NumPy入门
Posted 辰chen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NumPy入门相关的知识,希望对你有一定的参考价值。
目录
- 前言
- 1. 开发环境安装与配置
- 2.NumPy数组引出
- 3.NumPy数组创建
- 4.NumPy数组查看
- 5.NumPy数据保存
- 6.NumPy数据类型
- 7.NumPy数组运算
- 8.NumPy索引与切片
- 9.训练场
- 9.1 创建一个长度为10的一维全为0的ndarray对象,然后让第5个元素等于1
- 9.2 创建一个元素为从10到49的ndarray对象,间隔是1
- 9.3 将第2题的所有元素位置反转
- 9.4 使用np.random.random创建一个10*10的ndarray对象,并打印出最大最小元素
- 9.5 创建一个10*10的ndarray对象,且矩阵边界全为1,里面全为0
- 9.6 创建一个每一行都是从0到4的5*5矩阵
- 9.7 创建一个范围在(0,1)之间的长度为12的等差数列,创建[1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024]等比数列。
- 9.8 创建一个长度为10的正太分布数组np.random.randn并排序
- 9.9 创建一个长度为10的随机数组并将最大值替换为-100
- 9.10 如何根据第3列大小顺序来对一个5*5矩阵排序?
前言
本文其实属于:Python的进阶之道【AIoT阶段一】的一部分内容,本篇把这部分内容单独截取出来,方便大家的观看,本文介绍 NumPy入门,后续还会单独发一篇 NumPy高级内容供读者学习。
NumPy(Numerical Python)是Python的一种开源的数值计算扩展。提供多维数组对象,各种派生对象(如掩码数组和矩阵),这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix)),支持大量的维度数组与矩阵
运算,此外也针对数组运算提供大量的数学函数库,包括数学、逻辑、形状操作、排序、选择、输入输出、离散傅立叶变换、基本线性代数,基本统计运算和随机模拟等等。
几乎所有从事Python工作的数据分析师都利用NumPy的强大功能。
a.强大的N维数组
b.成熟的广播功能
c.用于整合C/C++和Fortran代码的工具包
d.NumPy提供了全面的数学功能、随机数生成器和线性代数功能
1. 开发环境安装与配置
🚩有两种不同的安装手段,本文主要介绍第二种方法,并提供两种下载渠道:
第一种方式:
在 cmd 中输入下面两行:
pip install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
第二种方式:
直接安装Anaconda下载:Anaconda Installers

读者根据自己不同的操作系统进行下载,博主为 Windows 系统,下面安装流程也是在 Windows 操作系统上进行,不过区别不大。
也可以直接在百度网盘下载:Anaconda Installers,提取码:3h2u


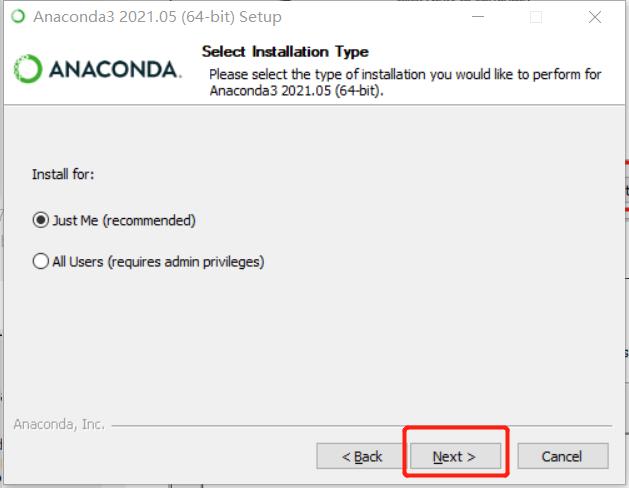

❗️ 注意:Add Path!!! 添加一下环境变量~
进入等待:

安装完成~


这时会弹出两个网站:

不用管,直接关闭即可。
我们进入 cmd,输入:
jupyter notebook

紧接着会进入一个网站:
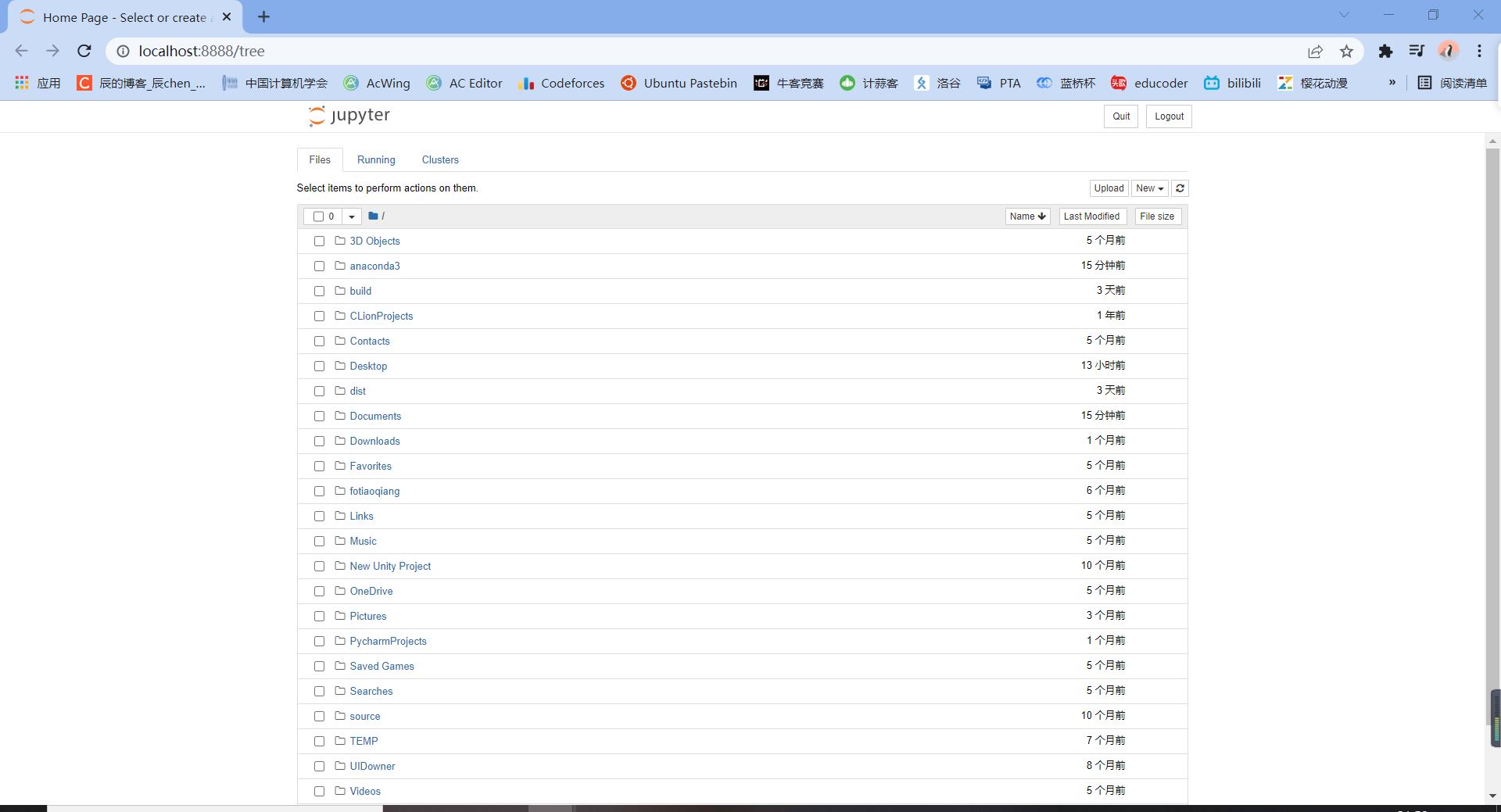
至此,我们的 Anaconda 安装成功,Congratulation~🎈
我们在这里新建一个文件夹:

此时的文件是未命名的,我们来给它起个名字:


我们在 AIoT 中创建一个 Python3:
 我们还是一样给它改个名:
我们还是一样给它改个名:
至此,我们成功创建了 Python3 文件,Congratulation~🎈
2.NumPy数组引出
🚩下面我们就开始写代码:

写完一行之后我们点击运行,同样用快捷键:Shift + Enter 也可以运行:
如下可以查看所有的快捷键:


我们的代码是可以反复运行的:比如我们再运行一下第一行代码,就会发现,从 In [1] 变成了 In[2]:




现在我们让它变成蓝色:
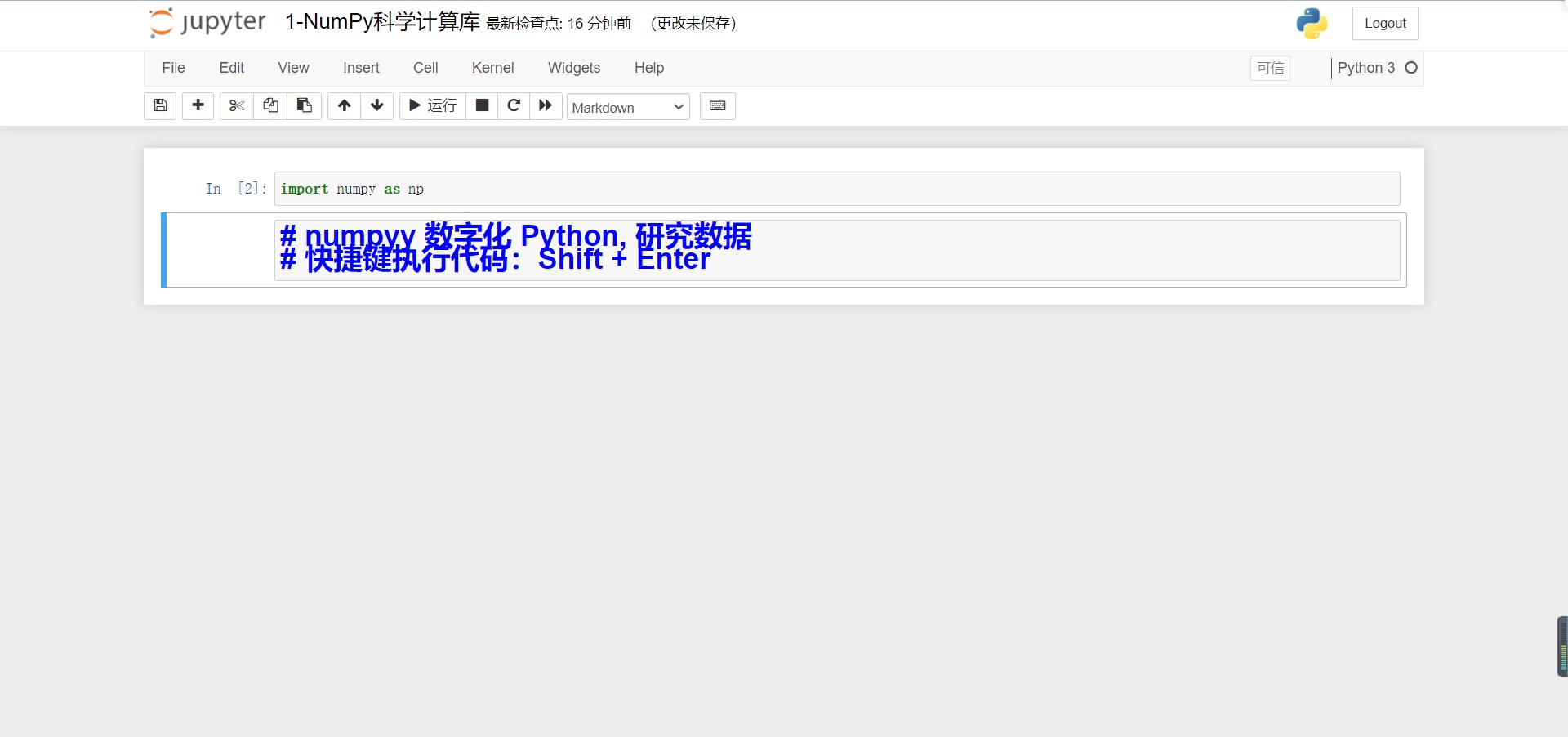
很丑,对吧,因为在 Python 语法中,# 代表的是注释,而在 Markdown 中,# 代表的是一级标题。
故我们可以去掉 #

按下快捷键:B,继续写代码

没有行号看起来是不是有些别扭?我们点击 view -> line numbers:


我们编写一个代码,输出一个列表,我们点击运行:

当然我们的切片操作也是一样的:

我们的主角登场了!numpy数组


numpy数组支持更简单的操作:
比如我们的列表,下述操作会报错:

但是我们的numpy数组就支持上述操作:

当然,还有一些很“离谱”的操作:


显然,我们的列表是没有这种“骚操作”的:

3.NumPy数组创建
🚩我们在 1.2 NumPy数组引出 其实已经简单给大家介绍了如何创建一个数组:使用 array 函数.
但其实,创建数组的方式不仅如此,NumPy 中有很多的方式去创建(初始化)一个数组:




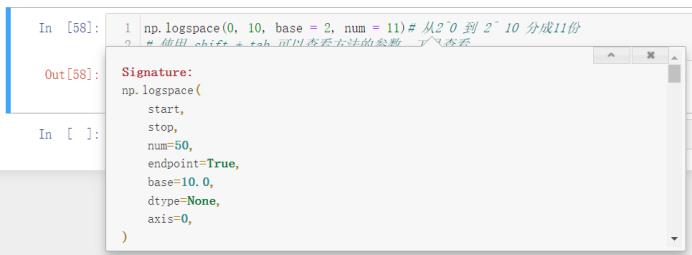
我们发现这个 logspace 的运行结果我们看不懂,这是因为它是用科学计数法表达的,我们可以使用 np.set_printoptions(suppress = True) 来让运行结果变成我们能看懂的数字:



上述代码:
np.ones(shape = 10) # 10个1
np.zeros(shape = 5) # 5个0
np.full(shape = 6, fill_value = 666) # 6个666
np.random.randint(0, 100, size = 10) # 在0 ~ 100 中随机生成10个数
np.random.randn(10) # 生成10个正态分布,平均值是0,标准差是1
np.linspace(1, 100, 100) # 把1 ~ 100等分成100份(等差数列)
np.linspace(1, 99, 50)
np.set_printoptions(suppress = True)
np.logspace(0, 10, base = 2, num = 11)# 从2^0 到 2^ 10 分成11份
# 使用 shift + tab 可以查看方法的参数,工具查看
# 二维数组:3行5列
np.random.randint(0, 10, size = (3, 5))
# 三维数组:
np.random.randint(0, 10, size = (2, 3, 5))
4.NumPy数组查看
🚩jupyter扩展插件(也可以不安装)
在我们的 cmd 中输入以下指令:
pip install jupyter_contrib_nbextensions -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install jupyter_nbextensions_configurator -i https://pypi.tuna.tsinghua.edu.cn/simple
jupyter contrib nbextension install --user
jupyter nbextensions_configurator enable --user
安装好后退出,重新进入jupyter notebook:


勾选如下:
安装好之后,再次进入我们的代码,会发现多了一个这个东西:
点击即可出现一个索引目录:


4.1 数组的维度

import numpy as np
arr = np.random.random(size = (3, 5))
arr.ndim # 维度
4.2 数组的形状
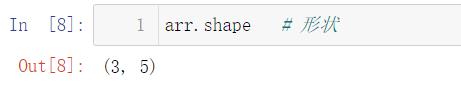
import numpy as np
arr = np.random.random(size = (3, 5))
arr.shape # 形状
4.3 数组元素的总数

import numpy as np
arr = np.random.random(size = (3, 5))
arr.size # 数组元素的总数
4.4 数据类型

import numpy as np
arr = np.random.random(size = (3, 5))
arr.dtype # 数据类型 float64 (64位)
4.5 数组中每个元素的大小(以字节为单位)

import numpy as np
arr = np.random.random(size = (3, 5))
# 0, 1 -----> 位
# 8个位 -----> 字节
# 64 / 8 = 8
arr.itemsize # 每个元素的大小,对应8个字节
5.NumPy数据保存
🚩我们可以使用 save 方法去保存我们的数组:

import numpy as np
arr = np.arange(0, 10, 3) # NumPy 的方法,功能类似
# 当前目录
np.save('./data1', arr) # 保存
运行后我们返回到创建好的目录下:

可以发现多了一个 data1.npy 这里面就是我们刚刚保存的数组信息。
注意,如果你点开新建立的这个文件的话,会发现:
里面并没有我们想看到的存储信息,这是因为文件保存的内容是二进制的,只能使用代码去打开,下面我们介绍从文件中读取我们的数据的方法:
我们按照下述代码可以取出数据:

import numpy as np
arr = np.arange(0, 10, 3) # NumPy 的方法,功能类似
np.load('./data1.npy') # 取出数据
如果我们要把多个数组存入一个文件,可以使用 savez 方法:
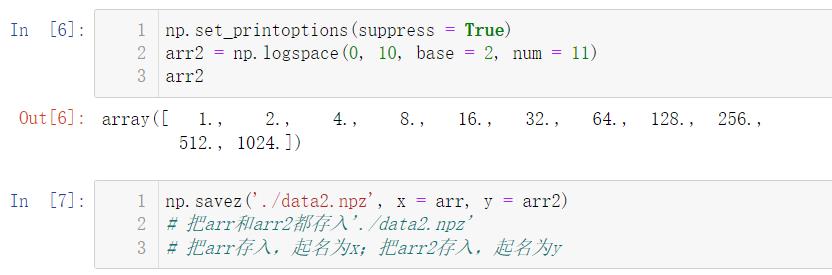
import numpy as np
arr = np.arange(0, 10, 3) # NumPy 的方法,功能类似
np.set_printoptions(suppress = True)
arr2 = np.logspace(0, 10, base = 2, num = 11)
np.savez('./data2.npz', x = arr, y = arr2)
# 把arr和arr2都存入'./data2.npz'
# 把arr存入,起名为x;把arr2存入,起名为y
运行后,可以看到多了一个 data2.npz 文件,这里面就是我们刚刚保存的数组信息。
我们在取值的时候可以一个一个取:

import numpy as np
arr = np.arange(0, 10, 3) # NumPy 的方法,功能类似
np.set_printoptions(suppress = True)
arr2 = np.logspace(0, 10, base = 2, num = 11)
np.load('./data2.npz')['x'] # 取出 x ---> 取出 arr
np.load('./data2.npz')['y'] # 取出 y ---> 取出 arr2
注意我们存的时候用什么名,取的时候就用什么名,比如:

显然在这个时候取出 y 的话就是错误的。
读写csv、txt文件:


import numpy as np
arr = np.random.randint(0, 10, size = (3, 4))
# 储存数组到csv文件
np.savetxt("./arr.csv", arr, delimiter = ',') # 存储到txt文件也一样
# 读取文件
np.loadtxt('./arr.csv', delimiter = ',', dtype = np.int32)
6.NumPy数据类型
🚩我们的数据类型包涵三大类:
整数
浮点数
字符串
ndarray的数据类型:
-
int(整数):
int8、uint8、int16、int32、int64 -
float(浮点数):
float16、float32、float64 -
str(字符串)
float16 float32,int16 int 32有什么不同:数字越大,证明其在内存中所占内存越大,当然相应的,可以表示的数的范围也就越大:如 int8 的范围大小为 28,但是因为它既包含正数也包含负数,故它其实可以表达的范围就是 [-128, 127] ,unit8 的范围也是 28,不同的是它不包含负数即只包含0和正数,故 unit8 的取值范围就是 [0, 255],使用 astype() 方法可以转换数据类型:
我们在创建类型的时候,可以用dtype指明它的数据类型

当然,我们还可以给它为 int32:

我们输入如下代码,编译运行:

然后返回到我们的文件夹查看我们刚刚保存的两个文件:

很直观的可以注意到,两个文件的大小相差大致为8倍,这个的原因其实就是 64 / 8 = 8
使用 astype() 方法可以转换数据类型:

这里我们需要注意,转换之后,原数组的数据类型是不变的,使用astype()进行转换可以说是创建了一个新的数组:

7.NumPy数组运算
🚩数组运算包含一个数组元素内的运算以及两个或多个数组之间的运算:
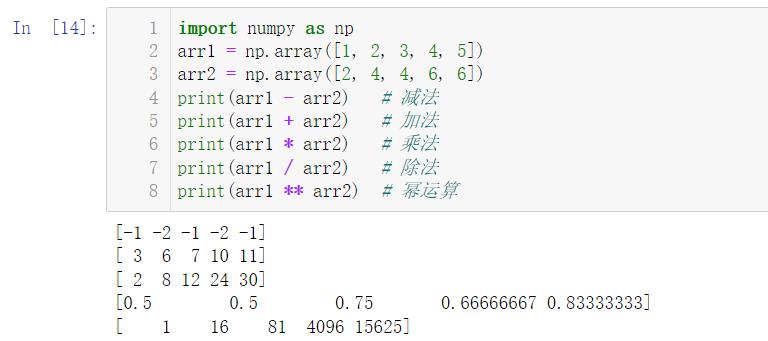
7.1 加减乘除幂运算

我们在算次方的时候也可以调用 power() 函数

当然还有还支持 / 和 % 运算

两个数组的运算,其实就是对应位置的运算:
import numpy as np
arr1 = np.array([1, 2, 3, 4, 5])
arr2 = np.array([2, 4, 4, 6, 6])
print(arr1 - arr2) # 减法
print(arr1 + arr2) # 加法
print(arr1 * arr2) # 乘法
print(arr1 / arr2) # 除法
print(arr1 ** arr2) # 幂运算
7.2 逻辑运算
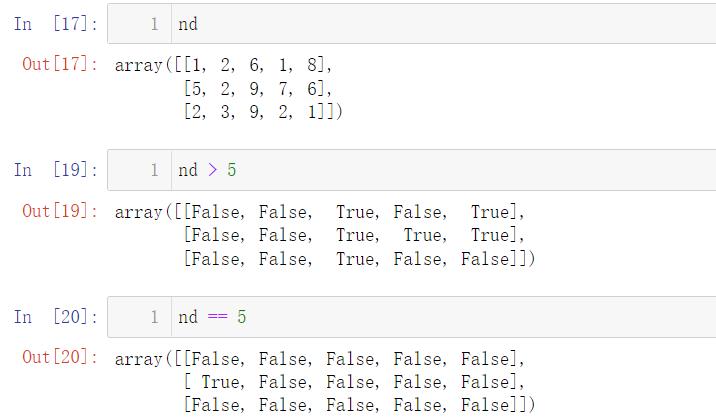
当然,两个数组之间也有逻辑运算:

7.3 += -= *= 操作
❗️ 注意:上述的操作并没有改变数组的原值,可以理解为重新创建了一个新的数组,但是下面的操作,是直接在数组的基础上进行修改,会改变数组的元素的值

注意,这里不包含 /= 运算,会报错,在这里为 //=:

8.NumPy索引与切片
🚩索引和切片操作其实我们在列表中是经常使用的,这里不再进行过多的赘述,讲解在 NumPy 中实现索引查找和切片操作
8.1 一维数组索引和切片



8.2 二维数组索引和切片

如果我们想取出多行多列的数据又该怎么操作呢?

很明显能看出,输出的结果并不是我们想要输出的,这是因为,如果我们要取出多行多列,需要索引和切片相配合使用:

你可能有点懵逼,没事儿,咋们多举几个例子:

咋们回头看看刚刚的错误操作取出来的到底是什么:
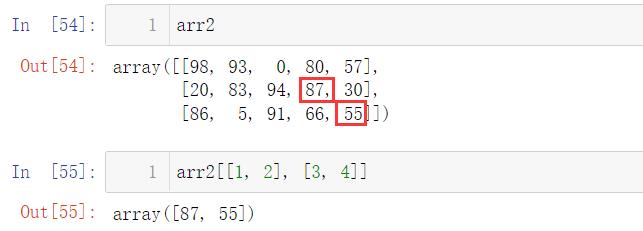
不难看出咋们取的是 (1, 3) 和 (2, 4) 位置的值
❗️ 接下来就开始骚操作:如果行和列不是连续的行和列该怎么取呢?比如我想取第一行,第三行以及第二列,第四列的数:
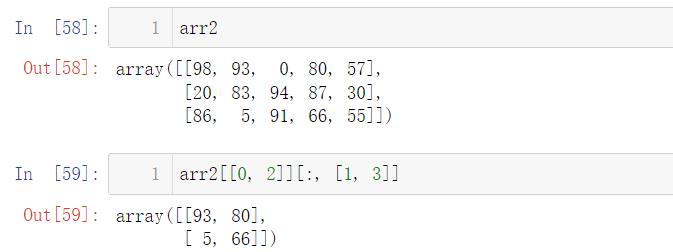
接下来介绍另一种方法,也可以实现:

我们也可以更改数组中的值,我们只需要找到相应的索引即可:
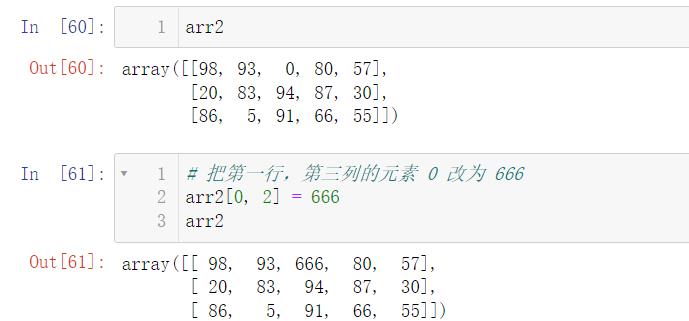
当然,我们可以一次性更改多个值:
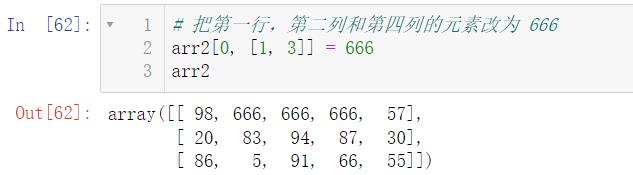
8.3 花式索引
所谓花式索引,其实就是一次性取出多个值


9.训练场
🚩训练场中包含十道例题以及答案代码,读者需要自己敲写一遍,已增强学习记忆。
在这里,给大家介绍一个函数:display() 它的作用类似于 print() 函数,不过它相较于 print 而言更加的美观:

9.1 创建一个长度为10的一维全为0的ndarray对象,然后让第5个元素等于1
# 创建一个长度为10的一维全为0的ndarray对象,然后让第5个元素等于1
import numpy as np
arr = np.zeros(10, dtype = 'int')
# 第5个
arr[4] = 1
arr
9.2 创建一个元素为从10到49的ndarray对象,间隔是1
# 创建一个元素为从10到49(包含49)的ndarray对象,间隔是1
import numpy as np
# 注意是包含 49 的,故我们在给函数串参数的时候需要传到 50
arr = np.arange(10, 50)
arr
9.3 将第2题的所有元素位置反转
# 将第2题的所有元素位置反转
import numpy as np
# 注意是包含 49 的,故我们在给函数串参数的时候需要传到 50
arr = np.arange(10, 50)
arr
# 使用反向切片操作可以使元素实现翻转
arr = arr[::-1]
arr
9.4 使用np.random.random创建一个10*10的ndarray对象,并打印出最大最小元素
# 使用np.random.random创建一个10*10的ndarray对象,并打印出最大最小元素
import numpy as np
arr = np.random.random(size = (10, 10))
# 使用 max 和 min 分别计算最大和最小元素
print('最大值为:', arr.max())
print('最小值为:', arr.min())
9.5 创建一个10*10的ndarray对象,且矩阵边界全为1,里面全为0
# 创建一个10*10的ndarray对象,且矩阵边界全为1,里面全为0
import numpy as np
arr = np.full(shape = (10, 10), fill_value = 0, dtype = np.int8)
# 第一行和最后一行赋值为 1
arr[[0, -1]] = 1
# 第一列和最后一列赋值为 1
arr[:, [0, -1]] = 1
arr
9.6 创建一个每一行都是从0到4的5*5矩阵
# 创建一个每一行都是从0到4的5*5矩阵
import numpy as np
# 先创建一个元素全为 0 的矩阵
arr = np.zeros((5, 5), dtype = int)
# 依次加值
arr += np.arange(5)
arr
9.7 创建一个范围在(0,1)之间的长度为12的等差数列,创建[1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024]等比数列。
# 创建一个范围在(0,1)之间的长度为12的等差数列
# 创建[1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024]等比数列
import numpy as np
# 等差数列
arr = np.linspace(0,1,12)
display(arr)
# 等比数列
arr2 = np.logspace(0, 10, base = 2, num = 11, dtype = int)
arr2
9.8 创建一个长度为10的正太分布数组np.random.randn并排序
# 创建一个长度为10的正太分布数组np.random.以上是关于NumPy入门的主要内容,如果未能解决你的问题,请参考以下文章