Python深度学习:机器学习理论知识,包含信息熵的计算(读书笔记)
Posted 芝士工具猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python深度学习:机器学习理论知识,包含信息熵的计算(读书笔记)相关的知识,希望对你有一定的参考价值。
今天这一篇,我们正式接触深度学习的理论基础—机器学习
第二篇
一、机器学习分类
1、基于学科分类
统计学、人工智能、信息论、控制理论
2、基于学习模式分类
归纳学习、解释学习、反馈学习
3、基于应用领域的分类
专家系统、数据挖掘、图像识别、人工智能、自然语言处理
二、机器学习的基本算法
一个完整的机器学习项目包含以下内容:
1、输入数据:自然采集的数据集
2、特征提取:通过多种方式对数据的特征值进行提取
3、模型设计:机器学习中最重要的部分
4、数据预测:通过对已经训练模式的使用和认识,实现预测。
基本算法分类:
1、无监督学习:完全黑盒训练的方法,对输入数据没有任何区别和标识
2、有监督学习:数据被人为的分类、标记和区别
3、半监督学习:混合有标记和无标记数据来训练
4、强化学习:输入不同的标识数据
三、算法的理论基础
对于机器学习而言,最重要的部分就是数据的收集和算法的设计。
我们在上小学的时候,就知道计算圆的面积可以用内接多边形去逼近,我们机器学习也类似于此,事实上,这也是我们所谓的微积分的数学基础。
1、机器学习的基础理论-----函数逼近
对于机器学习来说,机器学习的算法理论基础就是函数逼近。而具体的基本算法,我们会再后续的读书笔记中去探讨。

今天我们主要介绍一下机器学习中的函数逼近,其中最常用的就是回归算法。
2、回归算法
我们首先要对回归有一个认识:回归分析,是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。
按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。
简单说来,回归算法也是一种基于已有数据的预测算法(高中初等数学的学习内容),目的是研究数据特征因子与结果之间的因果关系。
线性回归的姐妹-----逻辑回归
逻辑回归主要用在分类领域,主要作用是对不同性质的数据进行分类标识。
我们看一下实现代码(需要数据集的可以私我):(此处转载来自Logistic)
import matplotlib
import matplotlib.pyplot as plt
import csv
import numpy as np
import math
def loadDataset():
data=[]
labels=[]
with open('C:\\\\Users\\\\AWAITXM\\\\Desktop\\\\logisticDataset.txt','r') as f: # "C:\\Users\\AWAITXM\\Desktop\\logisticDataset.txt"
reader = csv.reader(f,delimiter='\\t')
for row in reader:
data.append([1.0, float(row[0]), float(row[1])])
labels.append(int(row[2]))
return data,labels
def plotBestFit(W):
# 把训练集数据用坐标的形式画出来
dataMat,labelMat=loadDataset()
dataArr = np.array(dataMat)
n = np.shape(dataArr)[0]
xcord1 = []
ycord1 = []
xcord2 = []
ycord2 = []
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
# 把分类边界画出来
x = np.arange(-3.0,3.0,0.1)
y = (-W[0]-W[1]*x)/W[2]
ax.plot(x,y)
plt.show()
def plotloss(loss_list):
x = np.arange(0,30,0.01)
plt.plot(x,np.array(loss_list),label = 'linear')
plt.xlabel('time') # 梯度下降的次数
plt.ylabel('loss') # 损失值
plt.title('loss trend') # 损失值随着W不断更新,不断变化的趋势
plt.legend() # 图形图例
plt.show()
def main():
# 读取训练集(txt文件)中的数据,
data, labels = loadDataset()
# 将数据转换成矩阵的形式,便于后面进行计算
# 构建特征矩阵X
X = np.array(data)
# 构建标签矩阵y
y = np.array(labels).reshape(-1,1)
# 随机生成一个w参数(权重)矩阵 .reshape((-1,1))的作用是,不知道有多少行,只想变成一列
W = 0.001*np.random.randn(3,1).reshape((-1,1))
# m表示一共有多少组训练数据
m = len(X)
# 定义梯度下降的学习率 0.03
learn_rate = 0.03
loss_list = []
# 实现梯度下降算法,不断更新W,获得最优解,使损失函数的损失值最小
for i in range(3000):
# 最重要的就是这里用numpy 矩阵计算,完成假设函数计算,损失函数计算,梯度下降计算
# 计算假设函数 h(w)x
g_x = np.dot(X,W)
h_x = 1/(1+np.exp(-g_x))
# 计算损失函数 Cost Function 的损失值loss
loss = np.log(h_x)*y+(1-y)*np.log(1-h_x)
loss = -np.sum(loss)/m
loss_list.append(loss)
# 梯度下降函数更新W权重
dW = X.T.dot(h_x-y)/m
W += -learn_rate*dW
# 得到更新后的W,可视化
print('W最优解:')
print(W)
print('最终得到的分类边界:')
plotBestFit(W)
print('损失值随着W不断更新,不断变化的趋势:')
plotloss(loss_list)
# 定义一个测试数据,计算他属于那一类别
test_x = np.array([1,-1.395634,4.662541])
test_y = 1/(1+np.exp(-np.dot(test_x,W)))
print(test_y)
# print(data_arr)
if __name__=='__main__':
main()
运行结果如图:

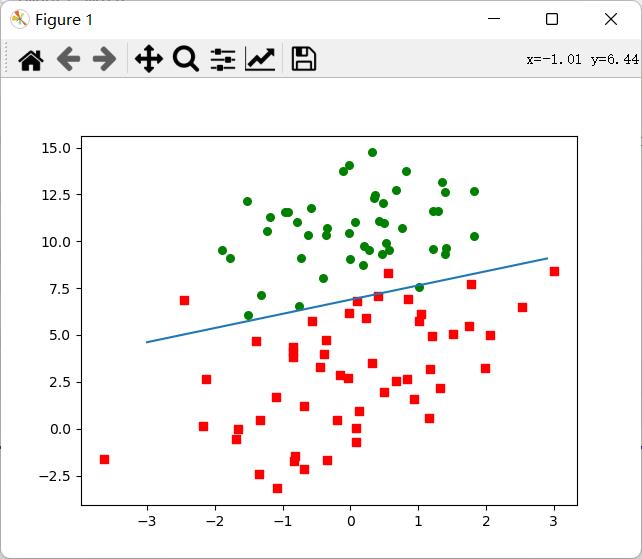
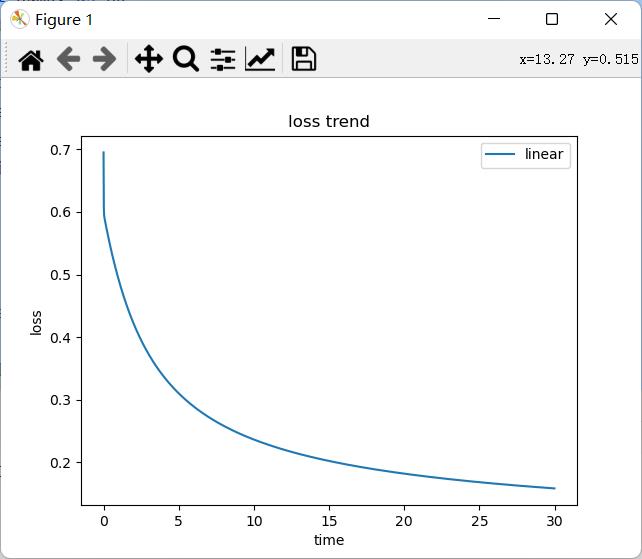
具体的教程,我也是参考这个的,大家也可以看一看:逻辑回归
至于损失函数、代价函数,大家可以参考这篇博客:代价函数
3、其他算法----决策树
决策树则相对比较容易理解,也就是树状结构一层一层从根部开始推理的过程。
决策树理论的运用(源于网络):
作为一个女孩子,你妈妈一直很为你的终身大事担心,今天又要给你介绍对象了。你随口一问:多大了?
她说:26
你问:长得帅不帅?
她说:挺帅的。
你问:收入高不高?
她说:不算很高,中等情况。
你问:学历怎么样吗?
她说:名牌大学研究生呢?
你说:那好的,我去见见。
什么叫决策树?其实刚才那连珠炮似的问题,就有决策树的基本逻辑在里面。
当你问:“多大了?”的时候,其实就开始启动了“相亲决策树”的第一个决策节点。这个决策节点,有两条分支:
第一,大于30岁?哦,年龄太大,那就不见了;
第二,三十岁以下?哦,年龄还可以。然后,你才会接着问“长得帅不帅?”
这又是一个决策节点,“到了丑的级别”,那就别见了。如果至少中等,那就再往下,走到第三个决策节点“收入高不高?” 没钱?那也不能忍。然后是第四个决策节点“是高学历吗?”。是?太好了,小伙子很有前途,那就见吧。
你通过四个决策节点“年龄、长相、收入、上进”,排除了“老、丑、穷还不上进的人”,选出“30岁以下,收入中等,但是很上进,在学习芒格学院的帅小伙”。
这套像树一样层层分支,不断递进的决策工具,就是“决策树”。
决策树的算法基础----信息熵
信息熵是对事件中不确定信息的量度。在一个事件或者属性中,信息熵越大,含有的不确定信息越大,对数据分析的计算就越有益处。因此信息熵总是选择当前事件中拥有最高信息熵的那个属性作为待测属性。
那么,如何计算信息熵?这是一个概率的计算问题:

演示数据:
| 性别(x) | 考试成绩(y) |
|---|---|
| 男 | 优 |
| 女 | 优 |
| 男 | 差 |
| 女 | 优 |
| 男 | 优 |
X的信息熵计算为:
p(男) = 3/5 = 0.6
p(女) = 2/5 = 0.4
根据上面的计算公式可得:
列X的信息熵 为: H(x)= - ( 0.6 * log2(0.6) + 0.4 * log2(0.4)) = 0.97…
Y的信息熵计算为:
p(优) = 4/5 = 0.8
p(差) = 1/5 = 0.2
列X的信息熵 为: H(x)= - ( 0.8 * log2(0.8) + 0.2 * log2(0.2)) = 0.72…
(数据源于链接信息熵的计算)
今天的记录也就到这里了,下次再见啦!
以上是关于Python深度学习:机器学习理论知识,包含信息熵的计算(读书笔记)的主要内容,如果未能解决你的问题,请参考以下文章
《深入浅出Python机器学习(段小手)》PDF代码+《推荐系统与深度学习》PDF及代码+《自然语言处理理论与实战(唐聃)》PDF代码源程序