 开始进入今天的正题。

今天整理的这篇文章是YouTubeDNN模型, 这是2016年的一篇文章, 虽然离着现在有些久远, 但这篇文章无疑是工业界论文的典范, 完全是从工业界的角度去思考如何去做好一个推荐系统,并且处处是YouTube工程师留给我们的宝贵经验, 由于这两天用到了这个模型,今天也正好重温了下这篇文章,所以借着这个机会也整理出来吧, 王喆老师都称这篇文章是"神文", 可见其不一般处。
今天读完之后, 给我的最大感觉,首先是从工程的角度去剖析了整个推荐系统,讲到了推荐系统中最重要的两大模块: 召回和排序, 这篇论文对初学者非常友好,之前的论文模型是看不到这么全面的系统的,总有一种管中规豹的感觉,看不到全局,容易着相。 其次就是这篇文章给出了很多优化推荐系统中的工程性经验, 不管是召回还是排序上,都有很多的套路或者trick,比如召回方面的"example age", “负采样”,“非对称消费,防止泄露”,排序方面的特征工程,加权逻辑回归等, 这些东西至今也都非常的实用,所以这也是这篇文章厉害的地方。
本篇文章依然是以paper为主线, 先剖析paper里面的每个细节,当然我这里也参考了其他大佬写的文章,王喆老师的几篇文章写的都很好,链接我也放在了下面,建议也看看。然后就是如何用YouTubeDNN模型,代码复现部分,由于时间比较短,自己先不复现了,调deepmatch的包跑起来,然后在新闻推荐数据集上进行了一些实验, 尝试了论文里面讲述的一些方法,这里主要是把deepmatch的YouTubeDNN模型怎么使用,以及我整个实验过程的所思所想给整理下, 因为这个模型结构本质上并不是很复杂(三四层的全连接网络),就不自己在实现一遍啦, 一些工程经验或者思想,我觉得才是这篇文章的精华部分。
主要内容:
- YoutubeDNN? 我们先从一个整体上剖析下推荐系统的漏斗范式
- YouTubeDNN的召回模型理论与细节剖析
- YouTubeDNN的排序模型理论与细节剖析
- YouTubeDNN的deepmatch的使用方法
- YouTubeDNN新闻推荐数据集的实验记录
Ok, let’s go!
2. 引言与推荐系统的漏斗范式
2.1 引言部分
本篇论文是工程性论文(之前的DIN也是偏工程实践的论文), 行文风格上以实际应用为主, 我们知道YouTube是全球性的视频网站, 所以这篇文章主要讲述了YouTube视频推荐系统的基本架构以及细节,以及各种处理tricks。
在Introduction部分, 作者首先说了在工业上的YouTube视频推荐系统主要面临的三大挑战:
- Scale(规模): 视频数量非常庞大,大规模数据下需要分布式学习算法以及高效的线上服务系统,文中体现这一点的是召回模型线下训练的时候,采用了负采样的思路,线上服务的时候,采用了hash映射,然后近邻检索的方式来满足实时性的需求, 这个之前我整理过faiss包和annoy包的使用, 感兴趣的可以看看。 其实,再拔高一层,我们推荐系统的整体架构呈漏斗范式,也是为了保证能从大规模情景下实时推荐。
- Freshness(新鲜度): YouTube上的视频是一个动态的, 用户实时上传,且实时访问, 那么这时候, 最新的视频往往就容易博得用户的眼球, 用户一般都比较喜欢看比较新的视频, 而不管是不是真和用户相关(这个感觉和新闻比较类似呀), 这时候,就需要模型有建模新上传内容以及用户最新发生的行为能力。 为了让模型学习到用户对新视频有偏好, 后面策略里面加了一个"example age"作为体现。我们说的"探索与利用"中的探索,其实也是对新鲜度的把握。
- Noise(噪声): 由于数据的稀疏和不可见的其他原因, 数据里面的噪声非常之多,这时候,就需要让这个推荐系统变得鲁棒,怎么鲁棒呢? 这个涉及到召回和排序两块,召回上需要考虑更多实际因素,比如非对称消费特性,高活用户因素,时间因素,序列因素等,并采取了相应的措施, 而排序上做更加细致的特征工程, 尽量的刻画出用户兴趣以及视频的特征 优化训练目标,使用加权的逻辑回归等。而召回和排序模型上,都采用了深度神经网络,通过特征的相互交叉,有了更强大的建模能力, 相比于之前用的MF(矩阵分解), 建模能力上有了很大的提升, 这些都有助于帮助减少噪声, 使得推荐结果更加准确。
所以从文章整体逻辑上看, 后面的各个细节,其实都是围绕着挑战展开的,找到当前推荐面临的问题,就得想办法解决问题,所以这篇文章的行文逻辑也是非常清晰的。
知道了挑战, 那么下面就看看YouTubeDNN的整体推荐系统架构。
2.2 YouTubeDNN推荐系统架构
整个推荐架构图如下, 这个算是比较原始的漏斗结构了:

这篇文章之所以写的好, 是给了我们一个看推荐系统的宏观视角, 这个系统主要是两大部分组成: 召回和排序。召回的目的是根据用户部分特征,从海量物品库,快速找到小部分用户潜在感兴趣的物品交给精排,重点强调快,精排主要是融入更多特征,使用复杂模型,来做个性化推荐,强调准。
而对于这两块的具体描述, 论文里面也给出了解释, 我这里简单基于我目前的理解扩展下主流方法:
- 召回侧

召回侧模型的输入一般是用户的点击历史, 因为我们认为这些历史能更好的代表用户的兴趣, 另外还有一些人口统计学特征,比如性别,年龄,地域等, 都可以作为召回侧模型的输入。 而最终模型的输出,就是与该用户相关的一个候选视频集合, 量级的话一般是几百。
召回侧, 目前根据我的理解,大致上有两大类召回方式,一类是策略规则,一类是监督模型+embedding,其中策略规则,往往和真实场景有关,比如热度,历史重定向等等,不同的场景会有不同的召回方式,这种属于"特异性"知识。
后面的模型+embedding思路是一种"普适"方法,我上面图里面梳理出了目前给用户和物品打embedding的主流方法, 这些方法大致成几个系列,比如FM系列(FM,FFM等), 用户行为序列,基于图和知识图谱系列,经典双塔系列等,这些方法看似很多很复杂,其实本质上还是给用户或者是物品打embedding而已,只不过考虑的角度方式不同。 这里的YouTubeDNN召回模型,也是这里的一种方式而已。 - 精排侧

召回那边对于每个用户, 给出了几百个比较相关的候选视频, 把几百万的规模降到了几百, 当然,召回那边利用的特征信息有限,并不能很好的刻画用户和视频特点,所以, 在精排侧,主要是想利用更多的用户,视频特征,刻画特点更加准确些,从这几百个里面选出几个或者十几个推荐给用户。 而涉及到准, 主要的发力点一般有三个:特征工程, 模型设计以及训练方法。 这三个发力点文章几乎都有所涉及, 除了模式设计有点审时度势之外,特征工程以及训练方法的处理上非常漂亮,具体的后面再整理。
精排侧,这一块的大致发展趋势,从ctr预估到多目标, 而模型演化上,从人工特征工程到特征工程自动化。主要是三大块, CTR预估主要分为了传统的LR,FM大家族,以及后面自动特征交叉的DNN家族,而多目标优化,目前是很多大公司的研究现状,更是未来的一大发展趋势,如何能让模型在各个目标上面的学习都能"游刃有余"是一件非常具有挑战的事情,毕竟不同的目标可能会互相冲突,互相影响,所以这里的研究热点又可以拆分成网络结构演化以及loss设计优化等, 而网络结构演化中,又可以再一次细分。 当然这每个模型或者技术几乎都有对应paper,我们依然可以通过读paper的方式,把这些关键技术学习到。
这两阶段的方法, 就能保证我们从大规模视频库中实时推荐, 又能保证个性化,吸引用户。 当然,随着时间的发展, 可能数据量非常非常大了, 此时召回结果规模精排依然无法处理,所以现在一般还会在召回和精排之间,加一个粗排进一步筛选作为过渡, 而随着场景越来越复杂, 精排产生的结果也不是直接给到用户,而是会再后面加一个重排后处理下,这篇paper里面其实也简单的提了下这种思想,在排序那块会整理到。 所以如今的漏斗, 也变得长了些。

论文里面还提到了对模型的评估方面, 线下评估的时候,主要是采用一些常用的评估指标(精确率,召回率, 排序损失或者auc这种), 但是最终看算法和模型的有效性, 是通过A/B实验, 在A/B实验中会观察用户真实行为,比如点击率, 观看时长, 留存率这种, 这些才是我们终极目标, 而有时候, A/B实验的结果和线下我们用的这些指标并不总是相关, 这也是推荐系统这个场景的复杂性。 我们往往也会用一些策略,比如修改模型的优化目标,损失函数这种, 让线下的这个目标尽量的和A/B衡量的这种指标相关性大一些。 当然,这块又是属于业务场景问题了,不在整理范畴之中。 但2016年,竟然就提出了这种方式, 所以我觉得,作为小白的我们, 想了解工业上的推荐系统, 这篇paper是不二之选。
OK, 从宏观的大视角看完了漏斗型的推荐架构,我们就详细看看YouTube视频推荐架构里面召回和排序模块的模型到底长啥样子? 为啥要设计成这个样子? 为了应对实际中出现的挑战,又有哪些策略?
3. YouTubeDNN的召回模型细节剖析
上面说过, 召回模型的目的是在大量YouTube视频中检索出数百个和用户相关的视频来。
这个问题,我们可以看成一个多分类的问题,即用户在某一个时刻点击了某个视频, 可以建模成输入一个用户向量, 从海量视频中预测出被点击的那个视频的概率。
换成比较准确的数学语言描述, 在时刻
t
t
t下, 用户
U
U
U在背景
C
C
C下对每个视频
i
i
i的观看行为建模成下面的公式:
P
(
w
t
=
i
∣
U
,
C
)
=
e
v
i
u
∑
j
∈
V
e
v
j
u
P\\left(w_t=i \\mid U, C\\right)=\\frace^v_i u\\sum_j \\in V e^v_j u
P(wt=i∣U,C)=∑j∈Vevjueviu
这里的
u
u
u表示用户向量, 这里的
v
v
v表示视频向量, 两者的维度都是
N
N
N, 召回模型的任务,就是通过用户的历史点击和山下文特征, 去学习最终的用户表示向量
u
u
u以及视频
i
i
i的表示向量
v
i
v_i
vi, 不过这俩还有个区别是
v
i
v_i
vi本身就是模型参数, 而
u
u
u是神经网络的输出(函数输出),是输入与模型参数的计算结果。
解释下这个公式, 为啥要写成这个样子,其实是word2vec那边借鉴过来的, e ( v i u ) e^ (v_i u) e(viu)表示的是当前用户向量 u u u与当前视频 v i v_i vi的相似程度, e e e只是放大这个相似程度而已, 不用管。 为啥这个就能表示相似程度呢? 因为两个向量的点积运算的含义就是可以衡量两个向量的相似程度, 两个向量越相似, 点积就会越大。 所以这个应该解释明白了。 再看分母 ∑ j ∈ V e v j u \\sum_j \\in V e^v_j u ∑j∈Vevju, 这个显然是用户向量 u u u与所有视频 v v v的一个相似程度求和。 那么两者一除, 依然是代表了用户 u u u与输出的视频 v i v_i vi的相似程度,只不过归一化到了0-1之间, 毕竟我们知道概率是0-1之间的, 这就是为啥这个概率是右边形式的原因。 因为右边公式表示了用户 u u u与输出的视频 v i v_i vi的相似程度, 并且这个相似程度已经归一化到了0-1之间, 我们给定 u u u希望输出 v i v_i vi的概率越大,因为这样,当前的视频 v i v_i vi和当前用户 u u u更加相关,正好对应着点击行为不是吗?
那么,这个召回模型到底长啥样子呢?
3.1 召回模型结构
召回模型的结构如下:
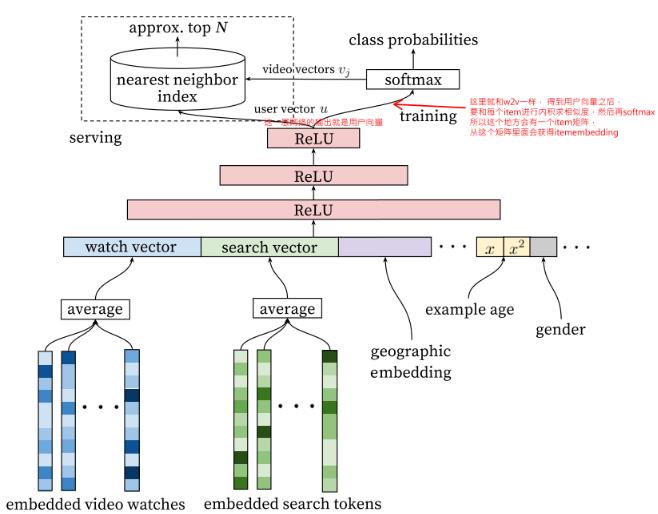
这个模型结构呢,相比之前的模型, 比较简单,就是一个DNN。
它的输入主要是用户侧的特征,包括用户观看的历史video序列, 用户搜索的历史tokens, 然后就是用户的人文特征,比如地理位置, 性别,年龄这些。 这些特征处理上,和之前那些模型的也比较类似,
-
用户历史序列,历史搜索tokens这种序列性的特征: 一般长这样
[item_id5, item_id2, item_id3, ...], 这种id特征是高维稀疏,首先会通过一个embedding层,转成低维稠密的embedding特征,即历史序列里面的每个id都会对应一个embedding向量, 这样历史序列就变成了多个embedding向量的形式, 这些向量一般会进行融合,常见的是average pooling,即每一维求平均得到一个最终向量来表示用户的历史兴趣或搜索兴趣。这里值的一提的是这里的embedding向量得到的方式, 论文中作者这里说是通过word2vec方法计算的, 关于word2vec,这里就不过多解释,也就是每个item事先通过w2v方式算好了的embedding,直接作为了输入,然后进行pooling融合。
除了这种算好embedding方式之外,还可以过embedding层,跟上面的DNN一起训练,这些都是常规操作,之前整理的精排模型里面大都是用这种方式。论文里面使用了用户最近的50次观看历史,用户最近50次搜索历史token, embedding维度是256维, 采用的average pooling。 当然,这里还可以把item的类别信息也隐射到embedding, 与前面的concat起来。
-
用户人文特征, 这种特征处理方式就是离散型的依然是labelEncoder,然后embedding转成低维稠密, 而连续型特征,一般是先归一化操作,然后直接输入,当然有的也通过分桶,转成离散特征,这里不过多整理,特征工程做的事情了。 当然,这里还有一波操作值得注意,就是连续型特征除了用了 x x x本身,还用了 x 2 x^2 x2, l o g x logx logx这种, 可以加入更多非线性,增加模型表达能力。
这些特征对新用户的推荐会比较有帮助,常见的用户的地理位置, 设备, 性别,年龄等。 -
这里一个比较特色的特征是example age,这个特征后面需要单独整理。
这些特征处理好了之后,拼接起来,就成了一个非常长的向量,然后就是过DNN,这里用了一个三层的DNN, 得到了输出, 这个输出也是向量。
Ok,到这里平淡无奇, 前向传播也大致上快说完了, 还差最后一步。 最后这一步,就是做多分类问题,然后求损失,这就是training那边做的事情。 但是在详细说这个之前, 我想先简单回忆下word2vec里面的skip-gram Model, 这个模型,如果回忆起来,这里理解起来就非常的简单了。
这里只需要看一张图即可, 这个来自cs231N公开课PPT, 我之前整理w2v的时候用到的,详细内容可看我这篇博客, 这里的思想其实也是从w2v那边过来的。

skip-gram的原理咱这里就不整理了, 这里就只看这张图,这其实就是w2v训练的一种方式,当然是最原始的。 word2vec的核心思想呢? 就是共现频率高的词相关性越大,所以skip-gram采用中心词预测上下文词的方式去训练词向量,模型的输入是中心词,做样本采用滑动窗口的形式,和这里序列其实差不多,窗口滑动一次就能得到一个序列[word1, word2, …wordn], 而这个序列里面呢? 就会有中心词(比如中间那个), 两边向量的是上下文词。 如果我们输入中心词之后,模型能预测上下文词的概率大,那说明这个模型就能解决词相关性问题了。
一开始, 我们的中心单词 w t w_t wt就是one-hot的表示形式,也就是在词典中的位置,这里的形状是 V × 1 V \\times1 V×1, V V V表示词库里面有 V V V个单词, 这里的 W W W长上面那样, 是一个 d × V d\\times V d×V的矩阵, d d d表示的是词嵌入的维度, 那么用 W ∗ w t W*w_t W∗wt(矩阵乘法)就会得到中心词的词向量表示 v c v_c vc, 大小是 d × 1 d\\times1 d×1。这个就是中心词的embedding向量。 其实就是中心词过了一个embedding层得到了它的embedding向量。
然后就是 v c v_c vc和上下文矩阵 W ′ W' W′相乘, 这里的 W ′ W' W′是 V × d V\\times d V×d的一个矩阵, 每一行代表每个单词作为上下文的时候的词向量表示, 也就是 u w u_w uw, 每一列是词嵌入的维度。 这样通过 W ′ ∗ v c W'*v_c W′∗v