揭晓阿里云神龙团队拿下TPCx-BB排名第一的背后技术
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了揭晓阿里云神龙团队拿下TPCx-BB排名第一的背后技术相关的知识,希望对你有一定的参考价值。
简介:近日,TPC Benchmark Express-BigBench(简称TPCx-BB)公布了最新的世界排名,阿里云自主研发的神龙大数据加速引擎获得了TPCx-BB SF3000排名第一的成绩。TPCx-BB测试分为性能与性价比两个维度。其中,在性能维度,在本次排名中,阿里云领先第二名高达41.6%,达到了2187.42 BBQpm,性价比领先第二名40%,降低到346.53 USD/BBQpm。

作者 | 神龙加速计算团队
来源 | 阿里技术公众号
一 背景介绍
近日,TPC Benchmark Express-BigBench(简称TPCx-BB)公布了最新的世界排名,阿里云自主研发的神龙大数据加速引擎获得了TPCx-BB SF3000排名第一的成绩。
TPCx-BB测试分为性能与性价比两个维度。其中,在性能维度,在本次排名中,阿里云领先第二名高达41.6%,达到了2187.42 BBQpm,性价比领先第二名40%,降低到346.53 USD/BBQpm。

(TPCx-BB SF3000性能维度排行)
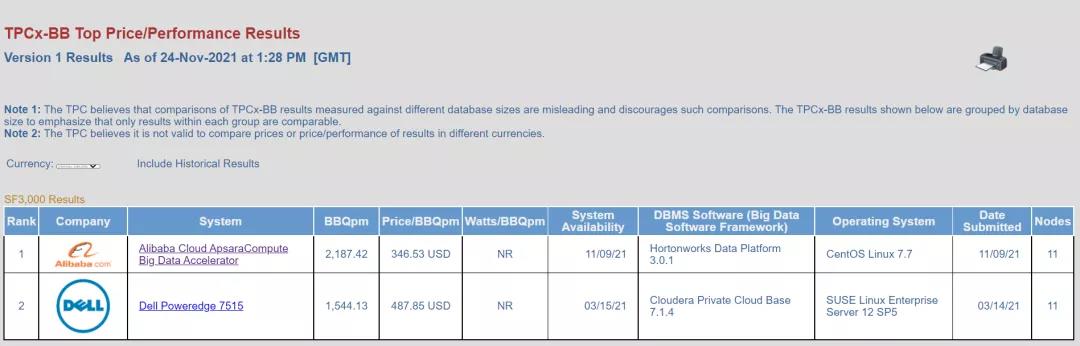
(TPCx-BB SF3000性价比维度排行)
借这个机会跟大家分享一下这个第一背后的技术历程。
二 神龙大数据加速引擎MRACC概述
阿里云自研的神龙大数据加速引擎MRACC(Apasara Compute MapReduce Accelerator)是这次取得优异成绩的杀手锏。
在数据处理需求激增的今天,许多企业会使用开源Spark、Hadoop组件或HDP、CDH等常用套件,自建开源大数据集群,处理数据量从TB到PB级,集群规模从几台到几千台。MRACC神龙大数据加速引擎,针对客户自建场景,依托神龙底座,提供常用组件加速能力,如Spark、Hadoop、Alluxio等。
结合阿里云神龙架构的特性,MRACC进行了软硬一体化优化,形成独一无二的性能优势,最终,使复杂SQL查询场景性能相比社区版Spark提升2-3倍,使用eRDMA加速Spark性能提升30%。在神龙大数据加速引擎的加持下,企业使用阿里云ECS云服务器运行大数据集群,将获得更高的性能和性价比。

图1 MRACC神龙大数据加速引擎架构
三 MRACC-Spark介绍
Spark自从2010年面世,到2020年已经经过十年的发展,现在已经发展为大数据批计算的首选引擎。针对大数据最常用的Spark引擎,MRACC进行了重点优化。具体来说,针对大数据任务重IO特性,MRACC在网络和存储方面结合云上的架构优势进行软硬件加速,包括软件的SQL引擎优化,使用缓存、文件裁剪、索引等优化手段,并尝试将压缩等运算卸载到异构器件;还使用eRDMA进行网络加速,将shuffle阶段的数据交换运行在eRDMA网络,使得延时降低、CPU利用率大幅提升。

图2 MRACC-Spark架构
四 Spark SQL引擎优化
从Spark2以后,Spark SQL, DataFrames and Datasets接口逐渐取代基础RDD API成为Spark的主流编程模型。社区对Spark SQL进行了大量投入,据统计Spark3.0版本发布将其中接近一半的优化都集中在Spark SQL上。使用 SparkSQL 替代 Hive 执行离线任务已成为不少企业的主流选择。
针对SQL引擎的anlyzer、optimizer、planner、Query execution几个阶段,我们都做了一些优化。Spark3.0对SQL引擎进行了大刀阔斧的改造和优化,其中AQE和DP机制广受关注。但目前开源Spark的AE机制目前仅支持分区裁剪,对于非分区键和subquery裁剪不支持,我们针对这块做了优化,支持subquery的动态数据裁剪,能大幅减少参与计算的数据量。
在物理计划执行阶段,我们支持了window topn排序,使得包含limit的sql语句性能大幅提升,并支持了parquet rowgroup裁剪、bloom filter join等高级特性。SPAKR SQL的CBO机制能较好的提高SQL执行效率,但是在cbo阶段,join table过多会导致的cbo搜索开销暴增,我们支持了遗传算法搜索,解决了 join table过多导致的开销暴增的情况。
此外,还支持了去重下推、join外键消除、完整性约束等功能,并结合deltalake支持了数据的增删改操作。
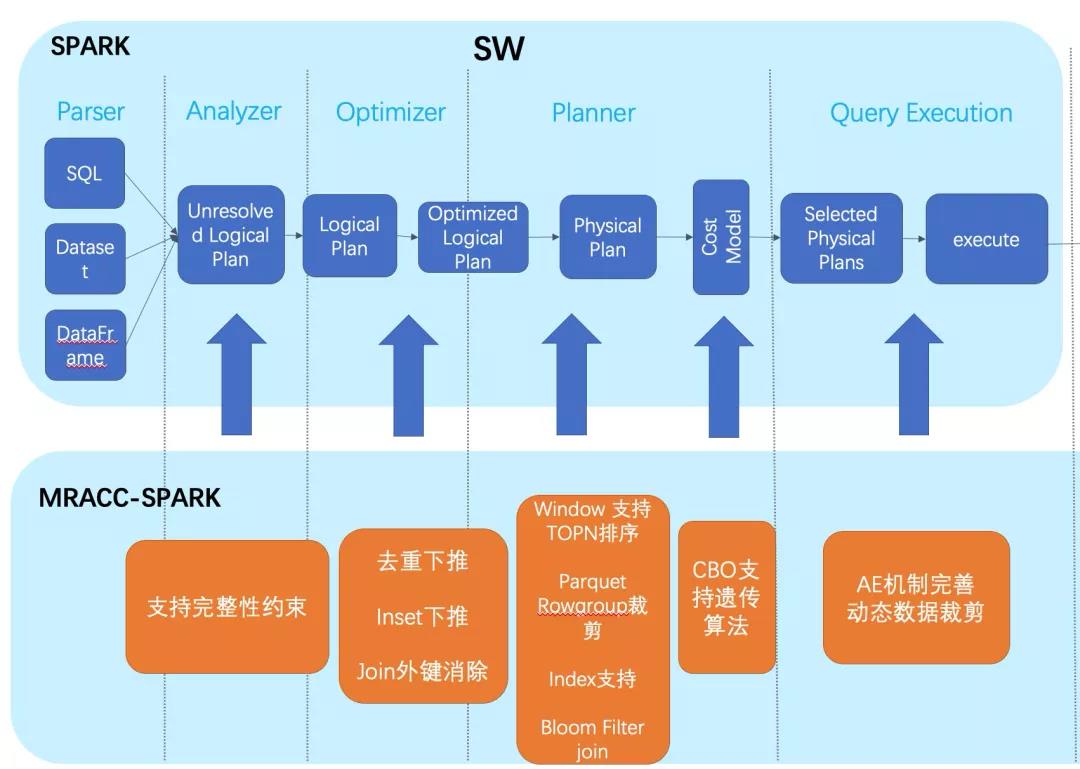
图3 MRACC-Spark的SQL引擎优化
五 近网络RDMA优化
2021年杭州云栖大会上,阿里云发布第四代神龙架构,提供业界首个大规模弹性RDMA加速能力。RDMA是一种高性能网络传输技术,提供直接内存访问的方式,数据传输bypass Kernel,从而能减少CPU的开销,提供低时延的高性能网络。在分布式计算中,shuffle过程必不可少,且消耗较多的计算和网络资源,是大数据分布式计算的优化重点。针对Spark 内存计算在shuffle阶段数据交换特点,可将shuffle数据交换变为memory-network-memory的模式,充分利用RDMA用户态内存直接交互、低延时、低cpu消耗的特点,最终在tpcxhs等端到端benchmark上获得了30%的性能提升。
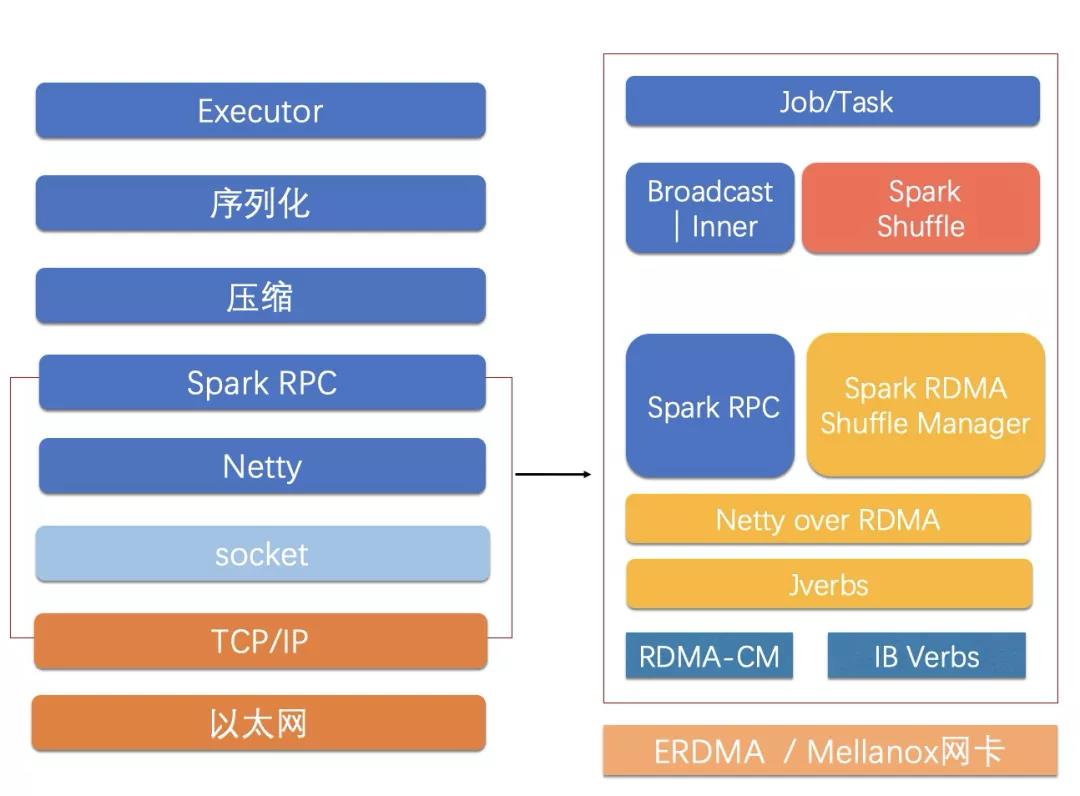
图4 MRACC-Spark的eRDMA近网络优化插件
六 性能优化结果
最终,在TPCDS 10T数据集上,相比最新的Spark3.1版本性能提升2.19倍。在TPCx-BB上相比第二名领先高达41.6%。


图5 TPCDS及TPCx-BB的数据效果
七 展望
目前,所有这些优化,我们都封装成插件形式交付给客户,客户代码基本上不需要修改,方便客户直接使用。
未来我们将持续将我们软硬件一体化极致性能优化能力服务阿里云的大数据客户,此外我们将在软硬件一体化性能优化能力上持续迭代,构建性能更高、成本更低的MRACC神龙大数据加速服务能力提供给广大用户。
附:TPCx-BB介绍
TPCx-BB是由国际标准化测试权威组织(TPC)发布的基于零售业场景构建的端到端大数据测试基准,支持主流分布式大数据处理引擎,模拟了整个线上与线下业务流程,有30个查询语句,涉及到描述性过程型查询、数据挖掘以及机器学习的算法。TPCx-BB的测试具有数据量大、特征复杂、来源复杂等特点,与真实业务场景较为接近,对各行业的基础设施选型有着重要参考意义。
TPCx-BB的测试结果,可以全面准确的反映端到端的大数据系统的整体运行性能。测试涵盖了结构化、半结构化和非结构化数据,能够从客户实际场景角度更全面的评估大数据系统软硬件性能、性价比、服务和功耗等各个方面。
本文为阿里云原创内容,未经允许不得转载。
以上是关于揭晓阿里云神龙团队拿下TPCx-BB排名第一的背后技术的主要内容,如果未能解决你的问题,请参考以下文章
性能提升40%,阿里云神龙大数据加速引擎获TPCx-BB世界排名第一
性能提升40%,阿里云神龙大数据加速引擎获TPCx-BB世界排名第一