不用纠结,这2个数据探索分析神器绝对好用
Posted Python数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不用纠结,这2个数据探索分析神器绝对好用相关的知识,希望对你有一定的参考价值。
大家好,今天我给大家推荐两款超好用的工具来对数据进行探索分析,他们可以更好地帮助数据分析师从数据集当中来挖掘出有用的信息。技术交流文末提供。
废话不多说,我们开始分享。
干货推荐
PandasGUI
一听到这个名字,大家想必就会知道这个工具是在Pandas的基础之上加了GUI界面,它所具备的主要功能有:
-
查看DataFrame数据集与Series数据集
-
交互式地绘制图表
-
过滤数据
-
统计分析
-
数据的修改与复制粘贴
-
拖放导入csv文件
-
搜索工具栏
当然在使用之前,我们先要安装好该工具
pip install pandasgui
然后我们导入该工具,并且用它来查看某个数据集,代码如下
import pandas as pd
from pandasgui import show
df = pd.read_excel(
io=r'supermarkt_sales.xlsx',
engine="openpyxl", sheet_name="Sales",
skiprows=3, usecols="B:R",
nrows=1000
)
show(df)
运行上述的代码之后会弹出一个GUI界面
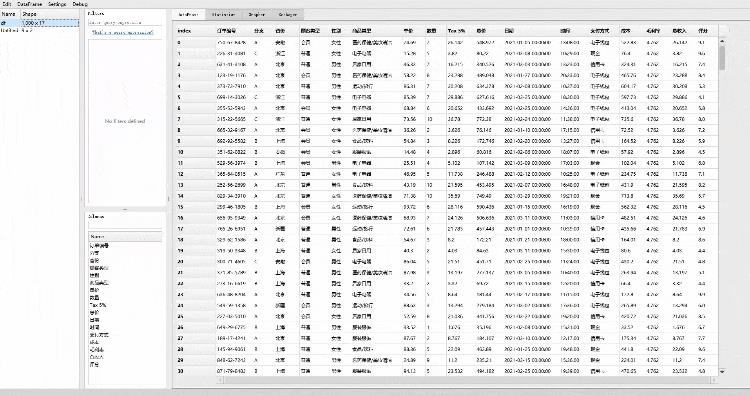
我们先来看一下弹出的页面当中的布局,最左边是数据集的形状,比方说1000*17,具体看下图
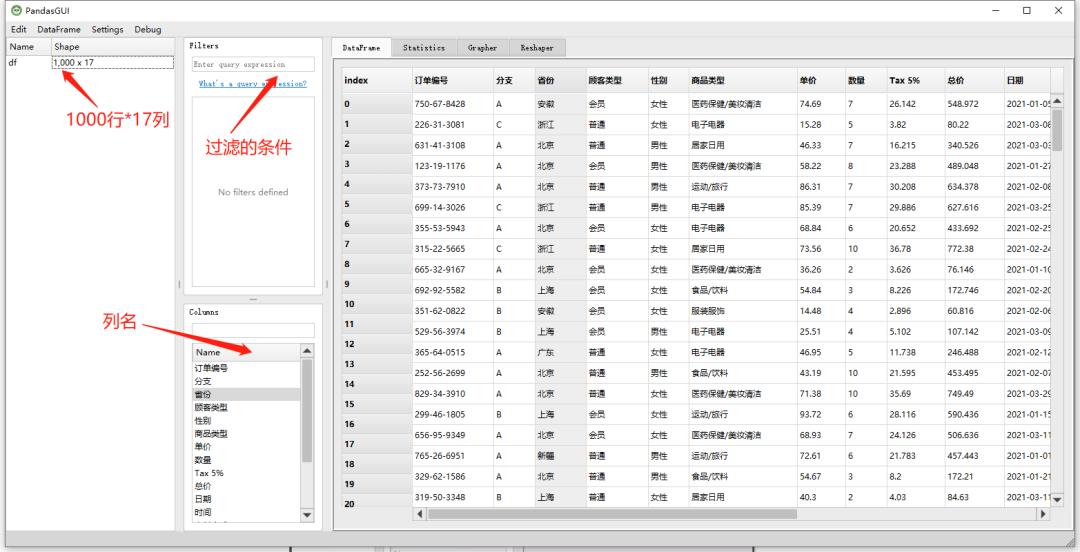
过滤数据
数据过滤时候,我们需要填入相应的条件,主要是在中间这一列中输入,例如我们想要筛选出来的数据需要满足
-
省份:浙江
-
顾客类型:会员
-
性别:男性
以上这几个条件,我们可以这么来做,在filter这一列当中依次输入筛选的条件,如下图
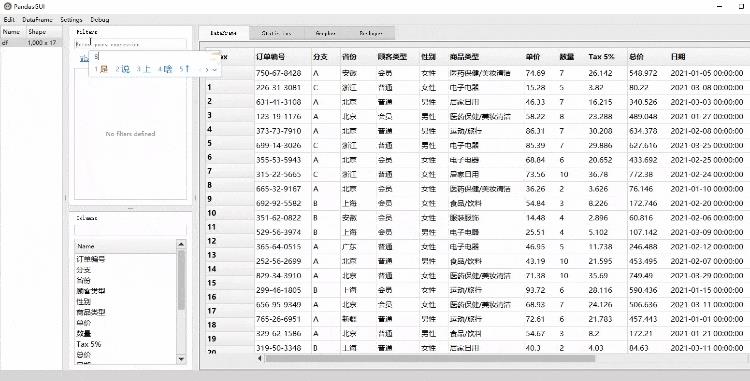
数据的修改与复制粘贴
同时我们还可以修改当中的数据
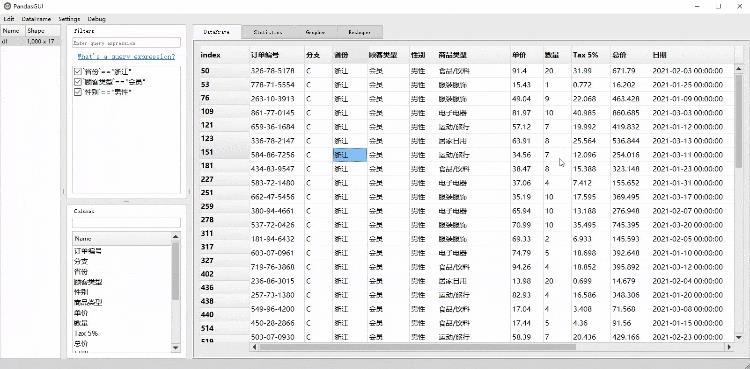
以及将里面的数据复制/粘贴出来
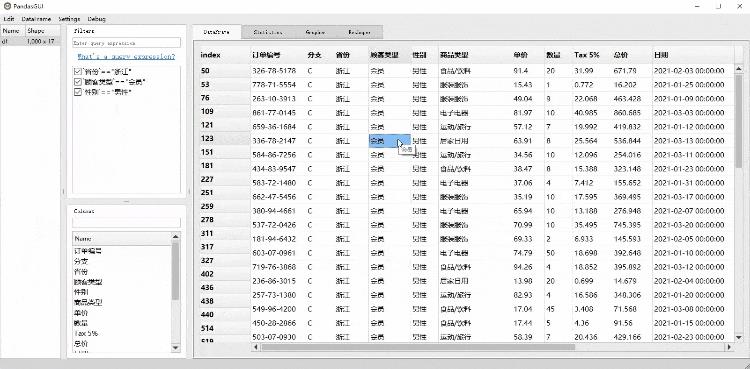
数据的统计分析
在PandasGUI这个工具当中,我们还能够对数据集进行统计分析,切换到Statistics选项当中就能够看到
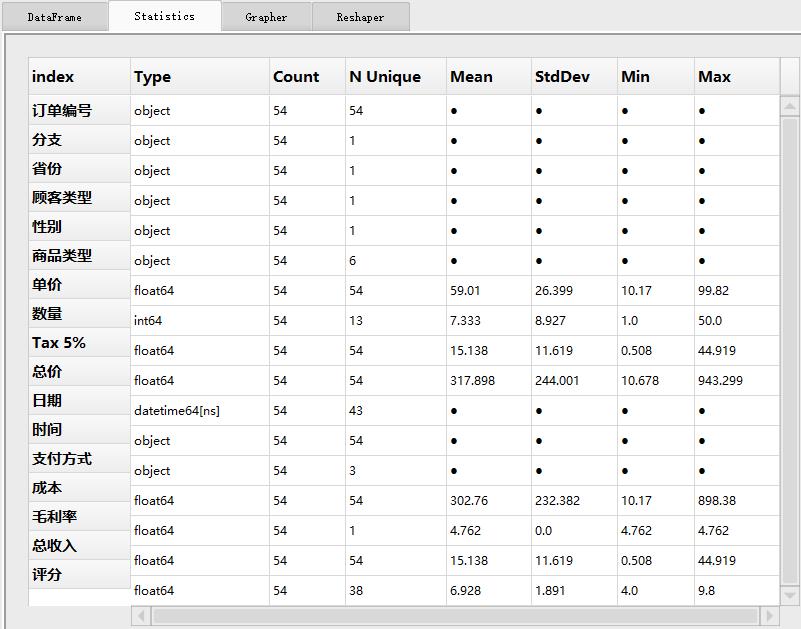
当中的统计变量有“平均值”、“最大/最小值”和“标准差”,包括每一个变量的数据类型也在当中有展示出来
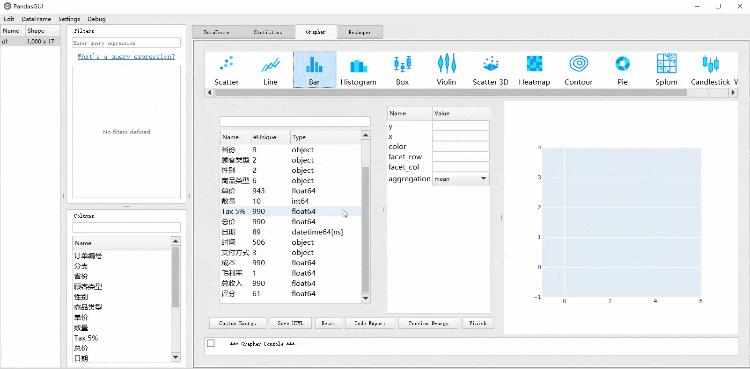
绘制交互式图表
我们还能够在上面绘制交互之图表,支持的图表类型有柱状图、散点图、折线图、饼图等等

例如柱状图,我们看到有x轴和y轴,我们只需要将相对应的列拖拽到x轴或者是y轴即可
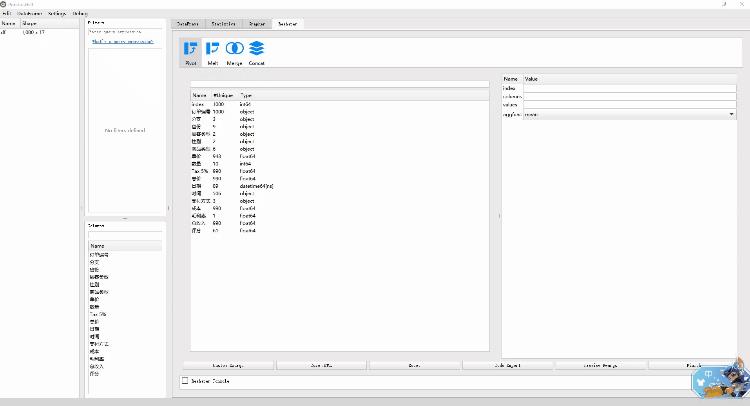
数据集的变形
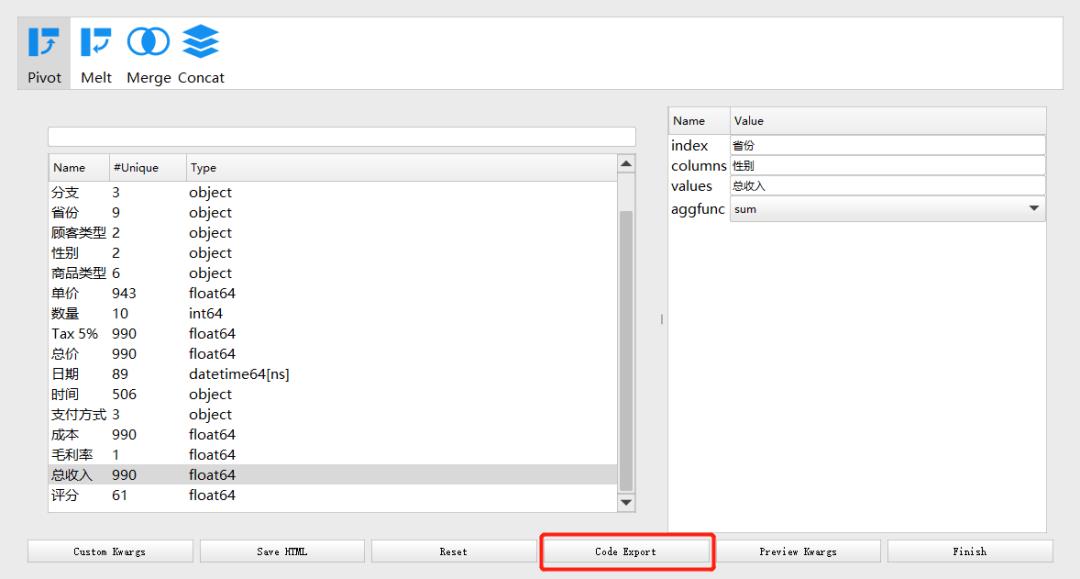
在Reshaper这个选项当中,我们可以将现有的数据集与其他的数据集合并,和pandas当中的merge()方法一样,同时我们也能制作透视表,和pandas当中的pivot_table()方法一样
当然我们还可以将以上的操作转换成代码的形式,通过点击Code Export这个按钮
支持csv文件的导入与导出
同时这里还支持csv文件的导入与导出,让我们更加快捷的操作数据集
Jupyter当中的小插件
下面小编给大家介绍一个在Jupyter当中使用的小插件名叫ipympl,能够使得matplotlib绘制出来的图表也能够具备交互性的特征,当然在使用之前,我们先要安装上该插件
通过pip来安装
pip install ipympl
也可以通过conda来进行安装
conda install -c conda-forge ipympl
然后涉及到具体的使用,我们导入相关的模块
%matplotlib widget
import pandas as pd
import matplotlib.pyplot as plt
我们使用常用的iris.csv来进行图表的绘制
plt.scatter('sepal_length(cm)', 'petal_width(cm)', data=iris)
plt.xlabel('Sepal Length')
plt.ylabel('Petal Width')
plt.show()
output

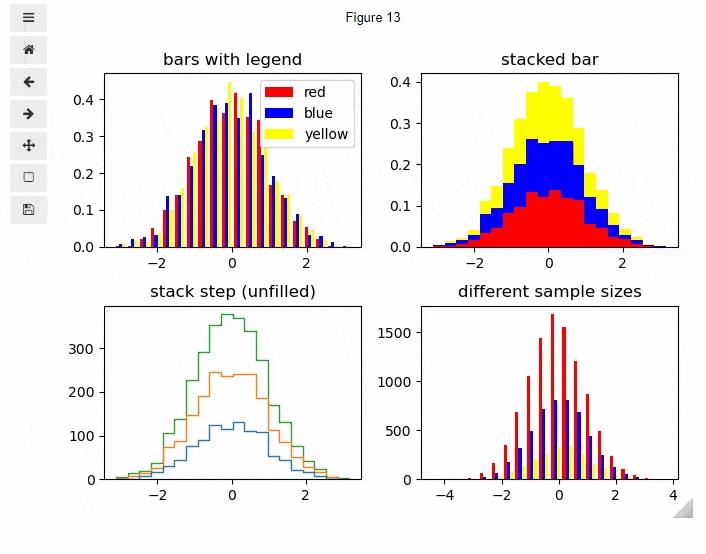
从上面的结果来看,绘制出来的图表具备交互性,并且可以任意我们放大、缩小以及拖拽,并且可以将绘制好的图表下载到本地,而针对具有多个子图的图表,也能够实现交互式的绘制
np.random.seed(0)
n_bins = 20
x = np.random.randn(1000, 3)
fig, axes = plt.subplots(nrows=2, ncols=2)
ax0, ax1, ax2, ax3 = axes.flatten()
colors = ['red', 'blue', 'yellow']
ax0.hist(x, n_bins, density=1, histtype='bar', color=colors, label=colors)
ax0.legend(prop='size': 10)
ax0.set_title('bars with legend')
ax1.hist(x, n_bins, density=1, histtype='bar', stacked=True, color=colors)
ax1.set_title('stacked bar')
ax2.hist(x, n_bins, histtype='step', stacked=True, fill=False)
ax2.set_title('stack step (unfilled)')
x_multi = [np.random.randn(n) for n in [10000, 5000, 2000]]
ax3.hist(x_multi, n_bins, histtype='bar', color=colors)
ax3.set_title('different sample sizes')
fig.tight_layout()
plt.show()
output
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群

以上是关于不用纠结,这2个数据探索分析神器绝对好用的主要内容,如果未能解决你的问题,请参考以下文章