[YOLO专题-11]:YOLO V5 - ultralytics/train基于自定义图片数据集重新训练网络, 完成自己的目标检测
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[YOLO专题-11]:YOLO V5 - ultralytics/train基于自定义图片数据集重新训练网络, 完成自己的目标检测相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/122150460
目录
步骤4: 为新数据集创建新配置文件或修改已有配置文件:xxxdataset.yaml
前言:
为什么不使用官网的数据集进行训练呢?
主要原因有两个:
(1)COCO和VOC数据集太大,用于个人学习训练的话,时间太长,预计要1个星期才能训练完成。
(2)用YOLO进行目标检测,在多数时候,我们自己的图片数据集与YOLO官方提供的预训练模型所对应的数据集是不相同的。
主要区别在于:
- 数据集图片的种类不同,自定义图片的种类有多有少,这个差别导致需要重新定义输出层。
- 数据集图片的内容不同,这与我们特定的业务强相关,特定业务所需要的图片, 与YOLO的数据集是不完全相同的,甚至相差很大。
- 数据集图片的背景不同,即使目标检测了类型相同,实际目标所处的环境也不一定相同。
这些就导致,我们需要基于YOLO官方预训练好的权重参数(预训练模型),然后,根据自身数据集的需求,重新训练YOLO模型的权重参数,最终才能满足我们自身业务的需求。
因此,我们首先从训练自己的数据集集开始。
要达成上述目标,具体步骤如下(本文重点讲解YOLO的使用方法,不讲原理):
官网手册:Train Custom Data 📌 - YOLOv5 Documentation
步骤1:下载对应版本的YOLO开源代码
1.1 github链接
登录github主页:https://github.com/search?q=PYTORCH++YOLOV5,所搜 “pytorch yolov5”
得到如下的信息:
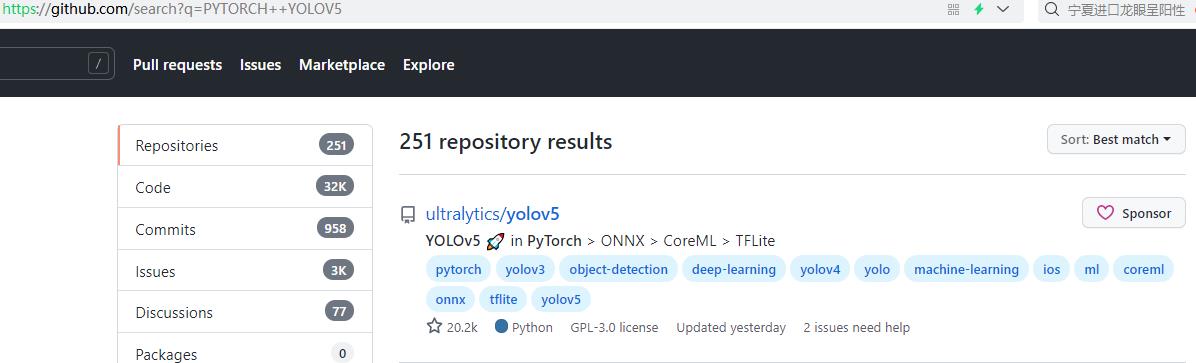
 https://github.com/ultralytics/yolov5
https://github.com/ultralytics/yolov5YOLO V5是按照项目管理的方式发布yolo v5的源代码的,yolo v5有不同 release tag,可以按照tag下载不同的release 版本,也可以直接下载master branch上的最新版本。
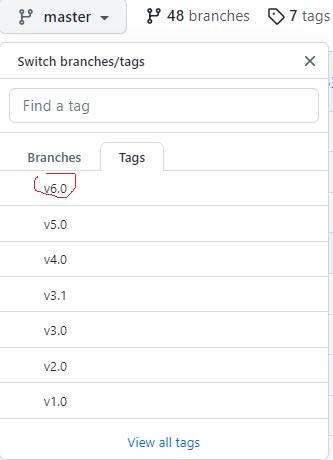
1.2 下载
1.3 拷贝到Pycharm工程目录中
cp
cd yolov5
$ pip install -r requirements.txt # install步骤2: 下载或创建自定义数据集
YOLO V5官方的开源代码,不自带数据集本身,需要程序员自己下载或创建数据集。
有几种方式创建数据集:
- 下载已经标注过的开源数据集:网络中有大量的免费或收费的数据集
- 制作自己的数据集:需要自己创建文件、标签
2.1 下载COCO128数据集(可选之一)
(1)从官网下载COCO128
COCO128是一个小型教程数据集,由COCO train2017中的前 128 张图像组成。这些128 张图像用于训练和验证,以验证我们的训练效果。
我们可以通过官网下载下载COCO128数据集, 需要先申请账号。
(2)从其他途径,如CSDN下载COCO128
我们也可以通过CSDN下载,有人在CSDN上提供了已经通过官网下载的COCO128数据集。
coco128.zip_coco128,coco128数据集-机器学习文档类资源-CSDN下载
2.2 从其他网站下载所需要的开源数据集(可选之一)
如下网站提供了大量的小型的已经打好标准的自定义数据集,我们可以直接利用这些数据集,这样可以节省大量需要我们手工打标签的时间。
官网地址:Computer Vision Datasets
比如戴口罩的数据集:

戴口罩的数据集地址:Mask Wearing Object Detection Dataset

直接下载YOLO V5版本对应格格式的文件

2.3 手工制作自己的数据(可选之一)
(0)数据集名称:xxxdata
xxxdataset/(1)采集自己的自定义数据集的图片数据
原始的图片文件存放在xxxdataset/images 目录中
xxxdataset/images/im0.jpg # image(2)用打标签工具为自己的自定义图片数据集打标签
xxxdataset/labels/
(3)通过标签格式转换工具,把标签转换成YOLO V5格式(不同版本,格式有些差异)
YOLO V5的标签是txt格式:

(4)标签文件与图片文件的关系:
xxxdataset/images/im0.jpg # image
xxxdataset/labels/im0.txt # label- images:存放原始的图片文件
- labels:存放同名的标签文件,每个原始图片有一个同名的标签文件
详见相关文章阐述。
步骤3: 组织数据集文件目录
把标注好的数据集拷贝到YOLO V5工程目录所在同一目录下的dataset目录中。

如果datasets没有指定的数据集,YOLO V5的程序会自动下载该数据集
步骤4: 为新数据集创建新配置文件或修改已有配置文件:xxxdataset.yaml
(1)配置文件名称: xxx.yaml
每个数据集xxx, 都有一个xxx.yaml数据集文件与之对应,用于指导模型训练程序,如何找到数据集图片与标签,以及获取数据的信息。
(2)配置文件的存放位置:yolov5/data/
如下是YOLO V5项目自带的数据集的配置文件:
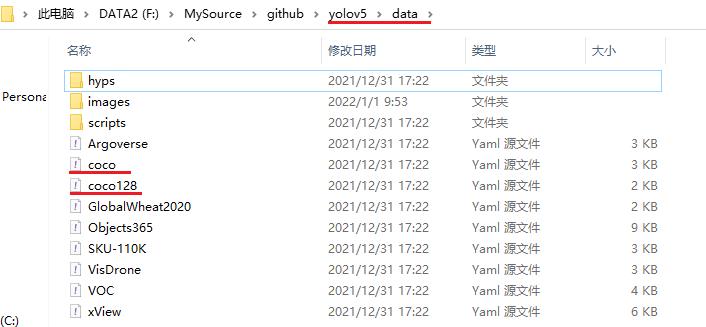
(3)配置文件的内容与格式
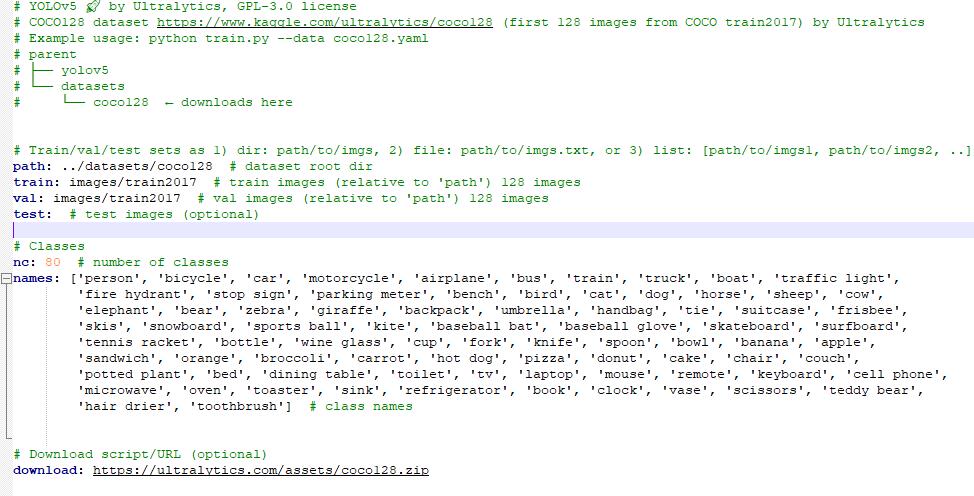
- path(可选):数据集的根目录
- train(必选):训练图片的子目录
- val(必选):验证图片的子目录
- nc(必选):分类的数目
- names(必选):每个分类的名称
- download(可选):远程下载数据集的路径(如果本地没有,则从网络下载)
步骤5:选择模型文件
5.1 选择模型文件
为了适应不同的应用场景,YOLO V5并不是采用单一规模的模型,而是采用多种规模的模型。不同的规模的模型,其速度、所需要的内存空间,mAP不尽相同。
GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite

其中,有4个典型规模的模型:
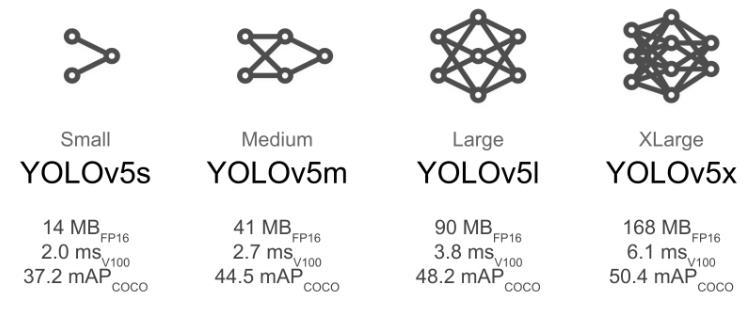
这里我们选择YOLOV5s为例
5.2 预训练模型的配置文件
(1)模型配置文件的作用
模型的配置文件,用于YOLO V5的工程文件来创建模型、下载预训练模型、初始化模型等操作。
(2)模型配置文件的存放位置
YOLO V5已经为支持的默认的模型创建了模型的模型的配置文件,如下图所示:
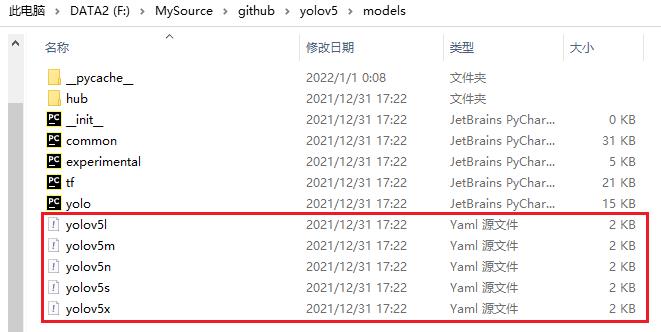
(3)模型配置文件的内容(YoloV5s为例)
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes # 分类数目
depth_multiple: 0.33 # model depth multiple # 模型的深度倍数,值越小,模型的规模越小
width_multiple: 0.50 # layer channel multiple # 模型通道的倍数,值越小,模型的规模越小
anchors: # 先验框: 3 * 3 = 9个
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone # 特征提取网络
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
模型配置文件是YOLO V5自带的,用户也可以修改该配置文件或创建自己的配置文件。
步骤6:用自定义数据训练模型
6.1 命令行
(1)GPU内存》=12G
# Train YOLOv5s on COCO128 for 5 epochs
$ python train.py --img 640 --batch 16 --epochs 5 --data coco128.yaml --weights yolov5s.pt(1)GPU内存<=8G
# Train YOLOv5s on COCO128 for 5 epochs
$ python train.py --img 640 --batch 1 --epochs 5 --data coco128.yaml --weights yolov5s.pt
$ python train.py --img 640 --batch 1 --epochs 5 --data MaskWearing.yaml --weights yolov5s.pt- python train.py: 模型训练文件
- --img 640 :图片文件的尺寸=640 * 640
- --batch 16 : batch size,如果GPU的内存空间不足,可是降低batch size。
- --epochs 5 :训练的轮数
- --data coco128.yaml :数据集配置文件
- --weights yolov5s.pt :预训练模型,节省训练时间,如果为空,则重头开始训练。
命令行所有的参数:
python train.py --img 640 --batch 1 --epochs 5 --data coco128.yaml --weights yolov5s.pt
train: weights=yolov5s.pt, cfg=, data=coco128.yaml, hyp=data\\hyps\\hyp.scratch.yaml, epochs=5, batch_size=1, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=False, adam=False, sync_bn=False, workers=8, project=runs\\train, name=exp, exist_ok=False, quad=False, linear_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest
6.2 训练结果的输出
(1)log
(pytorch-gpu-os) PS F:\\MySource\\github\\yolov5> python train.py --img 640 --batch 1 --epochs 5 --data coco128.yaml --weights yolov5s.pt
train: weights=yolov5s.pt, cfg=, data=coco128.yaml, hyp=data\\hyps\\hyp.scratch.yaml, epochs=5, batch_size=1, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=False, adam=False, sync_bn=False, workers=8, project=runs\\train, name=exp, exist_ok=False, quad=False, linear_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest
github: fatal: unable to access 'https://github.com/ultralytics/yolov5.git/': Failed to connect to github.com port 443 after 21127 ms: Timed out
Command 'git fetch && git config --get remote.origin.url' timed out after 5 seconds
YOLOv5 v6.0-162-gaffa284 torch 1.10.0 CUDA:0 (NVIDIA GeForce RTX 2070, 8192MiB)
hyperparameters: lr0=0.01, lrf=0.1, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
Weights & Biases: run 'pip install wandb' to automatically track and visualize YOLOv5 runs (RECOMMENDED)
TensorBoard: Start with 'tensorboard --logdir runs\\train', view at http://localhost:6006/
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 229245 models.yolo.Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 270 layers, 7235389 parameters, 7235389 gradients, 16.5 GFLOPs
Transferred 349/349 items from yolov5s.pt
Scaled weight_decay = 0.0005
optimizer: SGD with parameter groups 57 weight, 60 weight (no decay), 60 bias
train: Scanning '..\\datasets\\coco128\\labels\\train2017.cache' images and labels... 128 found, 0 missing, 2 empty, 0 corrupted: 100%|███████████████████████████████████████████████████████████████████████████████| 128/128 [00:00<?, ?it/s]
val: Scanning '..\\datasets\\coco128\\labels\\train2017.cache' images and labels... 128 found, 0 missing, 2 empty, 0 corrupted: 100%|█████████████████████████████████████████████████████████████████████████████████| 128/128 [00:00<?, ?it/s]
module 'signal' has no attribute 'SIGALRM'
AutoAnchor: 4.27 anchors/target, 0.994 Best Possible Recall (BPR). Current anchors are a good fit to dataset
Image sizes 640 train, 640 val
Using 0 dataloader workers
Logging results to runs\\train\\exp7
Starting training for 5 epochs...
Epoch gpu_mem box obj cls labels img_size
0/4 0.493G 0.04649 0.09372 0.04373 19 640: 100%|██████████| 128/128 [00:14<00:00, 9.04it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 64/64 [00:01<00:00, 38.13it/s]
all 128 929 0.648 0.596 0.645 0.413
Epoch gpu_mem box obj cls labels img_size
1/4 0.549G 0.04281 0.08579 0.04072 42 640: 100%|██████████| 128/128 [00:09<00:00, 13.66it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 64/64 [00:01<00:00, 38.47it/s]
all 128 929 0.701 0.556 0.648 0.411
Epoch gpu_mem box obj cls labels img_size
2/4 0.549G 0.04389 0.07658 0.037 8 640: 100%|██████████| 128/128 [00:34<00:00, 3.70it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 64/64 [00:01<00:00, 37.86it/s]
all 128 929 0.692 0.586 0.664 0.412
Epoch gpu_mem box obj cls labels img_size
3/4 0.589G 0.04433 0.08129 0.04049 5 640: 100%|██████████| 128/128 [00:09<00:00, 13.72it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 64/64 [00:01<00:00, 38.49it/s]
all 128 929 0.715 0.569 0.672 0.42
Epoch gpu_mem box obj cls labels img_size
4/4 0.633G 0.04291 0.07103 0.03668 3 640: 100%|██████████| 128/128 [00:09<00:00, 13.75it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 64/64 [00:01<00:00, 38.13it/s]
all 128 929 0.769 0.56 0.686 0.443
5 epochs completed in 0.024 hours.
Optimizer stripped from runs\\train\\exp7\\weights\\last.pt, 14.8MB
Optimizer stripped from runs\\train\\exp7\\weights\\best.pt, 14.8MB
Validating runs\\train\\exp7\\weights\\best.pt...
Fusing layers...
Model Summary: 213 layers, 7225885 parameters, 0 gradients, 16.5 GFLOPs
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 64/64 [00:02<00:00, 28.58it/s]
all 128 929 0.759 0.566 0.686 0.442
person 128 254 0.889 0.602 0.786 0.503
bicycle 128 6 1 0.328 0.623 0.427
car 128 46 0.817 0.283 0.475 0.215
motorcycle 128 5 0.794 0.8 0.866 0.638
airplane 128 6 0.927 0.833 0.955 0.668
bus 128 7 0.66 0.714 0.759 0.653
train 128 3 0.803 0.667 0.913 0.565
truck 128 12 0.744 0.333 0.501 0.281
boat 128 6 0.673 0.167 0.347 0.0817
traffic light 128 14 0.645 0.286 0.319 0.227
stop sign 128 2 0.903 1 0.995 0.945
bench 128 9 0.883 0.333 0.694 0.331
bird 128 16 0.961 1 0.995 0.611
cat 128 4 0.746 0.75 0.888 0.728
dog 128 9 0.86 0.556 0.766 0.534
horse 128 2 0.85 1 0.995 0.597
elephant 128 17 0.889 0.824 0.828 0.561
bear 128 1 0.495 1 0.995 0.995
zebra 128 4 0.882 1 0.995 0.937
giraffe 128 9 0.741 1 0.963 0.617
backpack 128 6 0.949 0.333 0.476 0.221
umbrella 128 18 0.817 0.611 0.823 0.441
handbag 128 19 0.58 0.105 0.172 0.115
tie 128 7 0.722 0.857 0.795 0.514
suitcase 128 4 0.722 1 0.995 0.634
frisbee 128 5 0.631 0.8 0.797 0.538
skis 128 1 0.691 1 0.995 0.597
snowboard 128 7 0.807 0.714 0.782 0.392
sports ball 128 6 1 0.61 0.686 0.445
kite 128 10 0.855 0.592 0.702 0.339
baseball bat 128 4 1 0.674 0.995 0.292
baseball glove 128 7 0.677 0.429 0.493 0.285
skateboard 128 5 0.917 0.8 0.962 0.488
tennis racket 128 7 0.698 0.571 0.594 0.232
bottle 128 18 0.664 0.44 0.495 0.322
wine glass 128 16 0.702 0.885 0.845 0.401
cup 128 36 0.93 0.368 0.616 0.381
fork 128 6 0.671 0.167 0.396 0.274
knife 128 16 0.708 0.625 0.638 0.395
spoon 128 22 0.68 0.5 0.604 0.275
bowl 128 28 0.9 0.643 0.702 0.496
banana 128 1 0 0 0.142 0.0711
sandwich 128 2 1 0 0.125 0.12
orange 128 4 0.146 0.0732 0.558 0.293
broccoli 128 11 0.556 0.182 0.295 0.245
carrot 128 24 0.782 0.748 0.786 0.554
hot dog 128 2 0.411 0.734 0.745 0.683
pizza 128 5 0.61 0.6 0.853 0.502
donut 128 14 0.715 1 0.99 0.807
cake 128 4 0.755 1 0.945 0.884
chair 128 35 0.564 0.429 0.479 0.243
couch 128 6 1 0.449 0.995 0.543
potted plant 128 14 0.801 0.714 0.855 0.457
bed 128 3 1 0 0.753 0.379
dining table 128 13 0.577 0.308 0.497 0.336
toilet 128 2 1 0.872 0.995 0.796
tv 128 2 0.483 1 0.995 0.846
laptop 128 3 1 0 0.668 0.401
mouse 128 2 1 0 0.17 0.051
remote 128 8 0.829 0.625 0.604 0.433
cell phone 128 8 1 0.213 0.443 0.184
microwave 128 3 0.512 1 0.913 0.648
oven 128 5 0.71 0.4 0.476 0.269
sink 128 6 0.381 0.167 0.223 0.151
refrigerator 128 5 0.777 0.8 0.824 0.486
book 128 29 0.783 0.138 0.265 0.103
clock 128 9 0.824 0.778 0.899 0.626
vase 128 2 0.307 1 0.497 0.398
scissors 128 1 1 0 0 0
teddy bear 128 21 0.896 0.412 0.779 0.397
toothbrush 128 5 1 0.374 0.742 0.309
Results saved to runs\\train\\exp7(2)训练好的模型文件
\\yolov5\\runs\\train\\exp7\\weights
- best.pt => 精度最好的模型文件
- last.pt => 最新的模型文件
(3)训练集部分目标检测的图片输出
\\yolov5\\runs\\train\\exp7\\train_batchXXX.jpg
(4)验证集目标检测的图片输出
\\yolov5\\runs\\train\\exp7\\val_batchXXX.jpg
(5)训练结果的可视化文件
\\yolov5\\runs\\train\\exp7\\result.jpg

步骤7:手工检验模型的训练效果
(1)模型训练后的权重矩阵输出
\\yolov5\\runs\\train\\exp7\\weights
- best.pt => 精度最好的模型文件
- last.pt => 最新的模型文件
(2)用训练的模型进行预测
python detect.py --source .\\data\\images\\bus.jpg --weights runs\\train\\exp7\\weights\\best.pt执行结果输出:Results saved to runs\\detect\\exp63
(pytorch-gpu-os) PS F:\\MySource\\github\\yolov5> python detect.py --source .\\data\\images\\bus.jpg --weights runs\\train\\exp7\\weights\\best.pt
detect: weights=['runs\\\\train\\\\exp7\\\\weights\\\\best.pt'], source=.\\data\\images\\bus.jpg, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs\\detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False
YOLOv5 v6.0-162-gaffa284 torch 1.10.0 CUDA:0 (NVIDIA GeForce RTX 2070, 8192MiB)
Fusing layers...
Model Summary: 213 layers, 7225885 parameters, 0 gradients, 16.5 GFLOPs
current working directory: F:\\MySource\\github\\yolov5
image's abs: F:\\MySource\\github\\yolov5\\data\\images\\bus.jpg
image's abs: F:\\MySource\\github\\yolov5\\data\\images\\bus.jpg
image 1/1 F:\\MySource\\github\\yolov5\\data\\images\\bus.jpg: 640x480 3 persons, 1 bus, Done. (0.007s)
Speed: 0.0ms pre-process, 7.0ms inference, 7.0ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs\\detect\\exp63
更详细的预测方法如下:
[YOLO专题-9]:YOLO V5 - ultralytics/yolov5代码快速启动详解_文火冰糖(王文兵)的博客-CSDN博客
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/122150460
以上是关于[YOLO专题-11]:YOLO V5 - ultralytics/train基于自定义图片数据集重新训练网络, 完成自己的目标检测的主要内容,如果未能解决你的问题,请参考以下文章
[YOLO专题-18]:YOLO V5 - ultralytics代码解析-总体架构
[YOLO专题-22]:YOLO V5 - ultralytics代码解析-超参数详解
[YOLO专题-21]:YOLO V5 - ultralytics代码解析-网络配置文件与总体结构
[YOLO专题-19]:YOLO V5 - ultralytics代码解析-dataloader数据加载机制