如何在IDEA编译器中连接HDFS,运行MapReduce程序
Posted Yuan-Programmer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在IDEA编译器中连接HDFS,运行MapReduce程序相关的知识,希望对你有一定的参考价值。
⭐ ⭐ ⭐ ⭐ ⭐ 博主信息⭐ ⭐ ⭐ ⭐ ⭐
博主名称:Yuan-Programmer
链接直达:https://bbs.csdn.net/topics/603957283
链接直达:https://bbs.csdn.net/topics/603957283
链接直达:https://bbs.csdn.net/topics/603957283
链接直达:https://bbs.csdn.net/topics/603957283
⭐ ⭐ ⭐ ⭐ ⭐ 点点五星⭐ ⭐ ⭐ ⭐ ⭐
我正在参加年度博客之星评选,请大家帮我投票打分,您的每一分都是对我的支持与鼓励。
贡献您几秒钟时间,点个五星,在此感激不尽!!!
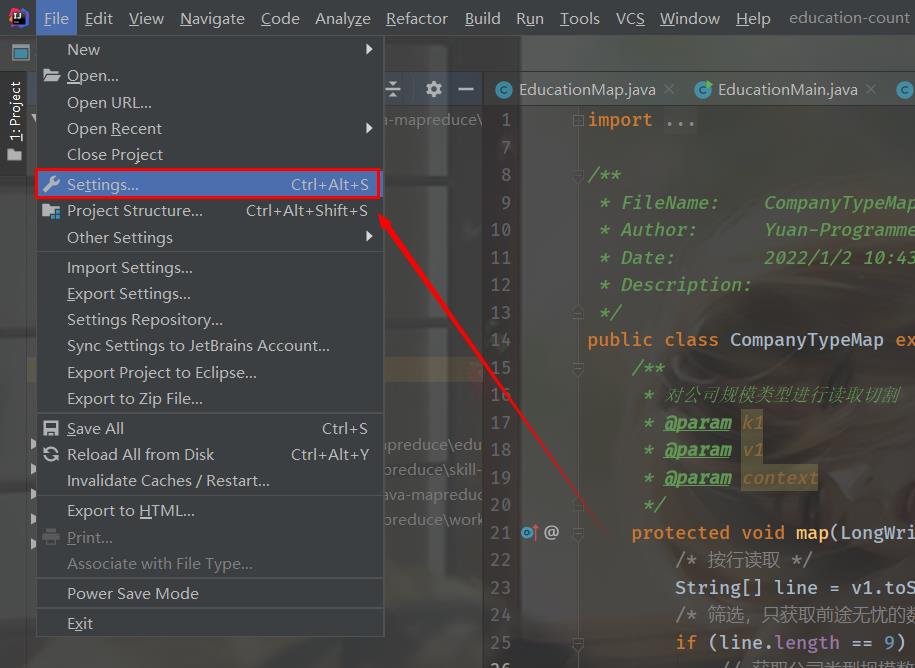
打开IDEA编译器-->>点击File-->>选择Settings
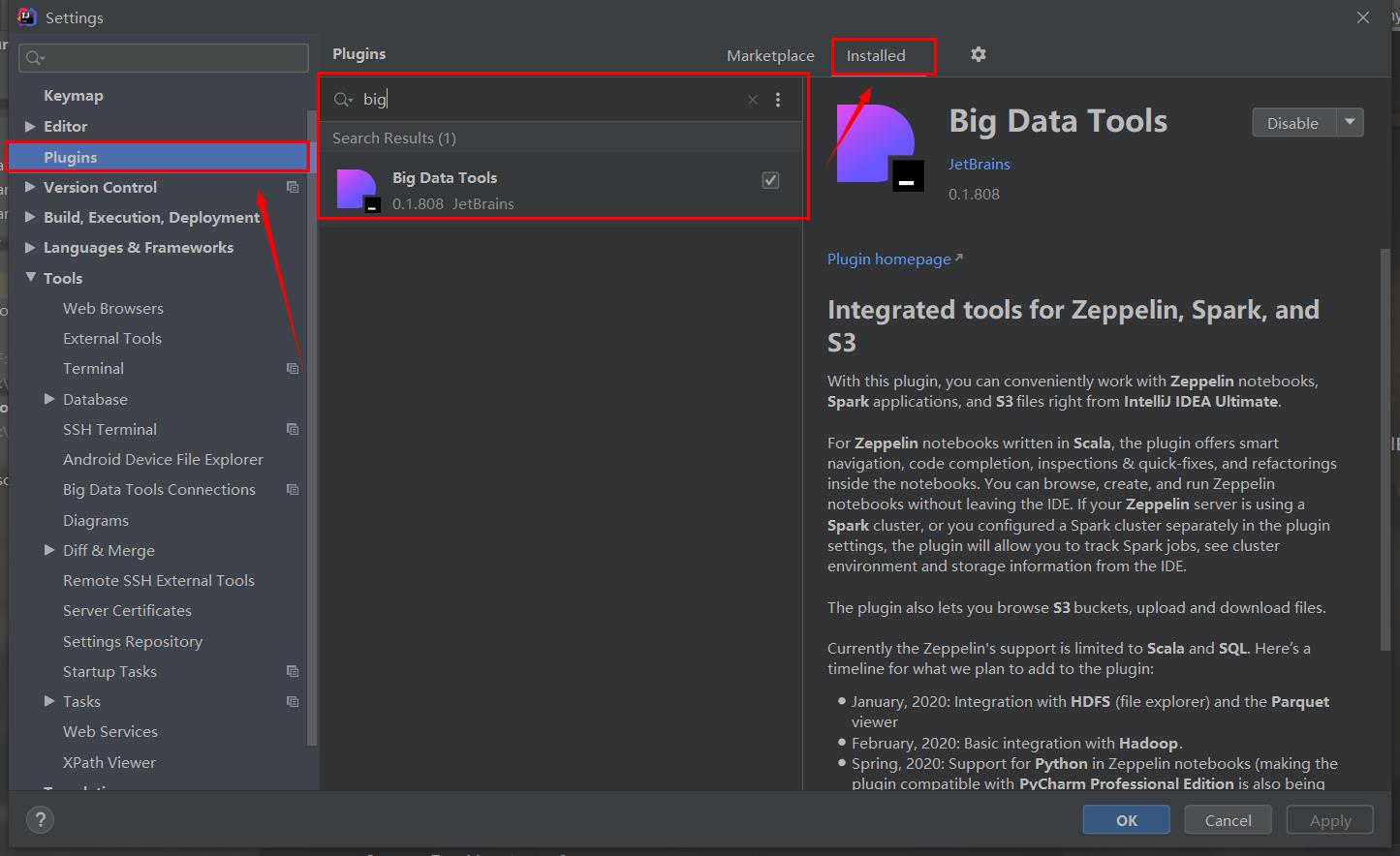
找到Plugins,在Installed中搜索big,找到下面这个,点击下载,我这里已经下载过了
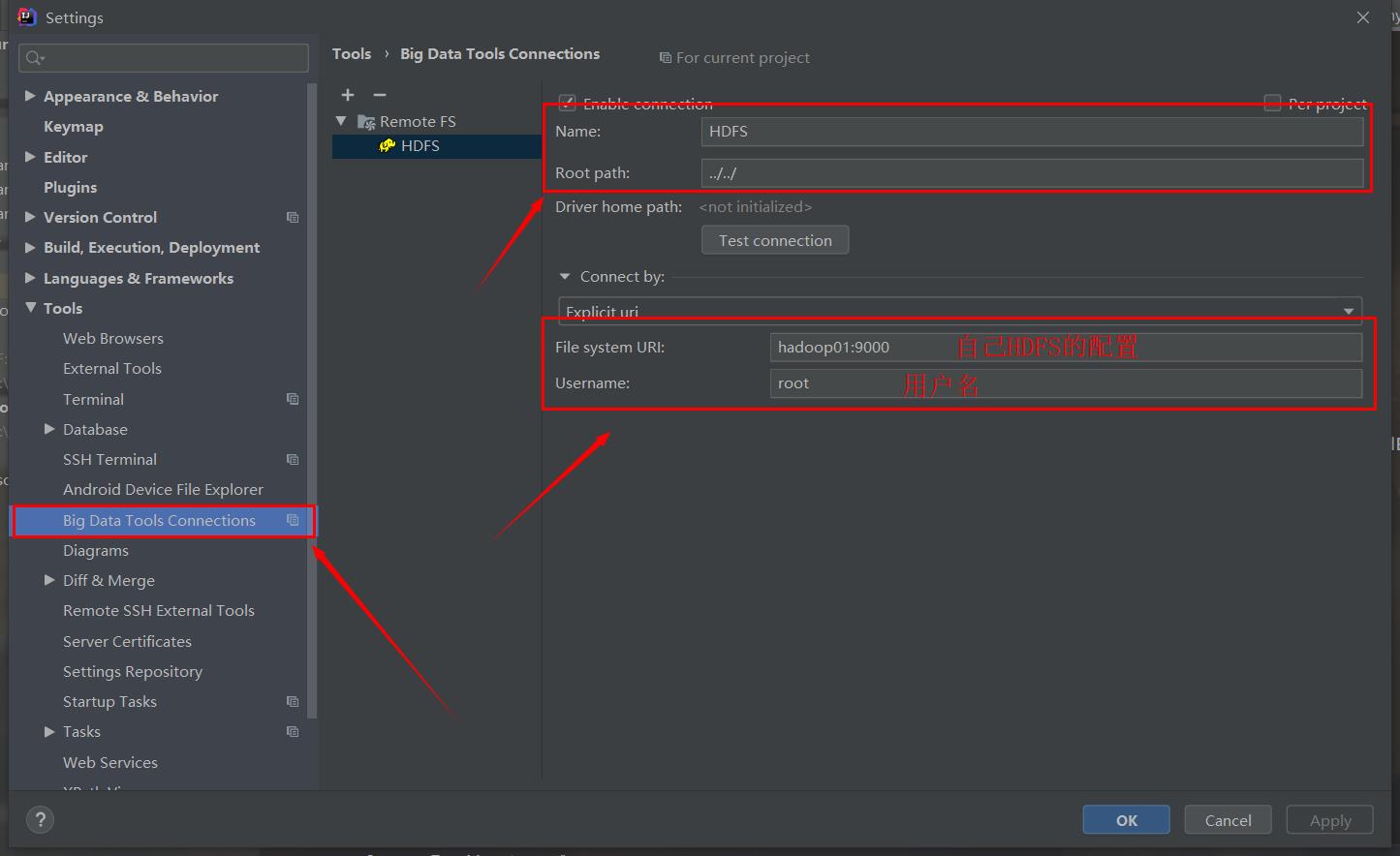
下载之后展开在左侧的Tools下的Big...里,配置如下信息
上面的hadoop01:9000是之前的core-site.xml配置里的
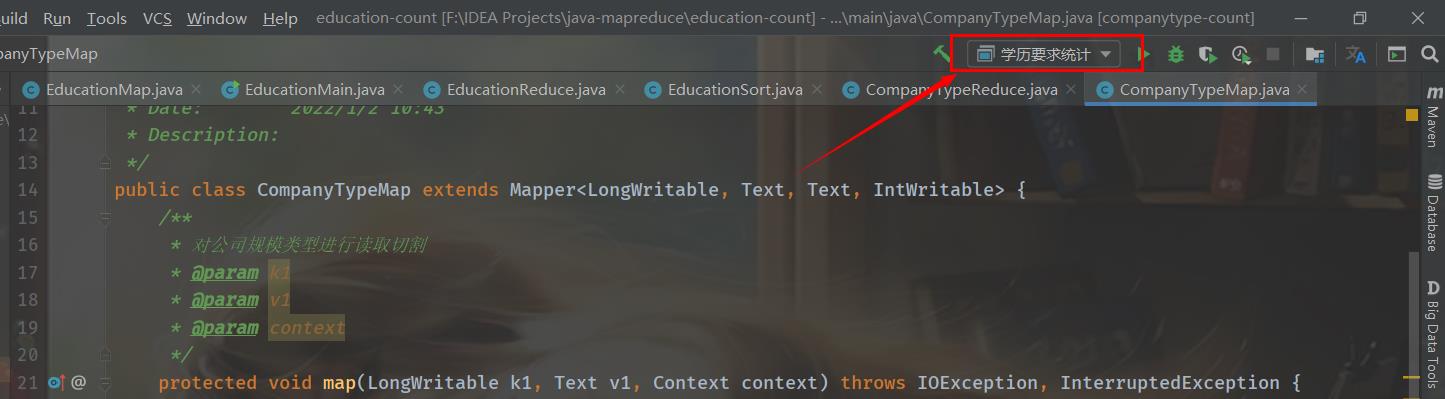
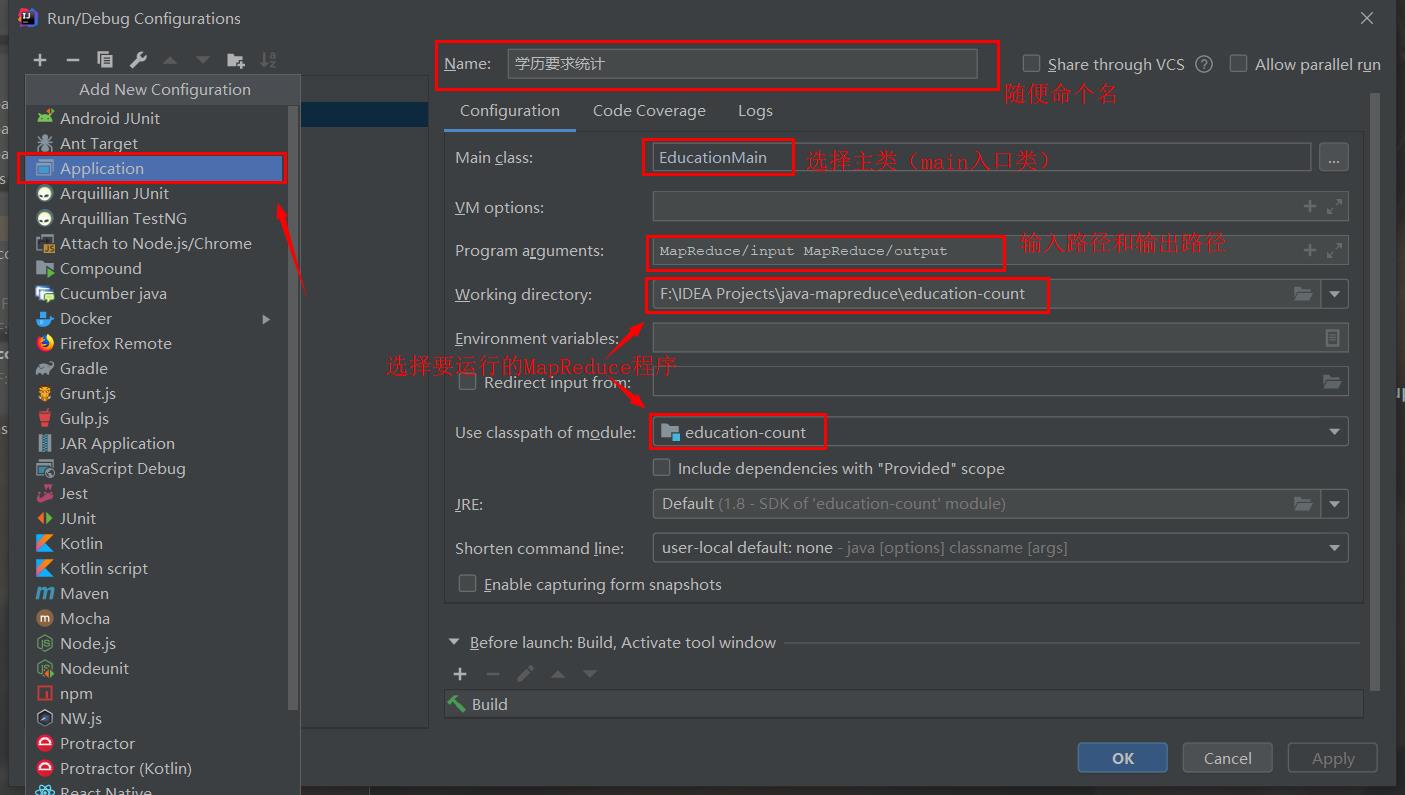
然后点击右上角的这里,添加新的Application
然后在你的maven项目(MapReduce)的resource下面添加三个配置文件
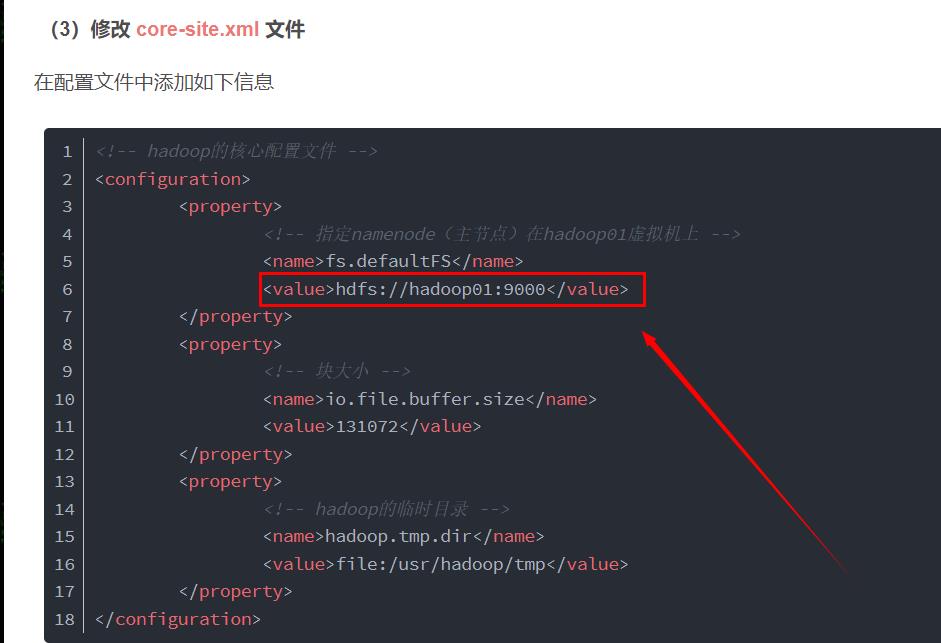
core-site.xml
<configuration> <property> <!-- URI 定义主机名称和 namenode 的 RPC 服务器工作的端口号 --> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000</value> </property> <!-- <property> 这个可以设置为本地路径,但没有什么用,这个路径是 Hadoop 集群用的 Hadoop 临时目录,默认是系统的临时目录下,/tmp/hadoop-$username 下 <name>hadoop.tmp.dir</name> <value>/home/xian/hadoop/cluster</value> </property> --> </configuration>log4j.properties(打印日志)
log4j.appender.A1.Encoding=UTF-8 log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%dABSOLUTE | %-5.5p | %-16.16t | %-32.32c1 | %-32.32C %4L | %m%nmapred-site.xml
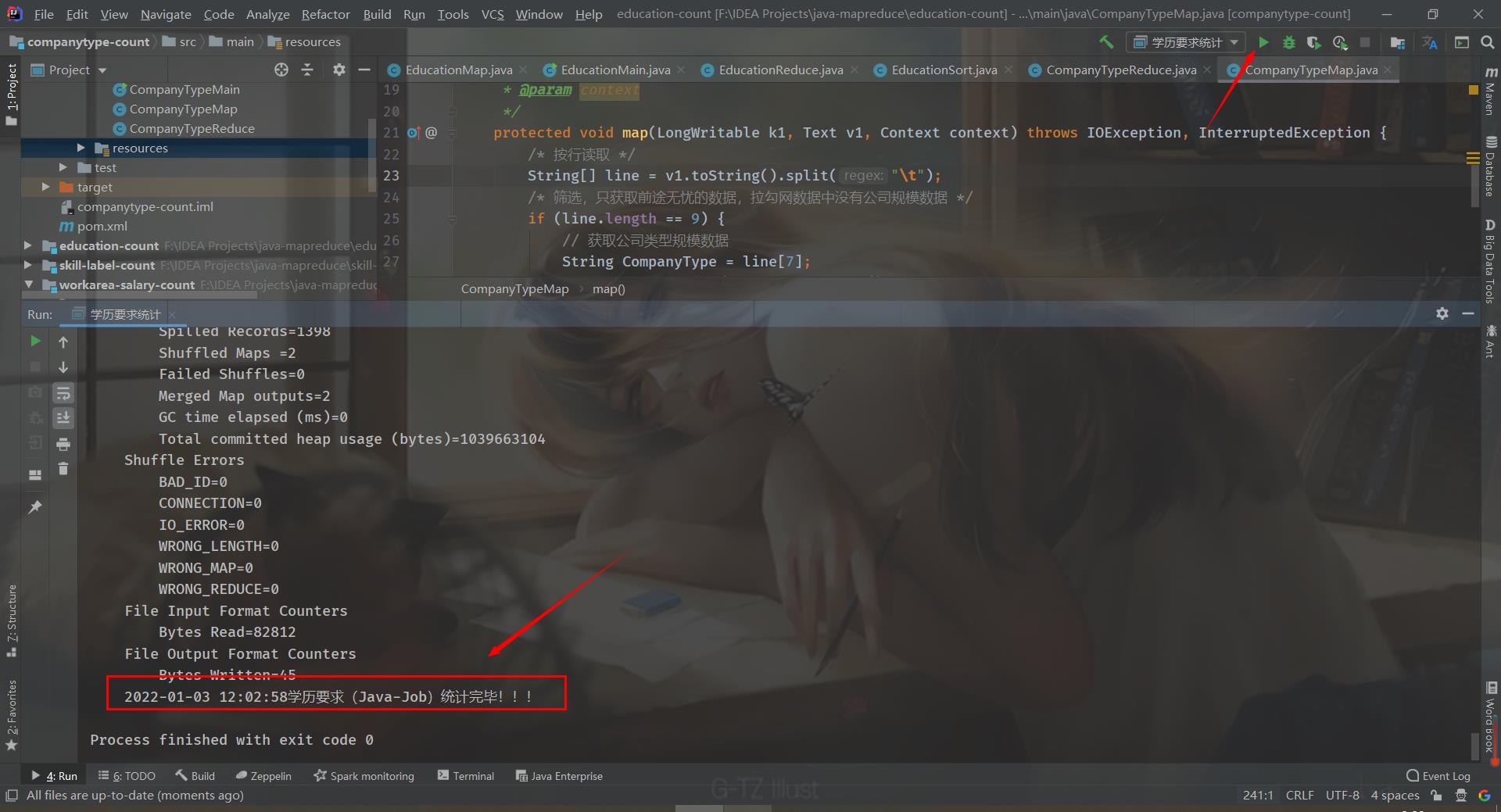
<configuration> <!-- 远程提交到 Linux 的平台上 --> <property> <name>mapred.remote.os</name> <value>Linux</value> <description>Remote MapReduce framework's OS, can be either Linux or Windows</description> </property> <!--允许跨平台提交 解决 /bin/bash: line 0: fg: no job control --> <property> <name>mapreduce.app-submission.cross-platform</name> <value>true</value> </property> </configuration>最后直接点击运行,就可以在IDEA运行MapReduce程序啦(前提是开启hadoop服务哦,能再浏览器打开HDFS文件系统)
以上是关于如何在IDEA编译器中连接HDFS,运行MapReduce程序的主要内容,如果未能解决你的问题,请参考以下文章