hadoop集群slave节点jps后没有datanode解决方案
Posted 1dress
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop集群slave节点jps后没有datanode解决方案相关的知识,希望对你有一定的参考价值。
hadoop集群slave节点jps后没有datanode

这个问题是重复格式化造成的,重复格式化namenode造成datanode中的VERSION文件中clusterID与主节点的不一致。
1.关闭集群
stop-all.sh
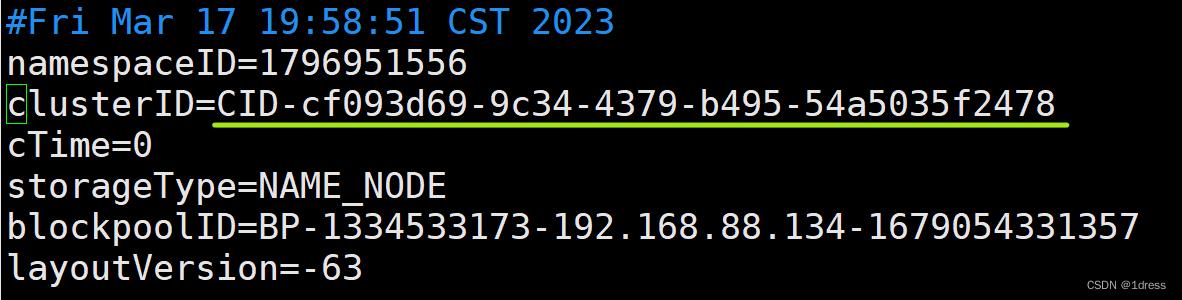
2.找到安装hadoop的文件夹,我的是(/usr/local/hadoop)再找到里面的tmp/dfs/name/current,打开VERSION查看并复制clusterID的内容。
操作:在master里输入命令
cd /usr/local/hadoop/tmp/dfs/name/current
vim VERSION
:q
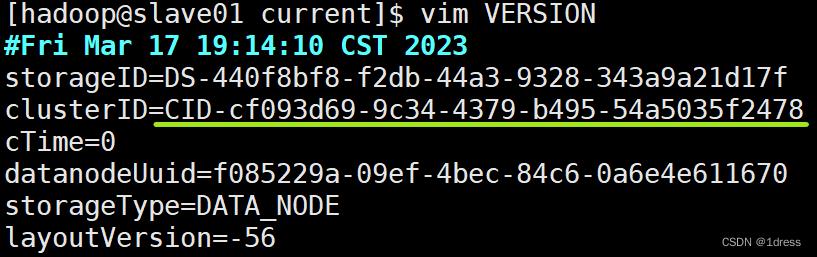
3.切换到slave节点,将/usr/local/hadoop/tmp/dfs/data/current里的VERSION文件中的clusterID替换成与master的VERSION文件中clusterID一致。
操作:在slave里输入命令
cd /usr/local/hadoop/tmp/dfs/data/current
vim VERSION
替换一致后:
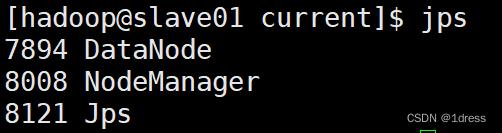
4.重启集群:
start-all.sh
以上是关于hadoop集群slave节点jps后没有datanode解决方案的主要内容,如果未能解决你的问题,请参考以下文章
Kafka:ZK+Kafka+Spark Streaming集群环境搭建针对hadoop2.9.0启动DataManager失败问题