深度学习笔记:利用预训练模型之特征提取训练小数据集上的图像分类器
Posted 笨牛慢耕
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习笔记:利用预训练模型之特征提取训练小数据集上的图像分类器相关的知识,希望对你有一定的参考价值。
目录
0. 前言
本文(以及接下来的几篇)介绍如何搭建一个卷积神经网络用于图像分类的深度学习问题,尤其是再训练数据集比较小的场合。通常来说,深度学习需要大量的数据进行训练,尤其是像在图像处理这种通常数据维度非常高的场合。但是当你没有一个足够大的数据集进行训练的时候应该怎么办呢?
解决训练数据集太小的方法通常有两种:
(1) 使用数据增强策略
(2) 使用预训练模型
前面两篇我们分别进行了在不用数据增强和用数据增强技术的条件下在一个小数据集上训练一个小的卷积神经网络。采用数据增强可以获得相当程度的改善,但是由于原始数据集毕竟太小,所以很难达到90%的预测准确度。
本文我们将考虑如何在(已经在大数据集上训练过的)预训练模型的基础上,在小数据集上进一步训练得到最终模型的效果。
本文中将略去数据下载和预处理,相关细节请参考前面两篇。
深度学习笔记:在小数据集上从头训练卷积神经网络 https://blog.csdn.net/chenxy_bwave/article/details/122260520
https://blog.csdn.net/chenxy_bwave/article/details/122260520
深度学习笔记:利用数据增强在小数据集上从头训练卷积神经网络https://blog.csdn.net/chenxy_bwave/article/details/122276708
1. 为什么可以用预训练模型?
换句话说,为什么预训练模型会有效?
预训练网络(pre-trained)是指一个之前在大型数据集(通常是大规模图像分类任务)上训练并保存好的网络模型。如果这个原始数据集足够大且足够通用,那么预训练模型学到的特征的空间层次结构可以有效地作为视觉世界的通用模型,因此这些特征可用于各种不同的计算机视觉问题,即时这些新问题涉及的类别和原始问题完全不同。举个例子,你在ImageNet(其类别主要是动物和日常用品)上训练了一个模型,然后将这个训练好的模型应用于某个不相干的任务,比如说在图像中识别家具。这种学到的特征在不同问题之间的可移植性,是深度学习与许多早期浅层学习方法相比的重要优势,它使得深度学习对小数据问题也能够做到非常有效。
使用预训练模型有两种方法:
(1) 特征提取: feature extraction
(2) 模型微调: fine-tuning
本文先做关于特征提取的实验。模型微调将留到下一篇讨论。
1.1 特征提取
特征提取就是使用预训练模型学到的表示来从新样本中提取出感兴趣的特征。然后将这些特征输入一个新的分类器,从头开始训练。
一个用于图像分类的卷积神经网络通常包含两部分。第一部分是一系列卷积层和池化层,通常称为卷积基(convolutional base, 简记为convbase);第二部分就是最后连接的密集连接分类器。
对于卷积神经网络而言,特征提取就是用卷积基对新数据进行处理,生成新数据的特征表示。然后再基于这些所提取的特征去训练一个新的分类器。
为什么仅重复使用卷积基呢?原因在于卷积基学到的表示更有通用性,因此更适合于重复使用。卷积神经网络的特征图表示通用概念在图像中是否存在,无论面对什么样的计算机视觉问题,这种特征图都可能有用。而最后的分类器学到的表示必然是针对有模型训练的类别,其中仅包含某个类别出现在整张图像中的概率信息。比如说,从猫狗分类中学习到的表示信息不太可能对于家具分类有什么帮助,但是不管是猫狗的图像还是家具的图像,都会有边缘啊、条纹啊之类的东西。此外,密集连接层的表示不再包含物体在输入图像中的位置信息,它舍弃了空间概念。物体的位置信息再卷积特征图中有描述,如果物体位置对于问题很重重要,那么密集连接层的特征在很大程度上是无用的。
进一步,卷积神经网络中不同的卷积层所学习到的表示的通用性也是不同的。通常来说,处于模型的前级的层提取的局部的有更高通用性的特征图(比如,边缘,颜色,纹理等等),而靠后的卷积层提取的是更加抽象的概念(比如说‘猫耳朵’、‘狗眼睛’等等)。因此,如果你的新数据与原始数据有很大的差异,那么最好只使用卷积基的前面基层来做特征提取。比如说如果你是在猫狗数据集上训练出的模型,想要用作预训练模型用于家具分类识别,后级卷积层所提取的整体的、抽象的特征(比如说‘猫耳朵’、‘狗眼睛’等等)对于家具分类显然没有什么意义。
1.2 模型微调
参见后续篇章。
2. 加载预训练模型
在这个例子中我们将使用在ImageNet上训练的VGG16网络的卷积基从猫狗图像数据集中提取特征,然后用于训练一个猫狗分类器。
由于ImageNet数据集中也包含了很多猫和狗的图片,所以可以直接使用VGG16网络进行猫狗图像数据集的图像分类其实是可以的。但是出于本文的演示目的,我们只使用VGG16的卷积基。
在keras中内置了很多卷积神经网络的经典模型(其实也就是过去不到十年的事情,但是深度学习发展过于迅速,几年的时间已经使得当年的新模型成为今天的经典。当然在这个加速发展的世界里,成为经典意味着它的性能可能已经远远落后与SOTA模型,只是它的思想被传承下去了),如下所示:
(1) Xception
(2) Inception X3
(3) ResNet50
(4) VGG16
(5) VGG19
(6) MobileNet
以下VGG16模型实例化中,将include_top置为False,意思就是剔除最顶层(即最终的密集分类层)。weights指定模型初始化的权重检查点,input_shape则指定输入数据形状。可以不指定,不指定的话,可以处理任意形状的输入。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import utils
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
print(tf.__version__)
conv_base = keras.applications.vgg16.VGG16(
weights="imagenet",
include_top=False,
input_shape=(180, 180, 3))
conv_base.summary()

3. 特征提取
以下我们同样先实例化生成ImageDataGenerator对象,然后分别生成训练集、验证集和测试集的数据生成器,这里我们先不考虑数据增强(step-by-step地累进式地前进有助于我们看清楚每一个技术要素所发挥的作用)。然后利用以上加载的VGG16的conv_base提取这些数据集中的特征。
# Data generators
import os
from tensorflow.keras.preprocessing.image import ImageDataGenerator
batch_size = 32
train_dir = os.path.join('F:\\DL\\cats_vs_dogs_small', 'train')
test_dir = os.path.join('F:\\DL\\cats_vs_dogs_small', 'test')
train_datagen = ImageDataGenerator(rescale=1./255,validation_split=0.3)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
directory=train_dir,
target_size=(180, 180),
color_mode="rgb",
batch_size=batch_size,
class_mode="binary",
subset='training',
shuffle=True,
seed=42
)
valid_generator = train_datagen.flow_from_directory(
directory=train_dir,
target_size=(180, 180),
color_mode="rgb",
batch_size=batch_size,
class_mode="binary",
subset='validation',
shuffle=True,
seed=42
)
test_generator = test_datagen.flow_from_directory(
directory=test_dir,
target_size=(180, 180),
color_mode="rgb",
batch_size=batch_size,
class_mode='binary',
shuffle=False,
seed=42
)
import numpy as np
def get_features_and_labels(dataGenerator):
all_features = []
all_labels = []
k = 0
for images, labels in dataGenerator:
features = conv_base.predict(images)
all_features.append(features)
all_labels.append(labels)
k += 1
if dataGenerator.batch_size * (k+1) > dataGenerator.n:
break
print('Totally, 0-batches with batch_size=1'.format(k,dataGenerator.batch_size))
return np.concatenate(all_features), np.concatenate(all_labels)
train_features, train_labels = get_features_and_labels(train_generator)
val_features, val_labels = get_features_and_labels(valid_generator)
test_features, test_labels = get_features_and_labels(test_generator)
print(train_features.shape,train_labels.shape)
需要注意的一点是,Generator是可以永远持续地生成数据的,而并不是说输出完一遍数据后就退出,因此需要有一个break机制。参见以上get_features_and_lables()中的break语句。
4. 训练以及评估
4.1 训练
由于这里的训练只涉及到最后的Dense Layer,因此训练会非常快(相比前面两篇中从头训练而言)。当然,由于本模型采用了VGG16的卷积基,所以在预测阶段所需要的运算量是远远地大于前两篇中训练的小型卷积网络。毕竟VGG16的卷积基虽然不用重新训练,但是预测时是需要全部参与的运算的。
from tensorflow.keras import optimizers
inputs = keras.Input(shape=(5, 5, 512)) # This shape has to be the same as the output shape of the convbase
x = layers.Flatten()(inputs)
x = layers.Dense(256,activation='relu')(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(loss="binary_crossentropy",
optimizer=optimizers.RMSprop(learning_rate=2e-5),
metrics=["accuracy"])
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath="feature_extraction.keras",
save_best_only=True,
monitor="val_loss")
]
history = model.fit(
train_features, train_labels,
epochs=32,
validation_data=(val_features, val_labels),
callbacks=callbacks)4.2 loss和accuracy曲线
import matplotlib.pyplot as plt
accuracy = history.history["accuracy"]
val_accuracy = history.history["val_accuracy"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(1, len(accuracy) + 1)
plt.plot(epochs, accuracy, "bo", label="Training accuracy")
plt.plot(epochs, val_accuracy, "b", label="Validation accuracy")
plt.title("Training and validation accuracy")
plt.legend()
plt.figure()
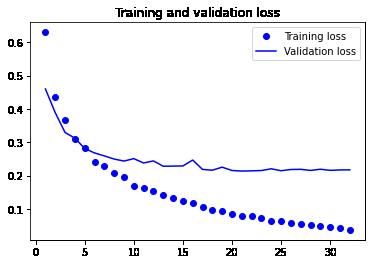
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.legend()
plt.show()
4.3. 在测试集进行模型性能评估
print(test_features.shape,test_labels.shape)
test_model = keras.models.load_model("feature_extraction.keras")
test_loss, test_acc = test_model.evaluate(test_features,test_labels)
print(f"Test accuracy: test_acc:.3f")
5. 小结
本文基于keras内置的VGG16做了一个基于预训练模型的特征提取(without data augmentation)的实验。
实验结果表明(unsurprisingly)存在明显的过拟合。但是相对地来看的话,在验证集和测试集上也分别得到了91%和89%的准确度(accuracy),而上一篇基于数据增强技术从头开始训练的网络只有80%出头而已,可以说是一个巨大的进步。
接下来我们来看看,在基于预训练模型的基础上再加上数据增强能不能取得更好的性能呢?
Reference: Francois, Chollet: Deep Learning with Python.
以上是关于深度学习笔记:利用预训练模型之特征提取训练小数据集上的图像分类器的主要内容,如果未能解决你的问题,请参考以下文章