机器学习小概述(机器学习初体验(Azure))
Posted 'or 1 or 不正经の泡泡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习小概述(机器学习初体验(Azure))相关的知识,希望对你有一定的参考价值。
文章目录
「这是我参与2022首次更文挑战的第4天,活动详情查看: 2022首次更文挑战」
前言
从今天开始我终于开始回归到我的老本行之一进行学习了!每天刷刷力扣,玩玩虚幻四突然发现时间是真不够。所以我得加快脚步了,本来我寒假的计划是完成多目标优化的学习,以及web的学习巩固进阶,也就是分布式SpringCloud 云原生那一块,并对前面写的博客社区进行完善和部署。现在看看时间似乎不够!而且我们这边还有机器学习,深度学习,Sklearn ,pytorch 方面的学习需要巩固(这些东西其实都是我花了半个月学习的,所以我需要重新学习巩固一遍(不然现在的我只能看看人家的demo,跑一跑)))。所以这个寒假三件事,刷Letcode,机器学习,啃多目标优化,并且重新温习java基础部分(线程,反射…框架玩太多了,这块好久没写过原生的了,但是下个学期写MoFlink必然用得上,没有轮子呀!))
OK,那么今天我们来说说机器学习这玩意。一说到这个我们就不得不提到人工智能。一说到人工智能我们又会想到 深度学习
所以问题来了,他们之间有什么关系咧?如果我对这玩意感兴趣,我应该从哪方面入手呢?同时我需要具备那些基础知识呢?
那么接下来我就来说说,他们之间的关系:
- [人工智能]:这玩意不用我多说,大家都懂。
- [机器学习]:机器学习是人工智能的一个实现途径。
- [深度学习]:深度学习是属于我们机器学习的一种分支,也就是说在学习深度学习之前我们最好先学习机器学习。
- [学习条件]:
- [数学]:数学的话我们最起码要学习高等数学,和线性代数(后面经常使用),已经概论论,当然还有离散。学习数学的目的是因为有些算法是需要有数学基础的,我们要求不高不奢望能够推导,但是我们最起码要理解。
- [编程]:如果你想要系统学习,你最好先掌握python。
- [算法]:掌握一些机器学习算法,我们机器学习的本质其实还是算法,对算法的优化,使用。
好了,那么接下来,我们是时候回来好好聊聊啥事机器学习了。
何为机器学习
机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测。
那么这个模型呢其实就是我们一些算法。
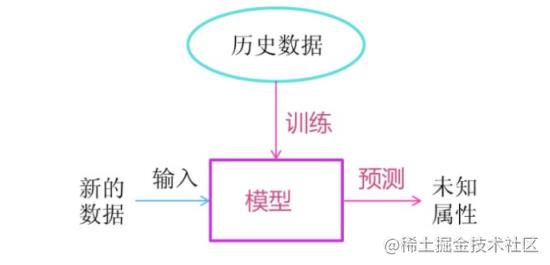
在早期我们的机器学习分为多个阶段,当然我们这边不是历史博文,所以这边只谈现状。
机器学习的流程
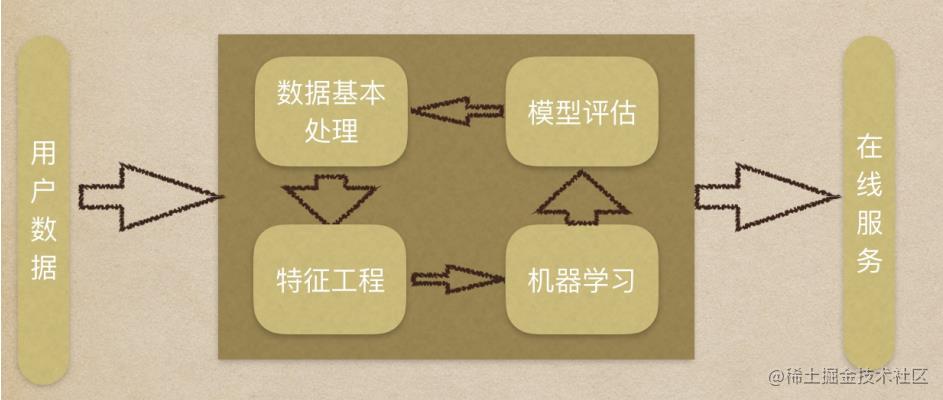
我们的机器学习,大致分为五个部分、
- 获取数据
- 数据基本处理
- 特征工程
- 机器学习(模型训练)
- 模型评估
这个也是我先前在使用sklearn里面说的五部曲。
演示(基于Azure实验平台)
那么接下来为了让我的说明更有力,我这里实际的演示一下,首先是我们的代码演示,我们使用我们的sklearn进行演示。这个是预测莺尾花的。
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
def nb_news():
"""
用朴素贝叶斯算法对新闻进行分类
:return:
"""
#1.获取数据
news = fetch_20newsgroups(subset="all")#subset="all"获取所有数据,train获取训练数据
#2.划分数据集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)
#3.特征工程:文本特征抽取-tfidf
transfer = TfidfVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
#4.朴素贝叶斯算法预估器流程
estimator = MultinomialNB()
estimator.fit(x_train, y_train)
#5.模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\\n", y_predict)
print("直接比对真实值和预测值:\\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\\n", score)
这个看不懂没关系,咱们还有简单的。那就是咱们的云平台。

我们这边直接使用我们的微软账号登录即可。
接下来这样操作
(在此之前我先放一张完整的图片)
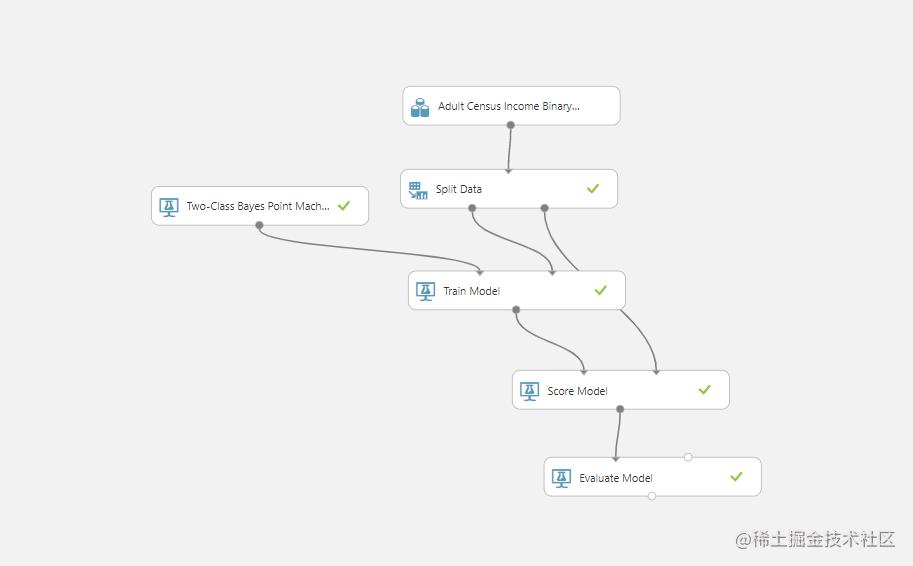
(使用谷歌浏览器翻译之后是这样的)
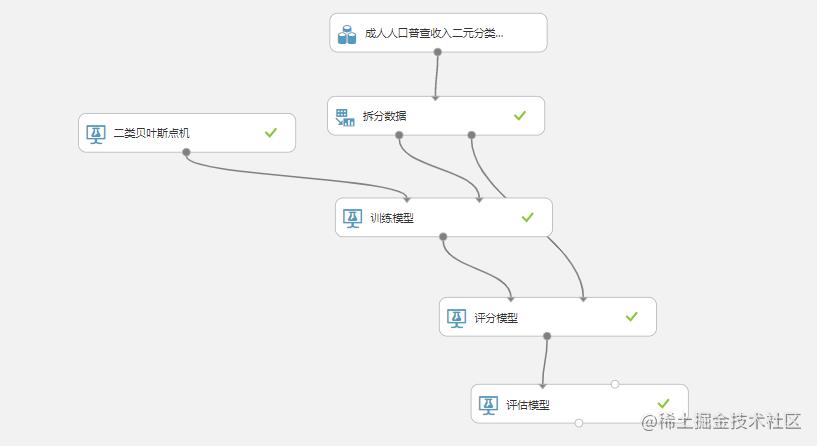
下面是正常的开始操作了:

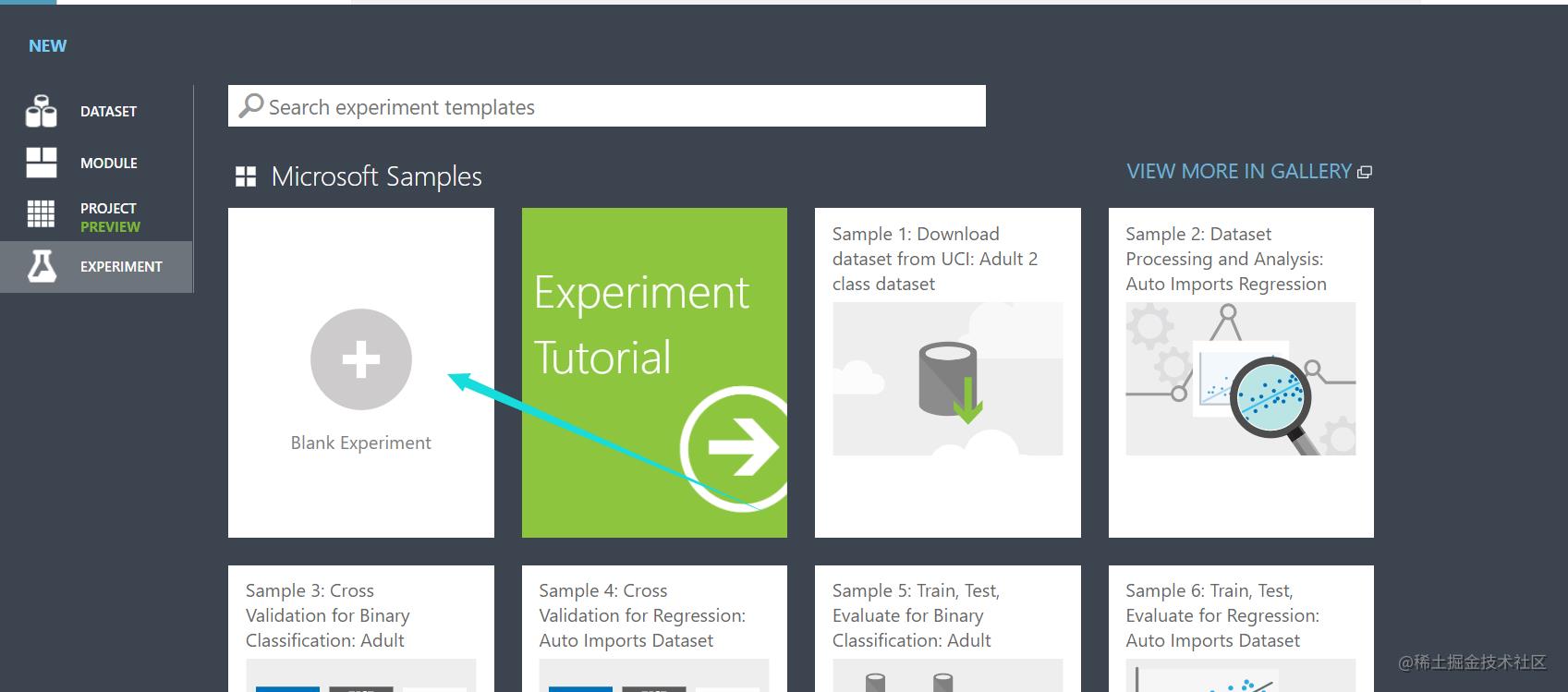
此时你就会进入这样的界面

注意我这里使用的数据集是直接第一个拖过来的。

它的数据集是长这样的
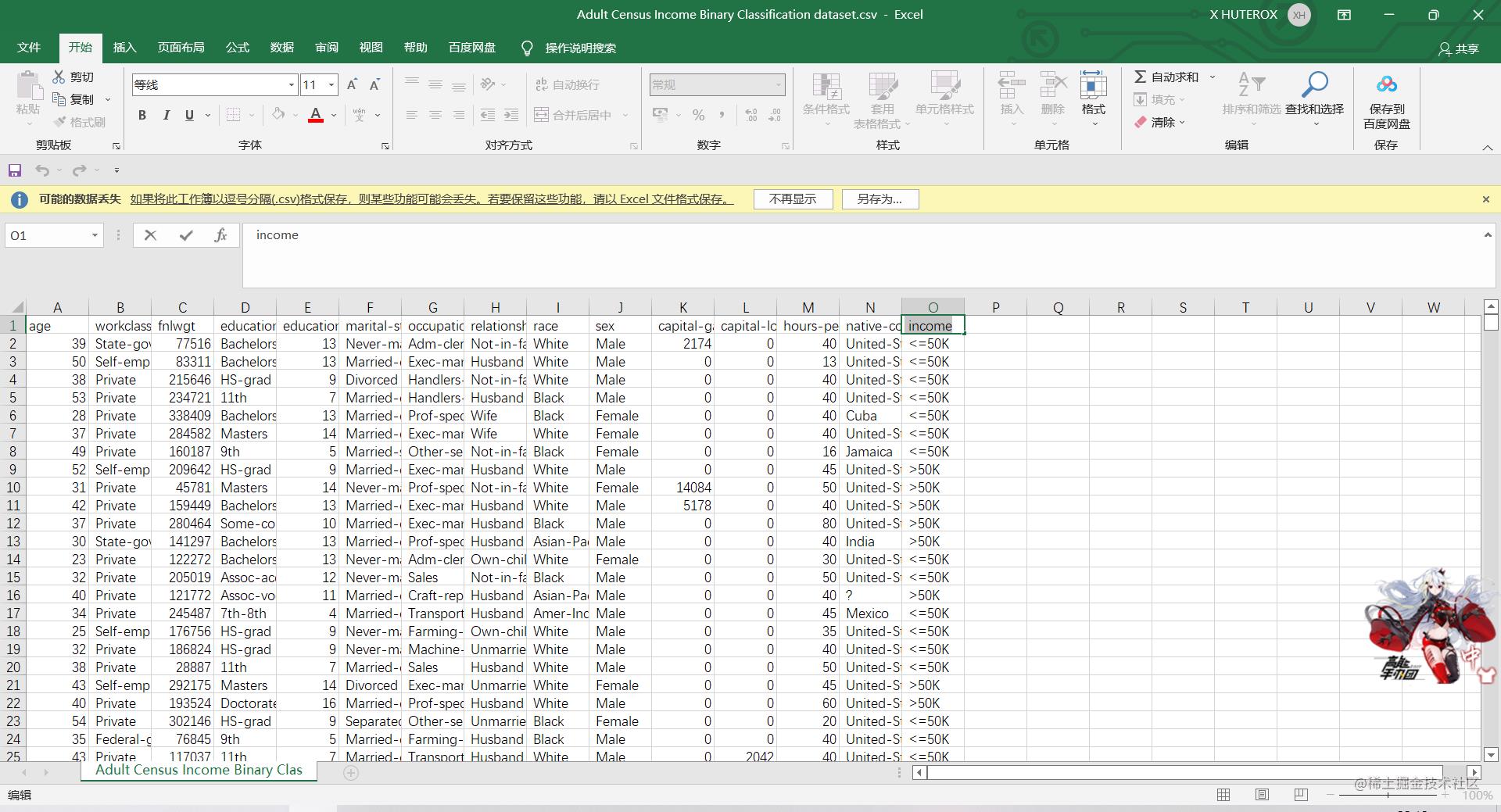
之后是绑定我们的预测数据(点击会有弹窗)
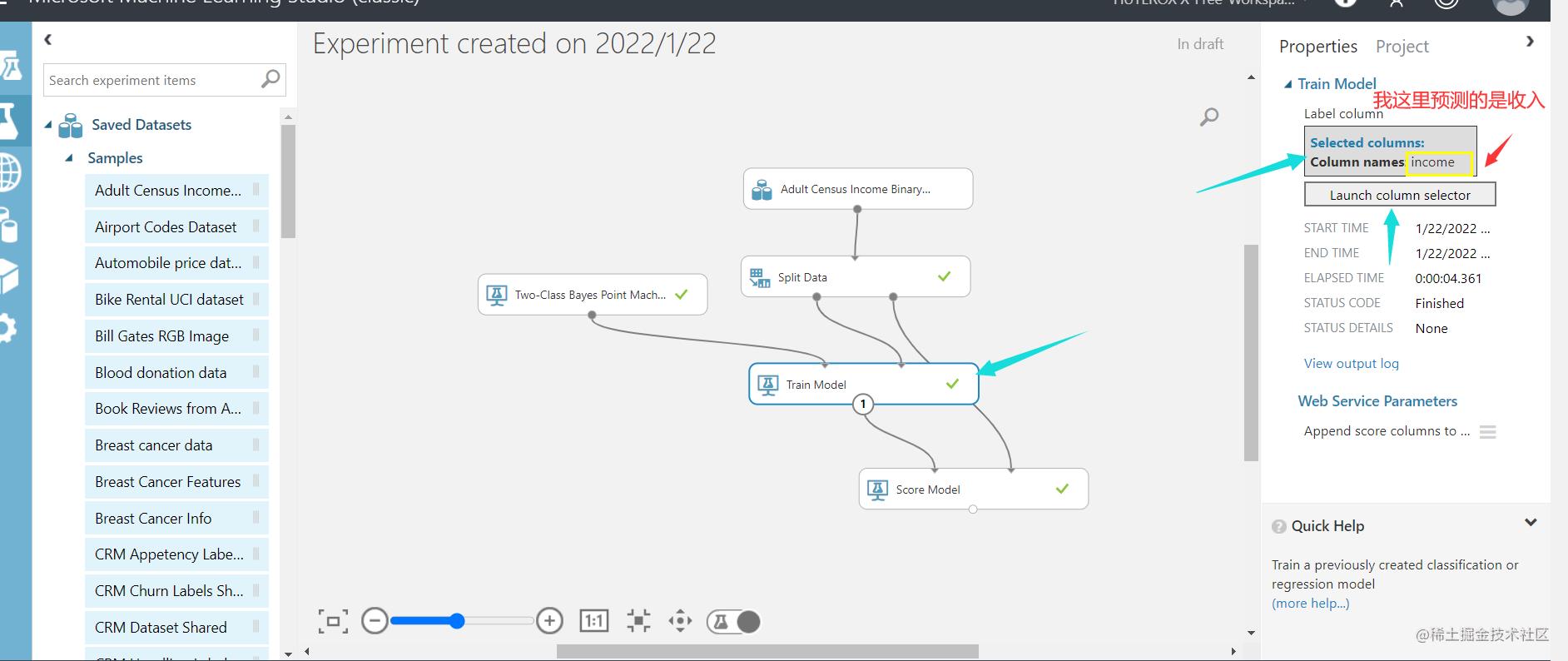
之后点击运行
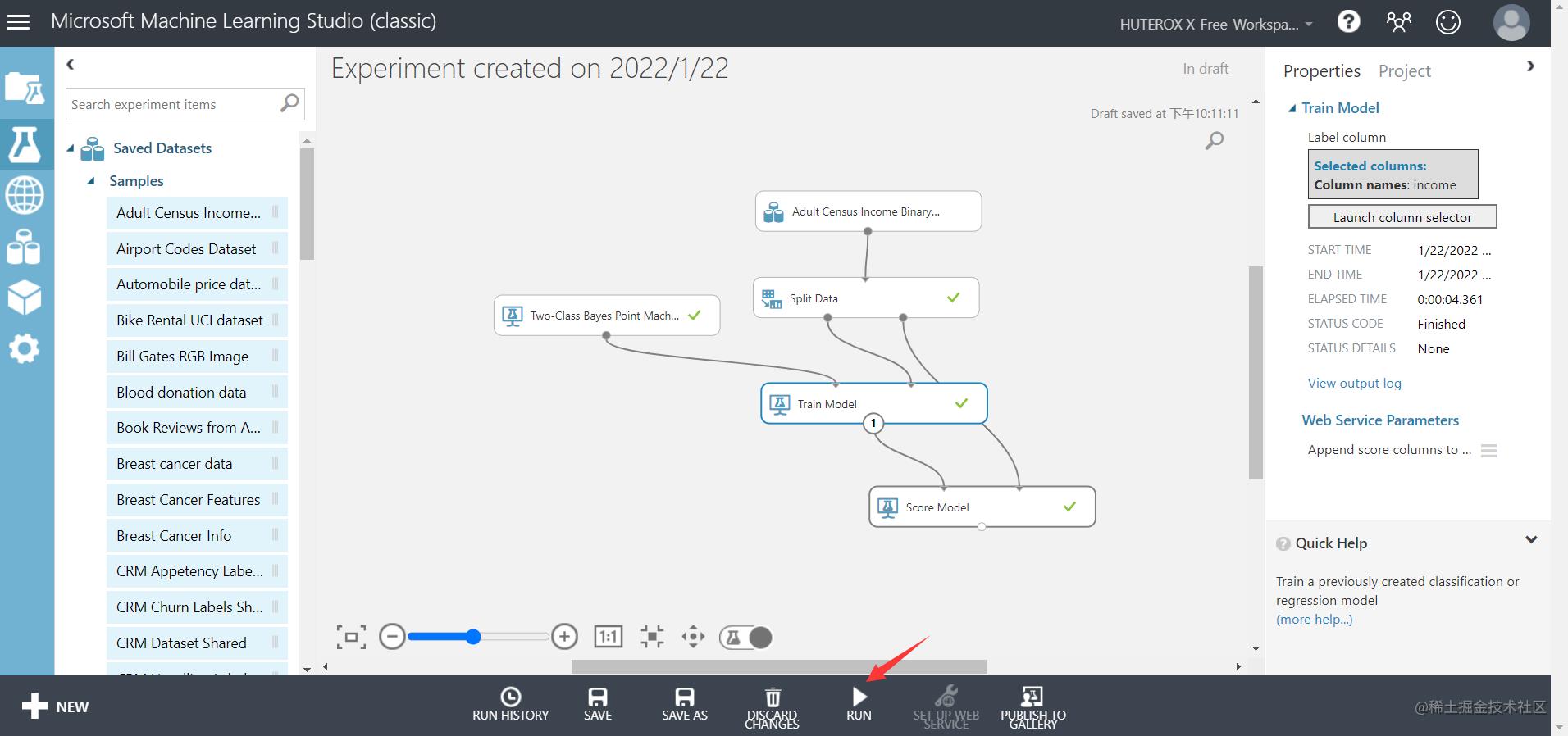
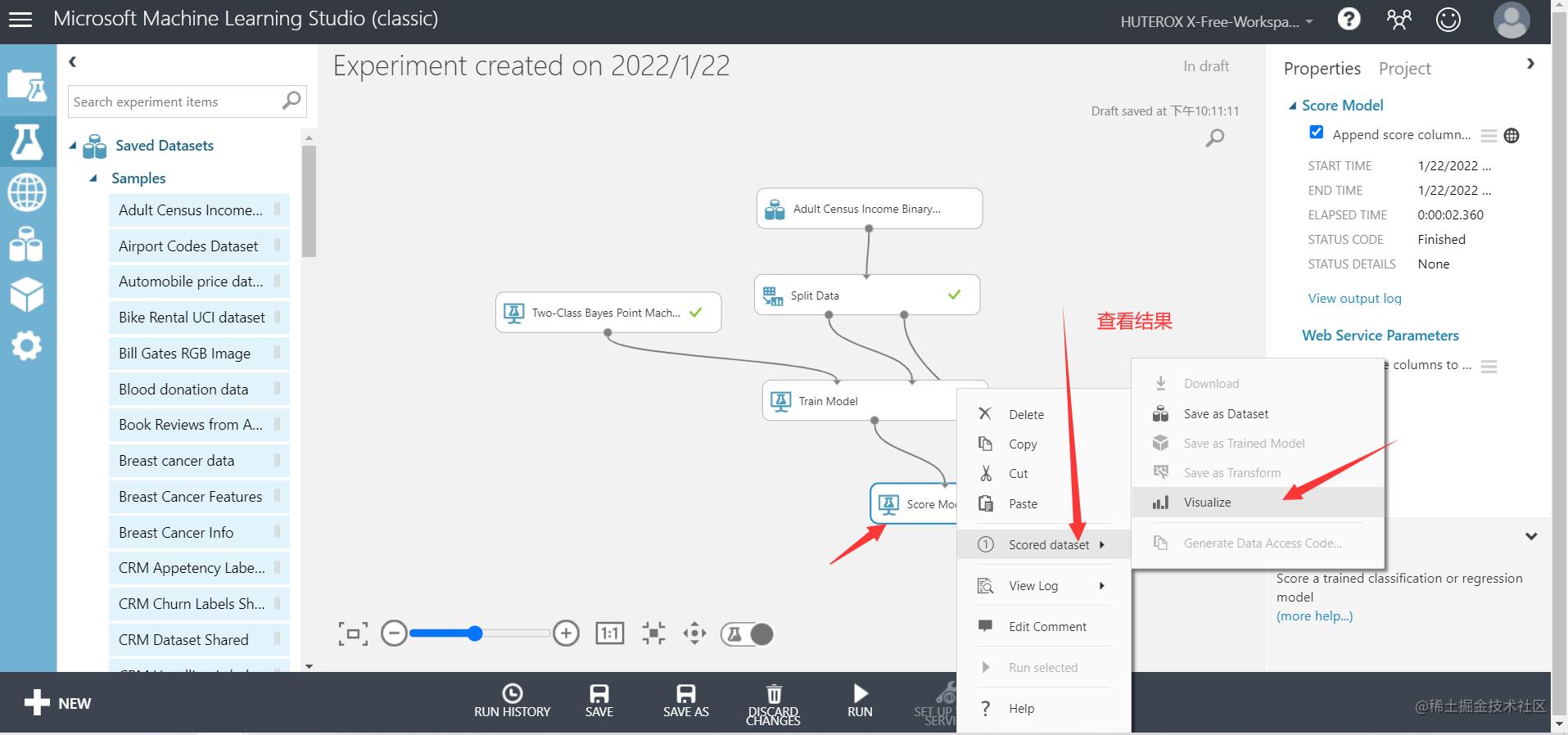

最后是我们的模型评估

机器学习算法分类
1 监督学习
定义:
输入数据是由输入特征值和目标值所组成。 函数的输出可以是一个连续的值(称为回归), 或是输出是有限个离散值(称作分类)。
例如:
回归问题
对某些数据进行预测
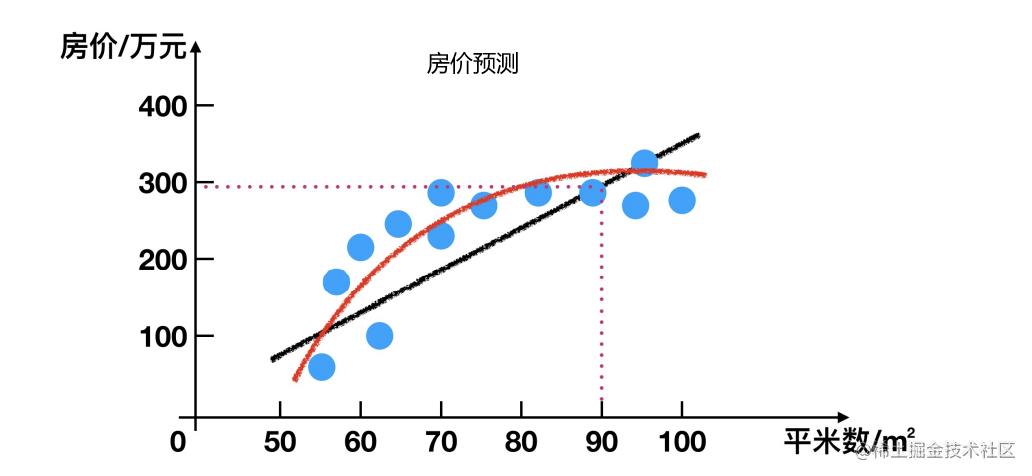
分类问题

当然关于分类问题 也可以是无监督学习例如 K-means
2无监督学习
定义: 输入数据是由输入特征值组成,没有目标值 输入数据没有被标记,也没有确定的结果。样本数据类别未知; 需要根据样本间的相似性对样本集进行类别划分。
举个例子就是,对你班上的人进行划分,你想怎么分都行,只要你能说出理由。

3半监督学习
定义: 训练集同时包含有标记样本数据和未标记样本数据。
这个举个例子就是,我们前面的监督学习是指输入数据是由输入特征值和目标值所组成。
也就是说,输入数据是【数据,标签】的形式,那么半监督就是输入的数据有一些是【数据,标签】还有一些是没有的。

模型评估
模型评估的话主要就是对,当前预测值和我们原有的数据集进行对比,例如一组数据,我们把75%用于训练25%用于评估,我们通过75%的数据进行训练得到模型,之后我们利用这个模型去预测剩下25%之后预测值和我们的实际值进行误差检验,例如最经典的求均方差

那么说到这里,我们模型还容易出现两张情况。
欠拟合
过拟合

以上是关于机器学习小概述(机器学习初体验(Azure))的主要内容,如果未能解决你的问题,请参考以下文章
机器学习之sklearn基础——一个小案例,sklearn初体验