IDC网络低时延无阻塞拥塞控制随想
Posted dog250
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了IDC网络低时延无阻塞拥塞控制随想相关的知识,希望对你有一定的参考价值。
传统的拥塞控制千篇一律:
- 假设数据流都是长流。
- 目标端主机或交换机提供反馈信息给源端主机,源端主机根据这些信息限制发送量。
无论交换节点是否参与,本质上这还是端到端拥塞控制,注定是滞后的。
传统的拥塞控制目标是所有流量公平收敛到网络瓶颈带宽。显然,下面的情况将无法从该目标中获得收益:
- 时延敏感的长流遭遇瞬时拥塞,时延必然抖动。拥塞控制算法无法避免当下的延时增加。
- 时延敏感的多条突发短流,造成局部拥塞。数据可能是oneshot传输,没有机会让反馈登场。
根本原因在于,网络交换节点没有起到疏导当前流量的作用。为此,我觉得交换节点应该担起这个责任,这就是上周我写的那篇脑洞的缘起。
交换节点介入拥塞控制进行流量疏导,这显然违背了端到端原则,将复杂性引入网络中心,既已如此,便可利用这种复杂性直接进行拥塞控制。
这种新型的拥塞控制方案,本质上是对路径和buffer的资源调度。
路径Load Balancing
动机
将IDC网络交换机分为两类:
- Leaf节点,即直连服务器的交换机,比如ToR。
- nonLeaf节点,除Leaf交换机之外其它交换机。
这个拥塞控制机制是拓扑无关的,简单期间,做成阡陌结构,交换节点分类如下:
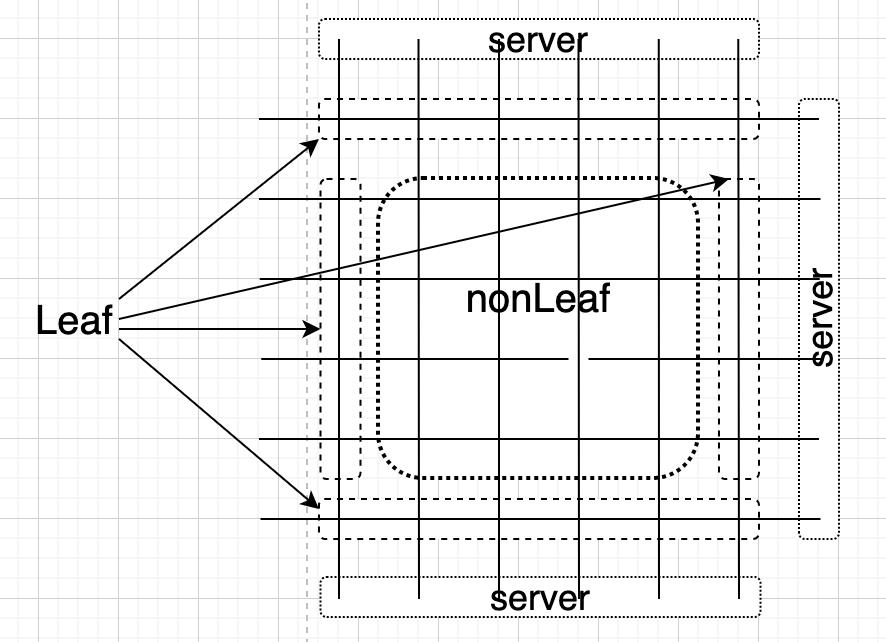
基于流体渗透原理,流量尽可能充满整个网络从而绕开拥塞节点,参见:
https://zhuanlan.zhihu.com/p/449581169
为此需要创建转发表。
静态weight更新
数据包从Leaf进入网络,被tag上该Leaf的Leaf-ID以及一个初始化为0的weight值,每经过一个nonLeaf节点:
- 数据包附着的weight递增1。
- 以数据包Src为键查询并以数据包Leaf-ID更新Src-Leaf映射表。
- 以数据包Leaf-ID为Dst键查询并以数据包weight值更新其它端口的Dst-Weight表项static weight。
这就通过学习填充了per-port转发表中的最优路径weight。
诸多次优路径的weight可通过向相邻non-Leaf节点询问特定Leaf节点weight,将返回的weight值加1即可,这需要独立的控制协议。具体如下:
- non-Leaf节点定期请求邻居的直连端口Dst-Weight表,以各表项 W s t a t i c + 1 W_static+1 Wstatic+1作为static weight。
动态weight更新
除了一个static weight,还有一个dynamic weight,更新规则:
- 若nonLeaf节点某端口P队列发生变化,队列长度为 l l l,将根据 w = f ( l ) w=f(l) w=f(l)更新P之外所有端口Dst-Weight表对应端口P所有Dst的weight值为 W s t a t i c + w W_static+w Wstatic+w。
防环路
为了防止环路,特意将原始路由协议的可能环路的weight设置成一个足够大的值,端口包括不限于:
- 收到数据包的上游端口。
- Leaf节点的其它端口。
- 邻居端口返回的环路端口。
weight-based转发
数据包到达时:
- 以数据包Dst为Src键查询Src-Leaf映射表,获取Leaf-ID。若查询无果,则按照标准路由转发。
- 以Leaf-ID为Dst键查询Dst-Weight表,获取weight值最小的port,转发至该port。
Buffer Load Balancing
Yet another PFC
动机
在交换节点拥塞时,PFC反压机制可以进行源抑制缓解拥塞。但标准的PFC反压没有区分Dst和Src,对所有通过同一端口的数据包一视同仁阻滞,造成无关流量HoL拥塞。Load Balancing解决了大部分问题,但是:
- nonLeaf节点既然可以通过路径Load Balancing绕开拥塞点,Leaf节点怎么办?
答案是扩展PFC反压机制。引入per-Dst反压,识别并隔离incast流量。结果:
- incast流量经由的路径上所有节点,共同buffer数据,避免Leaf节点溢出。
- 非incast流量不受incast流量影响。
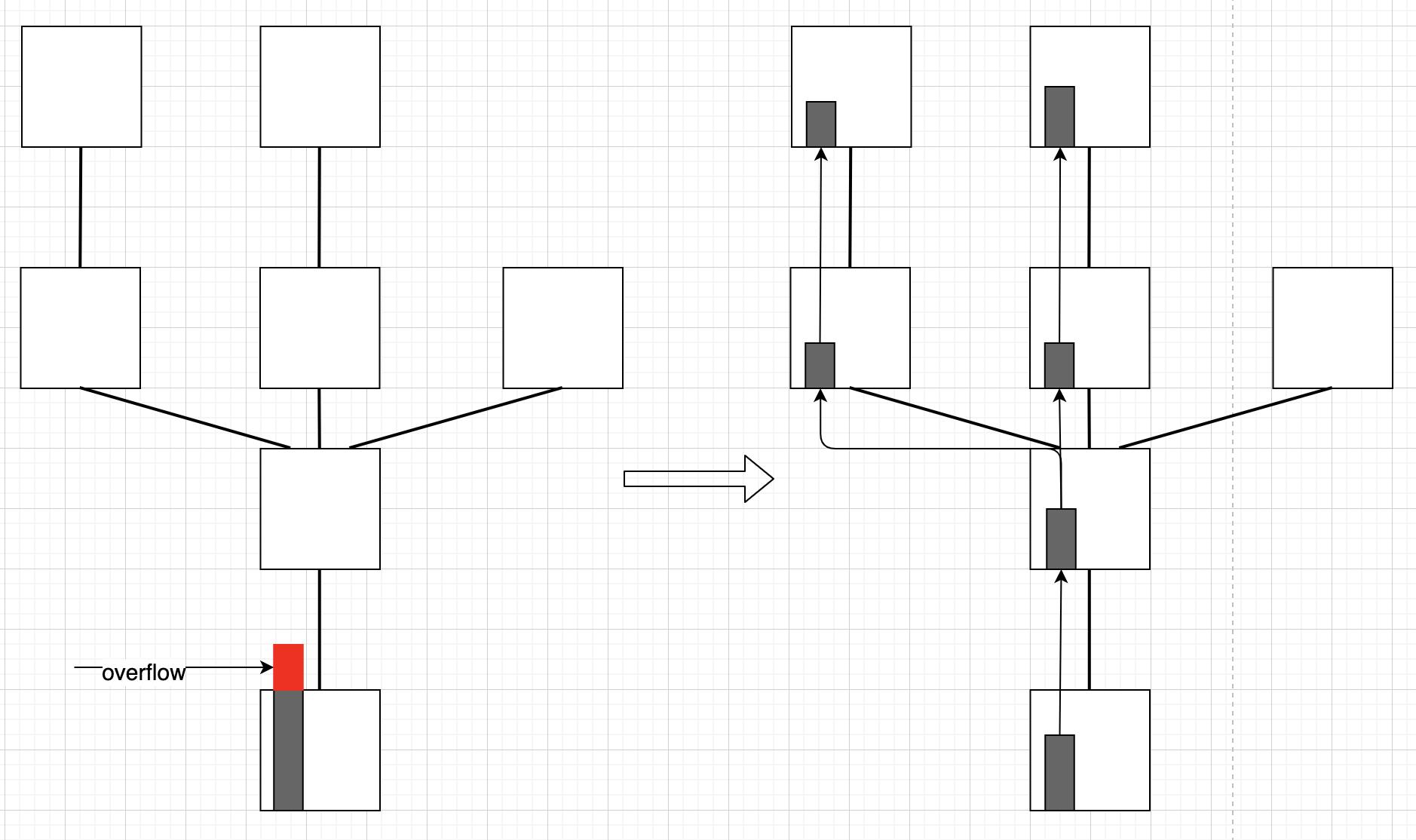
新式PFC反压
若Leaf节点出现了到达相同Dst的多打一队列堆积,显然是incast流量,需要反向逐跳反压源抑制消息:
- 当incast队列在Leaf节点达到一定阈值,向入端口的上一跳R发送携带Dst信息的反压消息。
- 上一跳R收到反压消息,解析出Dst,以Dst为键查询或新建队列Q。
- 上一跳R收到到达Dst的数据包,排入队列Q,向入端口的上一跳发送携带Dst信息的反压消息。
- 若反压至源端Leaf,进行下一步,否则回到上述第二步。
- 若源主机网卡不支持源抑制,则数据包在Leaf排队,否则直接抑制源主机。
支持源抑制的网卡需要自研,但一般情况下,能反压到源Leaf的流就需要端到端拥塞控制来收敛了。
取消反压
若Leaf节点到达某Dst的队列缓解,则反向发送unplug消息:
- 当incast队列在Leaf节点缓解到低于阈值,向入端口的上一跳R发送携带Dst信息的unplug消息。
- 上一跳R收到unplug消息,解析出Dst,以Dst为键查询Q,以pacing清除队列Q。
- 上一跳R向入端口的上一跳发送携带Dst信息的unplug消息。
- 回到上述第二步。
端到端流控
non-Leaf节点,Leaf节点的拥塞问题都解决了,最后一跳就是端主机了。
端主机拥塞控制是流量控制的职责,交换网络不负责。
自研交换机
没有哪家的交换机会实现上述的功能,但以上写的这些并非异想天开。自研交换机将会是IDC网络的趋势,各家互联网厂商都被延时抖动所困扰,于是解决方案也就百家争鸣了。
据了解,目前主流IDC部署,ToR一般在1000计,其Buffer在10MB计,二级,三级等汇聚Buffer在100M,1G计,完全可以满足流体渗透模型的复杂性约束。还在犹豫什么呢?
依据和原理
将数据通过网络传输到对端,有两种方式:
- 串行方式:沿着一条路径传输。
- 并行方式:沿着所有路径传输。
迄今都在采用串行方式,若非下面两个因素的偏袒,并行方式或许被大规模使用:
- 基于最短路径优先(SPF)的路由协议。最短路径优先原则相当于排除了所有其它路径。
- TCP等协议。流是对分组交换的反面,分组交换网对流不可见,流是端到端的概念。
串行方式有两个避不开的难题:
- 时延不可控。
- HoL阻塞。
洪水泛滥模型可根治上面两个问题,它显然属于并行方式。
有趣的是,SPF路由协议让人们忘记了一件事,当传输一组数据包而不是一个数据包时,在所有路径上一起传输效率更高,然而TCP协议却让人们记住了另一件事,即便是传输一组数据包,也要在一条路径上串行传输。二者合力让洪泛模型不合时宜。
总有人提TCP乱序的事,只要端主机缓存足够大,乱序重组效率非常高,相比复杂的保序逻辑,只是归并排序。
基于排队论M/M/1分析,考虑以下拓扑:
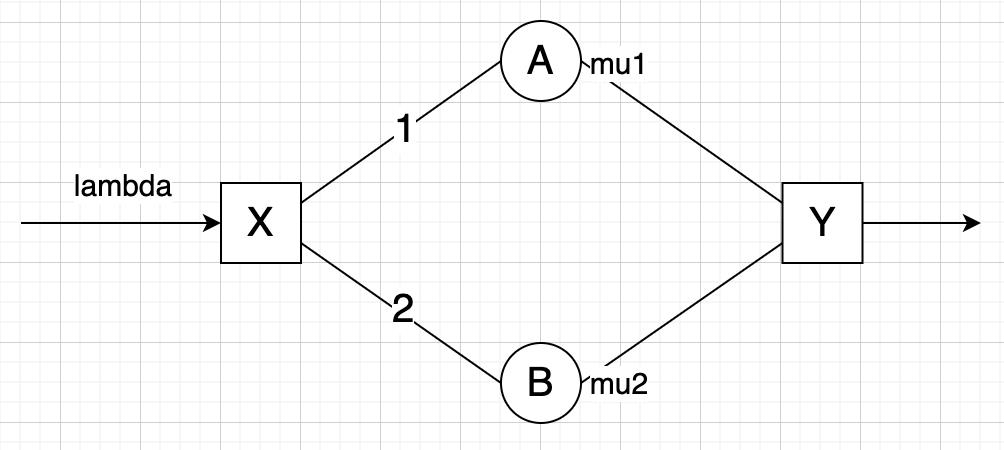
设到达率为 λ \\lambda λ,交换节点A,B的处理率分别为 μ 1 \\mu_1 μ1, μ 2 \\mu_2 μ2,假设从X流出的数据包以概率 p p p发往路径1,发往路径2的概率就是 1 − p 1-p 1−p,根据M/M/1时延公式,数据包从X到Y的平均时延为:
T = 1 λ [ λ p μ 1 − λ p + λ ( 1 − p ) μ 2 − λ ( 1 − p ) ] T=\\dfrac1\\lambda[\\dfrac\\lambda p\\mu_1-\\lambda p+\\dfrac\\lambda(1-p)\\mu_2-\\lambda(1-p)] T=λ1[μ1−λpλp+μ2−λ(1−p)λ(1−p)]
其中
p
p
p是变量。随便设
λ
=
3
\\lambda=3
λ=3,
μ
1
=
4.5
\\mu_1=4.5
μ1=4.5,
μ
2
=
6
\\mu_2=6
μ2=6,它的图像大致如下:
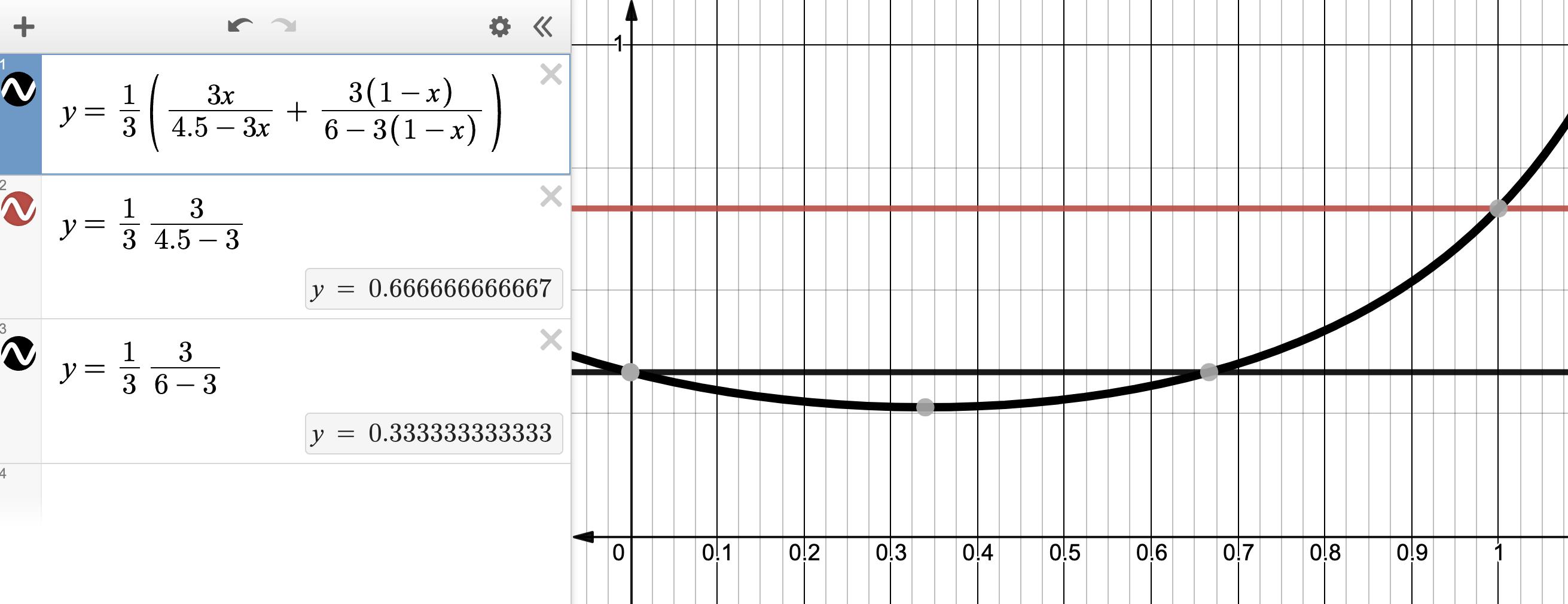
通过调节 p p p,总延时 T T T可达最小。显然,相比通过任意单一路径,最好情况下,路径Load Balancing时延更小。
也许你会认为将A和B合并为一个处理率为 μ 1 + μ 2 \\mu_1+\\mu_2 μ1+μ2的处理机岂不更好?但互联网本身是Trade-off,不止是为了低时延,还要为了高鲁棒性,后者更重要!
依据上述简单模型进行组合,便是本文上述的流体渗透模型的路径Load Balancing了。
至于Buffer Load Balancing,就是让整条路径分担队列,避免单一节点溢出,没什么好说的。
关于本文
刷知乎时偶遇一本书《高性能通信网络》:

2002年的老书,推荐这书的人我也有加微信,所以就询了目录,当即就买了,绝版书,淘宝上买了二手。
虽是老书,但豁然开朗,20年后的今天少有这种书了,现在的书普遍偏工程而少算法。比如本文介绍的内容,这书里就有基本思想,但现在几乎都没了声音。
很多老算法没能被实践,直接就没了声音。这无可厚非,最优解不是工业界追求的,关键看谁先做出来,并且大规模使用,资本嗅到了腥气才能利好工业界。
资本是一回事,随想是另一回事,随便想想,就是随想,就是本文。
浙江温州皮鞋湿,下雨进水不会胖。
以上是关于IDC网络低时延无阻塞拥塞控制随想的主要内容,如果未能解决你的问题,请参考以下文章