Elasticsearch:Supervised Machine Learning - 有监督的机器学习
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:Supervised Machine Learning - 有监督的机器学习相关的知识,希望对你有一定的参考价值。
Elastic 监督学习使你能够根据你提供的训练示例训练机器学习模型。 然后,你可以使用你的模型对新数据进行预测。 本文章总结了训练、评估和部署模型的端到端工作流程。 它对使用监督学习识别和实施解决方案所需的步骤进行了概述。这篇文章是之前文章 “Elasticsearch:使用 Elastic 机器学习进行 data frame 分析” 的续篇。
监督学习的工作流程包括以下阶段:
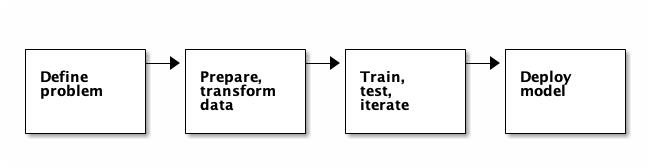
这些是迭代阶段,这意味着在评估每个步骤之后,你可能需要在进一步进行之前进行调整。
定义问题
花点时间思考一下机器学习在哪些方面最有影响力是很重要的。考虑一下你有什么类型的数据可用,它有什么价值。你对数据了解得越多,你就能越快地创建机器学习模型,从而产生有用的见解。你想在数据中发现什么样的模式?你想预测什么类型的值:一个类别,还是一个数值?这些答案可帮助你选择适合你的用例的分析类型。
确定问题后,请考虑哪些机器学习功能最有可能帮助你解决问题。监督学习需要一个数据集,其中包含可以训练模型的已知值。无监督学习——如异常检测或异常检测——没有这个要求。
Elastic Stack 提供以下类型的监督学习:
- regression:预测连续的数值,例如 Web 请求的响应时间。这个变量是可以连续变化的。
- classification:预测离散的分类值,例如 DNS 请求是来自恶意域还是良性域(两个 class)。或者是多个 class,比如新闻的分类:entertainment,sports,news,politics 等。

准备和转换数据
你已经定义了问题并选择了适当的分析类型。下一步是在 Elasticsearch 中生成与你的训练目标有明确关系的高质量数据集。如果你的数据尚未在 Elasticsearch 中,则这是你开发 data pipeline 的阶段。如果你想了解有关如何将数据摄取到 Elasticsearch 的更多信息,请参阅摄入节点文档。
Regression 和 classification 是有监督的机器学习技术,因此你必须提供标记数据集进行训练。这通常被称为“基本事实”。训练过程使用此信息来识别数据的各种特征与预测值之间的关系。它在模型评估中也起着至关重要的作用。
一个重要的要求是足够大的数据集来训练模型。例如,如果你想训练一个分类模型来确定电子邮件是否为垃圾邮件,你需要一个标记数据集,其中包含来自每个可能类别的足够数据点来训练模型。什么算“足够”取决于各种因素,例如问题的复杂性或你选择的机器学习解决方案。没有适合每个用例的确切数字;决定有多少数据是可接受的,是一个可能涉及迭代试验的启发式过程。
在训练模型之前,请考虑对数据进行预处理。在实践中,预处理的类型取决于数据集的性质。预处理可以包括但不限于减少冗余、减少偏差、应用标准和/或约定、数据规范化等。
Regression 和 Classificaiton 需要专门结构化的源数据:二维表格数据结构。出于这个原因,你可能需要转换你的数据以创建一个 data frame,该 data frame 可用作这些类型的 data frame 分析的来源。有关 data frame 的详细介绍,请参阅我之前的文章 “Elasticsearch:使用 Elastic 机器学习进行 data frame 分析”。
训练、测试、迭代
准备好数据并将其转换为正确的格式后,就该训练模型了。训练是一个迭代过程 — 每次迭代之后都会进行评估,以了解模型的性能。
第一步是定义将用于训练模型的特征——数据集中的相关字段。默认情况下,所有支持类型的字段都会自动包含在 regression 和 classification 中。但是,你可以选择从流程中排除不相关的字段。这样做使大型数据集更易于管理,减少了训练所需的计算资源和时间。
接下来,你必须定义如何将数据拆分为训练集和测试集。测试集不会用于训练模型;它用于评估模型的性能。没有适合所有用例的最佳百分比,这取决于数据量和你必须训练的时间。对于大型数据集,你可能希望从较低的训练百分比开始,以便在短时间内完成端到端迭代。
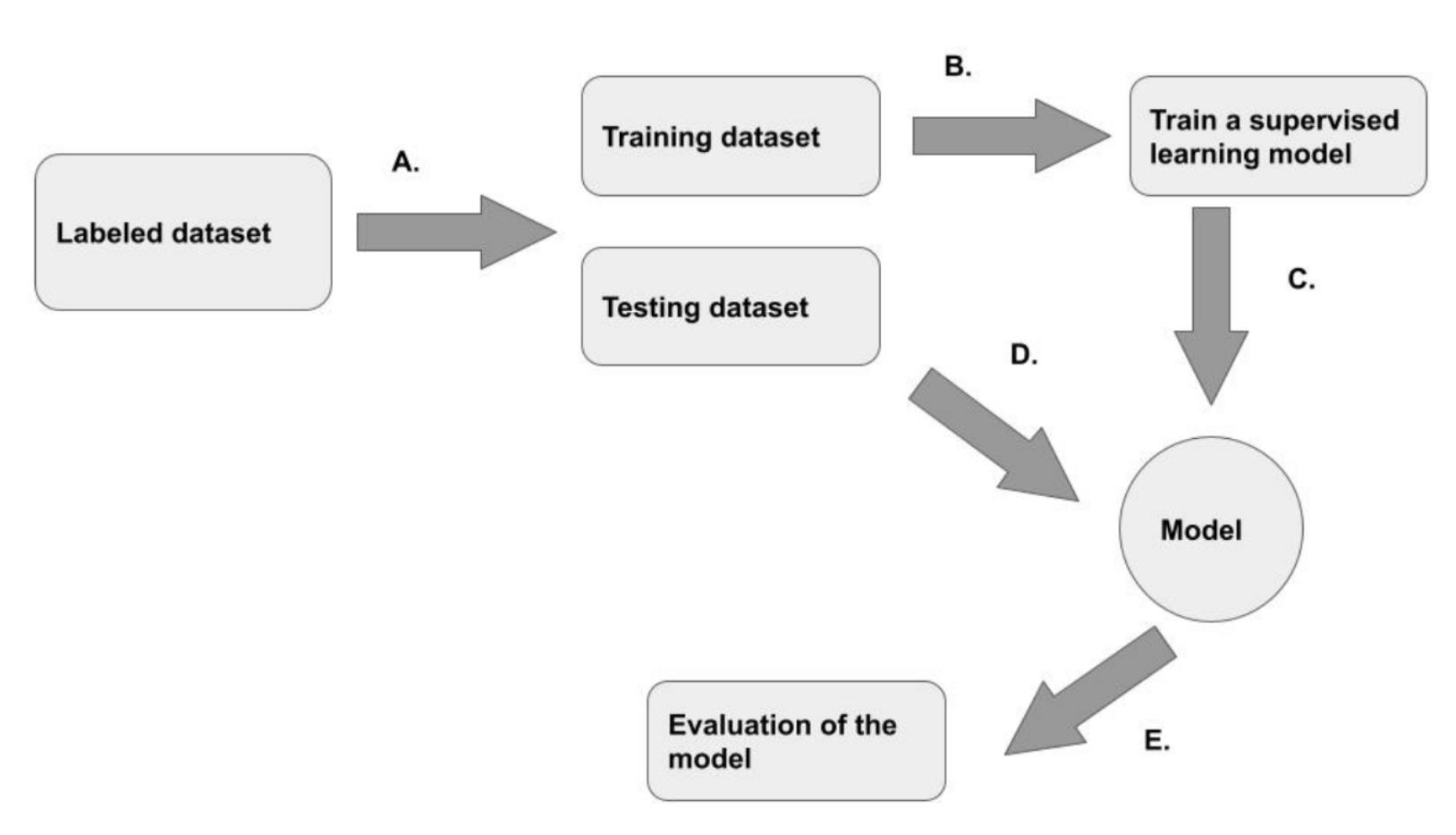
在训练过程中,训练数据通过学习算法输入。该模型预测该值并将其与基本事实进行比较,然后对该模型进行微调以使预测更加准确。
针对 Classification,我们可以使用如下的一个图来进行描述:
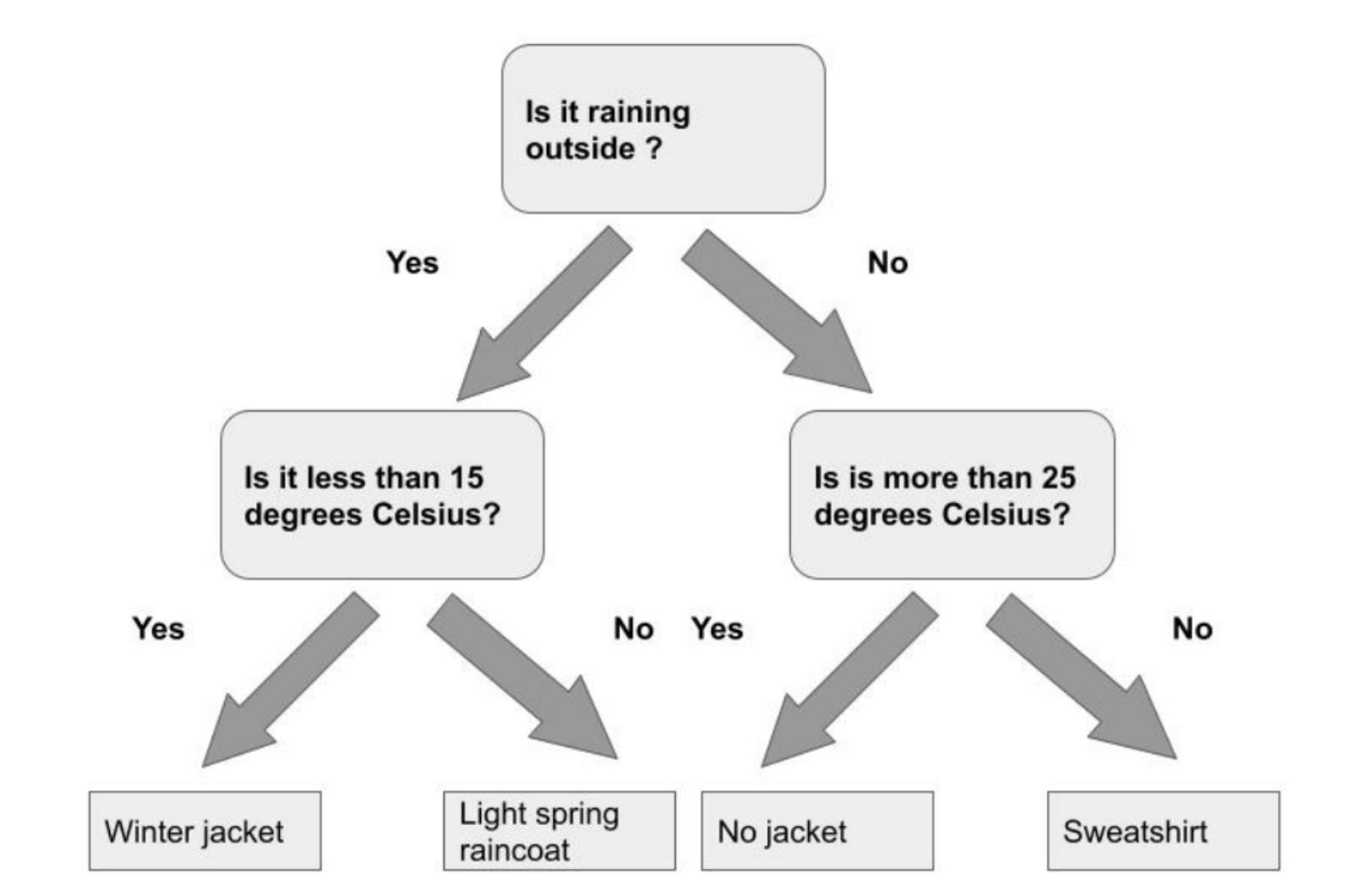
在上面图中,它显示了针对一个特定的条件,机器学习可以帮我们判断合适的可穿的衣服。如上所示,它含有不同的 class 可供选择。
针对 Regression,我们可以使用如下的图来进行描述:
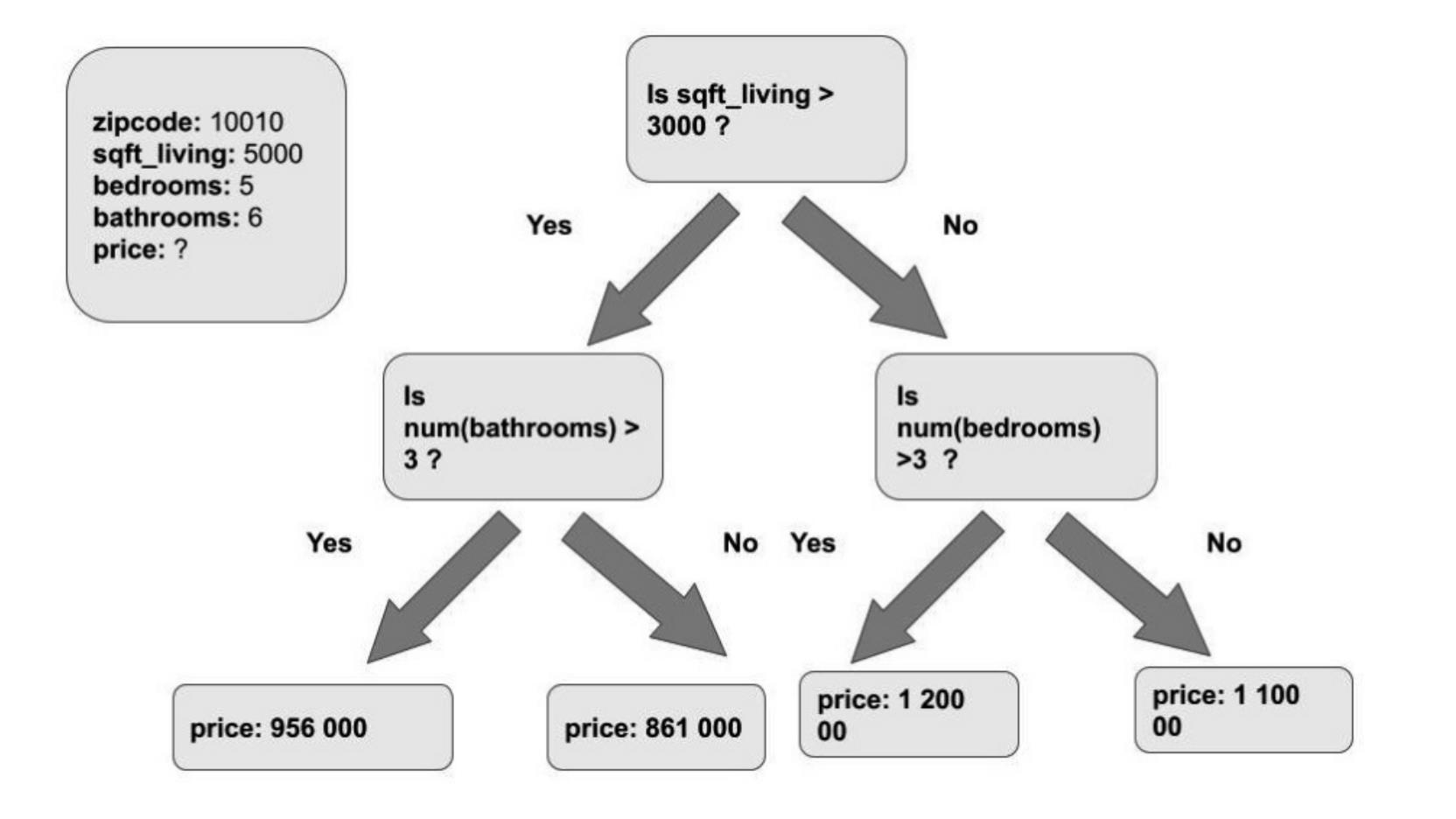
和 Classification 不同的是,regression 可以预测连续变化的变量值。针对上面的图来说,给定一定的条件,运用机器学习,我们可以预测房屋的价格。 关于上面的数据模型,请参阅我之前的文章 “Elasticsearch:使用 Elastic 机器学习进行 data frame 分析”。
部署模型
你已经训练了模型并对性能感到满意。 最后一步是部署经过训练的模型并开始在新数据上使用它。
称为 inference 的 Elastic 机器学习功能使你能够通过将新数据用作摄入管道中的处理器、连续转换或搜索时的聚合来对新数据进行预测。 当新数据进入你的摄取管道或你使用推理聚合对数据运行搜索时,该模型用于推断数据并对其进行预测。
Supervised Learning 演示
我们先准备数据。我们回到之前的文章 “Elasticsearch:使用 Elastic 机器学习进行 data frame 分析”。在那篇文章中,我们已经成功地摄入了美国 King County 这个地区的房价信息。我们接着那篇文章继续进行演示。
打开 Kibana:

这次我们选择 Regression 而不是之前的 Outlier detection。

接下来,我们选择我们感兴趣的那些参数来进行预测。比如,我们可以把 id, 经纬度参数去掉:

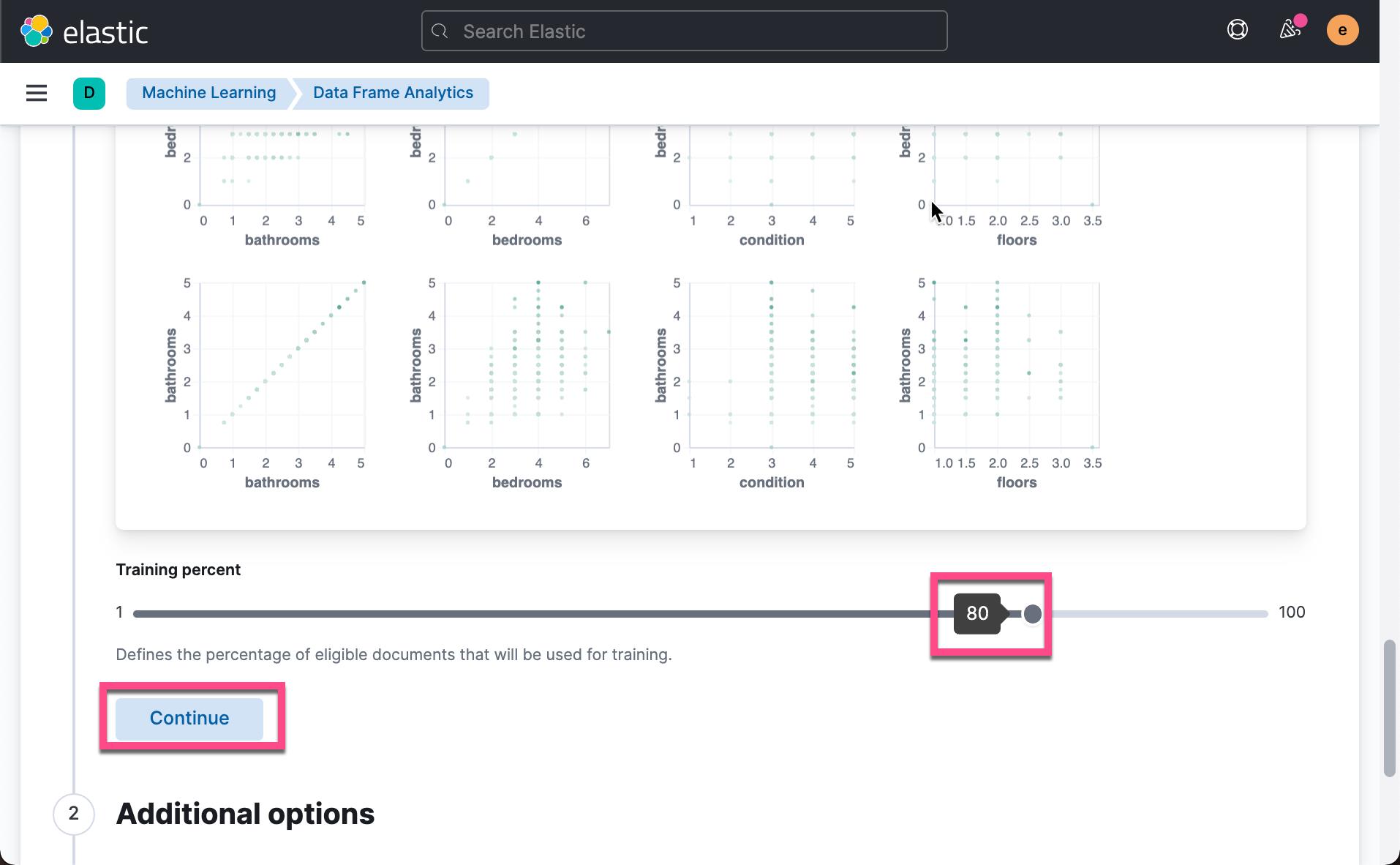
正如我们在上面所讲的,我们需要一定的数据集来进行训练,同时我们需要留一些数据来进行检验我们的模型是否正确。在上面,我们可以选择多少比例的数据来进行训练。 这个比例依赖于你有多少数据,你需要多长时间来完成训练。如果你的数据集比较大,那么建议你使用比较小的比例来做训练,并且不断地进行矫正直到你得到合适的正确率。针对我们的情况,我们的数据集并不是很大。我们接受默认的 80%。点击上面的 Continue:



点击上面的 Create 按钮。我们需要等一段时间才可以让我们的机器学习训练完成:
依赖于你的数据集的多少,这个时间可能会很长。针对我们的情况,这个需要大约3-4分钟的时间:


为了检验我们的模型的正确性,我们选择 Testing 数据集:
我们接着查看在测试数据集中的数据准确度:

从上面的表格中,我们可以看出来尽管有些数据的差异还是有的,但是绝大多数的被预测的 price 和 实际的 price 相差不是很大。我们还可以从上面的表格中查看出来有些字段对价格的预测的影响:

Inference - 推理
推理是一种机器学习功能,使你能够使用受监督的机器学习过程(例如 regression 或 classification),不仅可以作为批处理分析,而且可以以连续方式使用。 这意味着推理可以使用经过训练的机器学习模型来处理传入的数据。
例如,假设你有一项在线服务,并且你想预测客户是否可能流失。 你有一个包含历史数据的索引(有关你业务中多年来客户行为的信息)以及基于此数据训练的分类模型。 新信息进入连续变换的目标索引。 通过推理,你可以使用与训练模型相同的输入字段对新数据执行分类分析,并获得预测。

让我们仔细看看推理背后的机制。
Inference processor
Inference 可以用作摄取管道中指定的处理器。 它使用经过训练的模型来推断管道中正在摄取的数据。 该模型用于摄入节点。 Inference 通过使用模型对数据进行预处理并提供预测。 在这个过程之后,管道继续执行(如果管道中有任何其他处理器),最后将新数据与结果一起索引到目标索引中。
查看 inference processor 和机器学习 data frame 分析 API 文档以了解有关该功能的更多信息。
Inference aggregation
Inference 也可以用作管道聚合。 你可以在聚合中引用经过训练的模型来推断父桶聚合的结果字段。 推理聚合使用结果模型来提供预测。 此聚合使你能够在搜索时运行 regression 或 classification 分析。 如果你想对一小组数据执行分析,此聚合使你无需在摄入管道中设置处理器即可生成预测。
查看 inference aggregation 和机器学习 data frame 分析 API 文档以了解有关该功能的更多信息。
查看机器学习的模型
我们可以使用如下的命令来查看已经建立的模型:
GET _cat/ml/trained_models上述命令生成如下的结果:
lang_ident_model_1 1mb 39629 2019-12-05T12:28:34.594Z 0 __none__
webinar-demo-regression-1642141570214 1mb 1456 2022-01-14T06:26:10.214Z 0 webinar-demo-regression如上所示,我们已经有两个 model。其中的一个 lang_ident_mode_1 是目前每个 Elasticsearch 都含有的一个模型。它是用来识别语言的。感兴趣的开发者可以阅读我之前的文章 “Elasticsearch:在 Elasticsearch 中使用语言识别进行多语言搜索”。而下面的那个 webinar-demo-regression 是我们在上面生成的一个模型。
我们可以使用如下的命令来查看上面的模型的内容:
GET _ml/trained_models/webinar-demo-regression*上面的命令显示:
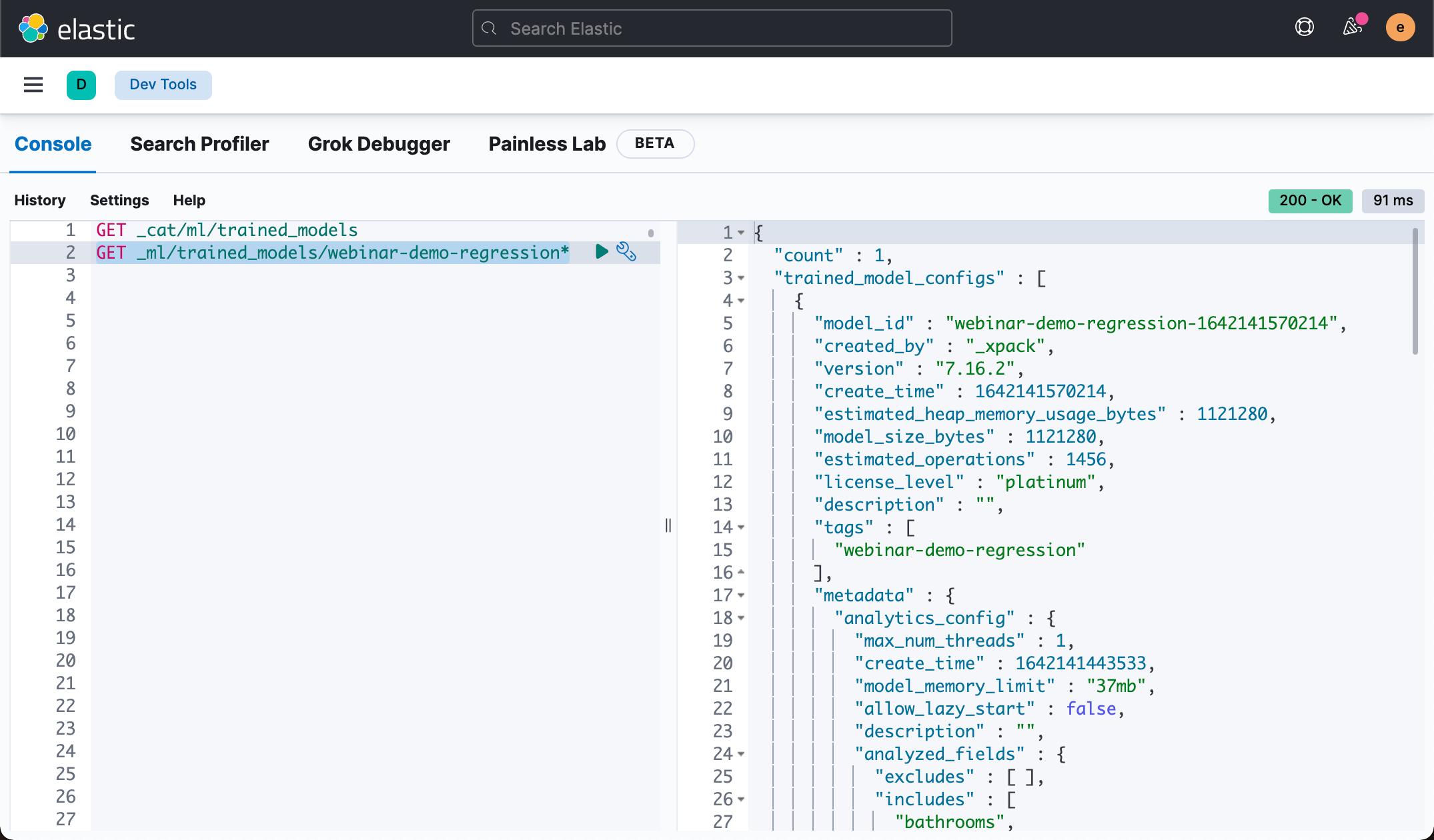
在上面最重要的信息的就是那个 model_id。这个是我们在下面进行推理时需要用到的。
接下来我们使用刚才创建的模型来创建一个基于 inference processor 的 pipeline:
# Enrichment + prediction pipeline
# NOTE: model_id will be different for your data
PUT _ingest/pipeline/house_price_predict
"description": "pridicts a house price given data",
"processors": [
"inference":
"model_id": "webinar-demo-regression-1642141570214",
"inference_config":
"regression":
,
"field_map": ,
"tag": "price_prediction"
]
一般来说,我们可以在上面的 ingest pipeline 里使用 enrich pricessor 来丰富我们的数据如果我们的数据需要从原始的数据中进行导出的话。针对我们的情况,我们不需要。我们运行上面的命令来生产一个叫做 house_price_predict 的 pipeline。
在我们摄入一个数据时,我们可以使用这个 ingest pipeline 来对我们的数据进行预测。为了检验我们的这个模型。我们首先从之前的文档里得到一个文档,比如:
GET king-county-house-prices/_source/ltdgUX4BDxnvOIf6bXj3注意上面的 ltdgUX4BDxnvOIf6bXj3 是我使用 Discover 来发现的一个已有文档的 _id。上面的命令给出的文档信息为:
"date" : "20141013T000000",
"yr_renovated" : 0,
"long" : -122.257,
"view" : 0,
"floors" : 1.0,
"sqft_above" : 1180,
"sqft_living15" : 1340,
"price" : 221900.0,
"id" : 7129300520,
"sqft_lot" : 5650,
"lat" : 47.5112,
"sqft_basement" : 0,
"sqft_lot15" : 5650,
"bathrooms" : 1.0,
"bedrooms" : 3,
"zipcode" : 98178,
"sqft_living" : 1180,
"condition" : 3,
"yr_built" : 1955,
"grade" : 7,
"waterfront" : 0,
"location" : "47.5112,-122.257"
我们接下来可以使用如下的命令来进行测试:
POST _ingest/pipeline/house_price_predict/_simulate
"docs": [
"_source":
"date": "20141013T000000",
"yr_renovated": 0,
"long": -122.257,
"view": 0,
"floors": 1,
"sqft_above": 1180,
"sqft_living15": 1340,
"price": 221900,
"id": 7129300520,
"sqft_lot": 5650,
"lat": 47.5112,
"sqft_basement": 0,
"sqft_lot15": 5650,
"bathrooms": 1,
"bedrooms": 3,
"zipcode": 98178,
"sqft_living": 1180,
"condition": 3,
"yr_built": 1955,
"grade": 7,
"waterfront": 0,
"location": "47.5112,-122.257"
]
在上面的 _source 字段里,我们直接把上面得到的 source 填入。运行上面的命令,我们可以得到:
"docs" : [
"doc" :
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" :
"date" : "20141013T000000",
"yr_renovated" : 0,
"long" : -122.257,
"view" : 0,
"floors" : 1,
"sqft_above" : 1180,
"sqft_living15" : 1340,
"price" : 221900,
"id" : 7129300520,
"sqft_lot" : 5650,
"lat" : 47.5112,
"ml" :
"inference" :
"price_prediction" :
"price_prediction" : 239677.90135690733,
"feature_importance" : [
"feature_name" : "sqft_living",
"importance" : -86914.40339769304
,
"feature_name" : "grade",
"importance" : -67529.40790045598
,
"feature_name" : "zipcode",
"importance" : -60953.68689058545
,
"feature_name" : "sqft_living15",
"importance" : -27909.453510639916
],
"model_id" : "webinar-demo-regression-1642141570214"
,
"sqft_basement" : 0,
"sqft_lot15" : 5650,
"bathrooms" : 1,
"bedrooms" : 3,
"zipcode" : 98178,
"sqft_living" : 1180,
"condition" : 3,
"yr_built" : 1955,
"grade" : 7,
"waterfront" : 0,
"location" : "47.5112,-122.257"
,
"_ingest" :
"timestamp" : "2022-01-17T09:11:59.48992Z"
]
我们使用之前已经建立的模型,我们得到的房屋估计价格是 "price_prediction" : 239677.90135690733。它和我们的实际的价格 221900 还是蛮接近的。在上面的 feature_importance 里,它包含了对这个估算价格贡献最大的四个影响因素:sqft_living,grade,zipcode 及 sqft_living15。
也许你想说,在你输入的文档中本身就含有这个价格 price 字段。我们在下面的 _source 里去掉这个 price 字段:
POST _ingest/pipeline/house_price_predict/_simulate
"docs": [
"_source":
"date": "20141013T000000",
"yr_renovated": 0,
"long": -122.257,
"view": 0,
"floors": 1,
"sqft_above": 1180,
"sqft_living15": 1340,
"id": 7129300520,
"sqft_lot": 5650,
"lat": 47.5112,
"sqft_basement": 0,
"sqft_lot15": 5650,
"bathrooms": 1,
"bedrooms": 3,
"zipcode": 98178,
"sqft_living": 1180,
"condition": 3,
"yr_built": 1955,
"grade": 7,
"waterfront": 0,
"location": "47.5112,-122.257"
]
我们运行上面的命令,我们可以得到同样的答案。也就是说,我们可以根据机器学习创建的模型来预测一个房屋的价格。
我们接下来,我们来尝试微调一些参数,比如修改 sqft_living 的值为 2000,那么我们再来看看最后的估价:
POST _ingest/pipeline/house_price_predict/_simulate
"docs": [
"_source":
"date": "20141013T000000",
"yr_renovated": 0,
"long": -122.257,
"view": 0,
"floors": 1,
"sqft_above": 1180,
"sqft_living15": 1340,
"id": 7129300520,
"sqft_lot": 5650,
"lat": 47.5112,
"sqft_basement": 0,
"sqft_lot15": 5650,
"bathrooms": 1,
"bedrooms": 3,
"zipcode": 98178,
"sqft_living": 2000,
"condition": 3,
"yr_built": 1955,
"grade": 7,
"waterfront": 0,
"location": "47.5112,-122.257"
]
上面命令的输出为:
"docs" : [
"doc" :
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" :
"date" : "20141013T000000",
"yr_renovated" : 0,
"long" : -122.257,
"view" : 0,
"floors" : 1,
"sqft_above" : 1180,
"sqft_living15" : 1340,
"id" : 7129300520,
"sqft_lot" : 5650,
"lat" : 47.5112,
"ml" :
"inference" :
"price_prediction" :
"price_prediction" : 320045.53082421474,
"feature_importance" : [
"feature_name" : "grade",
"importance" : -71221.99550030447
,
"feature_name" : "zipcode",
"importance" : -60646.70704720452
,
"feature_name" : "sqft_living15",
"importance" : -31176.143612357395
,
"feature_name" : "bathrooms",
"importance" : -15116.952345425949
],
"model_id" : "webinar-demo-regression-1642141570214"
,
"sqft_basement" : 0,
"sqft_lot15" : 5650,
"bathrooms" : 1,
"bedrooms" : 3,
"zipcode" : 98178,
"sqft_living" : 2000,
"condition" : 3,
"yr_built" : 1955,
"grade" : 7,
"waterfront" : 0,
"location" : "47.5112,-122.257"
,
"_ingest" :
"timestamp" : "2022-01-17T09:20:33.93337Z"
]
我们可以看到,当我们的 sqft_living 从 1180 提高到 2000 时,估价从之前的 239677.90135690733 变为 320045.53082421474,而影响这个价格最重要的因素是 grade 而不再是之前的 sqft_living。也许 sqft_living 提高到一定的值, grade 才变得更加重要。
总结
我们使用了一个美国的真实的房屋销售价格表。经过 Elasticsearch 的机器学习处理,我们运用 data frame 分析来进行有监督的机器学习从而使我们可以针对销售房屋的价格进行预测。在实际的使用中,我们可以创建实时的数据处理。我们可以让 transforms 实时运行,并让 data frame 分析任务不间断地运行以更新模型。更多展示,请参阅我的其它文章
以上是关于Elasticsearch:Supervised Machine Learning - 有监督的机器学习的主要内容,如果未能解决你的问题,请参考以下文章