每日一练(day11&look look Arrary.sort())
Posted 'or 1 or 不正经の泡泡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了每日一练(day11&look look Arrary.sort())相关的知识,希望对你有一定的参考价值。
文章目录
前言
突然发现在CSDN竟然还有这个功能没想到呀。
不过这些题目都是Letcode的,那么今天的三道题目不就来了嘛。(而且人家是选择题,代码都不用我手撸)
题目
这个第一题是我们以前做过的,这里就不重复了。
子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
示例 2:
输入:nums = [0]
输出:[[],[0]]
增量构造
这个解法首先最先想到的就是暴力求解,但是有些重复的子集。
也就是所谓的增量构造,其实也有动态规划的一点思想在里面。

但是显然发现,这个状态方程的决定因素和前面的元素比都有关系,所以和暴力没什么区别。
class Solution
List<List<Integer>> res = new ArrayList<>();
List<Integer> temp = new ArrayList<>();
public List<List<Integer>> subsets(int[] nums)
res.add(new ArrayList<>());
temp.add(nums[0]);
res.add(new ArrayList<>(temp));
temp.remove(temp.size()-1);
for (int i=1;i<nums.length;i++)
int lengthres = res.size();
temp.add(nums[i]);
res.add(new ArrayList<>(temp));
for(int j=1;j<lengthres;j++)
List<Integer> temp2 = new ArrayList<>();
temp2.addAll(res.get(j));
temp2.addAll(temp);
res.add(temp2);
temp.remove(temp.size()-1);
return res;
内存消耗还是比较高的,比较换来换去的。

DFS+回溯
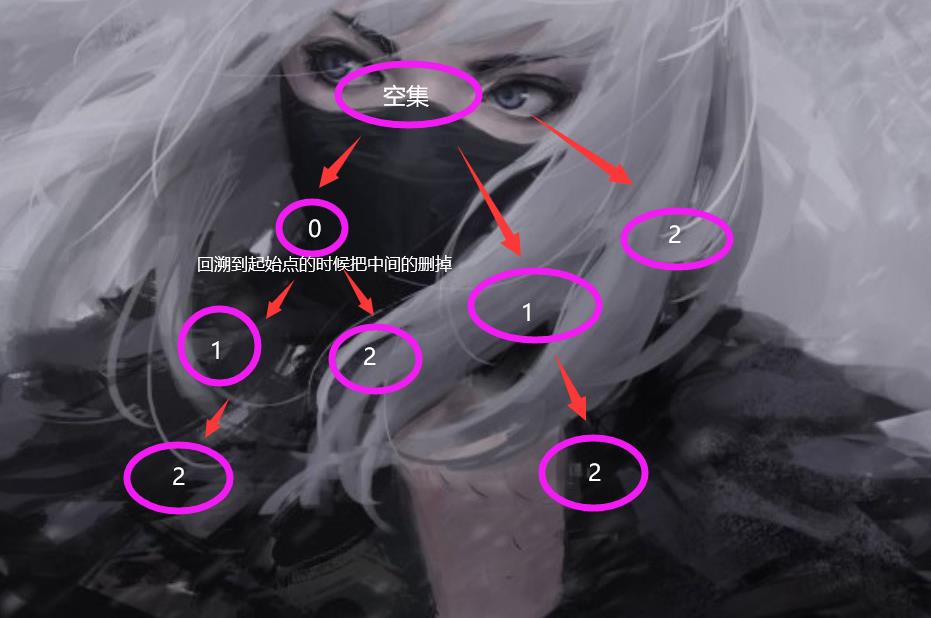
还有一种方式是用递归+回溯的方式去做的。原理其实就是我们高中常用的那种方法。

有个好听的名字叫做 DFS + 回溯,为什么这样加咧,首先往一个方向走,不撞南墙不回头,回溯是说,撞了南墙就回头。
当然在这里的执行顺序不太一样。
0,1,2
—> ,0,0,1,0,1,2,0,2,1,1,2,2
这里的厉害之处就是回溯的时候会把中间的元素删掉。
class Solution
List<List<Integer>> res = new ArrayList<>();
List<Integer> temp = new ArrayList<>();
public List<List<Integer>> subsets(int[] nums)
res.add(new ArrayList<>());
DFS(nums,0);
return res;
public void DFS(int[] nums,int start)
if(start>=nums.length)
return;
for(int i=start;i<nums.length;i++)
temp.add(nums[i]);
res.add(new ArrayList<>(temp));
DFS(nums,i+1);
temp.remove(temp.size()-1);
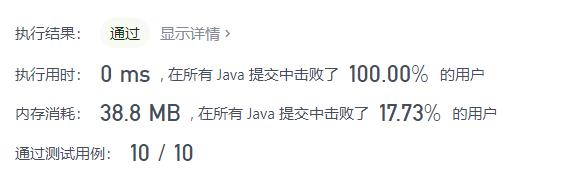
好家伙,内存消耗还更高了,其实也正常,递归的内存消耗确实不小。有时候这个递归写起了很方便,有时候写起来既抽象,消耗又高,看情况吧,但是这个也是比较经典的。
子集二
这里面和前面的题目要求一样,但是在我们的数据测试里面,是有重复数据输入的。
输入:nums = [1,2,2] 输出:[[],[1],[1,2],[1,2,2],[2],[2,2]]
这个其实也是类似的,但是我们发现假设给你一个这样的输入
【2 2 2 2 2】
你会发现很多子集其实都是一样的,所以对于相同元素的子集,我们要选择性忽略。所以问题来了我们如何判断相同元素。前面我们用过很多方法,最简单就是我们可已使用双指针,把重复的元素放在前面。那这里还有更简单的那就是直接先排序,如果有相同,那么相同的就在旁边。
class Solution
List<List<Integer>> res = new ArrayList<>();
List<Integer> temp = new ArrayList<>();
public List<List<Integer>> subsetsWithDup(int[] nums)
if(nums==null||nums.length==0)
return res;
res.add(new ArrayList<>());
Arrays.sort(nums);
DFS(nums,0);
return res;
public void DFS(int[] nums,int start)
if(start>=nums.length)
return;
for(int i=start;i<nums.length;i++)
if(i>start&&nums[i]==nums[i-1])
continue;
temp.add(nums[i]);
res.add(new ArrayList<>(temp));
DFS(nums,i+1);
temp.remove(temp.size()-1);

这个效果好吧。。。。
下面我又对CSDN提供的代码进行了提交
class Solution
public List<List<Integer>> subsetsWithDup(int[] nums)
List<List<Integer>> retList = new ArrayList<>();
retList.add(new ArrayList<>());
if (nums == null || nums.length == 0)
return retList;
Arrays.sort(nums);
List<Integer> tmp = new ArrayList<>();
tmp.add(nums[0]);
retList.add(tmp);
if (nums.length == 1)
return retList;
int lastLen = 1;
for (int i = 1; i < nums.length; i++)
int size = retList.size();
if (nums[i] != nums[i - 1])
lastLen = size;
for (int j = size - lastLen; j < size; j++)
List<Integer> inner = new ArrayList(retList.get(j));
inner.add(nums[i]);
retList.add(inner);
return retList;

我叉嘞!!!(搞了半天原来是负优化)
不过在这里我又开始好奇一个东西了,那就是我们亲爱的 Arrary.sort() 的排序规则到底是怎么样的咧?
Arrary.sort() 的排序方式
首先我们对于我们前面的程序而言,排序的复杂度也会在一定程度上拉低我们效率,所以问题来了,这个Arrary.sort()的排序规则到底是什么?他会不会拖慢我们的效率。

点开我们的源码,我们发现了这里不止一种sort的实现方法!!!
可以发现下面的那些注释是一些算法的描述。同时往下翻注意到这句话

并且我们的所有的sort都是由这玩意出来的


进去查看我们发现了这些玩意。
然后我们使用翻译器翻译一下
/ * *
*归并排序的最大运行次数。
*/
private static final int MAX_RUN_COUNT = 67;
/ * *
在归并排序中运行的最大长度。
*/
private static final int MAX_RUN_LENGTH = 33;
/**
如果要排序的数组长度小于这个值
*常量,快速排序优先使用归并排序。
*/
private static final int QUICKSORT_THRESHOLD = 286;
/**
如果要排序的数组长度小于这个值
*常量,插入排序优先于快速排序。
*/
private static final int INSERTION_SORT_THRESHOLD = 47;
/**
如果要排序的字节数组的长度大于这个值
*常量,计数排序优先使用插入排序。
*/
private static final int COUNTING_SORT_THRESHOLD_FOR_BYTE = 29;
/**
如果要排序的短数组或char数组的长度更大
*,计数排序优先于快速排序。
*/
private static final int COUNTING_SORT_THRESHOLD_FOR_SHORT_OR_CHAR = 3200;
到此我们发现了这个玩意。对于不同的数组长度,我们的Arrary.sort()采用了不同的策略。
那问题又来了 DualPivotQuicksort 是什么?分发器嘛,这个翻译可不是这个意思。
后来我在某段代码的注释当中找到了这个
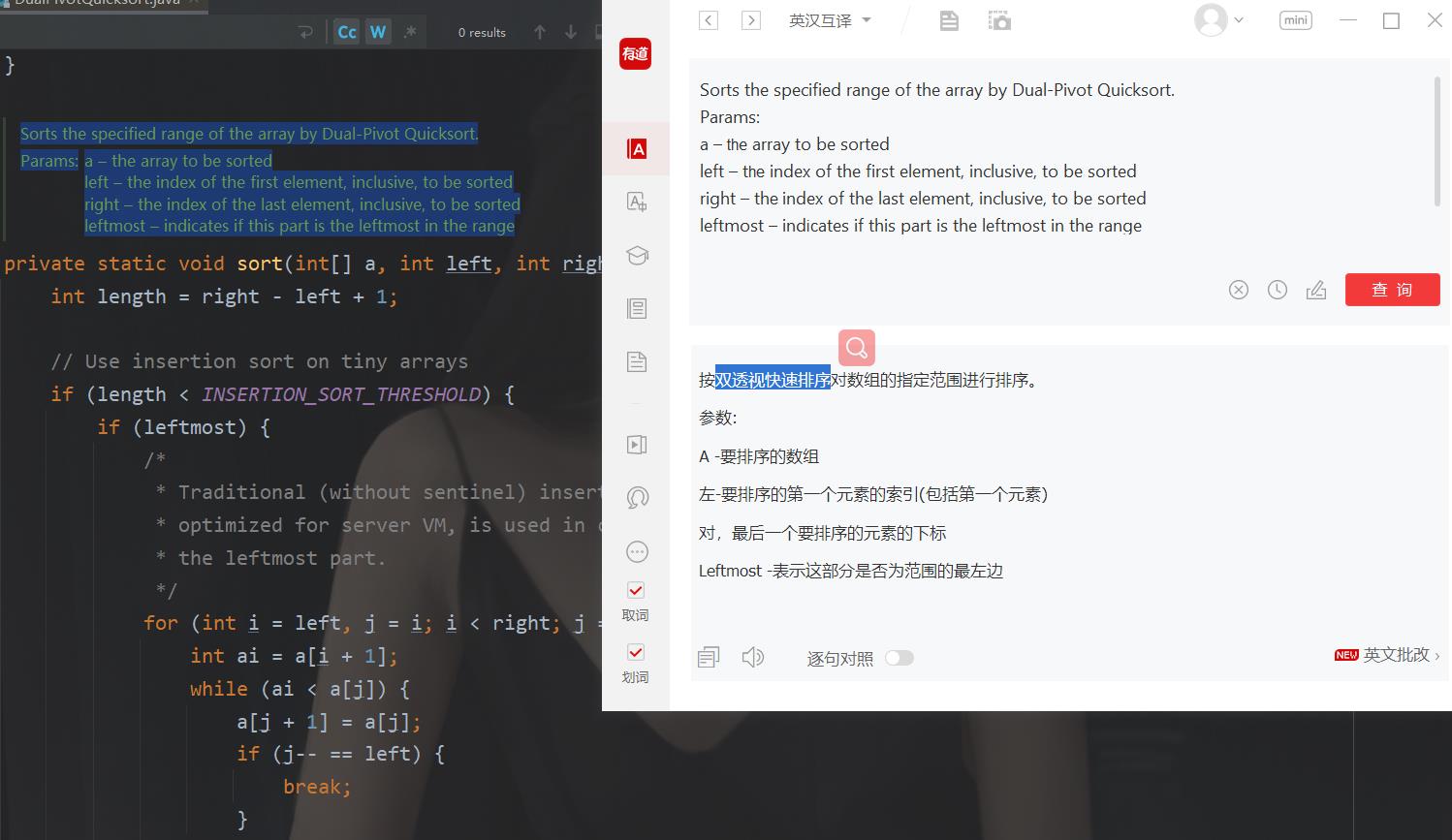
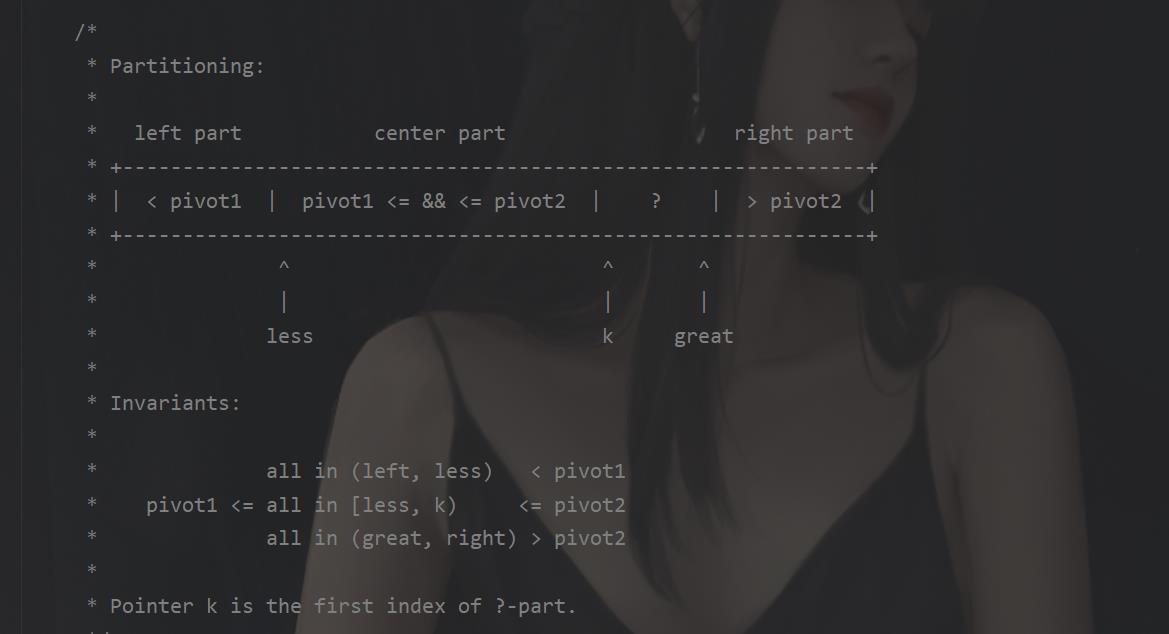
好家伙,原来java 对这些排序还有优化。
并且在当前的java版本当中使用的快速排序为共轴快速排序。
这个快速排序的的特点首先和我们传统的快速排序有点类似。我们的传统的如下图

但是我们现在这个呢,叫做共轴,先前我们是直接拿了一个点,现在我拿两个点。
之后我们将我们的数据分成四部分
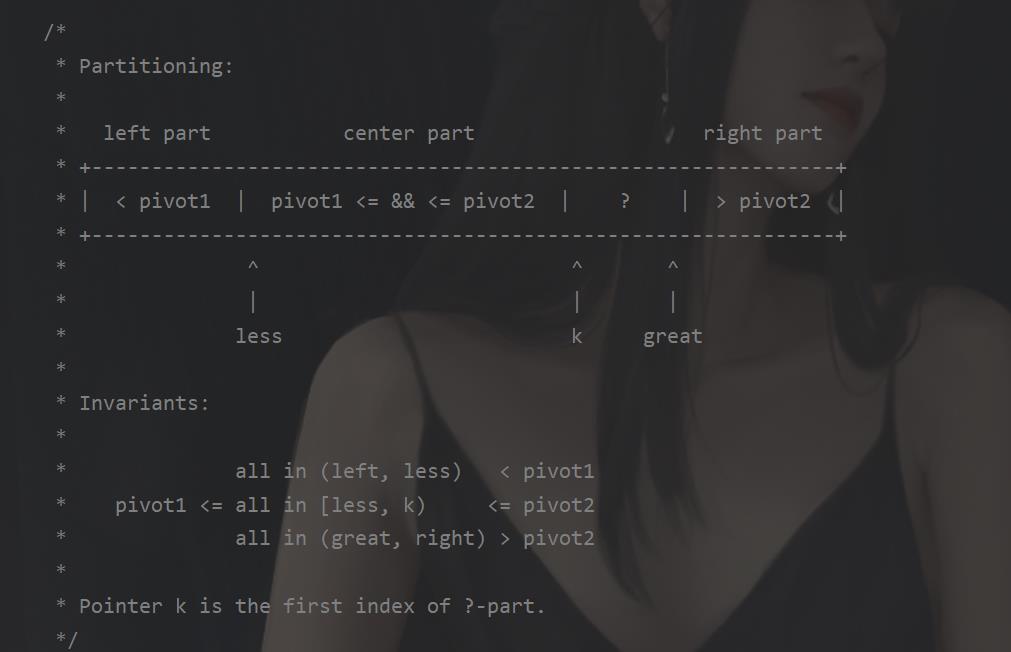
这样一来其实就是对我们的一个数据进行划分,对划分后的数据进行快排,就是选了两个点的快排。但是这样做好处是什么呢,首先这两个点的选择有要求,那就是A<B这样才能划分,可能是保证相对有序,减少交换次数吧。
总结
今天就这样吧,昨天熬夜熬得太久了,喵的PUBG玩得形态炸了,然后12点写了篇博客,写了一个小时,到一点多,死活睡不着。
以上是关于每日一练(day11&look look Arrary.sort())的主要内容,如果未能解决你的问题,请参考以下文章