SparkSQL 之旅
Posted cpuCode
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SparkSQL 之旅相关的知识,希望对你有一定的参考价值。
SparkSQL 之旅
概述

Spark SQL 是 Spark 用于结构化数据 ( structured data ) 处理的 Spark 模块
Hive and SparkSQL
SparkSQL 的前身是 Shark ,给熟悉 RDBMS 但又不理解 MapReduce 的技术人员提供快速上手的工具
Hive 是早期唯一运行在 Hadoop 上的 SQL-on-Hadoop 工具
但 MapReduce 计算过程中大量的中间磁盘落地过程消耗了大量的 I / O,降低的运行效率,为了提高 SQL-on-Hadoop 的效率,大量的 SQL-on-Hadoop 工具开始产生
如 :
- Drill
- Impala
- Shark
其中 Shark 是伯克利实验室 Spark 生态环境的组件之一,是基于 Hive 所开发的工具,修改三个模块,就运行在 Spark 引擎上
三个模块 :
- 内存管理
- 物理计划
- 执行

Shark 的出现,使得 SQL-on-Hadoop 的性能比 Hive 有了 10 - 100 倍的提高

最后"野心勃勃",停止对 Shark 的开发,发展出两个支线:SparkSQL 和 Hive on Spark

Spark SQL 为了简化 RDD 的开发,提供了2个编程抽象 :
- DataFrame
- DataSet
特点
- 易整合 : 无缝的整合了 SQL 查询和 Spark 编程
- 统一的数据访问 : 使用相同的方式连接不同的数据源
- 兼容Hive : 使用相同的方式连接不同的数据源
- 标准数据连接 : 通过 JDBC 或者 ODBC 来连接
DataFrame
DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中的二维表格
DataFrame 与 RDD 的区别 :
DataFrame : 有 schema 元信息,即 DataFrame 所表示的二维表数据集的每一列都带有名称和类型。Spark SQL有更多的结构信息,对 DataFrame 的数据源 和 在 DataFrame 之上的变换进行针对性的优化,可以提升运行效率
RDD : 不知数据元素的内部结构,Spark Core 只能在 stage 层面进行简单、通用的流水线优化。
DataFrame 支持嵌套数据类型(struct、array 和 map), DataFrame API提供了一套高层的关系操作,比函数式的 RDD API 更吊
DataFrame 和 RDD 的区别 :
-
RDD[Person] : 以 Person 为类型参数,无类的内部结构
-
DataFrame : 详细的结构信息,数据集中包含哪些列,每列的名称和类型各是什么
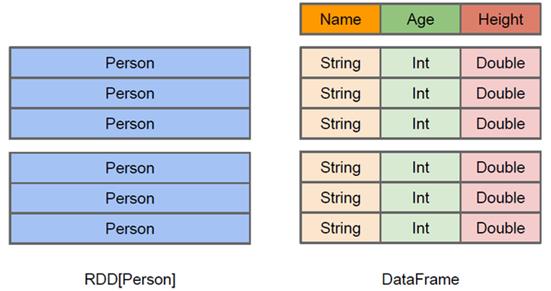
DataFrame : 为数据提供了 Schema 的视图。当数据库中的一张表来对待
DataFrame 也是懒执行的,但性能上比 RDD 要高
主要原因:优化的执行计划,即查询计划通过 Spark catalyst optimiser 进行优化
例子 :
user.join(events, users("id") === events("uids"))
.filter(events("date") > "2021-11-11")
左图 : 构造了两个 DataFrame ,将它们 join 之后又做了一次 filter 操作 , 执行该执行计划,执行效率不高
因为 join 是一个代价较大的操作,也可能会产生一个较大的数据集
右图 : 将 filter下推到 join下方,先对 DataFrame 进行过滤,再 join 过滤后的较小的结果集,就可缩短执行时间
Spark SQL 的查询优化器的逻辑查询计划优化就是一个利用基于关系代数的等价变换,将高成本的操作替换为低成本操作的过程

性能图 :
DataSet
DataSet 是分布式数据集合
DataSet 是 Spark 1.6 中添加的一个新抽象,是 DataFrame 的一个扩展,提供了 RDD 的优势(强类型, lambda 函数)以及 Spark SQL 优化执行引擎的优点
DataSet 也可以使用功能性的转换( map,flatMap,filter 等)
-
DataSet是DataFrame API的一个扩展,是SparkSQL最新的数据抽象
-
友好的 API 风格,有类型安全检查 和 DataFrame 的查询优化特性
-
用样例类来对 DataSet 中定义数据的结构信息,样例类中每个属性的名称直接映射到 DataSet 中的字段名称
-
DataSet是强类型。如 : DataSet[Car],DataSet[Person]
-
DataFrame 是 DataSet 的特列,
DataFrame = DataSet[Row],所以可以通过 as 方法将 DataFrame 转换为 DataSet 。Row是一个类型,跟Car、Person 这些的类型一样,所有的表结构信息都用 Row 来表示。获取数据时需要指定顺序
核心编程
Spark Core 中,如果要执行应用程序,先构建上下文环境对象 SparkContext ,Spark SQL 为对 Spark Core 的一种封装,不仅在模型上封装,还在上下文环境对象也封装了
以前 , SparkSQL有两种SQL查询起始点:
- SQLContext : Spark 自己提供的 SQ L查询
- HiveContext : 连接 Hive 的查询
SparkSession 是 Spark 最新的 SQL 查询起始点,实质上是 SQLContext 和 HiveContext 的组合,所以在 SQLContex 和HiveContext 上可用的 API 在 SparkSession 上也可使用
SparkSession 内部封装了 SparkContext,所以计算实际上是由 sparkContext 完成的
当使用 spark-shell 的时 , spark 会自动创建 SparkSession 对象 , 就和以前自动获取 sc 来表示 SparkContext 对象一样
DataFrame
DataFrame API 允许使用 DataFrame 而不用去注册临时表 或 生成 SQL 表达式
DataFrame API 既有 transformation 操作也有 action 操作
创建DataFrame
SparkSession 是创建 DataFrame 和执行 SQL 的入口
创建DataFrame有三种方式 :
- 通过 Spark 的数据源进行创建
- 从一个存在的 RDD 进行转换
- Hive Table 进行查询返回
从Spark数据源进行创建
查看 Spark 支持创建文件的数据源格式
spark.read.
在 spark 的 bin/data 目录(windows环境)中创建 user.json 文件
"username":"zhangsan",
"age":20
读取 json 文件创建 DataFrame
val df = spark.read.json("data/user.json")
从内存中获取数据,spark 可以知道数据类型具体是什么。如 : 数字,默认作为 Int 处理
从文件中读取的数字,不确定是什么类型,用 bigint 接收,可以和 Long 类型转换,但不能和 Int 进行转换
展示结果 :
show
从RDD进行转换
从Hive Table进行查询返回
SQL语法
SQL 语法风格 : 查询数据时使用 SQL 语句来查询,这种风格的查询必须要有临时视图或者全局视图来辅助
读取 JSON 文件创建 DataFrame
val df = spark.read.json("data/user.json")
对 DataFrame 创建一个临时表(视图)
df.createOrReplaceTempView("people")
通过 SQL 语句实现查询全表
val sqlDF = spark.sql("SELECT * FROM people")
结果展示
sqlDF.show
普通临时表是 Session 范围内的
全局临时表是应用范围内有效。使用全局临时表时需要全路径访问,如:global_temp.people
对于 DataFrame 创建一个全局表
df.createGlobalTempView("people")
通过 SQL 语句实现查询全表
spark.sql("SELECT * FROM global_temp.people").show()
spark.newSession().sql("SELECT * FROM global_temp.people").show()
DSL语法
DataFrame 提供一个特定领域语言(domain-specific language, DSL)去管理结构化的数据。
可以在 Scala, Java, Python 和 R 中使用 DSL,使用 DSL 语法风格不用创建临时视图
创建一个DataFrame
val df = spark.read.json("data/user.json")
查看 DataFrame 的 Schema 信息
df.printSchema
只查看 “username” 列数据,
df.select("username").show()
查看 “username” 列数据以及 “age+1” 数据
涉及到运算时 , 每列都必须使用 $ , 或 用引号表达式:单引号 + 字段名
df.select($"username", $"age" + 1).show()
df.select('username, ' age + 1).show
df.select('username, ' age + 1 as "newAge").show
查看 “age” 大于 “30” 的数据
df.filter($"age" > 30).show
按照 “age” 分组,查看数据条数
df.groupBy("age").count.show
RDD 转 DataFrame
在 IDEA 中开发程序时,如果需要 RDD 与 DF 或者 DS 之间互相操作,那么需要引入 import spark.implicits._ , spark 不是 Scala 中的包名
先创建 SparkSession 对象再导入 ,再创建的 sparkSession 对象的变量名称
Scala 只支持 val 修饰的对象的引入 ,所以 spark 对象不能使用 var 声明
spark-shell 中无需导入,自动完成此操作
val idRDD = sc.textFile("data/id.txt")
idRDD.toDF("id").show
将 RDD 转换为 DataFrame
case class User(name:String, age:Int)
sc.makeRDD(List(("cpucode",30), ("cpu",40)))
.map(t => User(t._1, t._2)).toDF.show
DataFrame 转 RDD
DataFrame 其实就是对 RDD 的封装,所以可以直接获取内部的 RDD
val df = sc.makeRDD(List(("cpucode", 20), ("cpu", 10)))
.map(t => User(t._1, t._2)).toDF
val rdd = df.rdd
val arrar = rdd.collect
得到的 RDD 存储类型为 Row
array(0)
array(0)(0)
array(0).getAs[String]("name")
DataSet
DataSet 是具有强类型的数据集合,需要提供对应的类型信息
创建 DataSet
样例类序列创建 DataSet
case class Person(name: String, age: Long)
val caseClassDS = Seq(Person("cpucode", 22)).toDS()
caseClassDS.show
基本类型的序列创建 DataSet
val ds = Seq(1, 2, 3, 4, 5).toDS
ds.show
RDD 转 DataSet
SparkSQL 能够自动将包含有 case 类的 RDD 转换成 DataSet
case 类定义了 table 的结构,case 类属性通过反射变成了表的列名。Case 类可以包含 Seq 或 Array 等复杂的结构
case class User(name:String, age:Int)
sc.makeRDD(List(("cpucode", 22), ("cpu", 33), ("code", 44)))
.map(t => User(t._1, t._2)).toDS
DataSet 转 RDD
DataSet 其实也是对 RDD 的封装,所以可以直接获取内部的 RDD
case class User(name: String, age: Int)
sc.makeRDD(List(("cpucode", 20), ("code", 11)))
.map(t => User(t._1, t._2)).toDS
val rdd = res11.rdd
rdd.collect
DataFrame 和 DataSet转换
DataFrame 其实是 DataSet 的特例,所以它们之间是可以互相转换的
DataFrame 转 DataSet
case class User(name: String, age: Int)
val df = sc.makeRDD(List("cpucode", 22), ("code", 33)).toDF("name", "age")
val ds = df.as[User]
DataSet 转 DataFrame
val df = ds.toDF
RDD、DataFrame、DataSet三者的关系
SparkSQL 两个新的抽象 :
- DataFrame
- DataSet
从版本的产生上来看:
- Spark1.0 => RDD
- Spark1.3 => DataFrame
- Spark1.6 => Dataset
三者的共性
RDD、DataFrame、DataSet 全都是 Spark 平台下的分布式弹性数据集,为处理超大型数据提供便利
三者都有惰性机制,在进行创建、转换,如 map 方法时,不会立即执行,只有在遇到 Action 如 foreach 时,三者才会开始遍历运算
三者有许多共同的函数,如 filter,排序等
在对 DataFrame 和 Dataset 进行操作许多操作都需要这个包: import spark.implicits._(在创建好 SparkSession 对象后尽量直接导入)
三者都会根据 Spark 的内存情况自动缓存运算 ,这样即使数据量很大,也不用担心会内存溢出
三者都有 partition 的概念
DataFrame 和 DataSet 均可使用模式匹配获取各个字段的值和类型
三者的共性
RDD
- RDD 一般和 spark mllib 同时使用
- RDD不支持 sparksql 操作
DataFrame
-
与 RDD 和 Dataset 不同,DataFrame 每一行的类型固定为 Row,每一列的值没法直接访问,只有通过解析才能获取各个字段的值
-
DataFrame 与 DataSet 一般不与 spark mllib 同时使用
-
DataFrame 与 DataSet 均支持 SparkSQL 的操作,如 : select,groupby 之类,还能注册临时表 / 视窗,进行 sql 语句操作
-
DataFrame 与 DataSet 支持一些保存方式,如 : 保存成 csv,可以带上表头,这样每一列的字段名
DataSet
-
Dataset 和 DataFrame 拥有完全相同的成员函数,区别只是每一行的数据类型不同。 DataFrame 是 DataSet 的一个特例
type DataFrame = Dataset[Row] -
DataFrame ( Dataset[Row] ) , 每一行的类型是 Row,不解析,每一行有哪些字段什么类型不知道,只能用 getAS 方法 或 共性中模式匹配拿出特定字段
-
Dataset ,每一行是什么类型是不一定的,在自定义 case class 后可以获得每一行的信息
三者的互相转换

IDEA开发SparkSQL
添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
代码实现
object SparkSql_Demo
def main(args: Array[String]): Unit =
//创建上下文环境配置对象
val conf: SparkConf = new SparkConf()
.setMaster("local[*]").setAppName("SparkSql_Demo")
//创建SparkSession对象
val spark:SparkSession = SparkSession.builder().config(conf).getOrCreate()
//RDD => DataFrame => DataSet 转换需要引入隐式转换规则,否则无法转换
//spark 不是包名,是上下文环境对象名
import spark.implicits._
//读取json文件 创建DataFrame "username": "lisi","age": 18
val df: DataFrame = spark.read.json("input/test.json")
//df.show()
//SQL风格语法
df.createOrReplaceTempView("user")
//spark.sql("select avg(age) from user").show
//DSL风格语法
//df.select("username", "age").show()
//***** RDD => DataFrame => DataSet *****
//RDD
val rdd1: RDD[(Int, String, Int)] = spark.sparkContext
.makeRDD(List(1, "cpucode", 30), (2, "cpu", 22), (3, "code", 33))
//DataFrame
val df1: DataFrame = rdd1.toDF("id", "name", "age")
//df1.show()
//DateSet
val ds1: Dataset[User] = df1.as[User]
//ds1.show()
//***** DataSet => DataFrame= > RDD *****
//DataFrame
val df2: DataFrame = ds1.toDF()
//RDD 返回的RDD类型为Row,里面提供的getXXX方法可以获取字段值,类似jdbc处理结果集,但是索引从0开始
val rdd2: RDD[Row] = df2.rdd
//rdd2.foreach(a=>println(a.getString(1)))
//***** RDD => DataSet *****
rdd1.map
case (id, name, age) => User(id, name, age)
.toDS()
//*****DataSet=>=>RDD*****
ds1.rdd
//释放资源
spark.stop()
case class User(id:Int, name:String, age:Int)
用户自定义函数
通过 spark.udf 添加自定义函数,实现自定义功能
UDF
创建 DataFrame
val df = spark.read.json("data/user.json")
注册 UDF
spark.udf.register("addName", (x: String) => "Name:" + x)
创建临时表
df.createOrReplaceTempView("people")
应用 UDF
spark.sql("select addName(name), age from people").show()
UDAF
强类型的 Dataset 和 弱类型的 DataFrame 都提供了相关的聚合函数
如 : count(),countDistinct(),avg(),max(),min()
用户可以设定自己的自定义聚合函数。通过继承 UserDefinedAggregateFunction 来实现用户自定义弱类型聚合函数
从 Spark3.0 版本后,不推荐使用弱类型聚合 。统一采用强类型聚合函数 Aggregator
需求:计算平均工资
实现方式 - RDD
val conf: SparkConf = new SparkConf().setAppName("app").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
val res: (Int, Int) = sc.makeRDD(List("cpucode", 22), ("lisi", 30)).map
case (name, age) =>
(age, 1)
.reduce
(t1, t2) =>
(t1._1 + t2._1, t1._2 + t2._2)
println(res._1 / res._2)
// 关闭连接
sc.stop()
实现方式 - 累加器
class MyAC extends AccumulatorV2[Int, Int]
var sum:Int = 0
实现方式 - UDAF - 弱类型
实现方式 - UDAF - 强类型
Spark3.0 版本可以采用强类型的 Aggregate 方式代替 UserDefinedAggregateFunction
数据的加载和保存
通用的加载和保存方式
SparkSQL 提供了通用的保存数据和数据加载的方式
通用指的是使用相同的API,根据不同的参数读取 和 保存不同格式的数据,SparkSQL默认读取和保存的文件格式为 parquet
加载数据
spark.read.load 是加载数据的通用方法
spark.read.
读取不同格式的数据,可以对不同的数据格式进行设定
spark.read.format("...")[.option("...")].load("...")
format("…"):指定加载的数据类型,包括"csv"、“jdbc”、“json”、“orc”、“parquet"和"textFile”
在文件上进行查询: 文件格式.`文件路径`
spark.sql("select * from json.`/opt/module/data/user.json`").show
保存数据
| Scala/Java | Any Language | Meaning |
|---|---|---|
| SaveMode.ErrorIfExists(default) | “error”(default) | 如果文件已经存在则抛出异常 |
| SaveMode.Append | “append” | 如果文件已经存在则追加 |
| SaveMode.Overwrite | “overwrite” | 如果文件已经存在则覆盖 |
| SaveMode.Ignore | “ignore” | 如果文件已经存在则忽略 |
df.write.mode("append").json("/opt/module/data/output")
Parquet
Spark SQL 的默认数据源为 Parquet 格式。Parquet 是一种能够有效存储嵌套数据的列式存储格式
数据源为 Parquet 文件时,Spark SQL 可以方便的执行所有的操作,不需要使用 format 。修改配置项 spark.sql.sources.default ,可修改默认数据源格式
JSON
Spark SQL 能够自动推测 JSON 数据集的结构,并将它加载为一个 Dataset[Row]. 可以通过SparkSession.read.json() 去加载 JSON 文件
Spark读取的JSON文件不是传统的JSON文件,每一行都应该是一个JSON串
CSV
mysql
Hive
项目实战
以上是关于SparkSQL 之旅的主要内容,如果未能解决你的问题,请参考以下文章