七月在线 《图像识别与检测》
Posted 刘润森!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了七月在线 《图像识别与检测》相关的知识,希望对你有一定的参考价值。
七月在线 课程:https://www.julyedu.com/course/getDetail/262
CSPNet
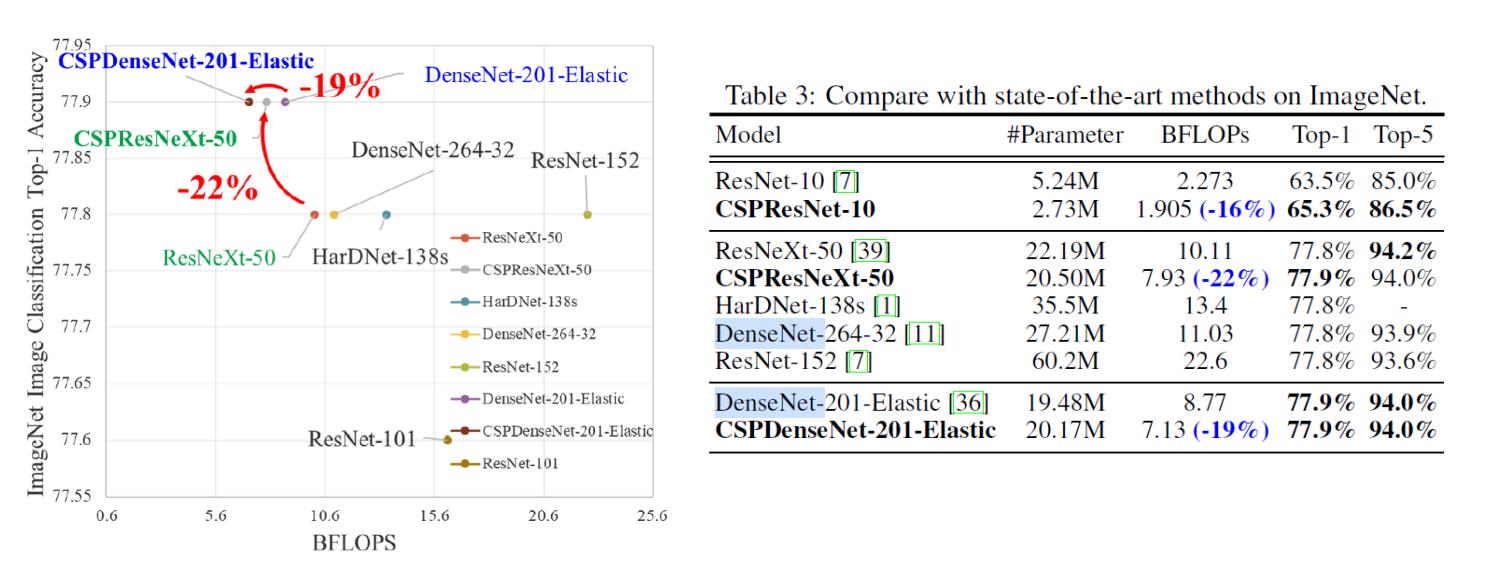
CSPNet全称是Cross Stage Partial Network,主要从一个比较特殊的角度切入,能够在降低20%计算量的情况下保持甚至提高CNN的能力。CSPNet开源了一部分cfg文件,其中一部分cfg可以直接使用AlexeyAB版Darknet还有ultralytics的yolov3运行。
-
增强CNN的学习能力:现有的CNN在轻量化后,其精度大大降低,因此本文希望加强CNN的学习能力,使其在轻量化的同时保持足够的准确性。CSPNet可以很容易地应用于ResNet、ResNeXt和DenseNet。将CSPNet应用于上述网络后,计算量可从10%减少到20%。
-
消除计算瓶颈:过高的计算瓶颈会导致更多的计算周期来完成推理过程,或者一些算力单元经常闲置。因此,本文希望能够均匀分配CNN中各层的计算量,这样可以有效提升各计算单元的利用率,从而减少不必要的能耗。此外,在基于MS COCO数据集的物体检测实验中,本文提出的模型在基于YOLOv3的模型上测试时,可以有效降低80%的计算瓶颈。
-
降低内存成本:动态随机存取存储器(DRAM)的晶圆制造成本非常昂贵,而且还占用了大量的空间。如果能有效降低存储器的成本,将大大降低集成电路成本。此外,小面积的晶圆可以用于各种边缘计算设备。在减少内存使用方面,文章采用cross-channel pooling,在特征金字塔生成过程中对特征图进行压缩。这样,CSPNet与对象检测器在生成特征金字塔时,可以减少PeleeNet上75%的内存使用量。
由于CSPNet能够促进CNN的学习能力,因此本文使用更小的模型来实现更好的精度。CSPNet可以在GTX 1080ti上以109 fps的速度达到50%的COCO AP50。由于CSPNet可以有效地削减大量的内存流量,本文提出的方法可以在英特尔酷睿i9-9900K上以52帧/秒的速度实现40%的COCO AP50。此外,由于CSPNet可以显著降低计算瓶颈,Exact Fusion Model(EFM)可以有效降低所需的内存带宽,因此,CSPNet能够在Nvidia Jetson TX2上实现42%的COCO AP50,每秒49帧。
YOLO、SSD和Faster-RCNN
YOLO、SSD和Faster-RCNN都是目标检测领域里面非常经典的算法,无论是在工业界还是学术界,都有着深远的影响;Faster-RCNN是基于候选区域的双阶段检测器代表作,而YOLO和SSD则是单阶段检测器的代表;在速度上,单阶段的YOLO和SSD要比双阶段的Faster-RCNN的快很多,而YOLO又比SSD要快,在精度上,Faster-RCNN精度要优于单阶段的YOLO和SSD;不过这也是在前几年的情况下,目标检测发展到现在,单阶段检测器精度已经不虚双阶段,并且保持着非常快的速度,现阶段SSD和Faster-RCNN已经不更了,但是YOLO仍在飞快的发展,目前已经迭代到V4、V5,速度更快,精度更高,在COCO精度上双双破了50map,这是很多双阶段检测器都达不到的精度,而最近的Scale yolov4更是取得了55map,成功登顶榜首。当然虽然SSD和Faster-RCNN已经不更了,但是有很多他们相关的变体,同样有着不错的精度和性能,例如Cascade R-CNN、RefineDet等等。
CIFAR10 CNN(torch)
import numpy as np
import torch, torchvision
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets
import torchvision.transforms as transforms
torch.__version__
我们计算数据的平均值和标准偏差,以便对其进行标准化。
我们的数据集由彩色图像组成,但有三个颜色通道(红色、绿色和蓝色),而MNIST的黑白图像只有一个颜色通道。为了规范化我们的数据,我们需要独立地计算每个颜色通道的平均值和标准偏差。
为此,我们将一个包含轴的元组传递给’mean’和’std’函数,我们希望将平均值和标准偏差传递给’mean’和’std’函数,并收到三个颜色通道中每个通道的平均值和标准偏差列表。
ROOT = '.data'
train_data = datasets.CIFAR10(root = ROOT,
train = True,
download = True)
means = train_data.data.mean(axis = (0,1,2)) / 255
stds = train_data.data.std(axis = (0,1,2)) / 255
print(f'Calculated means: means')
print(f'Calculated stds: stds')
接下来是定义用于数据扩充的转换。
CIFAR10数据集中的图像比MNIST数据集中的图像复杂得多。它们更大,像素数量是原来的三倍,而且更凌乱。这使它们更难学习,因此意味着我们应该少用扩充。
我们使用的一个新变换是“RandomHorizontalFlip”。这将以指定的“0.5”概率水平翻转图像。因此,马面向右侧的图像将翻转,使其面向左侧。我们无法在MNIST数据集中执行此操作,因为我们不希望测试集包含任何翻转的数字,但是自然图像(如CIFAR10数据集中的图像)可能会被翻转,因为它们仍然具有视觉意义。
由于我们的手段'和性病’现在已经在列表中,我们不需要像在MNIST数据集中处理单通道图像那样将它们包含在列表中。
train_transforms = transforms.Compose([
transforms.RandomRotation(5),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomCrop(32, padding = 2),
transforms.ToTensor(),
transforms.Normalize(mean = means,
std = stds)
])
test_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean = means,
std = stds)
])
train_dataset = datasets.CIFAR10(ROOT,
train = True,
download = True,
transform = train_transforms)
test_dataset = datasets.CIFAR10(ROOT,
train = False,
download = True,
transform = test_transforms)
# create data loaders
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size = 128, shuffle = True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size = 128, shuffle = False)
# create CNN with one convolution/pooling layer
class net(nn.Module):
def __init__(self, input_dim, num_filters, kernel_size, stride, padding, num_classes):
super(net, self).__init__()
self.input_dim = input_dim
conv_output_size = int((input_dim - kernel_size + 2 * padding)/stride) + 1 # conv layer output size
pool_output_size = int((conv_output_size - kernel_size)/stride) + 1 # pooling layer output size
self.conv = nn.Conv2d(3, num_filters, kernel_size = kernel_size, stride = stride, padding = padding)
self.pool = nn.MaxPool2d(kernel_size = kernel_size, stride = stride)
self.relu = nn.ReLU()
self.dense = nn.Linear(pool_output_size * pool_output_size * num_filters, num_classes)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
x = self.pool(x)
x = x.view(x.size(0), -1) # resize to fit into final dense layer
x = self.dense(x)
return x
# hyperparameters
DEVICE = torch.device('cuda')
INPUT_DIM = 32
NUM_FILTERS = 32
KERNEL_SIZE = 3
STRIDE = 1
PADDING = 1
NUM_CLASSES = 10
LEARNING_RATE = 1e-3
NUM_EPOCHS = 30
model = net(INPUT_DIM, NUM_FILTERS, KERNEL_SIZE, STRIDE, PADDING, NUM_CLASSES).to(DEVICE)
criterion = nn.CrossEntropyLoss() # do not need softmax layer when using CEloss criterion
optimizer = torch.optim.Adam(model.parameters(), lr = LEARNING_RATE)
# training for NUM_EPOCHS
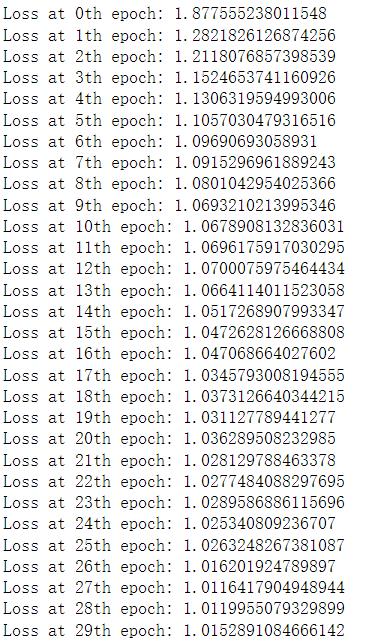
for i in range(NUM_EPOCHS):
temp_loss = []
for (x, y) in train_loader:
x, y = x.float().to(DEVICE), y.to(DEVICE)
outputs = model(x)
loss = criterion(outputs, y)
temp_loss.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("Loss at th epoch: ".format(i, np.mean(temp_loss)))
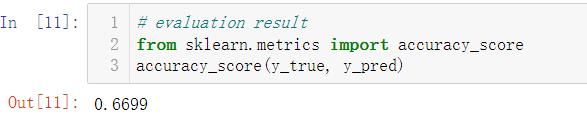
- 用准确度评分评估训练后的CNN模型
- 将每个实例的概率存储到列表中,并将其与真y标签进行比较
y_pred, y_true = [], []
with torch.no_grad():
for x, y in test_loader:
x, y = x.float().to(DEVICE), y.to(DEVICE)
outputs = F.softmax(model(x)).max(1)[-1] # predicted label
y_true += list(y.cpu().numpy()) # true label
y_pred += list(outputs.cpu().numpy())
以上是关于七月在线 《图像识别与检测》的主要内容,如果未能解决你的问题,请参考以下文章