python笔记:fancyimpute
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python笔记:fancyimpute相关的知识,希望对你有一定的参考价值。
0 包介绍
各种矩阵补全和插补
注:
- 这个包的作者不打算添加更多的插补算法或特征
- IterativeImputer 最初是一个 fancyimpute 包的原创模块,但后来被合并到 scikit-learn 中,。 为方便起见,您仍然可以 from fancyimpute import IterativeImputer,但实际上它只是从 sklearn.impute import IterativeImputer 做的。
1 涉及的算法
| SimpleFill | 用每列的平均值或中值替换缺失的条目。 |
| KNN | 最近邻插补,它使用两行都具有观察数据的特征的均方差对样本进行加权。 |
| SoftImpute | 通过 SVD 分解的迭代软阈值完成矩阵 |
| IterativeImputer | 通过以循环方式将具有缺失值的每个特征建模为其他特征的函数,来估算缺失值 |
| IterativeSVD | 通过迭代低秩 SVD 分解完成矩阵 |
| MatrixFactorization | 将不完整矩阵直接分解为低秩 U 和 V,具有每行和每列偏差以及全局偏差。 |
| BiScaler | 行/列均值和标准差的迭代估计以获得双重归一化矩阵。 不保证收敛,但在实践中效果很好。 |
2 每个的使用方法
2.1 SimpleFill
需要补全的矩阵(实际应用中比这个会大很多)
tmp=np.array([[1,2,3,4],
[np.nan,3,2,np.nan],
[5,7,np.nan,np.nan]])
tmp
'''
array([[ 1., 2., 3., 4.],
[nan, 3., 2., nan],
[ 5., 7., nan, nan]])
'''声明的时候有一个参数可以设置
| fill_method |
|
from fancyimpute import SimpleFill
x=SimpleFill(fill_method='mean').fit_transform(tmp)
x
'''
array([[1. , 2. , 3. , 4. ],
[3. , 3. , 2. , 4. ],
[5. , 7. , 2.5, 4. ]])
'''2.2 KNN
2.2.1 声明参数
| k | 用于插补的相邻行数。 |
| orientation | 输入矩阵的哪个轴应该被视为样本(默认是row,可以设置为column) |
| use_argpartition | True或者False,默认为False 如果少于 k 个邻居可用于缺失值,则可能给出 NaN。 |
| print_interval | 每补全几行打印一次信息,默认是100 |
| min_value | 补全的数值的下限(小于之的会被设置为这个值) |
| max_value | 补全的数值的上限(大于之的会被设置为这个值) |
2.2.2 具体使用
需要补全的矩阵
array([[ 1., 2., 3., 4.],
[nan, 3., 2., nan],
[ 5., 7., nan, nan],
[ 7., nan, 11., 14.],
[76., 37., 27., nan],
[56., 77., nan, nan],
[ 1., 28., 33., 41.],
[nan, 31., 21., nan],
[ 5., 7., nan, nan]])from fancyimpute import KNN
x=KNN(k=2,print_interval=3).fit_transform(tmp)
x
'''
Imputing row 1/9 with 0 missing, elapsed time: 0.000
Imputing row 4/9 with 1 missing, elapsed time: 0.000
Imputing row 7/9 with 0 missing, elapsed time: 0.000
array([[ 1. , 2. , 3. , 4. ],
[ 1.23529412, 3. , 2. , 4.12195125],
[ 5. , 7. , 9.2 , 12.36734637],
[ 7. , 7. , 11. , 14. ],
[76. , 37. , 27. , 24.86588619],
[56. , 77. , 25.07445545, 26.67637945],
[ 1. , 28. , 33. , 41. ],
[51.99999875, 31. , 21. , 29.29744947],
[ 5. , 7. , 9.2 , 12.36734637]])
'''from fancyimpute import KNN
x=KNN(k=2,print_interval=6,max_value=2).fit_transform(tmp)
x
'''
Imputing row 1/9 with 0 missing, elapsed time: 0.000
Imputing row 7/9 with 0 missing, elapsed time: 0.000
array([[ 1. , 2. , 3. , 4. ],
[ 1.23529412, 3. , 2. , 2. ],
[ 5. , 7. , 2. , 2. ],
[ 7. , 2. , 11. , 14. ],
[76. , 37. , 27. , 2. ],
[56. , 77. , 2. , 2. ],
[ 1. , 28. , 33. , 41. ],
[ 2. , 31. , 21. , 2. ],
[ 5. , 7. , 2. , 2. ]])
'''2.3 SoftImpute
需要补全的矩阵
array([[ 1., 2., 3., 4.],
[nan, 3., 2., nan],
[ 5., 7., nan, nan],
[ 7., nan, 11., 14.],
[76., 37., 27., nan],
[56., 77., nan, nan],
[ 1., 28., 33., 41.],
[nan, 31., 21., nan],
[ 5., 7., nan, nan]])2.3.1 声明时的参数
| shrinkage_value | 默认无 我们在每次迭代中缩小奇异值的值。 如果省略,则默认值将是初始化矩阵的最大奇异值(缺失值用零补全)除以 50。 |
| convergence_threshold | 停止前迭代之间的最小定量差,默认为0.001 soft-impute 中的ε |
| max_iters | SVD迭代的最大次数,默认为100 (这个和上面一个同时限制的时候,谁先达到就结束迭代) |
| min_value | 补全的数值的下限(小于之的会被设置为这个值) |
| max_value | 补全的数值的上限(大于之的会被设置为这个值) |
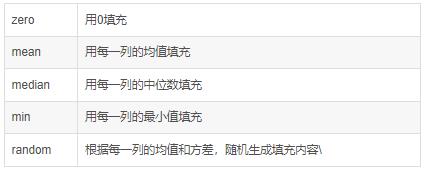
| init_fill_method | 如何初始化缺失值,和SimpleFill类似
|
| verbose | 默认True,是否打印信息 |
2.3.2 进行补全
from fancyimpute import SoftImpute
x=SoftImpute().fit_transform(tmp)
x
'''
[SoftImpute] Max Singular Value of X_init = 131.068550
[SoftImpute] Iter 1: observed MAE=0.688068 rank=4
[SoftImpute] Iter 2: observed MAE=0.688751 rank=4
[SoftImpute] Iter 3: observed MAE=0.689301 rank=4
[SoftImpute] Iter 4: observed MAE=0.689713 rank=4
[SoftImpute] Iter 5: observed MAE=0.689983 rank=4
[SoftImpute] Iter 6: observed MAE=0.690109 rank=4
.....
[SoftImpute] Iter 98: observed MAE=0.668583 rank=3
[SoftImpute] Iter 99: observed MAE=0.668481 rank=3
[SoftImpute] Iter 100: observed MAE=0.668381 rank=3
[SoftImpute] Stopped after iteration 100 for lambda=2.621371
array([[ 1. , 2. , 3. , 4. ],
[ 1.99541572, 3. , 2. , 1.49377198],
[ 5. , 7. , 3.24041776, 1.71202629],
[ 7. , 9.85341851, 11. , 14. ],
[76. , 37. , 27. , 4.83992705],
[56. , 77. , 35.75297423, 18.6416866 ],
[ 1. , 28. , 33. , 41. ],
[20.74186052, 31. , 21. , 15.78120489],
[ 5. , 7. , 3.24041776, 1.71202629]])
'''2.4 IterativeSVD
需要补全的矩阵
array([[ 1., 2., 3., 4.],
[nan, 3., 2., nan],
[ 5., 7., nan, nan],
[ 7., nan, 11., 14.],
[76., 37., 27., nan],
[56., 77., nan, nan],
[ 1., 28., 33., 41.],
[nan, 31., 21., nan],
[ 5., 7., nan, nan]])2.4.1 声明时的参数
| rank | 截断SVD的时候,选择最大的几个奇异值 默认是10个 |
| convergence_threshold | 停止前迭代之间的最小定量差,默认为0.00001 |
| max_iters | SVD迭代的最大次数,默认为200 (这个和上面一个同时限制的时候,谁先达到就结束迭代) |
| min_value | 补全的数值的下限(小于之的会被设置为这个值) |
| max_value | 补全的数值的上限(大于之的会被设置为这个值) |
| init_fill_method | 如何初始化缺失值,和SimpleFill类似
|
| verbose | 默认True,是否打印信息 |
2.4.2 进行补全
from fancyimpute import IterativeSVD
x=IterativeSVD(rank=2).fit_transform(tmp)
x
'''
[IterativeSVD] Iter 1: observed MAE=9.314811
[IterativeSVD] Iter 2: observed MAE=3.898237
[IterativeSVD] Iter 3: observed MAE=3.044470
[IterativeSVD] Iter 4: observed MAE=2.463926
[IterativeSVD] Iter 5: observed MAE=2.080959
...
[IterativeSVD] Iter 80: observed MAE=0.653643
[IterativeSVD] Iter 81: observed MAE=0.650037
[IterativeSVD] Iter 82: observed MAE=0.646448
[IterativeSVD] Iter 83: observed MAE=0.642877
[IterativeSVD] Iter 84: observed MAE=0.639324
array([[ 1. , 2. , 3. , 4. ],
[ 4.36077941, 3. , 2. , -0.30385289],
[ 5. , 7. , 6.66333863, 5.15766473],
[ 7. , 12.71726727, 11. , 14. ],
[ 76. , 37. , 27. , -21.33610166],
[ 56. , 77. , 73.07388471, 55.70698081],
[ 1. , 28. , 33. , 41. ],
[ 44.14701235, 31. , 21. , -2.11268537],
[ 5. , 7. , 6.66333863, 5.15766473]])
'''2.5 MatrixFactorization
需要补全的矩阵
array([[ 1., 2., 3., 4.],
[nan, 3., 2., nan],
[ 5., 7., nan, nan],
[ 7., nan, 11., 14.],
[76., 37., 27., nan],
[56., 77., nan, nan],
[ 1., 28., 33., 41.],
[nan, 31., 21., nan],
[ 5., 7., nan, nan]])2.5.1 声明时需要的参数
| rank | 默认为40 U,V低秩矩阵的rank |
| learning_rate | 学习率 |
| max_iters | 最大迭代次数 |
| min_value | 补全的数值的下限(小于之的会被设置为这个值) |
| max_value | 补全的数值的上限(大于之的会被设置为这个值) |
2.5.2 进行补全
from fancyimpute import MatrixFactorization
x=MatrixFactorization(rank=2).fit_transform(tmp)
x
'''
[MatrixFactorization] Iter 10: observed MAE=2.560441 rank=2
[MatrixFactorization] Iter 20: observed MAE=1.120212 rank=2
[MatrixFactorization] Iter 30: observed MAE=0.924099 rank=2
[MatrixFactorization] Iter 40: observed MAE=0.735406 rank=2
[MatrixFactorization] Iter 50: observed MAE=0.624251 rank=2
array([[ 1. , 2. , 3. , 4. ],
[ 3.24821785, 3. , 2. , 4.244756 ],
[ 5. , 7. , 6.69442221, 9.34054331],
[ 7. , 11.5915197 , 11. , 14. ],
[76. , 37. , 27. , 12.29345116],
[56. , 77. , 70.03487199, 71.43511672],
[ 1. , 28. , 33. , 41. ],
[33.91093635, 31. , 21. , 21.18448482],
[ 5. , 7. , 6.67985782, 9.32187028]])
'''参考资料
以上是关于python笔记:fancyimpute的主要内容,如果未能解决你的问题,请参考以下文章