elastic stack技术栈学习—— 安装elasticsearch IK分词器(一个插件)
Posted 玛丽莲茼蒿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了elastic stack技术栈学习—— 安装elasticsearch IK分词器(一个插件)相关的知识,希望对你有一定的参考价值。
为了实现查询时的部分匹配,决定安装一个IK 分词器。
一、什么是分词器
分词器就是把一段中文划分成一个个的词。
默认的中文分词其实是划分成了一个一个字,比如我们去搜索“扫描敬业福”,默认划分成的是“扫”,“描”,“敬”,“业”和“福”5个字,这显然是不符合我们的搜索想法的,我们希望能够划分成“扫描”和“敬业福”两个词。
使用中文的话可以去下载IK分词器。
IK分词器有两种分词的算法:
- ik_smart (最少划分,切分的所有结果中不可能有重复的字)
- ik_max_word(最细粒度划分,把所有可能的分词组合都给出来)(通过字典去指定)
二、下载安装IK分词器
注意:要和es的版本保持一致!因为我的es版本是7.16.2所以IK分词器也要下载7.16.2版本的。
1.下载安装
https://github.com/medcl/elasticsearch-analysis-ik
下载地址 :https://github.com/medcl/elasticsearch-analysis-ik/releases
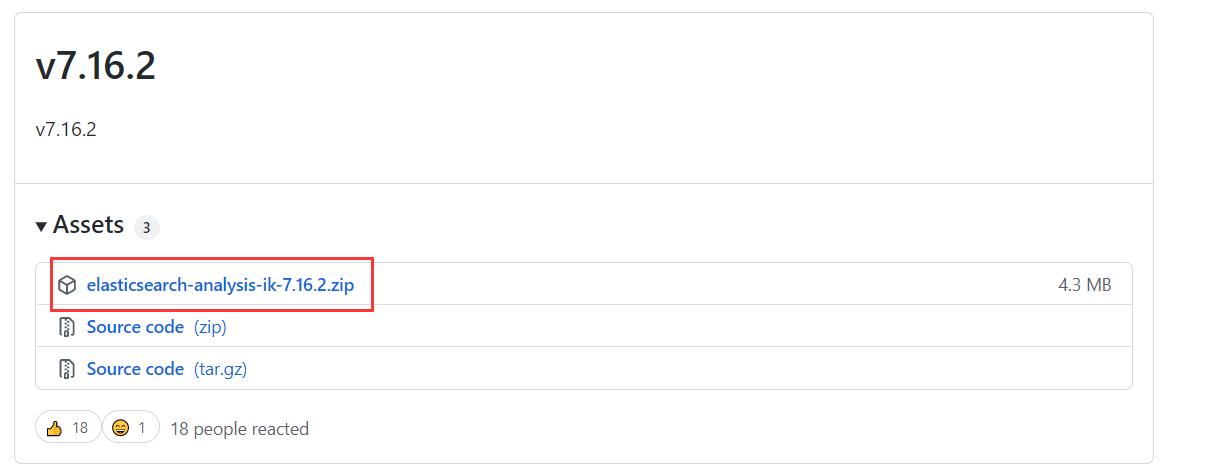
下载这个.zip文件。
在es的plugin目录下,新建一个文件夹ik,将压缩包在这里解压,然后删除压缩包。

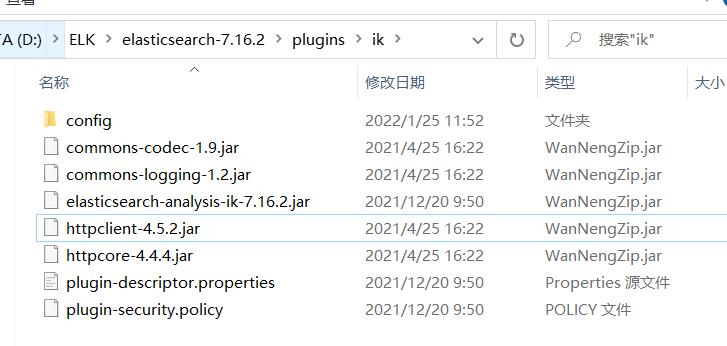
2、重启es
可以看到在es的启动过程中,分词器被加载了。
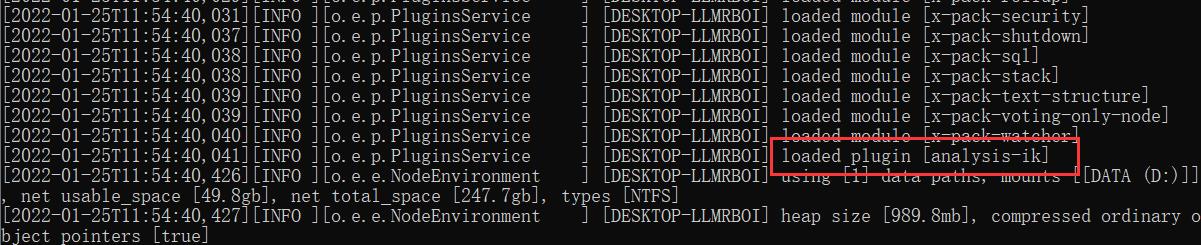
3、使用kibana测试分词器
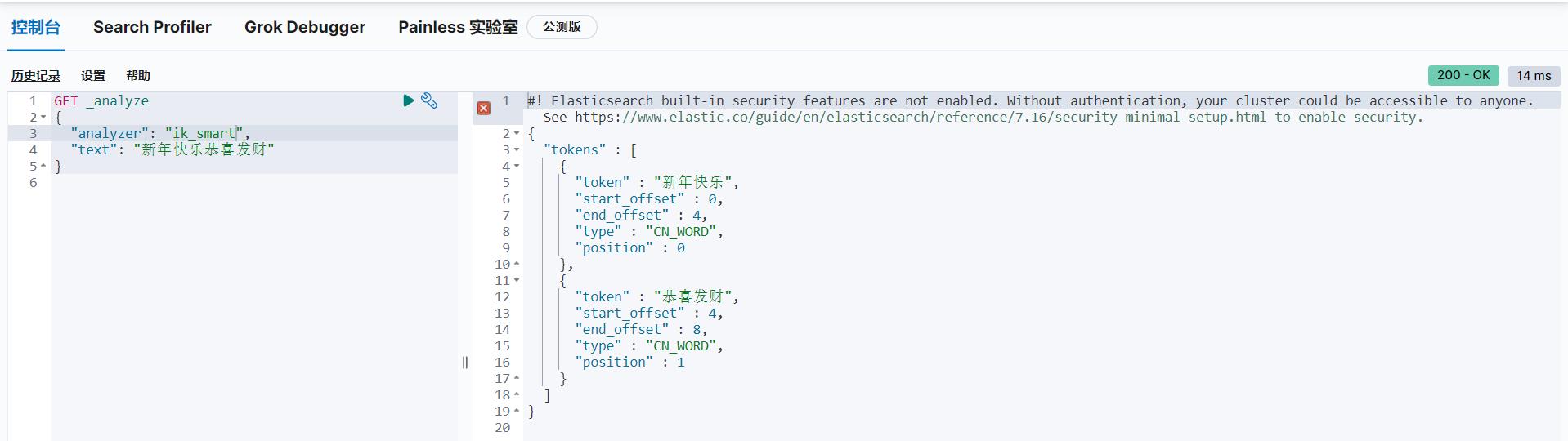
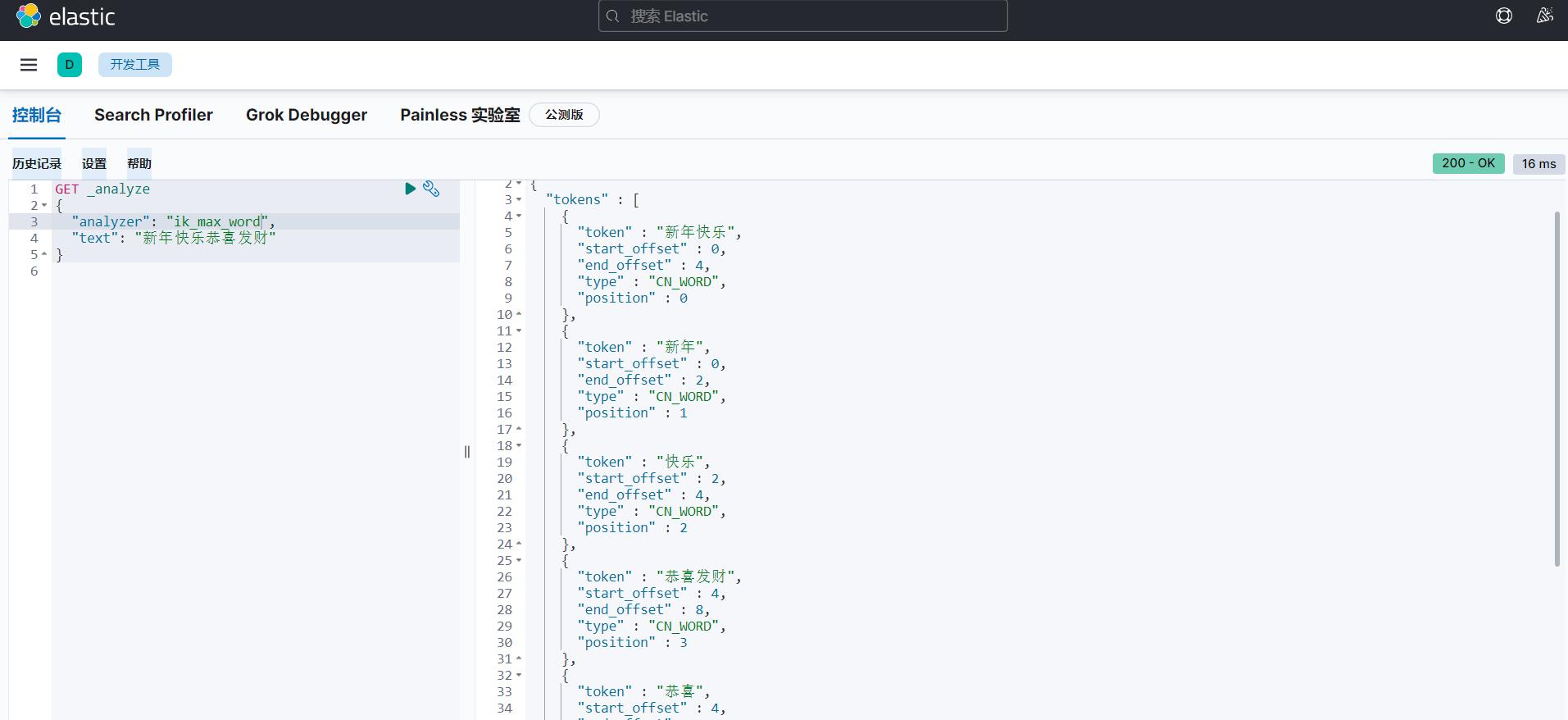
分别采用最少划分、最细粒度划分两种算法,看一下区别。当然,出来下面的划分结果也说明我们的分词器安装成功了。
(1)最少划分
GET _analyze
"analyzer": "ik_smart",
"text": "新年快乐恭喜发财"
(2)最细粒度划分
GET _analyze
"analyzer": "ik_max_word",
"text": "新年快乐恭喜发财"
(3)字典
存在一个问题,比如输入的文字是“我想要敬业福”,划分的结果把“敬业福”给拆开了。

显然IK分词器所用的字典没有敬业福这个词。但是允许我们自己修改词典,以满足自定义的搜索。
那么怎样修改呢?
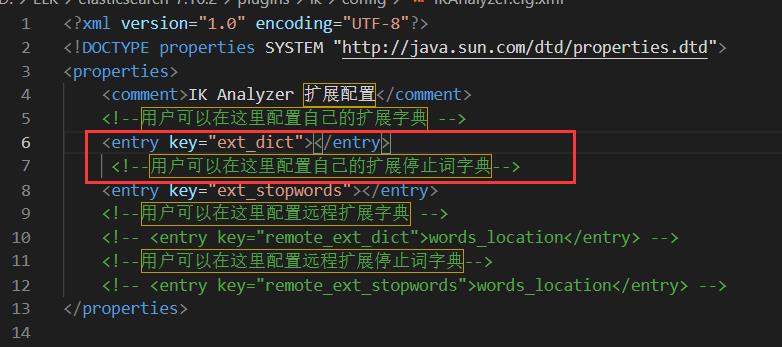
打开IK分析器的配置文件,如下:

里面内容如下:
4、自定义字典
(1)创建扩展字典
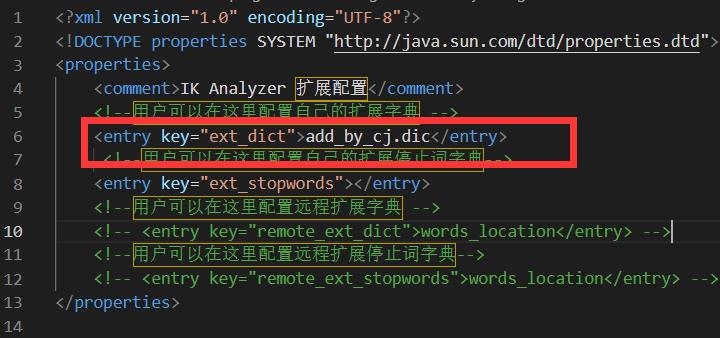
在ik文件夹的config目录下,存放了原有字典的.dic文件。我们需要新建一个自己的“add_by_c.dicj”文件。然后加入新词。

(2)把扩展字典的文件名加入到配置文件中
(3) 重启es
重启es才能生效,当然也要重启kibana测试一下划分结果。

“敬业福”被完整地识别为一个词了。

以上是关于elastic stack技术栈学习—— 安装elasticsearch IK分词器(一个插件)的主要内容,如果未能解决你的问题,请参考以下文章