[YOLO专题-6]:YOLO V3 - 网络结构原理改进的全新全面通俗结构化讲解
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[YOLO专题-6]:YOLO V3 - 网络结构原理改进的全新全面通俗结构化讲解相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/122226224
目录
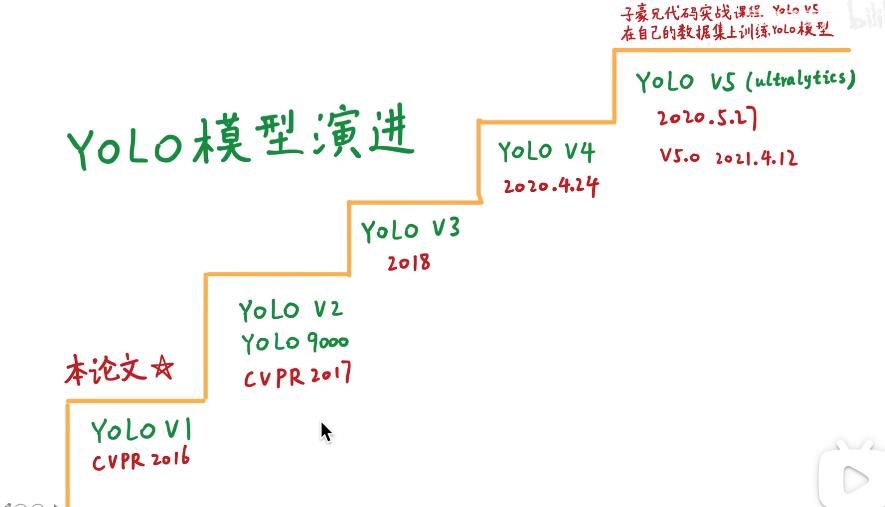
3.1 Darknet特征提取骨干网:V2 Darknet-19 =》 V3 Darknet-53
3.2 YOLO V2细粒度特征提取器Fine-Grained Features的缺点
3.3 YOLO V3多尺度multi-scale特征输出(这是YOLO V3最重要的改变)
前言:
本文重点讲解YOLO V3对YOLO V2的改进,而不是介绍整个V3网络的所有算法细节。
解读本文时,请先参考YOLO V2版本的解读。
YOLO V2是YOLO V3版本解读的基础, 而YOLO V1又是YOLO V2的基础。
YOLO V2版本详解:
https://blog.csdn.net/HiWangWenBing/article/details/122203173
YOLO V1详解:
https://blog.csdn.net/HiWangWenBing/article/details/122156426
第1章 YOLO V3应运而生
1.1 YOLO V2的不足
无论在速度和精度上,YOLO V2都超越了R-CNN系列算法了。
如果说YOLO V2有什么不足,那就是:速度和mAP和小目标可以进一步的改进,甚至超越人类 。
1.2 YOLO V3的出现
(1) YOLO V3相对于YOLO V2版本,也不过就是一年多的时间
YOLO V3重点:对小目标检测的优化上!
(2)YOLO V3在整个目标检测中的位置

1.3 YOLO V3的改进与优点

- 检测目标的数量得到了极大的提升:大目标507个,中目标2028个,小目标8112个。
- 达到了军事应用的水平(正是此原因,YOLO的作者决定放弃计算机视觉的研究,放弃YOLO的进一步更新,YOLO V4和V5的更新不是有原作者本人完成的)
1.4 YOLO总体的网络结构
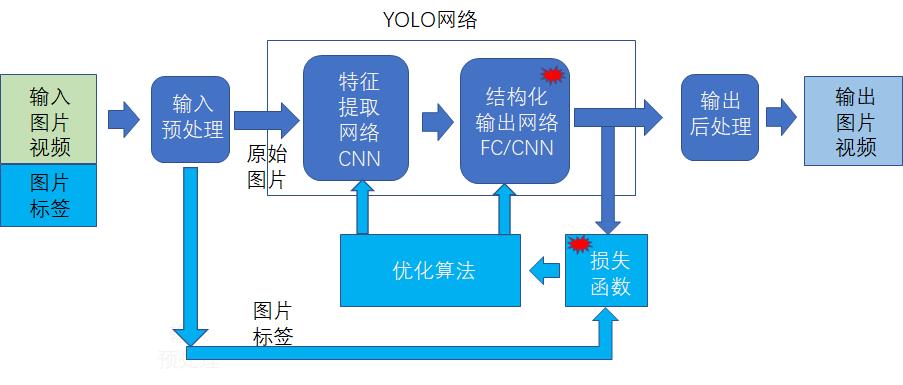
(1) YOLO的核心算法体现在:
- 结构化的输出定义
- 损失函数的设计
(2)与目标检测配套的地方体现在:
- 输入图片的标签:定位目标的手工定位信息 + 目标的分类类型
- 输出图片:原始图片 + 添加的额外信息(目标预测定位信息 + 目标类型 + 可能性大小)
1.5 YOLO V3的总体网络架构
(1)输入图片尺寸
- YOLO V1: 448 * 448 * 3
- YOLO V2: 416 * 416 * 3
- YOLO V3: 416 * 416 * 3
(2)特征提取的骨干网络
- YOLO V1: 普通的CNN网络
- YOLO V2: Darknet-19
- YOLO V3: Darknet-53
(3)输出网络
- YOLO V1: 全连接网络
- YOLO V2: 普通卷积网络
- YOLO V3: 特殊卷积网络
(4)输出尺寸
- YOLO V1: 7 * 7 * 1 * 30 # 30 = 5 + 5 + 20:分类
- YOLO V2:13 * 13 * 5 * 25 # 25 = 5:定位信息 + 20:分类
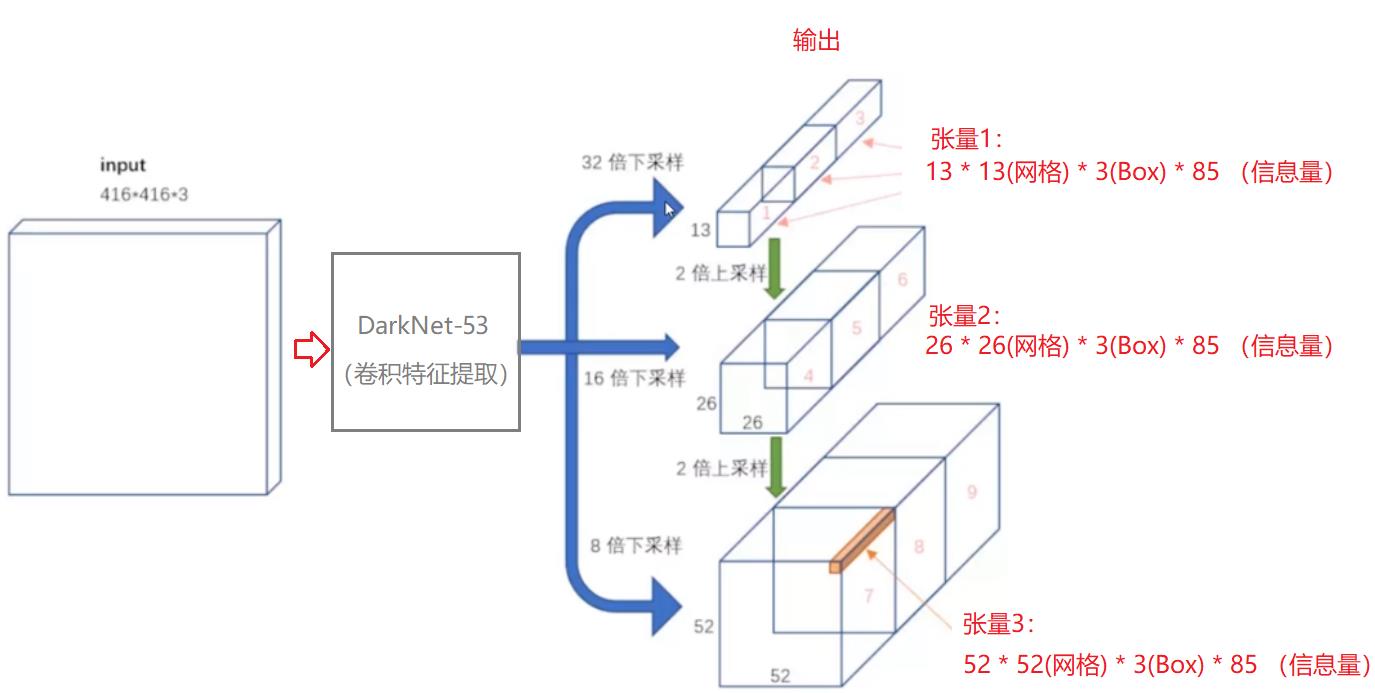
YOLO V3 同时输出三种格式:
- YOLO V3: 13 * 13 * 3 * 85 # 高层特征抽象, 5:定位信息 + 80:分类
- YOLO V3: 26 * 26 * 3 * 85 # 中层特征抽象, 5:定位信息 + 80:分类
- YOLO V3: 52 * 52 * 3 * 85 # 底层特征抽象, 5:定位信息 + 80:分类
第2章 YOLO V3网络的图片输入
2.1 输入图片的尺寸
- 同YOLO V2, 无改进
2.2 图片的标签改进
- 支持单个物体有多种标签
2.5 输入图片的预处理
无特别的地方,与其他网络一致。
第3章 YOLO V3前向特征提取网络
3.1 Darknet特征提取骨干网:V2 Darknet-19 =》 V3 Darknet-53
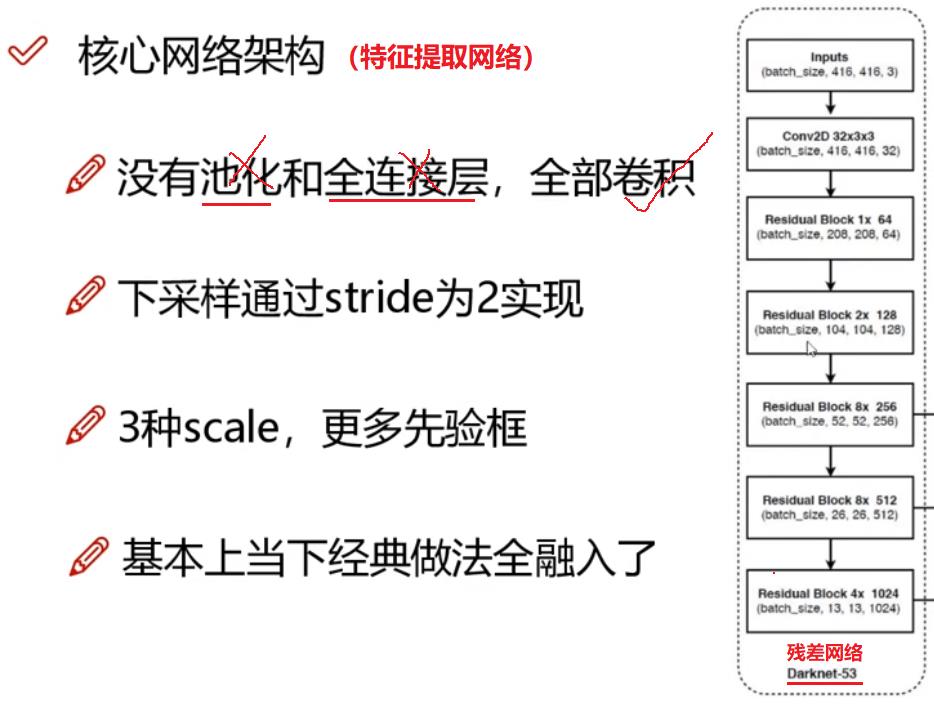
Darknet-53是一种残差网络(一种特殊的卷积网络),替代了Darknet-19普通的卷积网络。
关于残差网络的进一步细节,请参看:
https://blog.csdn.net/HiWangWenBing/article/details/120915279
3.2 YOLO V2细粒度特征提取器Fine-Grained Features的缺点
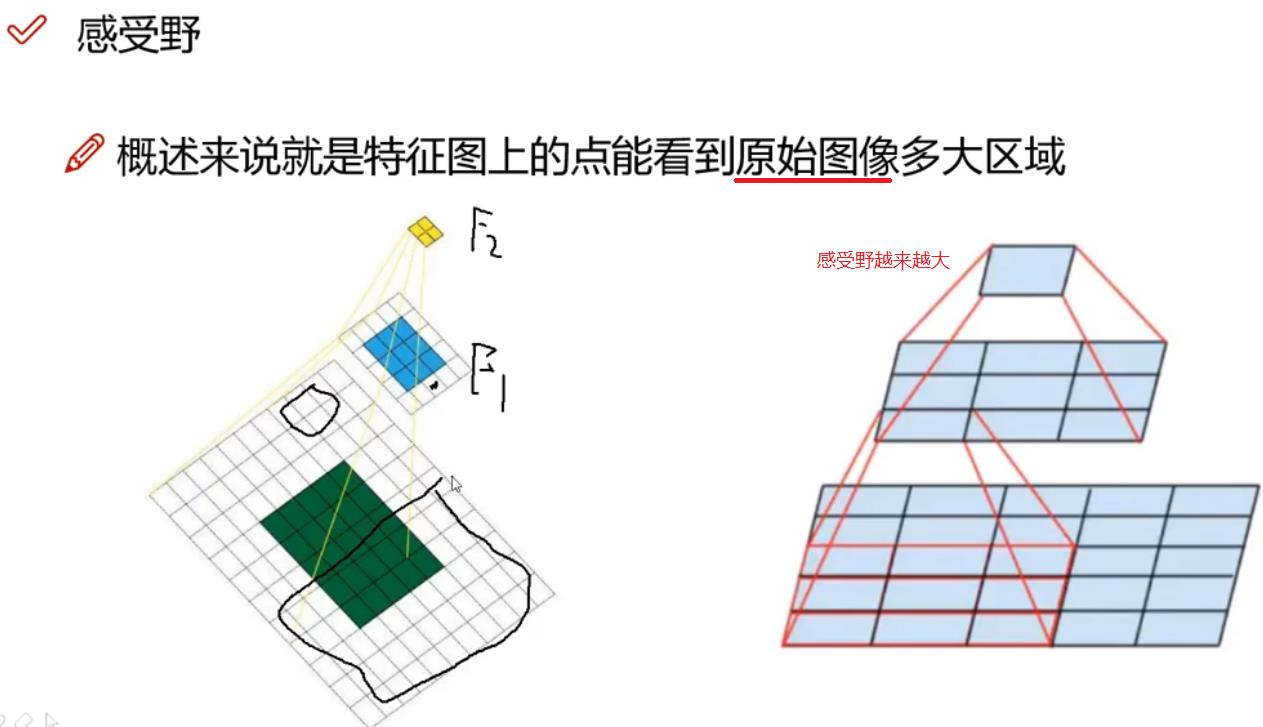
感受野反应了特征图上的一个点,能够感受到原始图像上像素点区域的大小,
越是接近输入端,特征图上的一个点的感受野越小,局部信息越多,宏观信息越少。
越是远离输入端,特征图上的一个点的感受野越大,局部信息越少,宏观信息越多。
为了支持小目标的识别,YOLO V2采用的pass through和concat组合方式来实现的,见下图。

这种方式,把pass through的局部特征,与Darknet输出的全局特征,通过concat组合或混合在一起,形成新的输入,送入到目标检测和分类网络中统一处理。
这种统一处理的缺点是:
大小目标的分类不够专业,没有专业化分工带来的效率上的提升。
因此YOLO V3借鉴YOLO V3借鉴了当时最新的多尺度特征输出思想。
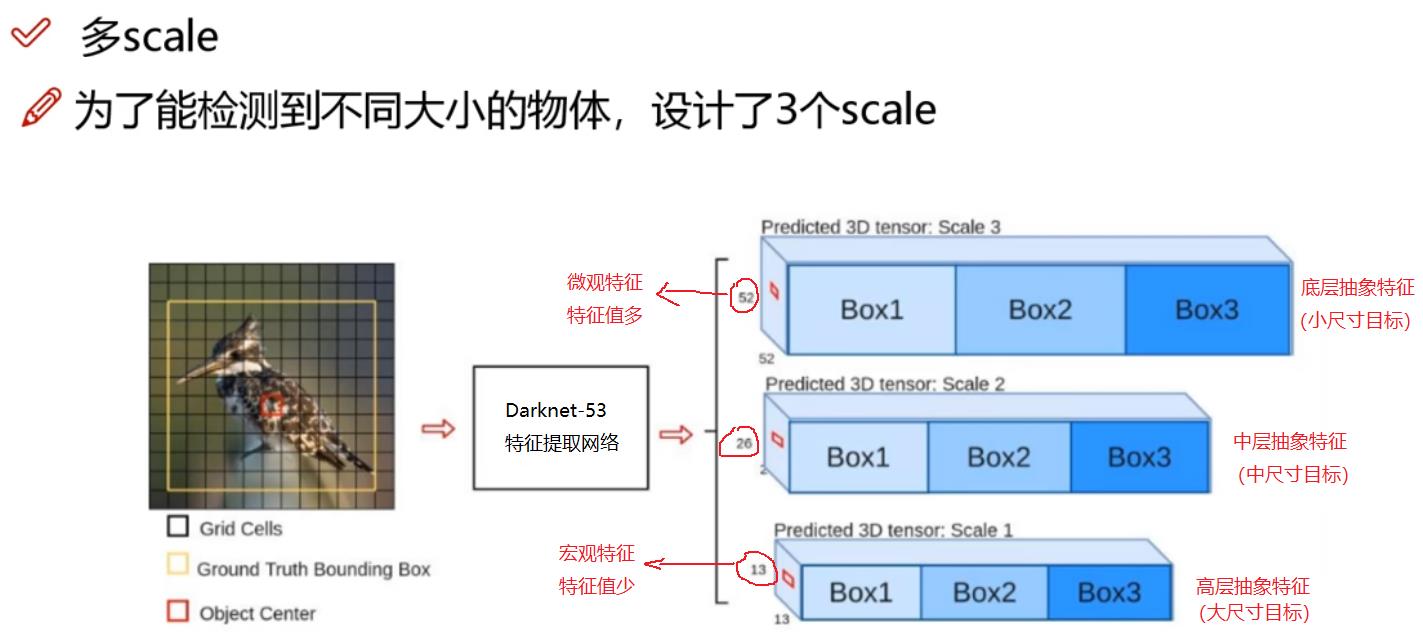
3.3 YOLO V3多尺度multi-scale特征输出(这是YOLO V3最重要的改变)
多尺度的核心思想是:专业化分工,即把提取的大、中、小目标的特征值分开处理,而不是混合在一起处理。具体方法有:
(1)单一输入法: YOLO V1采用的方法
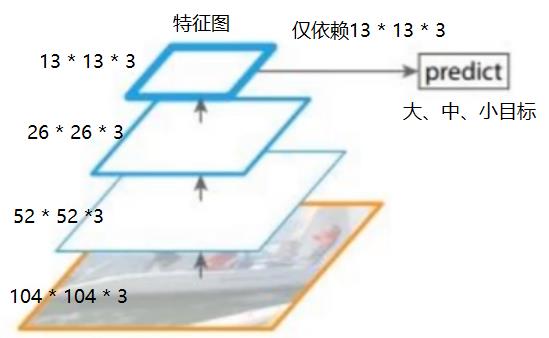
这是YOLO V1采用的方法,YOLO V1使用最后抽象的高层特征,统一对大、中、小目标进行预测。这种方法,不利于小目标的检测。
(2)Pass Through法: YOLO V2采用的方法
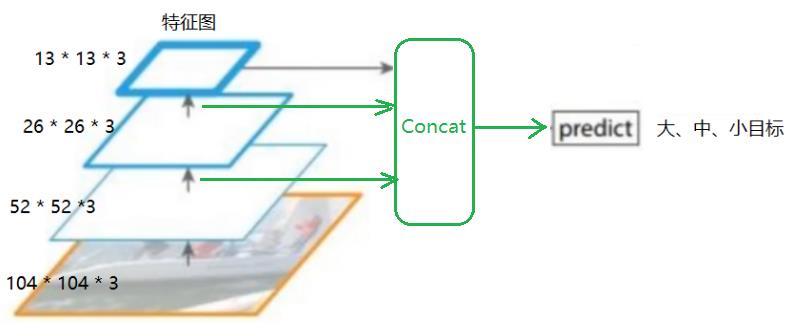
(3)图像特征金字塔法
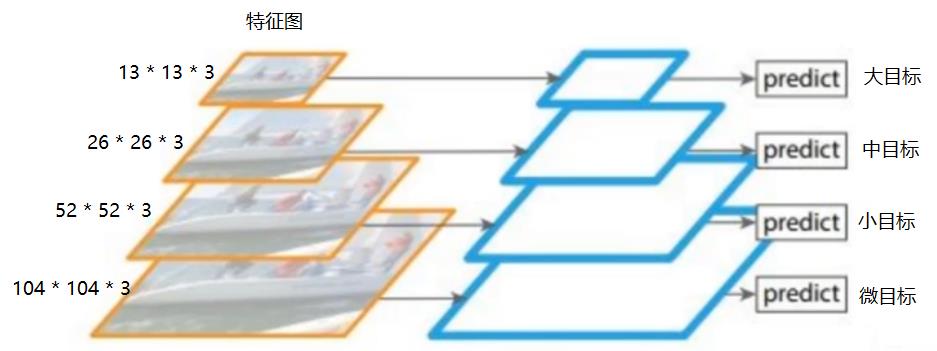
这种方法,不同抽象层,有不同的特征,每一层的特征本身相互独立,使用独立的预测器进行独立预测。不同抽象程度的特征之间没有关联,导致高层特征导致重复计算低层特征,浪费计算资源。
(4)图像特征金字塔优化法
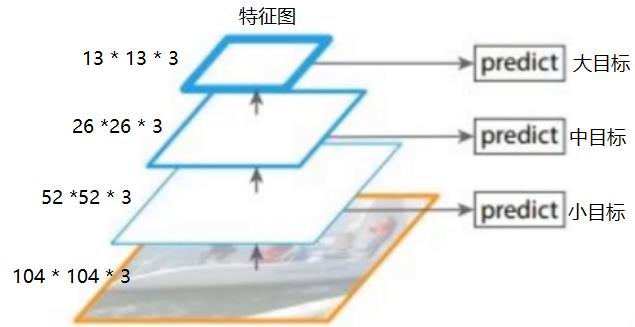
通常情况下,高层特征依赖于低层特征的计算,为了避免特征图的重复计算,天然地利用了神经网络的架构本身的特点。
- 特征图的计算上:高层特征依赖底层特征,高层特征是底层特征的进一步抽象,这样就串联特征图就串联了起来。
- 特征图的使用上:针对不同的目标,使用不同的预测器,不同的预测器使用不同层的特征图作为输入。
(6)回馈法 -- YOLO V3采用的方法
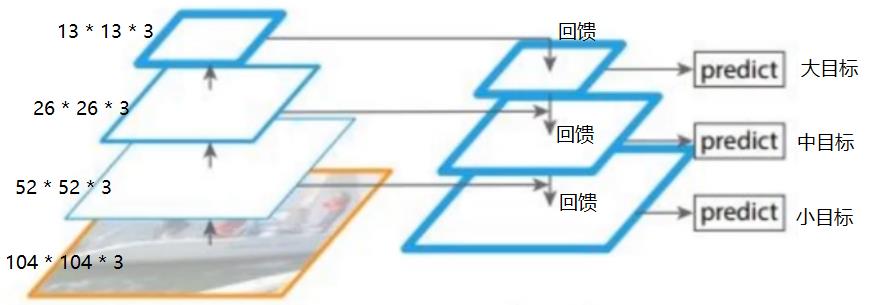
回馈法最重要的特征:回馈。
- 对于大目标,只需要最高层的特征,这里是13 * 13 * 3.
- 对于中目标,除了利用本层的特征26 * 26 * 3外,还需要利用高层反馈的特征13 * 13 * 3,这样,中目标的预测,不仅仅依赖中目标的特征图,还依赖更高层、更全局的特征,这样判决就根据准确。
- 对于小目标,除了利用本层的特征52 * 52 * 3外,还需要利用中层反馈的特征26 * 26 * 3。这样,小目标的预测,不仅仅依赖小目标的局部特征图,还依赖更高层、更全局的特征,这样判决就根据准确。
回馈法:使得小目标的检测,不仅仅取决于小目标自身的全部特征,还取决于小目标所处的环境特征,使得小目标的检测更加的精确与完美。

YOLO V3正是采用了此方法。
更详细的特征反馈连接如下图所示:
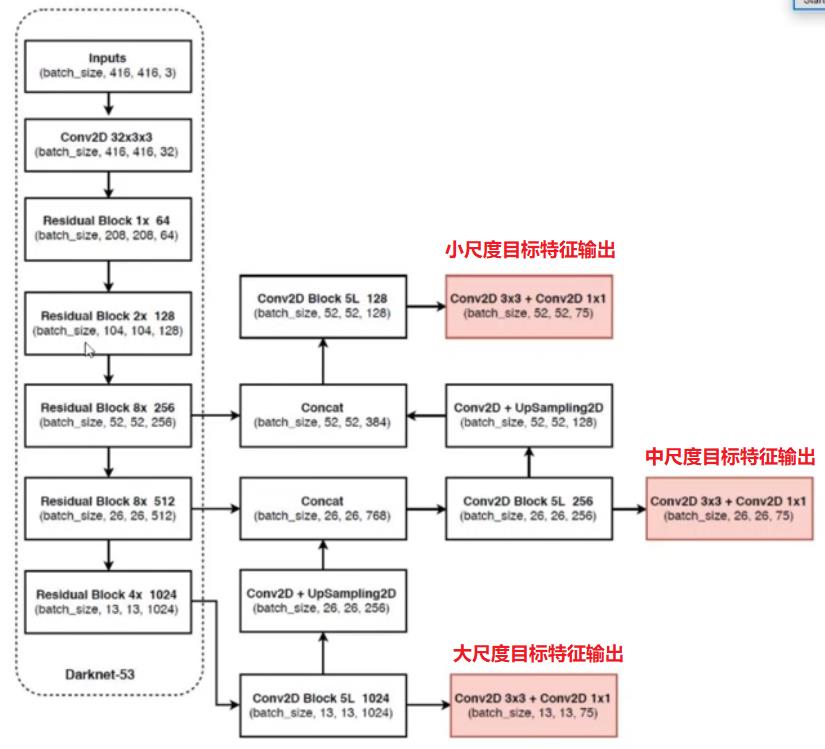
第4章 YOLO V3的前向输出网络
4.1 YOLO V3前向输出网络
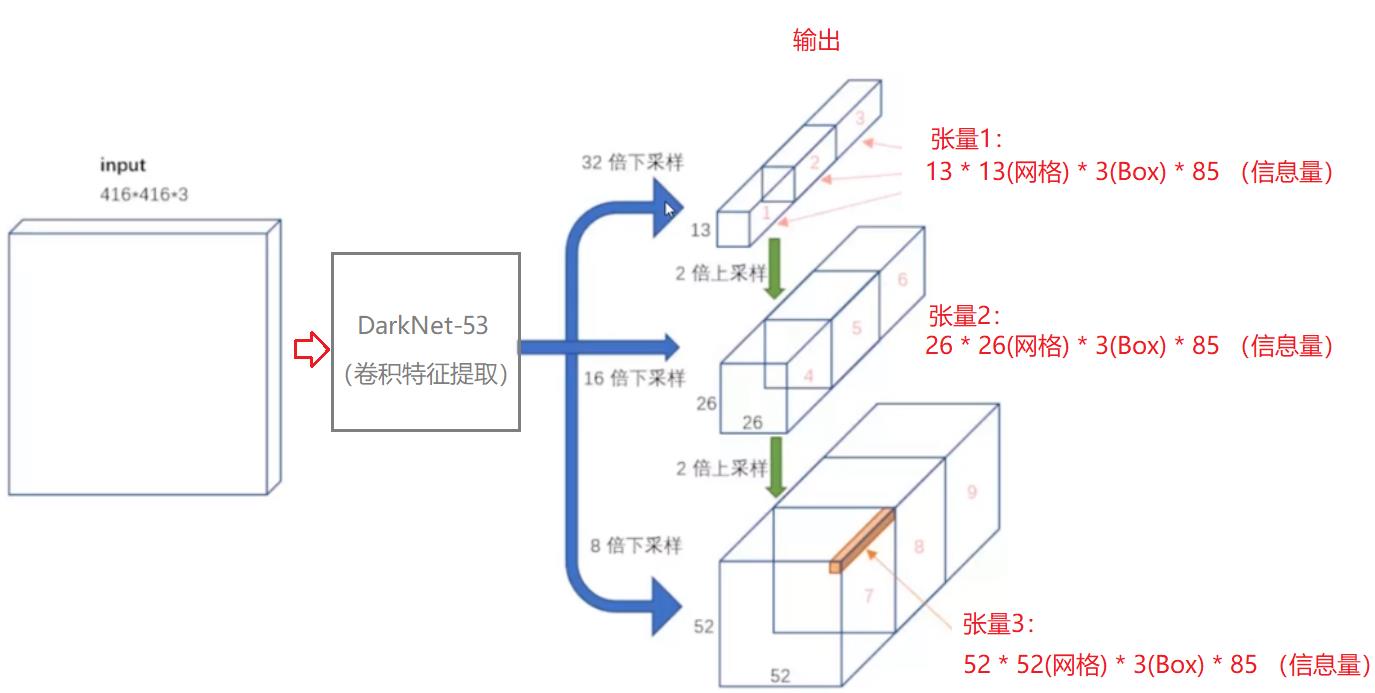
YOLO V3的前向输出,不是简单的单一尺寸的输出。
它三种不同张量的结构化输出(结构体Struct,而不是联合体Union)
- 13 * 13 * 3 * 85 # 高层特征抽象, 5:定位信息 + 80:分类
- 26 * 26 * 3 * 85 # 中层特征抽象, 5:定位信息 + 80:分类
- 52 * 52 * 3 * 85 # 底层特征抽象, 5:定位信息 + 80:分类
因此,YOLO V3的输出张量的结构化信息量远远大于 YOLO V1和YOLO V2
- YOLO V1: 7 * 7 * 1 * 30 # 30 = 5 + 5 + 20:分类
- YOLO V2:13 * 13 * 5 * 25 # 25 = 5:定位信息 + 20:分类
4.2 YOLO V3图片网格的切分
YOLO V1的网格: 7 * 7, 每个网格指定2个Bounding Box,同时能够检测49个目标。
YOLO V2的网格: 13 * 13,每个网格指定5个Bounding Box,同时能检测845个目标。
YOLO V3的网格: 没有采用单一的切分,而是采用了3层的网格切分
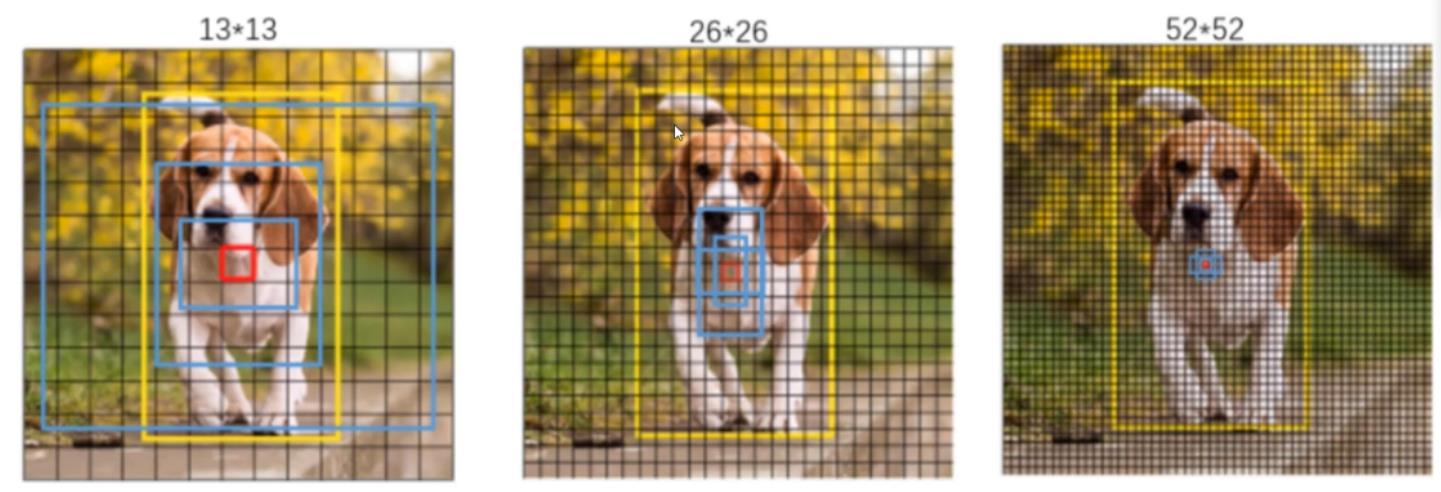
- 高层:13 * 13, 每个网格指定3个Bounding Box,用于大目标检测,同时能检查13 * 13 * 3 = 507个大目标。
- 中层:26 * 26, 每个网格指定3个Bounding Box,用于中目标检测,同时能检查26 * 26 * 3 = 26 * 26 * 3 = 2028个中目标。
- 底层:52 * 52, 每个网格指定3个Bounding Box,用于小目标检测,同时能检查52 * 52 * 3 = 52 * 52 * 3 = 8112个小目标。
这样,网格的总数 = 13 * 13 + 26 * 26 + 52 * 52 = 169(适合大目标) + 676(适合中目标) + 2704(适合小 目标)。
4.3 YOLO V3的Bounding Box
(1)每个网格Bounding Box的个数
每个网格Bounding Box的个数从YOLO V2的5个降到YOLO V3的3个。
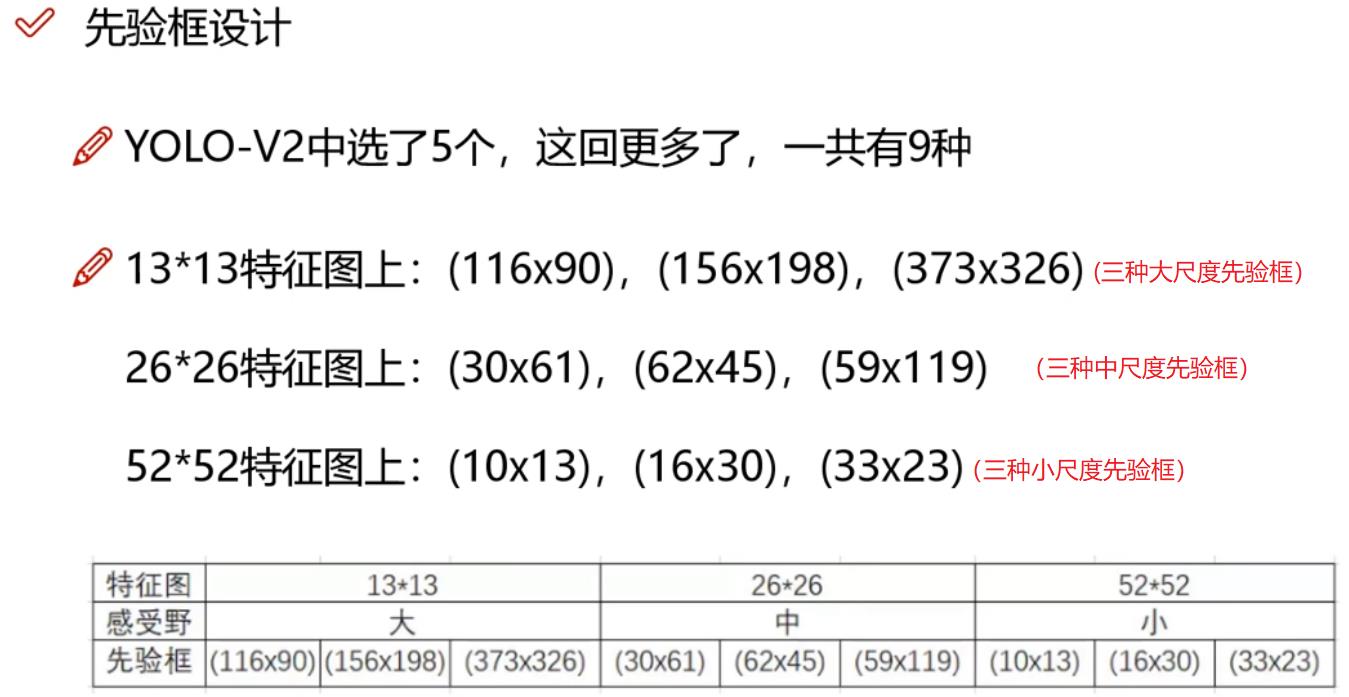
(2)Bounding Box的分类:9种
Bounding Box的分类与网格的分层是对应的。
先把Bounding Box分为3层:大、中、小三层。
三层Bounding Box,根据其输入特征的不同,他们有着不同的、专业化的职责。
三层Bounding Box,其输入分别来自于multi-scale特征输出的三种不同层面的特征。
每层Bounding Box内部,又进一步分为3种,微尺度变化的Bounding Box。
因此,Bounding Box的种类是: 3 * 3 = 9种类型。
(3)Bounding Box的总数
- 高层:网格个数=13 * 13,Bounding Box个数=13 * 13 * 3 = 507个
- 中层:网格个数=26 * 26,Bounding Box个数=26 * 26 * 3 = 2028个
- 底层:网格个数=52 * 52,Bounding Box个数=52 * 52 * 3 = 8112个
Bounding Box总数 = 507 + 2028 + 8112 = 10647个
4.4 先验框Anchor
根据所有样本图片的尺寸,先分聚合层三大类,每个大类再聚合成3个小类。
如下是:先验框在某个数据集上聚合之后的一个实际案例。
4.5 每个Box包含的结构化信息
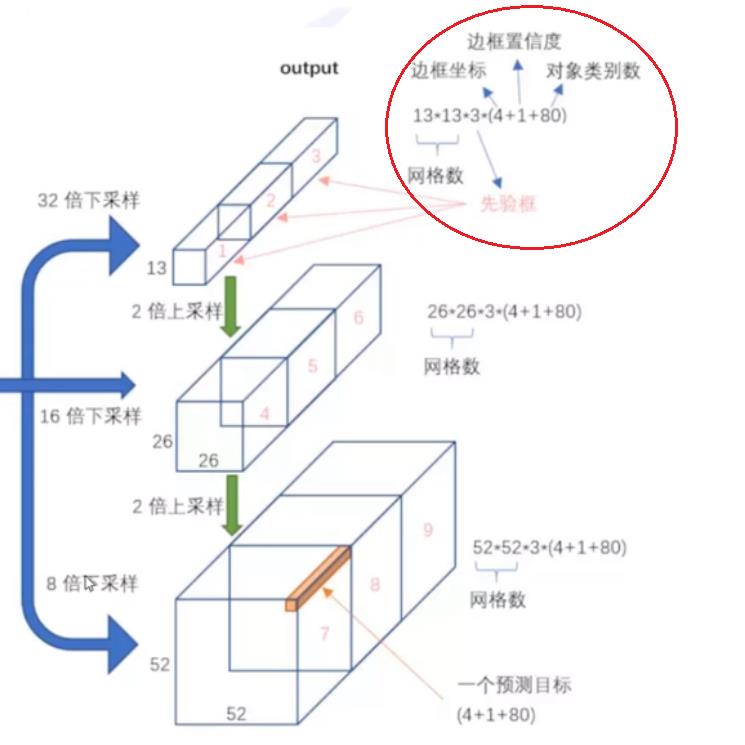
4.6 每个域的含义
与YOLO V1和V2含义相同:
- 定位框的中心点位置信息(x,y)
- 定位框的形状尺寸信息(w,h)
- 定位框是否包含物体的置信度信息(c)
- 定位框包含的物体的分类信息
4.7 SoftMax的替换:支持多标签
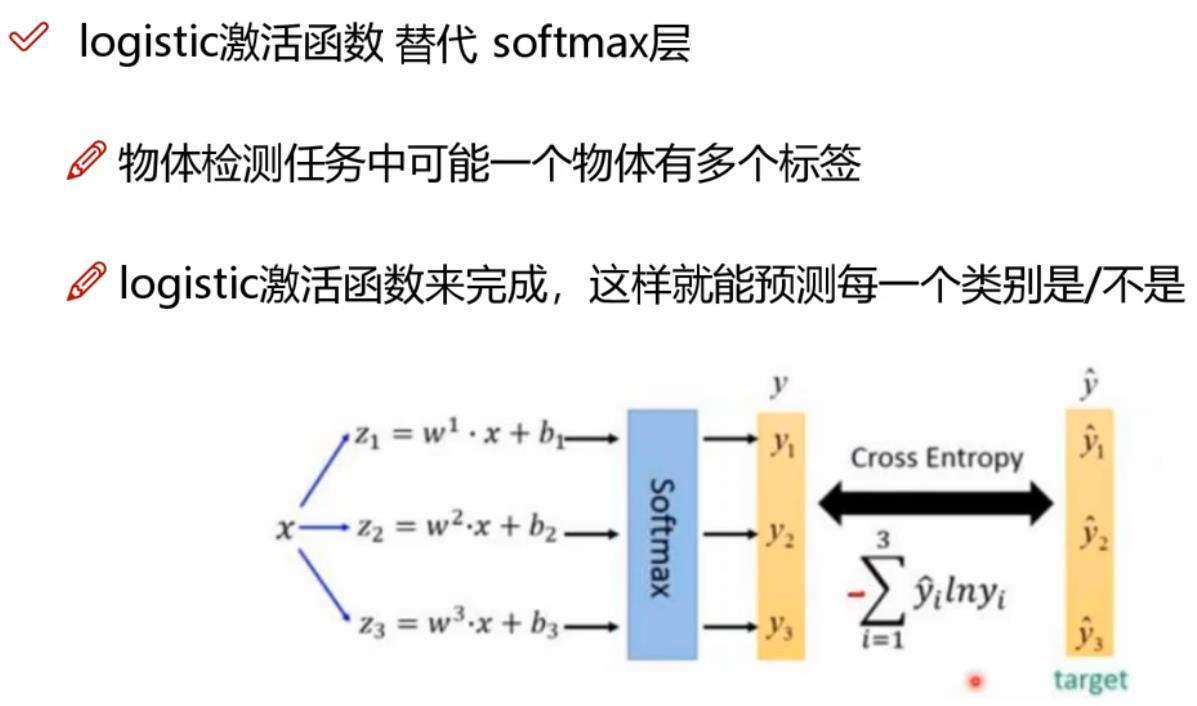
Softmax实现物体单分类最后的评判, Softmax能够确保所有物体的预测概率之和为1,比如一个物体的预测是狗的概率是80%,那么是其他物体的概率之和为20%。这就是单标签概率。
然后,对于多标签预测,比如,一个物体是狗的概率是80%,是狼狗的概率是70%,是猎狗的概率是75%,像这样的分类判决,Softmax就无法胜任了。
YOLO V3使用了logistic激活函数替换了softmax函数,把物体的联合的多分类,变成独立的二分类,从而实现对物体多标签的支持。
第5章 前向输出(预测阶段)后处理:NMS非极大值抑制处理
同YOLO V2
第6章 YOLO V3反向Loss计算与网络优化训练
6.1 Loss函数的设计(核心、核心、核心)
同YOLO V2
6.2 优化算法
YOLO并没有引入新的优化算法,梯度下降法等优化算法,也普遍适应于YOLO目标检测。
同YOLO V2
第7章 YOLO V3的不足与改进
(1)YOLO V3主要的目标是提升检测目标的数量,特别是小目标的数量,牺牲了一定的速度和mAP.
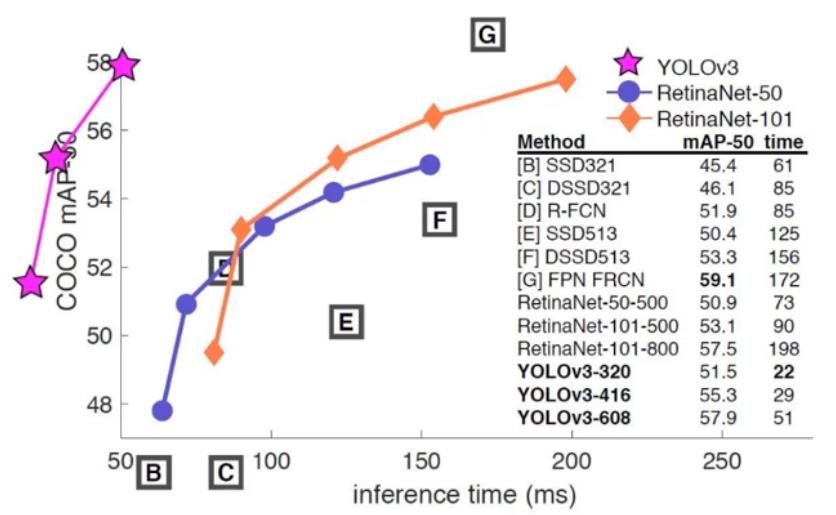
(2)硬件环境要求高
YOLO V3网络比较复杂,对GPU的训练环境要求比较高,一般单机无法训练。
参考视频:
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/122226224
以上是关于[YOLO专题-6]:YOLO V3 - 网络结构原理改进的全新全面通俗结构化讲解的主要内容,如果未能解决你的问题,请参考以下文章