(翻译)A Deep Learning-Based Approach to Progressive Vehicle Re-identification for Urban Surveillance
Posted 爱做梦的鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(翻译)A Deep Learning-Based Approach to Progressive Vehicle Re-identification for Urban Surveillance相关的知识,希望对你有一定的参考价值。
废话(建议直接跳过):
我的毕设是做汽车重识别
今天我第一天认真开始写毕设论文(2021-05-23)
这几天写毕设论文(其实就是打开word,然后玩手机,嘿嘿),明天需要交初稿
给大家见识一下啥叫一个晚上,一个电脑,一个奇迹。
有人说我骚的不行,我只想说那确实。
甲:您是做什么工作?
乙:做机器学习。
甲:哦哦哦,机器学习好啊。诶,我有一个问题,关于机器学习的,想请教您。
乙:啊,您请讲。
甲:请问在做机器学习的时候,是你找数据库,还是机器找数据库?
乙:我找数据库。
甲:做机器学习的时候,是你写代码,还是机器写代码?
乙:我写代码。
甲:调参数是机器调参数,还是你调参数?
乙:我调参数。
甲:学习完了之后,是机器写报告,还是你写报告?
乙:我写报告。
甲:那问题来了。到底是机器学习,还是你学习?

目录
一种基于深度学习的城市监控渐进式车辆再识别方法
摘要
虽然对人的重新识别(Re-Id)引起了广泛的关注,但作为城市视频监控中一个重要的对象类的汽车,却经常被视觉界忽视。大多数现有的车辆重识别方法只达到有限的性能,因为它们主要关注车辆的一般外观,而忽略了车辆的一些独特标识(例如,车牌)。在本文中,我们提出了一种新的基于深度学习的渐进式车辆重识别方法,称为“PROVID”。我们的方法将车辆重识别视为两个特定的渐进式搜索过程:
在特征方面的由粗到细搜索和在现实世界监控环境中的近距离搜索。
- 第一个搜索过程是使用车辆的外观属性进行粗过滤,然后利用Siamese神经网络(孪生神经网络)进行车牌验证以准确识别车辆。
- 第二个搜索过程以一种像人类一样的方式,通过从近距离到远距离的摄像头和时间进行搜索来检索车辆。
此外,为了促进渐进的车辆再识别研究,我们从大规模城市监控视频中收集了迄今为止最大的名为VeRi-776的数据集,它不仅包含具有不同属性和高复发率(出现率)的大量车辆,还包含足够的车牌和时空标签。对VeRi-776的全面评估表明,我们的方法优于最先进的方法,在mAP方面提高了 9.28%。
关键词: 车辆重识别 渐进式搜索 深度学习 车牌识别 时空关联
1 引言
车辆作为城市视频监控中的重要对象,在计算机视觉研究领域吸引了大量关注,如检测,分类和姿态估计。然而,车辆重新识别(Re-Id)仍然是一个前沿且重要的话题,但经常被研究人员忽视。
车辆重新识别的任务是,给定探测车辆图像,在数据库中搜索由多个摄像机捕获的相同车辆的图像。 车辆重识别在视频监控,智能交通和城市计算方面具有普遍应用,可以在大型监控视频中快速发现,定位和跟踪目标车辆。

与车辆检测,跟踪或分类不同,车辆重新识别可以作为一个实例级的对象搜索问题。在现实世界的车辆识别中,这个问题可以通过渐进过程来处理。例如,如果监控想要在大量监控视频中找到可疑车辆,他们将首先通过外观特征(例如颜色,形状和类型)过滤掉大量车辆,以缩小搜索空间。然后,对于其余车辆,利用牌照来准确识别嫌疑人,如图1(b)所示。此外,搜索范围从近摄像机扩展到遥远,搜索周期从近距离延伸到远处。因此,时空信息也可以提供很大的帮助,如图2所示。现实世界的实践激励我们构建一个渐进式车辆重识别方法,其中包括两个渐进式搜索过程:(1)从粗 - 到 - 精细搜索特征空间; (2)在现实世界的时空环境中从近到远的搜索。

然而,在现实世界城市交通监控中实施渐进式车辆重识别方法仍然面临着几个重大挑战:
- 基于外观特征的方法难以得到最佳结果:不同视角(摄像头)下相同车辆可能会有很大的类内差异,而同样视角(摄像头)下的不同车辆却可能只有微小的类间差异,如图1(a)所示。
- 此外,传统的车牌识别技术可能由于各种照明,视点和分辨率而在无约束的监视场景中失败,如图1(b)所示。此外,车牌识别是一个复杂的多步骤过程,包括车牌检测,分割,形状调整和字符识别,如[7,8]。如何在无约束的交通场景中有效和高效地利用车牌信息仍然是极具挑战性的。
- 城市监控环境中,很难在不受约束的条件下对车辆行为模式建模。交通状况,路况和天气会影响行车路线。时空线索的利用也具有挑战性。
现有的车辆重识别方法主要关注基于外观的模型[1,9]。但是,这些方法不能区分外观相似的车辆,也不能忽视车牌来唯一地识别车辆。 与这些方法不同,我们从粗到精的方式考虑外观特征和车牌。 基于外观的模型首先过滤掉不同的车辆,然后使用车牌进行准确的车辆搜索。 此外,大多数方法都没有考虑时空信息来寻求帮助。 时空关系已被用于许多领域,例如多摄像机监视,交叉摄像机跟踪和对象检索。 利用监控网络中的时空信息,我们可以在时间尺度和空间尺度上以从近到远的原则处理搜索过程。
在本文中,我们提出了PROVID,这是一种用于城市监控的基于深度学习的渐进式车辆重识别方法,具有以下特性:(1)采用渐进式方法搜索车辆,如同在现实世界中一样; (2)利用深度卷积神经网络(CNNs)学习的外观属性模型作为粗车辆过滤器;(3)提出基于Siamese神经网络(孪生神经网络)的车牌验证来匹配车牌图像; (4)探索时空关系以协助搜索过程。特别是对于基于外观的粗过滤器,我们采用低级和高级特征的融合模型来寻找相似的车辆。对于车牌号,**我们只需要验证两个车牌图像是否属于同一车辆,而不是准确识别车牌字符。**因此,使用大量车牌图像训练Siamese神经网络(孪生神经网络)以进行车牌验证。最后,利用时空关系模型对车辆进行重新排序,以进一步改善车辆重识别的最终结果。
为了便于研究和验证相关算法,我们构建了一个名为VeRi-776的综合车辆Re-Id数据集,其中不仅包含具有不同属性和高复发(出现)率的大量车辆,而且还包含足够的车牌和时空标签,这可以极大地方便基于车牌和时空信息的渐进式车辆重识别方法的研究。 最后,我们评估了VeRi-776上的PROVID,以证明所提出的框架的有效性,该框架的性能优于最先进的方法,它在mAP上取得了9.28%的改进,在HIT@1上取得了10.94%的改进。
最后,我们在VeRi-776上评估PROVID以证明所提出框架的有效性,该框架比最新技术在mAP和HIT @ 1方面分别提高了9.28%和10.94%。
2 相关工作
车辆重新识别。
近年来,车辆重识别仍处于有一些作品的早期阶段。
- Feris 等人 [1]提出了一种车辆检测和检索系统,其中车辆按外观分为不同的类型和颜色,然后在数据库中通过这些属性进行索引和搜索。最近,
- Liu 等人 [9]首先评估和分析了几种基于外观的模型,包括纹理,颜色和语义属性,然后提出了一种车辆识别的低层次特征和高级语义属性的融合模型。
然而,由于车辆的相似性和各种环境因素,如照明、视点和遮挡,基于外观的方法不能独特地识别车辆。更重要的是,车辆重识别应该考虑作为每辆车的唯一ID的车牌。
车牌验证。
在工业中,车牌识别已被广泛用于识别车辆[7,8]。然而,由于对车牌图像质量的高要求,现有的方法只能在公园入口和收费站等受限的条件下使用。由于各种环境因素,车牌识别可能在无约束的监视场景中失败[1,9]。因此,对于车辆重识别我们使用车牌验证而不是识别。近年来,深度神经网络在计算机视觉方面取得了巨大成功,如对象分类[13],检测[14],图像理解[15],视频分析[16]和多媒体搜索[17]。其中,
- Bromley 等人提出了 Siamese 神经网络(SNN)来验证手写签名[18]。 SNN采用两个权重共享的卷积神经网络和一个对比度损失函数。在训练期间,它可以同时最小化相似物体对的距离并最大化不同对的距离。
- Chopra 等 [19]采用SNN进行人脸验证,取得了很好的效果。
- Zhang 等人[20]在SNN的步态识别方面取得了最佳性能。
因此,我们利用SNN进行车牌验证,以准确地进行车辆重新识别。
时空关系。
时空关系在多摄像机系统中得到了广泛的应用。[10-12]。 其中,
- 其中,Kettnaker 等[10]建议在相机上使用贝叶斯估计来组合可能的物体路径。
- Javed 等人 [11]利用时空信息来估计物体跟踪的相机间对应关系。
- Xu 等人。 [12]提出了一种分布式摄像机网络中基于图的对象检索系统。
然而,这些方法主要关注于缓慢移动的物体上,例如校园等受限环境中的人。 在大规模无约束的交通场景中,由于复杂的交通状况、路线图和天气,很难对车辆的模式进行建模。
3 所提出的方法
3.1 概述
图3显示了所提出的渐进式车辆重识别方法的架构。 该查询包含车辆的图像,车辆带有摄像机ID和时间戳,用于记录捕获的位置和时间。 根据查询,该方法将车辆重识别的任务视为渐进过程:
- (1)基于外观的粗度过滤器:使用基于外观的模型来过滤车辆数据库中大多数具有不同颜色、纹理、形状、类型的车辆;
- (2)基于车牌的精细搜索:对于剩余的过滤车辆,通过 Siamese 神经网络计算查询车辆与源车辆的车牌相似性,查找最相似的车辆;
- (3)基于所提出的从近到远原理,利用其时空特性对车辆进行了重新排序,进一步改进了车辆的搜索过程。
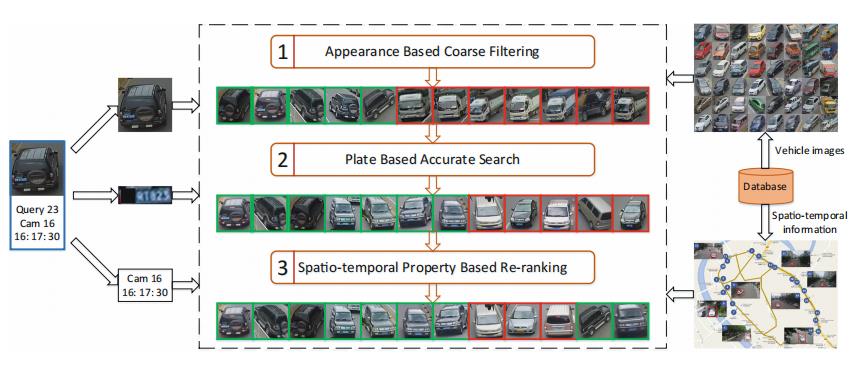
3.2 通过CNN进行外观特征提取
在现实世界的实践中,诸如颜色,形状和类型的外观特征对于过滤掉不同的车辆非常有效。此外,它们在大规模数据集中被提取和搜索是有效的。因此,我们采用了由 Liu [9]等人评估的纹理,颜色和语义属性的融合模型作为粗略过滤器,找到与查询车辆外观相似的车辆。
纹理特征由常规描述符表示,例如尺度不变特征变换(SIFT)[21]。 然后由于词包(BOW)模型在图像检索模型中的准确性和效率,所以用词包(BOW)模型对描述符 进行了编码。颜色特征由经BOW模型量化的颜色名称(CN)模型[23]提取,从而获得了在汽车重识别中具有优异的性能[24]。 高级属性由深度卷积神经网络(CNN)学习,即GoogLeNet [25]。 该模型在CompCars 数据集[2]上进行了微调,以检测车辆的详细属性,例如车门数量,车灯形状,座椅数量和车辆型号。 最后,通过距离级融合将三种类型的特征集成在一起。
通过纹理,颜色和语义属性的融合,基于外观的方法可以筛选出大多数具有不同颜色,形状和类型的车辆。 因此,搜索空间从整个车辆数据库缩小到相对少量的车辆。 然而,由于车辆的相似性和环境因素,基于外观的模型不能唯一地识别车辆。 因此,我们利用车牌(车辆的唯一ID)来获得准确的车辆Re-Id。
3.3 基于Siamese神经网络的车牌验证
对于准确的车辆搜索,车牌是一个重要的提示,因为它是车辆的唯一ID。在无约束的监视场景中,由于视点,低照度和图像模糊,可能无法正确识别牌照,如图1(b)所示。此外,车牌识别技术是一个复杂的过程,包括车牌定位,形状调整,字符分割和字符识别。因此,对于车辆重识别任务而言,它不是很有效。尽管如此,在车辆重识别中,我们只需要验证两个车牌是否相同而不是识别字符。[18]中引入的 Siamese 神经网络(SNN)用于签名验证任务。 SNN的主要思想是学习一个将输入模式映射到潜在空间的函数,其中相同对象对的相似度量很大,来自不同对象对的相似度量很小。因此,它最适合于类的数量很大,和/或在训练期间所有类的样本都不可用的验证场景。当然,车牌验证就是其中一种情况。
设计用于车牌验证的SNN包含两个并行的CNN,如图4所示。每个CNN堆叠有两个部分:(1)两个卷积层和最大池层,以及(2)三个完整连接层。 对比度损失层连接在输出层的顶部。 网络参数设置如图4所示。在训练之前,两个车牌图像被配对作为训练样本,如果它们属于同一车辆则标记为1,否则标记为0。 在训练期间,成对的车牌图像被分别馈送到两个CNN中。 在正向传播之后,CNN的输出被组合到对比损失层中以计算模型的损失。 然后通过具有对比损失的反向传播,同时优化两个CNN的共享权重。

具体地说,让
W
W
W 是SNN的权重,给定一对车牌图像
x
1
x_1
x1 和
x
2
x_2
x2 ,我们可以将数据映射到潜在的度量空间中
S
W
(
x
1
)
S_W(x_1)
SW(x1)和
S
W
(
x
2
)
S_W(x_2)
SW(x2)。然后,能量函数
E
W
(
x
1
,
x
2
)
E_W(x_1, x_2)
EW(x1,x2),它衡量了
x
1
x_1
x1 和
x
2
x_2
x2 之间的兼容性,被定义为
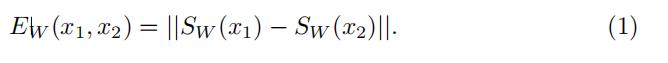
利用能量函数,对比损失可以表示为
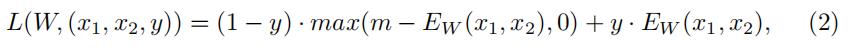
其中 ( x 1 、 x 2 、 y ) (x_1、x_2、y) (x1、x2、y) 是一对带有标签的样本,m为正边距。在实现中,我们采用了具有默认边际值的Caffe框架[26],m=1。在测试过程中,我们使用了已经学习过的SNN从车牌图像中提取 F C 2 FC2 FC2 层的1000d特征。采用欧几里得距离来估计两个车牌图像的相似度分数。
3.4 基于时空关系的车辆重新排序
正如第一部分中所讨论的。 如图1所示,在现实世界的实践中,在时空域中从近到远的方式进行车辆搜索是合理的。 基于这一原理,我们利用时空关系进一步改进车辆重识别。
然而,在无约束的交通情景中,很难对车辆的行驶模型进行建模和预测两辆任意车辆的时空关系。 为了研究时空关系是否对车辆Re-Id有效,我们分析了来自相同车辆的20,000个图像对和来自随机选择的车辆的20,000个对的空间和时间距离。 统计数据如图5所示。我们发现相同车辆的空间和时间距离相对小于随机选择的车辆。 根据这一观察,我们作出一般假设:如果两个图像具有较小的空间或时间距离,则它们具有较高的可能性为同一车辆,并且如果它们具有较大的空间或时间距离,则较低的可能性为同一车辆。 利用该假设,对于每个查询图像i和测试图像j,时空相似性
S
T
(
i
,
j
)
ST(i,j)
ST(i,j)被定义为:

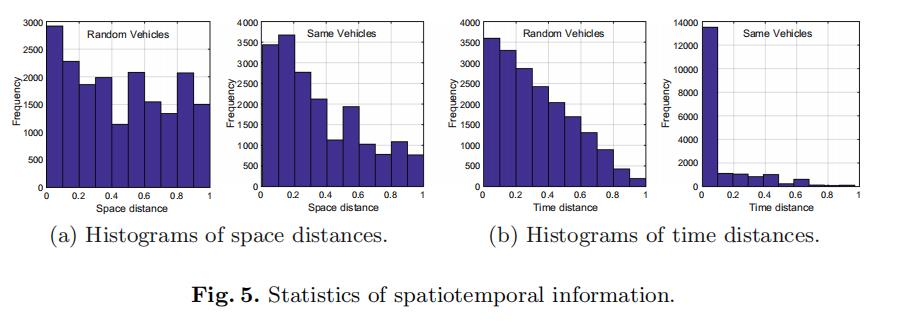
其中,Ti和Tj是查询图像i和测试图像j的时间戳,Tmax是所有查询图像和测试轨迹之间的最大时间差。δ(Ci,Cj)是相机Ci和Cj之间最短路径的长度,Dmax是所有相机之间的最大长度。两个相机之间的最短路径从谷歌地图中获得,并存储在一个矩阵中,如图6所示。最后,可以采用融合后策略或重新排序策略,以将时空信息与外观和板块特征相结合。

4 实验
4.1 数据集
为了很好地研究时空关系并评估所提出的渐进式车辆重建方法,我们从[9]的 VeRi数据集建立了VeRi-776数据集。VeRi数据集有三个特征特性。首先,它包 含了20台监控摄像头拍摄的619辆汽车的图像。此外,图像在真实无约束的交通 场景中捕获,并标记不同的属性,例如。BBoxes、类型(轿车、卡车)、颜色和品牌。此外, 每个车辆由2 -18 个摄像机以不同的视点、照明和遮挡被捕获,这为车辆重新识 别提供了很高的复发率。最后,我们用(1)数据卷扩展、(2)车牌标签和(3)时空信息扩展了VeRi数据集。
数据卷扩展。 在[9]中,刘等人提供的视频帧。我们在VeRi数据集中添加了超 过20%的新车。新车还标记有BBoxes、类型、颜色、品牌和跨相机关系。这使得 该数据集包含超过50,000个车辆图像、大约9000条轨道和776辆车辆,这进一步 提高了车辆重新识别码的可伸缩性。
车牌注释。 新的VeRi776数据集最重要的贡献是对车牌的注释。在注释之前,我 们将数据集分为200辆车辆和11579张图像的测试集,以及576辆车辆和37781张图像的训练集。对于测试集,我们从每个轨道中选择一个图像作为查询,并获 得1678个查询。然后,对于每个查询图像和测试图像,如果注释器可以检测到 车牌,我们对车牌进行注释。对于注释的质量,每个图像至少由三个有多数投 票的人工注释者进行注释。最后,查询图像999幅板图像,测试图像4825幅板图 像,列车图像7647幅板图像。大约50%的查询和测试图像可以利用车牌来改善车 辆的重新编号。
时空关系注释。 我们注释了所有车辆轨迹的时空关系。轨道是一个相机同时捕捉的车辆轨迹,属于一个轨道的图像聚集在一起。对于每条轨道,我们首先标记捕获轨道的相机的ID(从1到20)。然后我们使用第一个捕获的图像的时间戳跟踪作为它的时间戳。此外,为了方便计算在基于时空关系的重新排序中使用的空间距离,我们得到了两者之间的最短路径的长度 通过谷歌地图对监控网络中的20个摄像头,如图6所示。
4.2 实验性设置
在4.1部分,VeRi-776数据集被分为两个子集,用于训练和测试。训练集有576辆车的37781张图片,测试集有200辆车的11579张图片。在评估中,执行了交叉相机搜索,这意味 着我们使用一个相机中的一个车辆图像在其他相机中搜索同一车辆的轨迹。此 外,在[9]中,车辆Re-Id以图像到图像的方式,这意味着使用查询图像像个人 Re-Id[24]一样搜索目标图像。与[9]不同的是,我们以一种图像到跟踪的方式 进行车辆的重新识别,其中查询是一个图像,而目标单元是车辆的轨迹。查询 图像和测试轨迹之间的相似性由查询图像与所有轨迹的图像之间的最大相似性 来表示。在现实实践中,我们只需要在一个相机中找到轨道来捕捉目标车辆。 因此,图像到跟踪的实际搜索更合理。对于图像到跟踪的搜索,我们有1678个 查询图像和2021个测试跟踪。
对于VeRi-776数据集,每个查询都有多个基本事实。因此,我们采用平均平均精度(mAP),同时考虑精度和召回率来评估整体性能 为车辆重新编号。对于每个查询图像,我们计算平均精度(AP)为
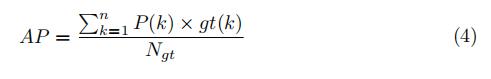
其中n是测试轨迹的数量,Ngt是地面真相的数量,P(k)是结果列表中截止k的精度,如果cthk结果是co,gt(k)是等于1的指示函数 重新安装。mAP通过所有查询计算为

其中,Q是查询的数量。此外,我们还采用了累积匹配特征(CMC)曲线、HIT@1和HIT@5,它们被广泛应用于人工回复Id[24]。
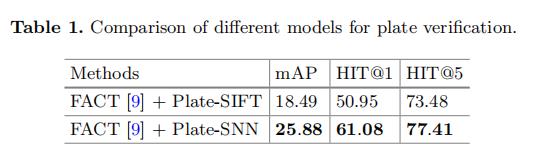
4.3 评估车牌验证
为了评估基于孪生神经网络的车牌验证,我们将其与传统的手工特征 SIFT[21] 进行了比较。我们通过融合将车牌的特征与 FACT 模型结合起来测试其对基于外观的模型的性能。这两种模型的设置如下:
(1) . FACT + Plate-SIFT,该方法采用传统的SIFT作为局部描述符。然后用袋字 (BOW)模型对板的描述符进行量化。在测试之前,我们用VeRi-776的训 练板来训练一个BOW模型的码本,码本的大小为1000。在测试阶段,每 个板表示为1000d焊接特征。
(2) FACT + Plate-SNN,我们首先训练孪生神经网络进行车牌验证。在7647张训练板图像中,我们在训练集随机挑选出大约5万对同一车辆的车牌为阳性样本,5万对不同车辆的车牌为负样本。我们采用Caffe[9]来实现 第2节中的SNN。3.3、用随机梯度降解器训练SNN。我们使用6万次迭代的模 型来提取1000d的FC2层输出作为车牌的表示。
对于这两种模型,都进行了图像到跟踪的搜索,用欧几里得距离计算了相似性。融合后的FACT重量为0.4,Plate-SNN的重量为0.6。mAP、HIT@1和HIT@5用于评估性 能。表1显示了搜索结果,表明深度学习模型比SIFT是好得多的特征。结果表 明,在无约束的监控场景中,传统的手工特征对各种光照、视点和分辨率没有 鲁棒性。而在大量板对上训练的SNN模型可以将输入模式映射到一个潜在空间, 其中相同对象的相似度量更大,不同对象的相似度量更低。丰富的训练车牌样 本保证了学习模型的鲁棒性。
4.4 车辆识别方法的评价
(1) BOW-CN [24]. 这是带有颜色名称描述符的单词包,这是个人身份证的最先进的外观功能之一。在[9]中,也采用它作为车辆重新识别的颜色 特征。
(2) LOMO [27]. 这是一种最先进的人工再识别纹理特征,可以有效地克服现实监控环境中的各种照明问题。
(3) GoogLeNet [2]. 该方法利用了GoogLeNet模型[25]。我们将其作为特征提取器来获得外观的高级语义属性。
(4) FACT [9]. 我们采用FACT[9]来估计查询图像和测试轨迹之间的外观相似性。该FACT考虑了基于外观筛选的所有颜色、纹理、形状和语义属性。
(5) Plate-SNN. 此方案仅使用查询和跟踪之间的车牌相似性来搜索测试跟踪中最近的目标。这些特征是由训练的SNN模型计算的。
(6) FACT + Plate-SNN. We firstly use the FACT as the coarse vehicle filter.
Then we adopt the post-fusion strategy which combines the similarities of
FACT model and Plate-SNN model as fine search. The weights used in
summation are 0.4 and 0.6 respectively for the FACT and the Plate-SNN
due to their individual performances in vehicle Re-Id.
(7) FACT + Plate-REC. In this scheme, we adopt a commercial plate recognition system (Plate-REC) to replace the Place-SNN as the fine search.
(8) FACT + Plate-SNN + STR. This scheme integrates the similarities of
the FACT, Plate-SNN, and spatiotemporal relations (STR). The spatiotemporal similarity between the query and test is calculated by Eq. 3. Then, the
similarity matrixes of the FACT + Plate-SNN and STR are both normalized
to (0, 1). At last, the two matrixes are summed with different weights. The
weights are 0.8 and 0.2 respectively due to their individual performances.
By this means, the appearance, license plate, and spatiotemporal relations
are combined together for the progressive vehicle search.
以上是关于(翻译)A Deep Learning-Based Approach to Progressive Vehicle Re-identification for Urban Surveillance的主要内容,如果未能解决你的问题,请参考以下文章