ElasticSearch 学习笔记
Posted 皓洲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch 学习笔记相关的知识,希望对你有一定的参考价值。
ElasticSearch 学习笔记
很久没有写blog了,最近在一个项目中有用到ElasticSearch,出现了一个不定时出现的bug,经常会每隔一段时间es的查询就会失效,有幸捕获到这个异常,查看报错,是连接超时的问题,后来通过百度,为es的配置设置了连接池的大小,问题就解决了。这时候经典疑惑就来了:
为什么他运行不了?为什么他又能运行了?
带着这样的疑问,我打开了elastic官网进行学习。
什么是ElasticSearch?
Elasticsearch 是一个实时的分布式搜索分析引擎,它能让你以前所未有的速度和规模,去探索你的数据。 它被用作全文检索、结构化搜索、分析以及这三个功能的组合:
- Wikipedia 使用 Elasticsearch 提供带有高亮片段的全文搜索,还有 search-as-you-type 和 did-you-mean 的建议。
- Guardian 使用 Elasticsearch 将网络社交数据结合到访客日志中,为它的编辑们提供公众对于新文章的实时反馈。
- Stack Overflow 将地理位置查询融入全文检索中去,并且使用 more-like-this 接口去查找相关的问题和回答。
- GitHub 使用 Elasticsearch 对1300亿行代码进行查询。
它可以被下面这样准确的形容:
- 一个分布式的实时文档存储,每个字段 可以被索引与搜索
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
为什么要学习ElasticSearch?
搜索以及分布式系统是非常复杂的,不过为了充分利用 Elasticsearch,迟早也需要掌握它们。
恩,是有点复杂,但不是魔法。复杂系统如同神奇的黑盒子,能响应外部的咒语,但是通常里面的工作逻辑很简单。 理解了这些逻辑过程你就能驱散魔法,理解内在能够让你更加明确和清晰,而不是寄托于黑盒子做你想要做的。
索引
存储数据到 Elasticsearch 的行为叫做 索引 ,但在索引一个文档之前,需要确定将文档存储在哪里。
一个 Elasticsearch 集群可以 包含多个 索引 ,相应的每个索引可以包含多个 类型 。 这些不同的类型存储着多个 文档 ,每个文档又有 多个 属性 。
索引 这个词在 Elasticsearch 语境中有多种含义, 这里有必要做一些说明:
| 索引对比 | |
|---|---|
| 索引(名词) | 如前所述,一个 索引 类似于传统关系数据库中的一个 数据库 ,是一个存储关系型文档的地方。 索引 (index) 的复数词为 indices 或 indexes 。 |
| 索引(动词) | 索引一个文档 就是存储一个文档到一个 索引 (名词)中以便被检索和查询。这非常类似于 SQL 语句中的 INSERT 关键词,除了文档已存在时,新文档会替换旧文档情况之外。 |
| 倒排索引: | 关系型数据库通过增加一个 索引 比如一个 B树(B-tree)索引 到指定的列上,以便提升数据检索速度。Elasticsearch 和 Lucene 使用了一个叫做 倒排索引 的结构来达到相同的目的。 默认的,一个文档中的每一个属性都是 被索引 的(有一个倒排索引)和可搜索的。一个没有倒排索引的属性是不能被搜索到的。我们将在 倒排索引 讨论倒排索引的更多细节。 |
搜索
- 查询表达式搜索
curl -X GET "localhost:9200/megacorp/employee/_search?pretty" -H 'Content-Type: application/json' -d'
"query" :
"match" :
"last_name" : "Smith"
'
- 过滤器 filter 搜索
curl -X GET "localhost:9200/megacorp/employee/_search?pretty" -H 'Content-Type: application/json' -d'
"query" :
"bool":
"must":
"match" :
"last_name" : "smith"
,
"filter":
"range" :
"age" : "gt" : 30
'
- 全文搜索
curl -X GET "localhost:9200/megacorp/employee/_search?pretty" -H 'Content-Type: application/json' -d'
"query" :
"match" :
"about" : "rock climbing"
'
- 短语搜索
curl -X GET "localhost:9200/megacorp/employee/_search?pretty" -H 'Content-Type: application/json' -d'
"query" :
"match_phrase" :
"about" : "rock climbing"
'
- 高亮搜索
curl -X GET "localhost:9200/megacorp/employee/_search?pretty" -H 'Content-Type: application/json' -d'
"query" :
"match_phrase" :
"about" : "rock climbing"
,
"highlight":
"fields" :
"about" :
'
- 分析搜索(类似sql的group by)
curl -X GET "localhost:9200/megacorp/employee/_search?pretty" -H 'Content-Type: application/json' -d'
"query":
"match":
"last_name": "smith"
,
"aggs":
"all_interests":
"terms":
"field": "interests"
'
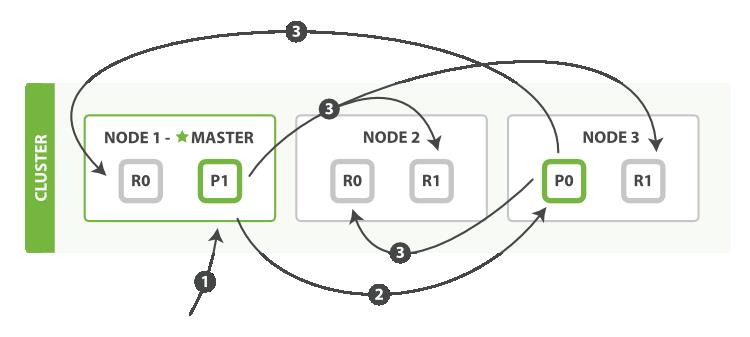
分布式特性
Elasticsearch 尽可能地屏蔽了分布式系统的复杂性。这里列举了一些在后台自动执行的操作:
- 分配文档到不同的容器 或 分片 中,文档可以储存在一个或多个节点中
- 按集群节点来均衡分配这些分片,从而对索引和搜索过程进行负载均衡
- 复制每个分片以支持数据冗余,从而防止硬件故障导致的数据丢失
- 将集群中任一节点的请求路由到存有相关数据的节点
- 集群扩容时无缝整合新节点,重新分配分片以便从离群节点恢复
使用 mget 取回多个文档

使用 bulk 修改多个文档
以上是关于ElasticSearch 学习笔记的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch - 尚硅谷(2. Elasticsearch 安装)学习笔记