什么是 Proactor 模型?
Posted 张维鹏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是 Proactor 模型?相关的知识,希望对你有一定的参考价值。
一、Proactor出现的背景:
Reactor 是非阻塞同步网络模型,而 Proactor 是异步网络模型。
(1)对于阻塞IO,当用户程序执行 read,线程会被阻塞,一直等内核数据准备好,并把数据从内核缓冲区拷贝到应用程序的缓冲区中,当拷贝过程完成,read 才会返回。如下图:

阻塞等待的是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程
(2)对于非阻塞IO,非阻塞的read请求在数据未准备好的情况下立即返回,可以继续往下执行,此时应用程序不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲区,read 调用才可以获取到结果。过程如下图:
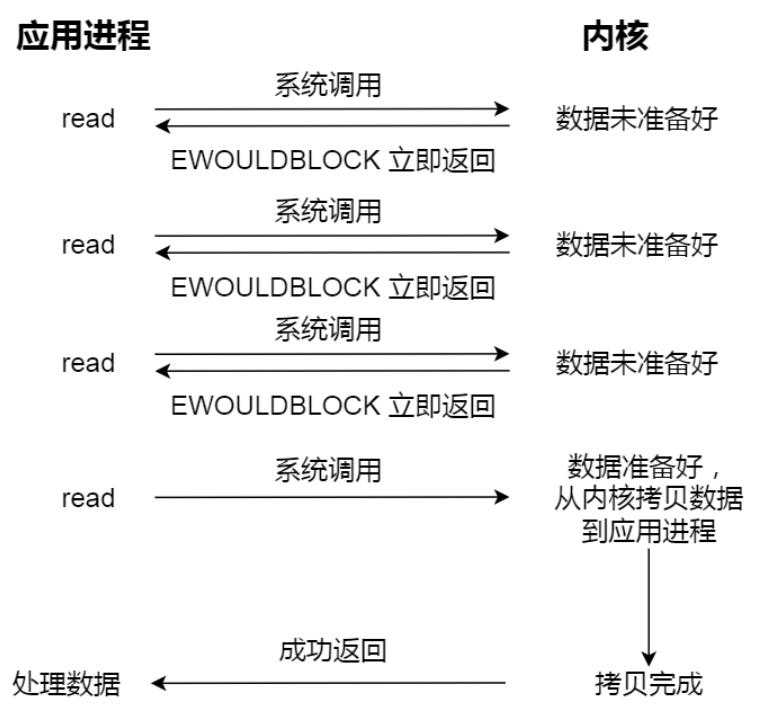
这里最后一次 read 调用,获取数据的过程,是一个同步的过程,是需要等待的过程。这里的同步指的是内核态的数据拷贝到用户程序的缓存区这个过程。
因此,无论 read 和 send 是阻塞 I/O,还是非阻塞 I/O 都是同步调用。因为在 read 调用时,内核将数据从内核空间拷贝到用户空间的过程都是需要等待的,也就是说这个过程是同步的,如果内核实现的拷贝效率不高,read 调用就会在这个同步过程中等待比较长的时间。
(3)对于异步IO,指的是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待。当我们发起 aio_read (异步 I/O) 之后,就立即返回,内核自动将数据从内核空间拷贝到用户空间,这个拷贝过程同样是异步的,内核自动完成的,和前面的同步操作不一样,应用程序并不需要主动发起拷贝动作。过程如下图:
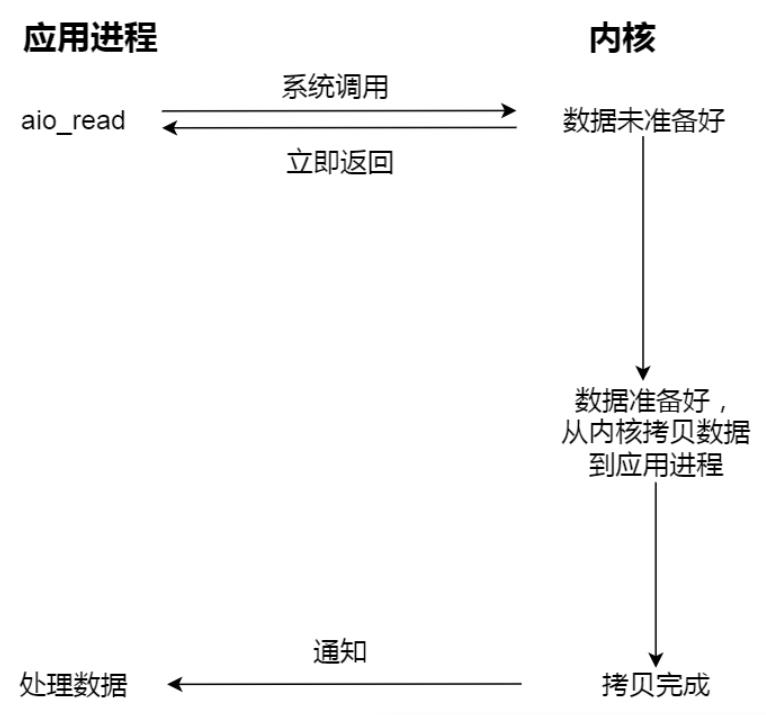
Proactor 正是使用了异步 I/O 技术,所以被称为异步网络模型。现在我们再来理解 Reactor 和 Proactor 的区别,就比较清晰了:
- Reactor 是同步非阻塞网络模型,感知的是就绪可读写事件。在每次感知到有事件发生(比如可读就绪事件)后,就需要应用进程主动调用 read 方法来完成数据的读取,也就是要应用进程主动将 socket 接收缓存中的数据读到应用进程内存中,这个过程是同步的,读取完数据后应用进程才能处理数据。
- Proactor 是异步网络模式, 感知的是已完成的读写事件。在发起异步读写请求时,需要传入数据缓冲区的地址(用来存放结果数据)等信息,这样系统内核才可以自动帮我们把数据的读写工作完成,这里的读写工作全程由操作系统来做,并不需要像 Reactor 那样还需要应用进程主动发起 read/write 来读写数据,操作系统完成读写工作后,就会通知应用进程直接处理数据。
因此,Reactor 可以理解为「来了事件操作系统通知应用进程,让应用进程来处理」,而 Proactor 可以理解为「来了事件操作系统来处理,处理完再通知应用进程」。这里的「事件」就是有新连接、有数据可读、有数据可写的这些 I/O 事件这里的「处理」包含从驱动读取到内核以及从内核读取到用户空间。
举个实际生活中的例子,Reactor 模式就是快递员在楼下,给你打电话告诉你快递到你家小区了,你需要自己下楼来拿快递。而在 Proactor 模式下,快递员直接将快递送到你家门口,然后通知你。
从上面介绍的内容我们不难看出 Proactor 产生的主要原因:Reactor 性能确实非常高,适合高并发场景,但它依然存在一个问题,那就是它是同步IO。同步IO需要线程自己等待内核准备好数据,在内核准备数据的过程中,当前线程是阻塞的,这样就会导致如果某个线程因为读取IO的时间过长(比如读取文件、写文件),则它势必会影响其他线程的执行。
二、Proactor 的执行流程:
无论是 Reactor,还是 Proactor,都是一种基于「事件分发」的网络编程模式,区别在于 Reactor 模式是基于「待完成」的 I/O 事件,而 Proactor 模式则是基于「已完成」的 I/O 事件。接下来,一起看看 Proactor 模式的示意图:
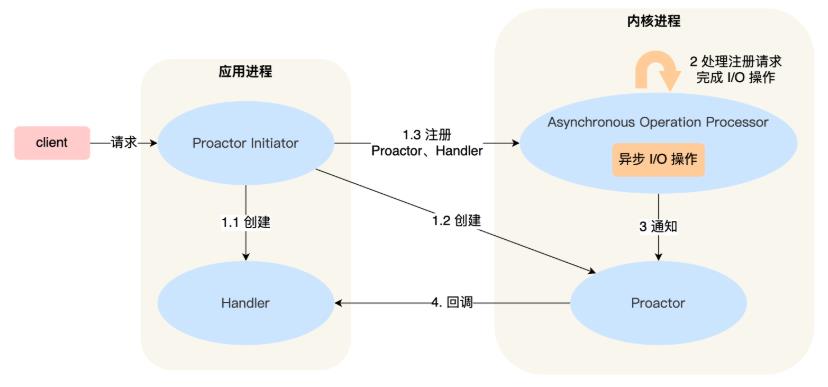
介绍一下 Proactor 模式的工作流程:
- Proactor Initiator 负责创建 Proactor 和 Handler 对象,并将 Proactor 和 Handler 都通过 Asynchronous Operation Processor 注册到内核;
- Asynchronous Operation Processor 负责处理注册请求,并处理 I/O 操作;
- Asynchronous Operation Processor 完成 I/O 操作后通知 Proactor;
- Proactor 根据不同的事件类型回调不同的 Handler 进行业务处理;
- Handler 完成业务处理;
需要注意的是:Proactor关注的不是就绪事件,而是完成事件,这是区分Reactor模式的关键点。
下面就简单介绍下 Proactor 模型处理读取操作的主要流程:
- (1)应用程序初始化一个异步读取操作,然后注册相应的事件处理器,此时事件处理器不关注读取就绪事件,而是关注读取完成事件,这是区别于Reactor的关键。
- (2)事件分离器等待读取操作完成事件
- (3)在事件分离器等待读取操作完成的时候,操作系统调用内核线程完成读取操作,并将读取的内容放入用户传递过来的缓存区中。这也是区别于Reactor的一点,Proactor中,应用程序需要传递缓存区。
- (4)事件分离器捕获到读取完成事件后,激活应用程序注册的事件处理器,事件处理器直接从缓存区读取数据,而不需要进行实际的读取操作。
异步IO都是操作系统负责将数据读写到应用传递进来的缓冲区供应用程序操作。
Proactor中写入操作和读取操作基本一致,只不过监听的事件是写入完成事件而已。
三、Proactor 的缺点:
Proactor 性能确实非常强大,效率也高,但是同样存在以下缺点:
(1)内存的使用:缓冲区在读或写操作的时间段内必须保持住,可能造成持续的不确定性,并且每个并发操作都要求有独立的缓存,相比Reactor模型,在Socket已经准备好读或写前,是不要求开辟缓存的;
(2)操作系统的支持:Windows 下通过一套完整的支持 socket 的异步编程接口,也就是通过 IOCP 实现了真正的异步,但 Linux 系统下的异步 IO 还不完善,aio 系列函数是由 POSIX 定义的异步操作接口,不是真正的操作系统级别支持的,而是在用户空间模拟出来的异步,并且仅仅支持基于本地文件的 aio 异步操作,网络编程中的 socket 是不支持的。因此,Linux 系统下高并发网络编程都是以 Reactor 模型为主
参考文章:
以上是关于什么是 Proactor 模型?的主要内容,如果未能解决你的问题,请参考以下文章