数据库-Elasticsearch进阶学习笔记(集群故障扩容简繁体拼音等)
Posted lady_killer9
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库-Elasticsearch进阶学习笔记(集群故障扩容简繁体拼音等)相关的知识,希望对你有一定的参考价值。
上篇文章主要分享了ES的高级搜索、核心概念,本篇对集群和分词器的使用做补充。
集群
集群配置
把之前的复制一份,删掉data和logs里面的文件
打开config里面的elasticsearch.yaml
- cluster.name:集群的名字,同一个集群的节点应该相同
- node.name:节点的名字,不同节点名字不同
- node.master:是否可以作为master节点,一般设置为true
- node.data:是否可以作为数据节点,一般设置为true
- network.host:主机地址
- http.port:访问端口
- transport.tcp.port:通信端口,没有的话添加一下
- http.cors.enabled:是否可以跨域
- http.cors.allow-origin:哪些源可以访问此节点
- discovery.seed_hosts:其他节点查找列表,格式:ip:通信端口
- discovery.zen.fd.ping_timeout:查找超时时间
- discovery.zen.fd.ping_retries:查找重试次数
单节点集群
我们之前使用的就是单节点的集群
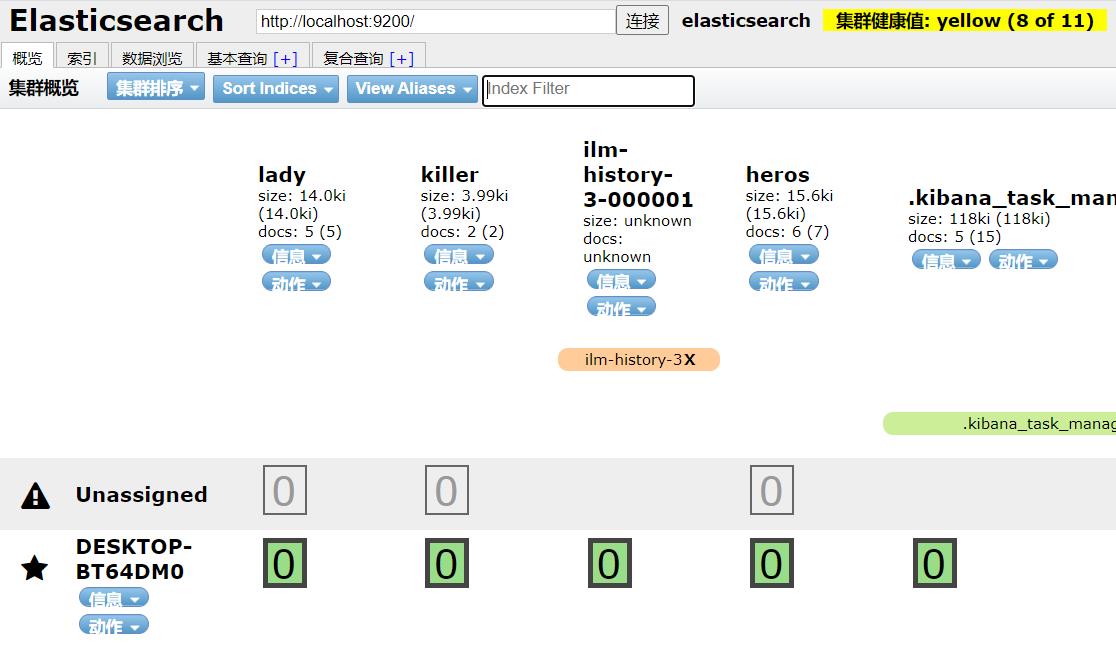
节点的健康状态有三个
- 绿色:健康
- 黄色:警告
- 红色:危险
上面是8/11,因为我们之前建了三个索引lady、killer、heros,他们默认是有一个副本,但是没有分配到节点,所以整体是黄色的。
分布式集群
本地配置如下
| 配置 | cluster.name | node.name | node.master | node.data | network.host | http.port | transport.tcp.port | discovery.seed_hosts | discovery.zen.fd.ping_timeout | discovery.zen.fd.ping_retries | http.cors.enabled | http.cors.allow-origin |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| node | my-application | node | true | true | localhost | 9200 | 9300 | [“localhost:9301”] | 1m | 5 | true | “*” |
| node-1 | my-application | node-1 | true | true | localhost | 9201 | 9301 | [“localhost:9300”] | 1m | 5 | true | “*” |
启动两个节点后再次查看集群
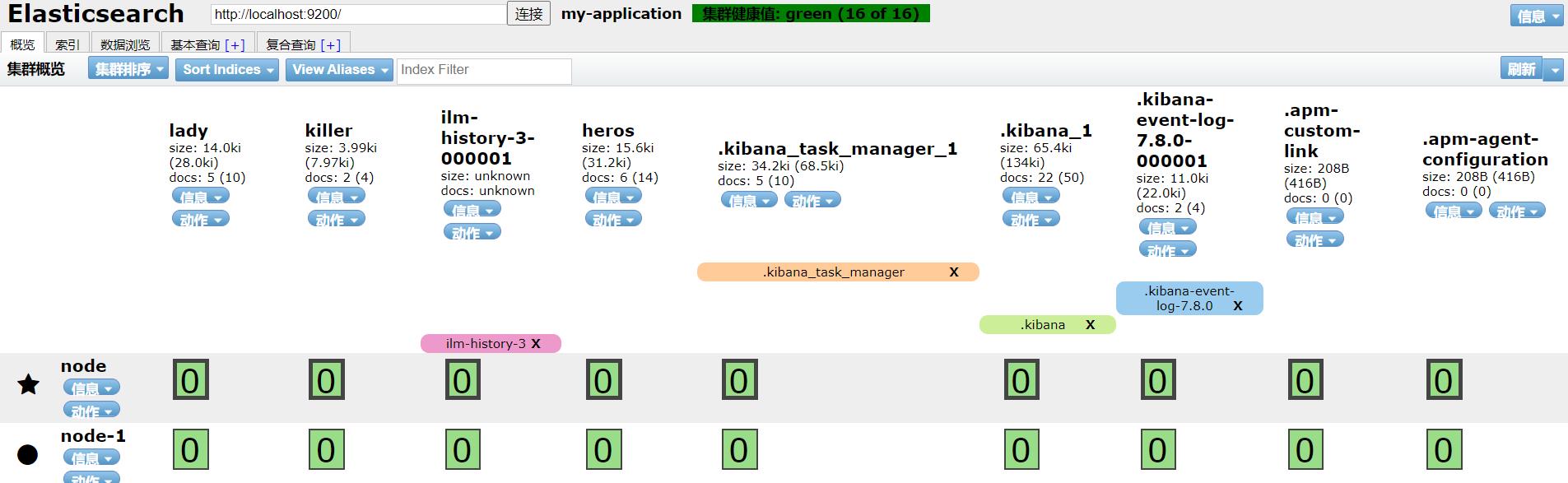
其中,星星代表主节点,原点代表数据节点。可以看到是健康的绿色。
查看腾讯云的集群状态
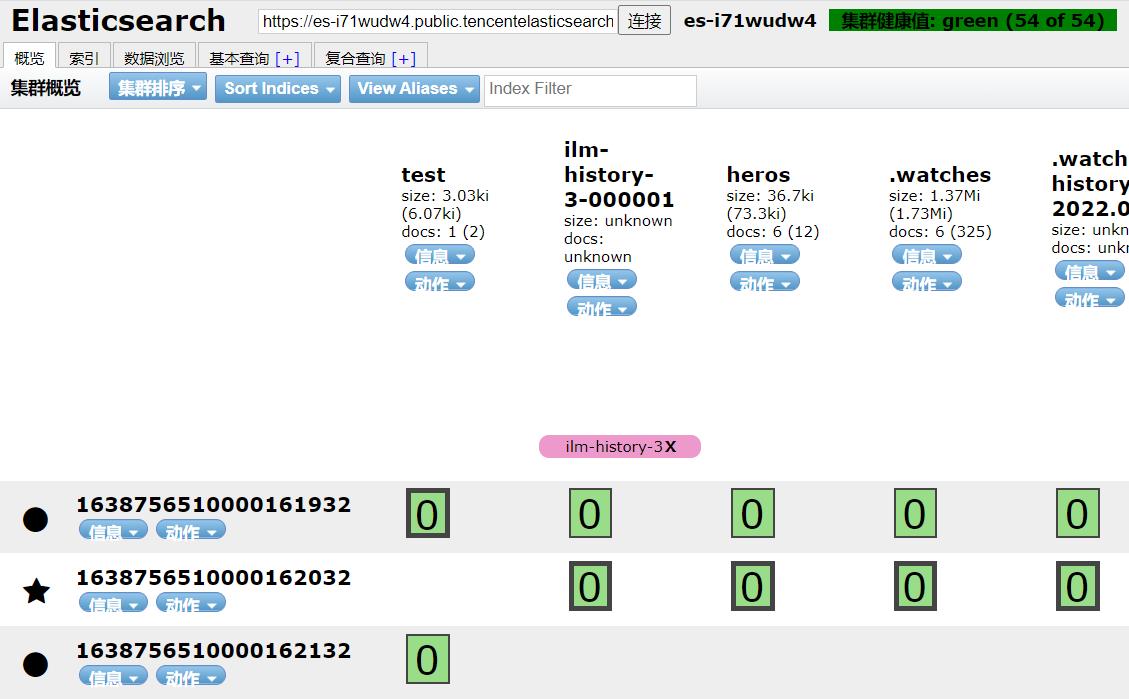
可以看到也是绿色的。
查看腾讯云ES的基础配置
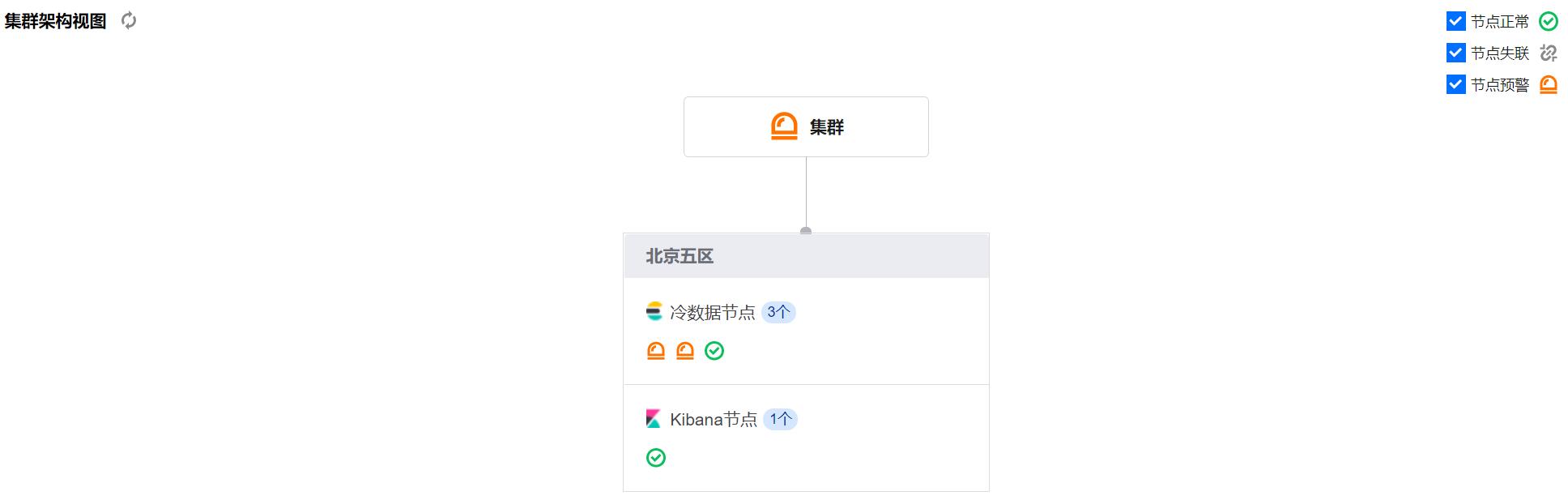
可以看到3个ES节点,一个Kibana节点。这个节点预警是可以自己在集群监控的告警策略设置的,一般与CPU、内存的使用情况相关,浏览器插件的黄色是节点是否宕机。
故障转移
集群中只有一个节点时,一旦出现故障,服务就无法保证了,需要有冗余。上面插件的截图中,绿色加粗框的分片是主分片,细的就是副本。当添加一个节点时,ES会自动根据索引的配置来分配副本所在节点,有节点宕机时,不影响,当主节点宕机时,会重新选择主节点(选择node.master为true的)
水平扩容
多启动一个节点,会分散负载,重新分配分片,保持负载平衡。例如,前面本地由黄色变绿色。
路由计算&分片控制
多个分片,增加或查询数据时,应该存放到哪个分片或从按个分片取数据,有一个规则,成为路由计算。
路由计算:使用Hash算法:hash(id)%主分片数量
查询数据时,不一定访问主节点或主分片,选择哪一个都可以,这个选择过程,称为分片控制。
分片控制:用户可以访问任何一个节点获取数据,一般采用轮询的方式,该节点称为协调节点,若处于繁忙状态,可将请求转发至其他节点。
数据CRUD流程
写流程
1.客户端请求集群协调节点
2.协调节点将请求转换到指定的节点
3.主分片需要将数据保存
4.主分片需要将数据发送个副本
5.副本保存后,进行反馈
6.主分片进行反馈
7.客户端获取反馈
读流程
1.客户端发送查询请求到协调节点
2.协调节点计算数据所在的分片以及全部的副本位置
3.为了能够负载均衡,可以轮询所有节点
4.将请求转发给具体的节点
5.节点返回查询结果,将结果反馈给客户端
更新流程
1.客户端向Node1发送更新请求。
2.它将请求转发到主分片所在的Node3。
3.Node3从主分片检索文档,修改_source字段中的JSON,并且尝试重新索引主分片的文档。如果文档已经被另一个进程修改,它会重试步骤3,超过retry_on_conflict次后放弃。
4.如果Node3成功地更新文档,它新版本的文档并行转发到Node1和Node2上的副本分片,重新建立索引。一旦所有副本分片都返回成功,Node3向协调节点也返回成功,协调节点向客户端返回成功。
删除流程
逻辑删除:在每个提交节点添加**.del**文件,列出被删除文档的段信息,搜索后筛选掉。
物理删除:多个倒排索引合并时,进行物理删除。
分词器
内置的分词器对中文不友好,只会一个字一个字的分,无法形成词语。对拼音也不行,无法拆分。
之前建立索引,使用的默认分词器,中文分词结果如下。
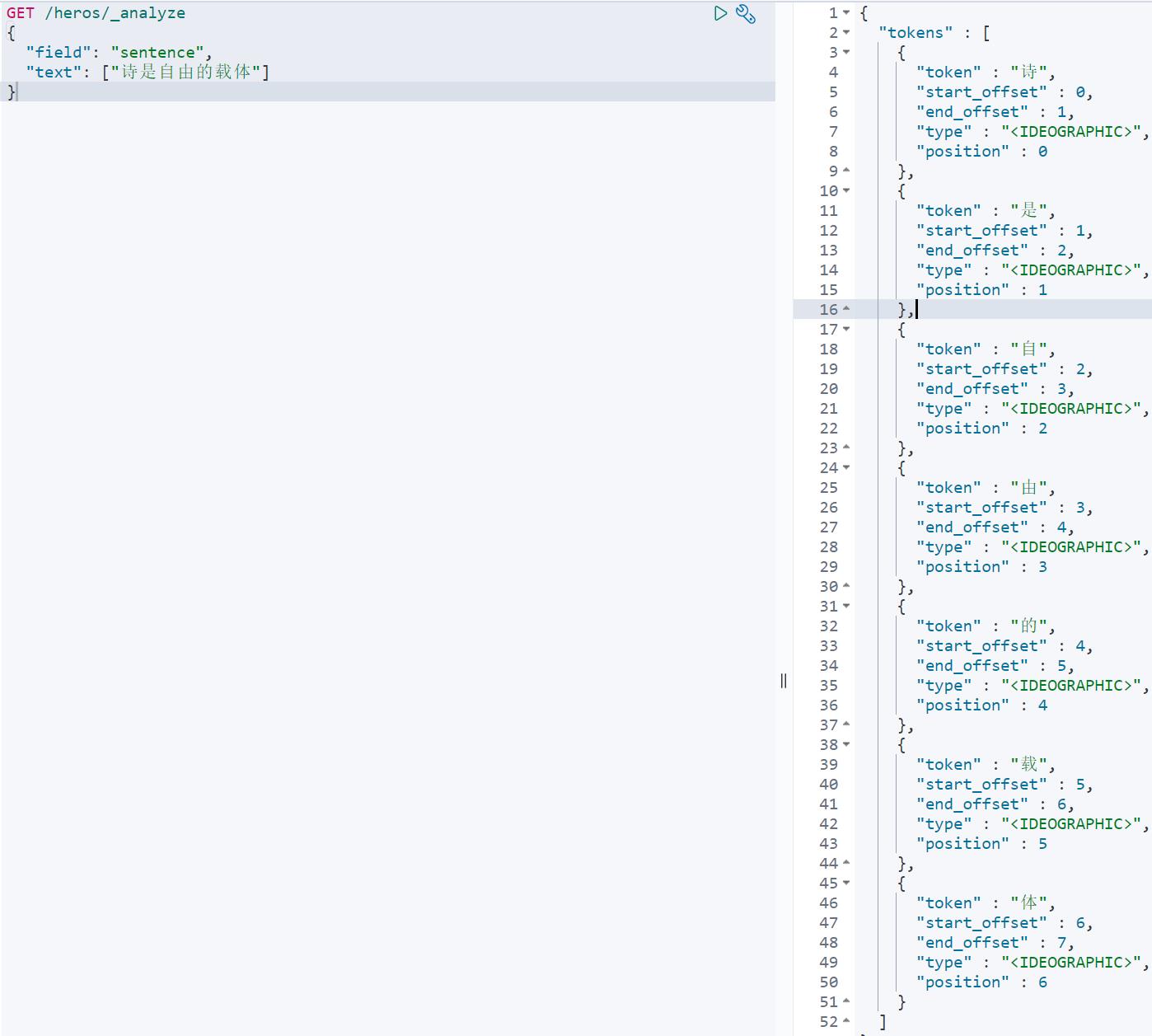
拼音分词结果如下

因为腾讯云的ES集群已经安装好了ik分词器、pin分词器和简繁体转换分词器,这里就不在本地演示了,可以去对应的github官网下载安装。
IK分词器
查看ik分词器官方文档,可以看到
Analyzer:
- ik_smart
- ik_max_word
Tokenizer:
- ik_smart
- ik_max_word
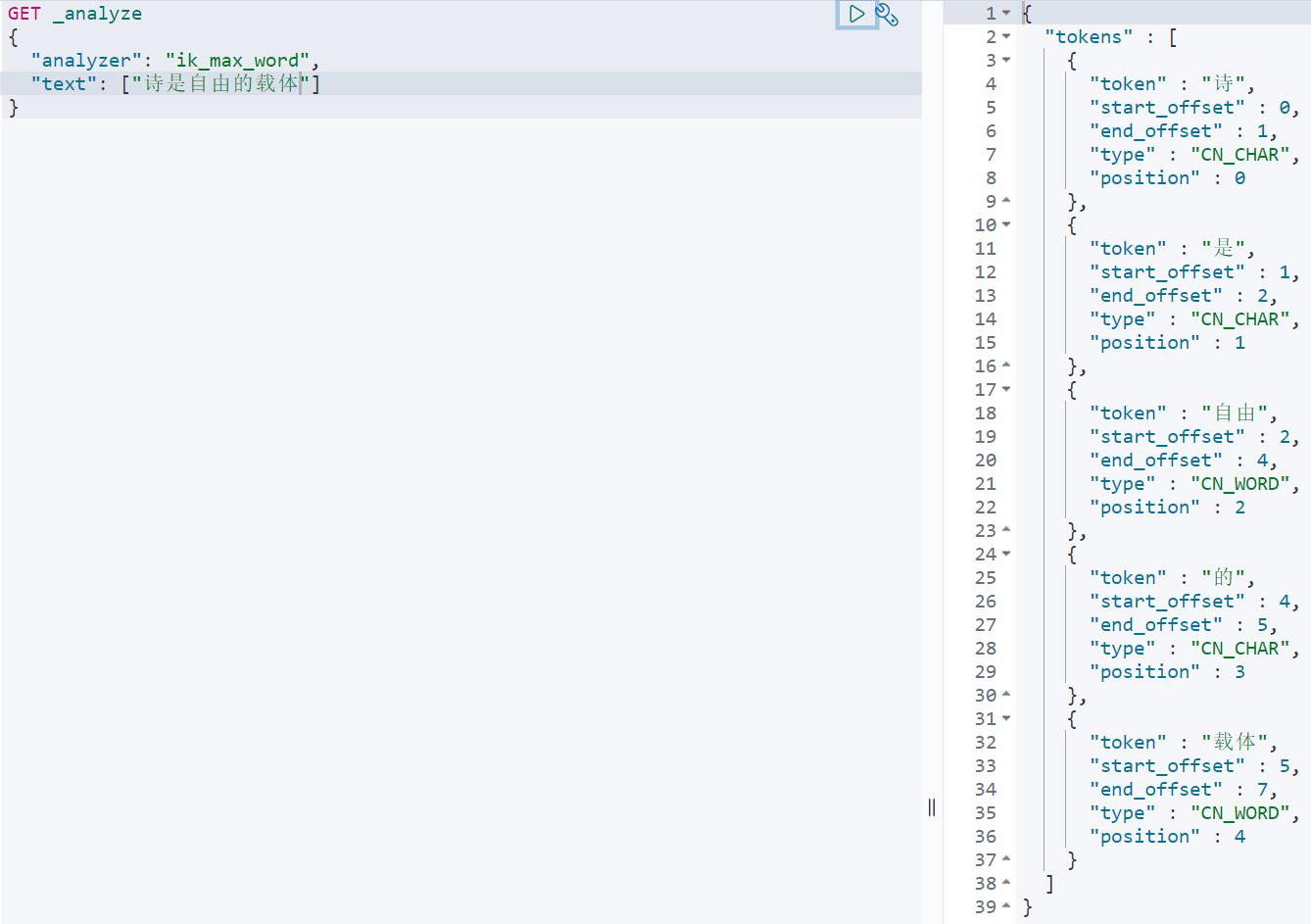
GET _analyze
"analyzer": "ik_max_word",
"text": ["诗是自由的载体"]
结果如下图所示
Pinyin分词器
Analyzer:
- pinyin ,
Tokenizer:
- pinyin
Token-filter:
- pinyin
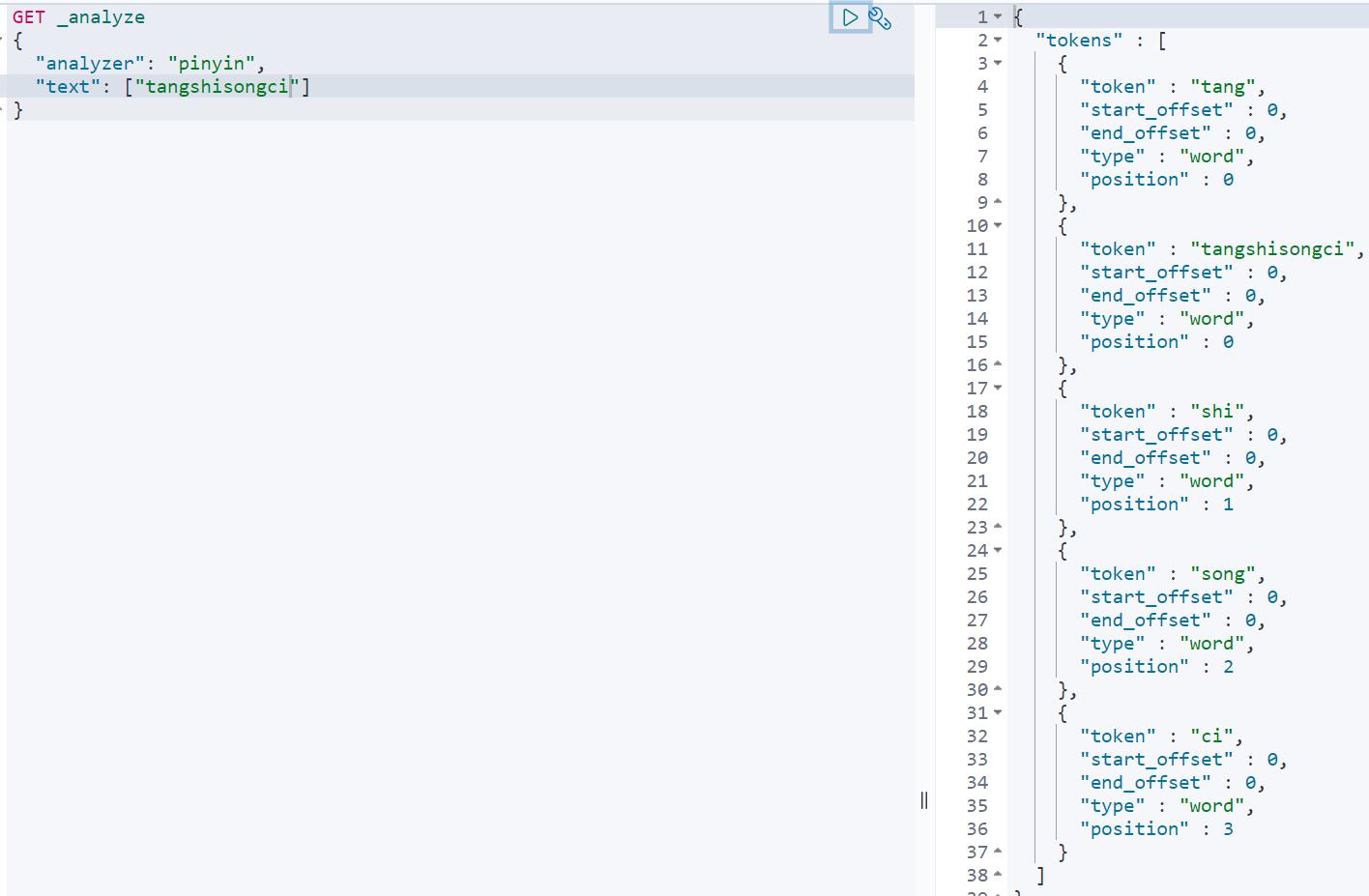
GET _analyze
"analyzer": "pinyin",
"text": ["tangshisongci"]
结果如下图所示
简繁体转换器
查看官方文档可以看到
Analyzer:
- stconvert
Tokenizer:
- stconvert
Token-filter:
- stconvert
Char-filter:
- stconvert
GET _analyze
"analyzer": "stconvert",
"text": ["我向往诗和远方,也不会忘记她和故乡"]
结果如下图所示

参考
IK分词器-GitHub
Pinyin分词器-GitHub
简繁体转换器-GitHub
更多ELK相关内容:数据库-ElasticSearch学习笔记_lady_killer9的博客-CSDN博客
喜欢本文的请动动小手点个赞,收藏一下,有问题请下方评论,转载请注明出处,并附有原文链接,谢谢!
如有侵权,请及时联系。如果您感觉有所收获,自愿打赏,可选择支付宝18833895206(小于),您的支持是我不断更新的动力。
以上是关于数据库-Elasticsearch进阶学习笔记(集群故障扩容简繁体拼音等)的主要内容,如果未能解决你的问题,请参考以下文章