一起学习正则表达式正则匹配原理
Posted 容华谢后
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一起学习正则表达式正则匹配原理相关的知识,希望对你有一定的参考价值。
转载请注明出处:https://blog.csdn.net/kong_gu_you_lan/article/details/119725415
本文出自 容华谢后的博客
往期回顾:
0.写在前面
在前面的文章中,我们学习了正则表达式的基础元字符,贪婪匹配还有一些常用的匹配模式,学会了这些,工作中的大部分问题,我们都可以做到游刃有余的解决。
But,仅仅是这些还不够,今天我们一起来学习下正则的匹配原理,知其所以还要知其所以然,学完本篇文章,相信各位可以写出更加优美的正则表达式。
1.有穷状态自动机
如果看过《编译原理》这本书,对有穷状态自动机这个词一定不陌生,有穷是指一个系统具有有穷个状态,不同的状态代表不同的意义。自动机是指系统可以根据相应的条件,在不同的状态下进行转移,从一个初始状态到达终止状态。
以正则表达式 ab|ac 为例:
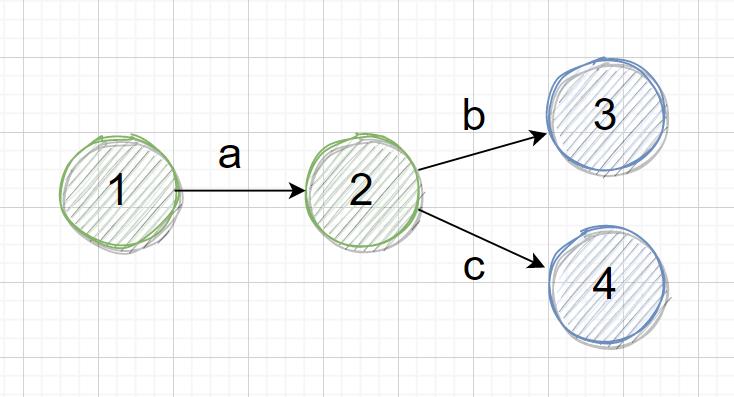
1 是初始状态,输入 a 后就转移到状态 2 上,接着再输入 b 可以转移到状态 3 上,或者输入 c 可以转移到状态 4 上,图中蓝色的圆圈代表可接受的结束状态,结束状态可以是一个,也可以是多个。
有穷状态自动机就是一个识别器,它对每个输入的字符做识别和判断,来确定下一步该走向哪里,有穷状态状态机分为两种,分别是:
-
确定性有穷自动机(Deterministic Finite Automata,DFA)
-
非确定性有穷自动机(Nondeterministic Finite Automata,NFA)
2.DFA原理
DFA 是确定性有穷自动机的简称,因为是确定性的,所以 DFA 的特点是,每一个状态都能够基于下一个输入的字符,进行确定的转换,以 ab*c 为例:
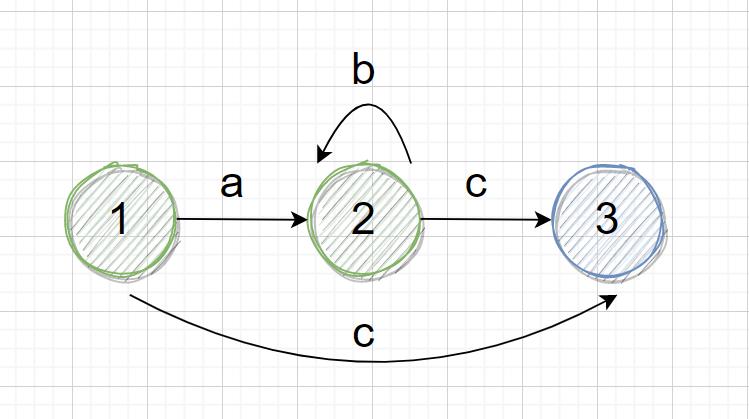
可以看到上图中,在状态 1 下,输入 a 可以到达状态 2,输入 c 可以到达状态 3,在状态 2 下,输入 b 还是在状态 2,输入 c 可以到达状态 3,其中的每一步状态转移都是确定的。
3.NFA原理
NFA 是非确定性有穷自动机的简称,和 DFA 相反,在某些状态的输入下,不能做确定性的状态转换,分为两种情况:
-
同一个输入字符,可以转换到不同的状态
-
接受空字符 ε,也就是不读入字符就跳转到另一个状态上
注:ε:epsilon,音标/ep’silon/,中文读音为“艾普西隆”
现在有这样一个需求,匹配以字母 a 开头,字母 b 结尾,中间是任意多(可以是 0 个)英文小写字母的字符串,我们可以很快的写出正则表达式 a[a-z]*b,看下状态图:
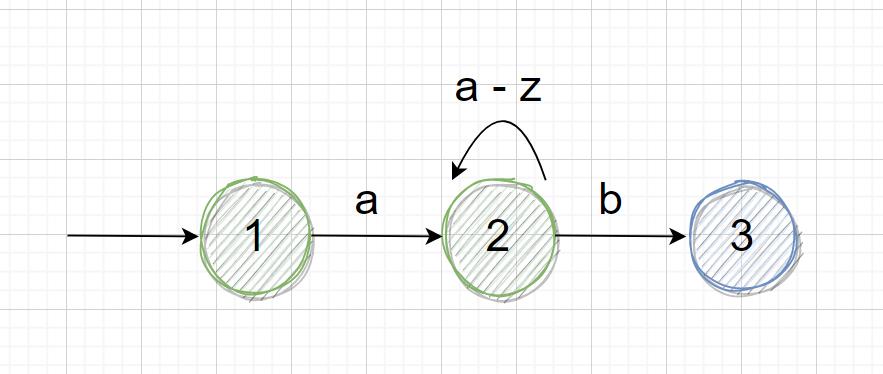
当要匹配的目标字符串是 aabb 时,在状态 1 下,输入 a 到达状态 2,在状态 2 下,输入第二个 a 还在状态 2,这个时候输入 b,既可以保持在状态 2 下,还可以转移到状态 3,这个时候状态是不确定的,只有输入第二个 b 之后,才能知道上一步应该向什么状态转移。
上面的状态图,还可以用 ε-NFA 来表示:
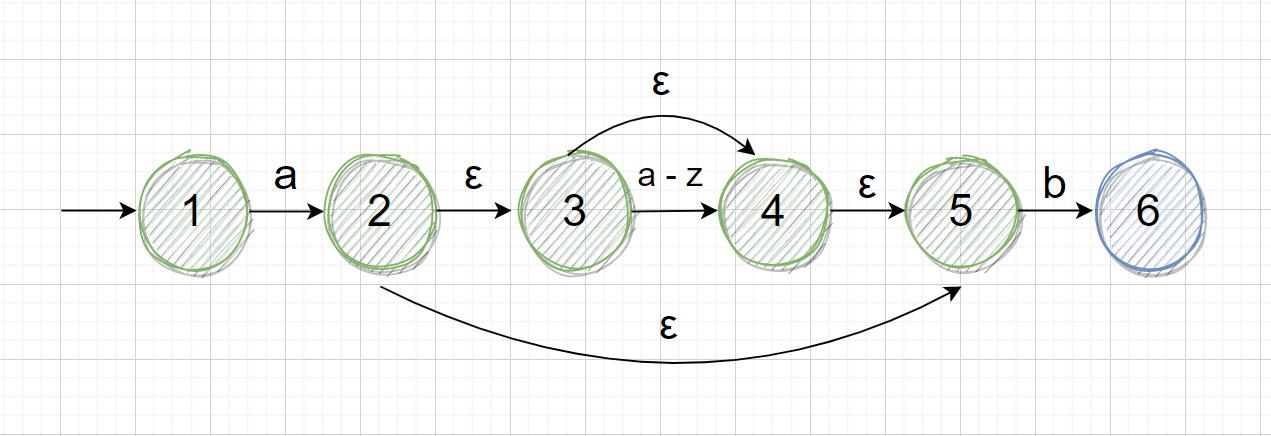
ε 代表空字符,如果要匹配的目标字符串是 ab,路径就是:状态1 —> a —> 状态2 —> ε —> 状态5 —> b —> 状态6
4.DFA工作机制
DFA 引擎的工作方式是,先看文本再看正则,以文本为主导,举个栗子:
目标字符串:Toady is such a beautiful day
正则表达式:beau(x|tify|tiful)
想象一下,你手里拿着一张彩票(文本),在看电视中的开奖号码(正则),看一眼第一个 T 不对,接着 o、a、d、y… 依次看下来,到了 b 终于对了一个,接着又对上了 e、a、u 三个字母,有戏:
text: Toady is such a beautiful day
^
regex: beau(x|tify|tiful)
^
继续往后看,彩票中 u 的后面是 t,看一眼开奖号码的三个奖项,一等奖 x 不符合,二等奖和三等奖都是以 t 开头的:
text: Toady is such a beautiful day
^
regex: beau(x|tify|tiful)
^ ^ ^
✘✔ ✔
接着看彩票的 i、f、u、l 部分,发现中了三等奖,Congratulations!
text: Toady is such a beautiful day
^
regex: beau(x|tify|tiful)
^ ^ ^
✘ ✘ ✔
可以发现,DFA 以文本为主导,目标字符串只看一遍,不会发生回溯,相同的字符不会被测试多次。
5.NFA工作机制
NFA 引擎的工作方式和 DFA 相反,是先看正则再看文本,以正则为主导,还是用上面的栗子。
这次是先看开奖号码(正则),再看你手里的彩票(文本),开奖号码第一个字母是 b,在彩票中找到了 b,接着看开奖号码后面的 e,看下彩票中 b 后面是 e,就这样找到了 beau:
regex: beau(x|tify|tiful)
^
text: Toady is such a beautiful day
^
接着再看彩票 beau 的后面是不是 x,发现不是,一等奖擦肩而过:
regex: beau(x|tify|tiful)
^
✘
text: Toady is such a beautiful day
^
继续看二等奖,开奖号码 t、i、f 都符合,到了 y 发现彩票里的是 u,二等奖擦肩而过:
regex: beau(x|tify|tiful)
^
✘
text: Toady is such a beautiful day
^
再看三等奖,重新从 t 开始比较(回溯,NFA 引擎会记住这里),发现都符合,又中奖了。
可以发现,NFA 以正则为主导,会发生回溯,目标字符串的同一部分,有可能会被反复测试很多次,因此,在最坏的情况下,它的执行速度可能会非常慢。
6.POSIX NFA
因为传统的 NFA 引擎急于报告匹配结果,找到第一个匹配上的就返回了,所以可能会导致还有更长的匹配未被发现,比如我们用正则 北京|北京市 来匹配文本 北京市,看下效果:
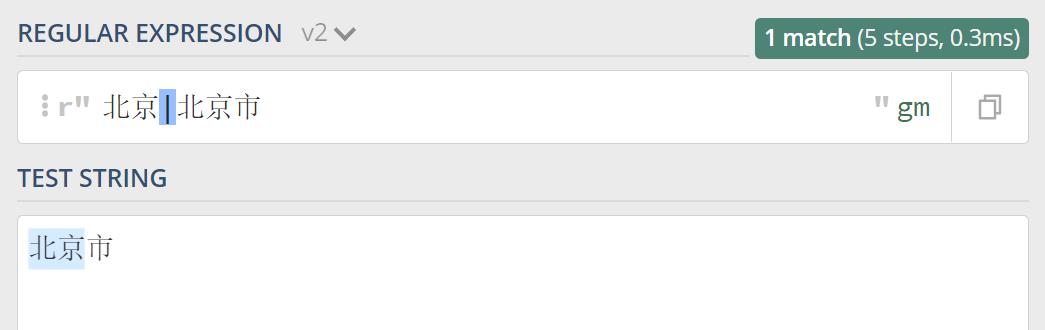
可以看到匹配到的结果是 北京,而 北京市 也是我们想要的匹配结果,并没有匹配上,这个时候 POSIX NFA 应运而生,它会在找到可能的最长匹配之前进行回溯,也就是说它会匹配最长的目标字符串,如果两边长度相同,则以左边的为准,所以POSIX NFA 引擎的速度要慢于传统的 NFA 引擎。
看下DFA、传统 NFA 以及 POSIX NFA 引擎的特点:
| 引擎类型 | 语言 | 忽略优先量词(懒惰) | 捕获型括号 | 回溯 |
|---|---|---|---|---|
| DFA | mysql、awk(大多数版本)、egrep(大多数版本)、 flex、lex、Procmail | 不支持 | 不支持 | 不支持 |
| 传统型 NFA | Golang、PCRE library、Perl、php、Java、Python、 Ruby、grep(大多数版本)、GNU Emacs、less、 more、.Net、sed(大多数版本)、vi | 支持 | 支持 | 支持 |
| POSIX NFA | mawk、Mortice Kern Systems`utilities、 GNU Emacs(明确指定时使用) | 不支持 | 不支持 | 支持 |
| DFA/NFA 混合 | GNU awk、GNU grep/egrep、Tcl | 支持 | 支持 | DFA 支持 |
7.写在最后
最后在总结下上面讲到的内容:
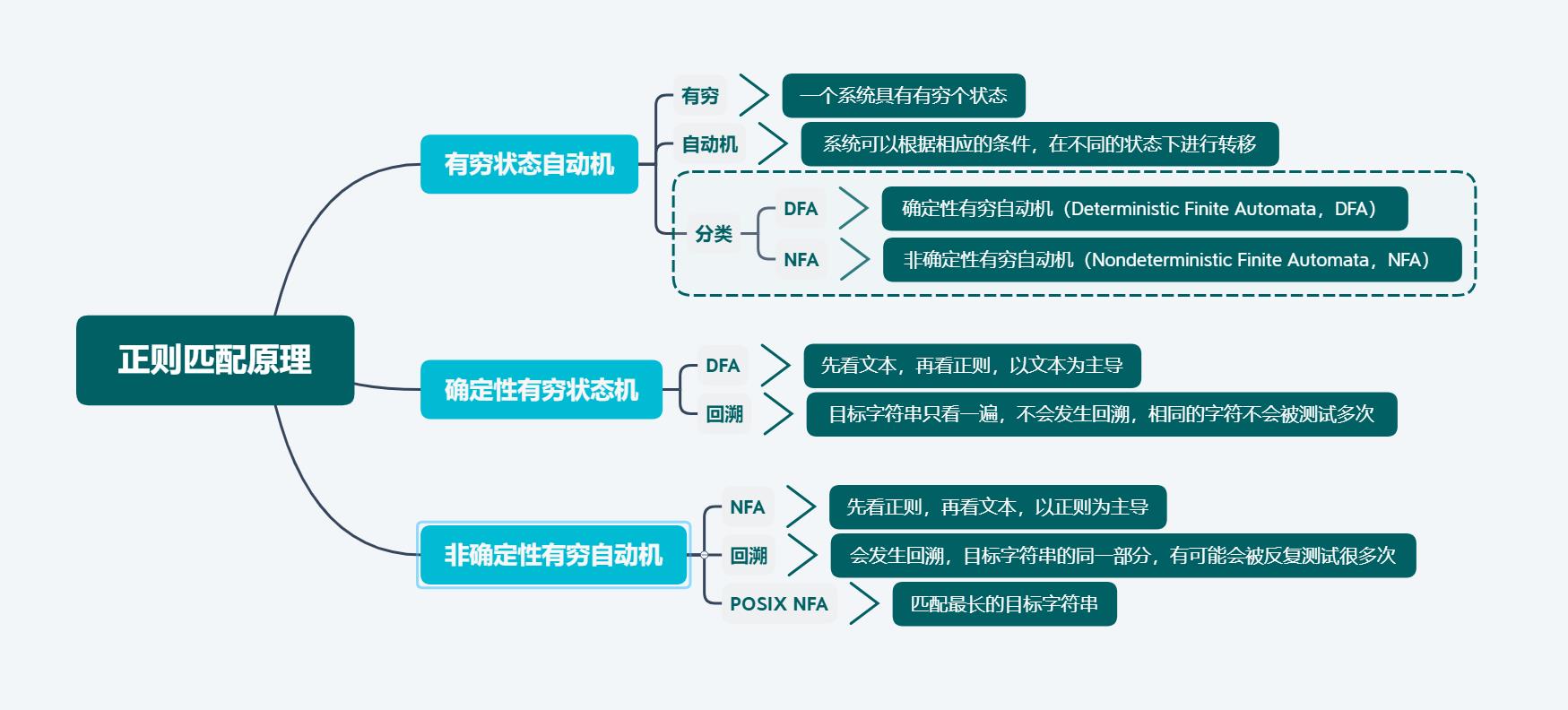
到这里,正则表达式的匹配原理就讲完了,如果有问题可以给我留言评论,谢谢。
正则表达式在线校验工具:https://regex101.com/
以上是关于一起学习正则表达式正则匹配原理的主要内容,如果未能解决你的问题,请参考以下文章