由于hadoop高可用状态切换,导致hive在指定数据库下建立以及读取表失败
Posted cuichunchi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了由于hadoop高可用状态切换,导致hive在指定数据库下建立以及读取表失败相关的知识,希望对你有一定的参考价值。
问题描述:因为cdh集群,hadoop启用了HA高可用,之前node1节点为active,现在变成了node2节点为standby。而且之前hive建库的时候,LOCATION=hdfs://node1:8020/user/warehouse/dir.....
导致库里面的表默认都是获取DB的location来拼接的表的hdfs路径。
由于切换成了standby后,读取表的时候,报READ IS NOT
SUPPORT in state standby。就是从机器不允许读写。

定位:由于配置文件hive-site.xml、core-site.xml、hdfs-site.xml等有关配置文件都替换了最新,都是配置了hdfs://高可用地址/
因为通过hivemetastore去连接创建表,所以排查了日志。在FlieUtils这行显示了不是集群地址的路径。由hivemetastore类去调用了fileutils方法
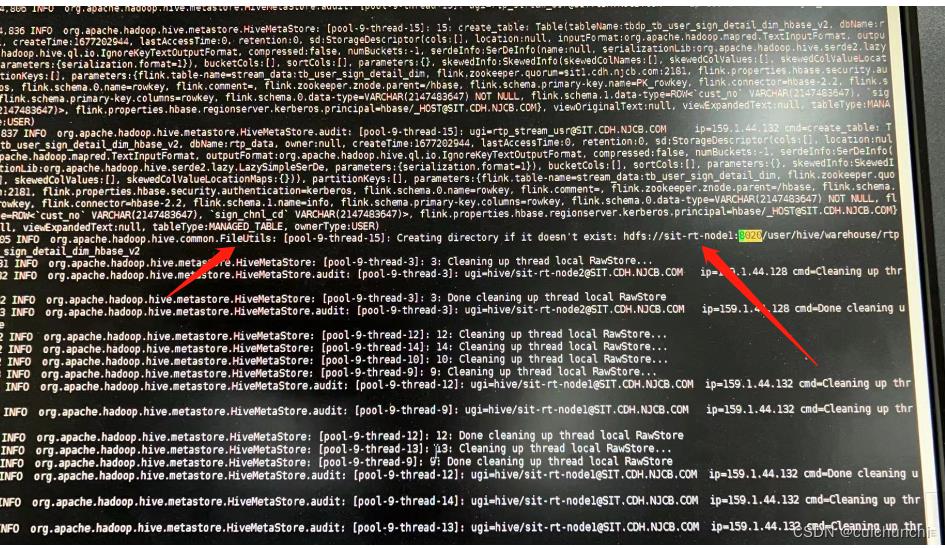
于是最后,翻看了hive的源码,在下面看出:
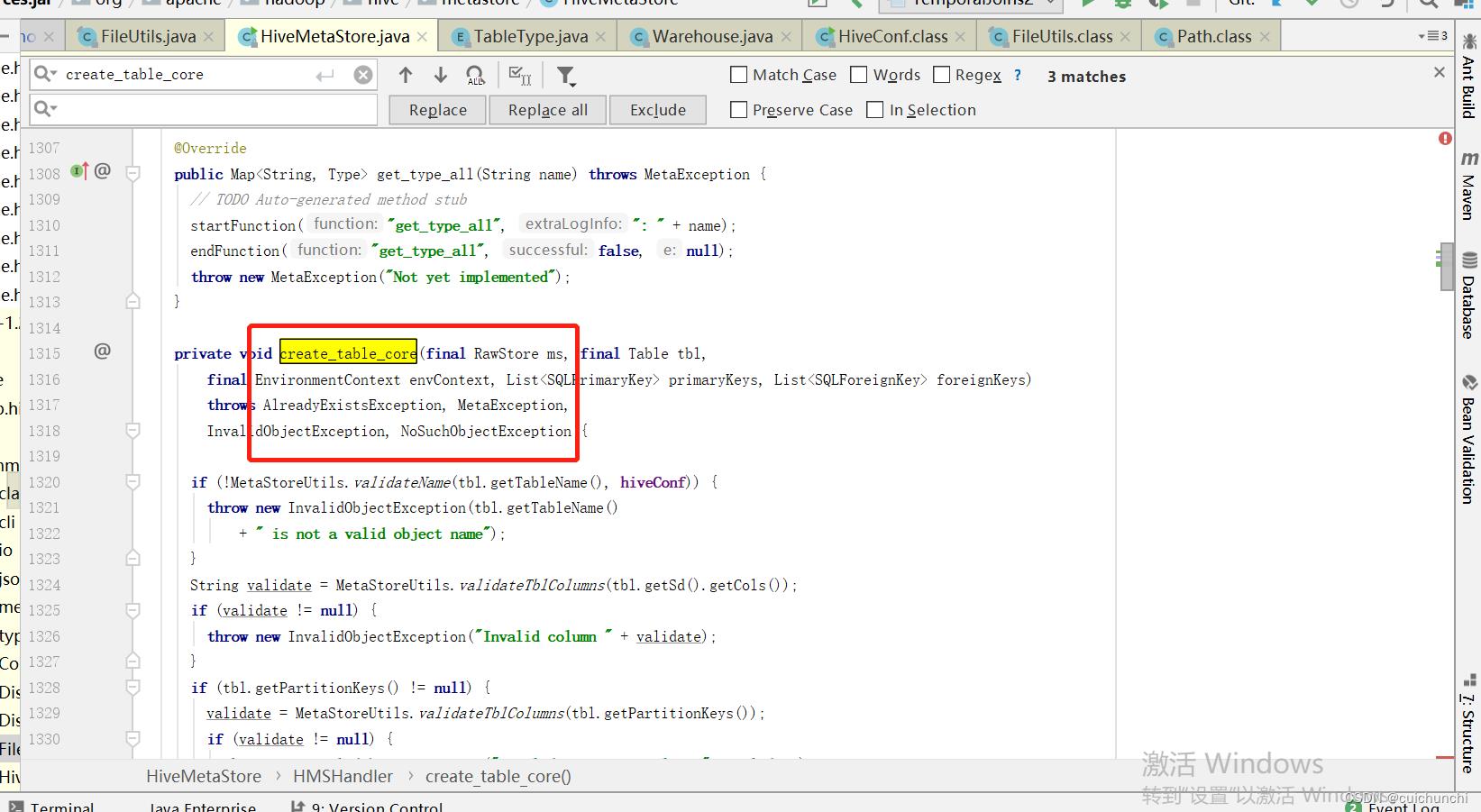
这个方法下面:

进入wh(warehouse类).getTablePath() 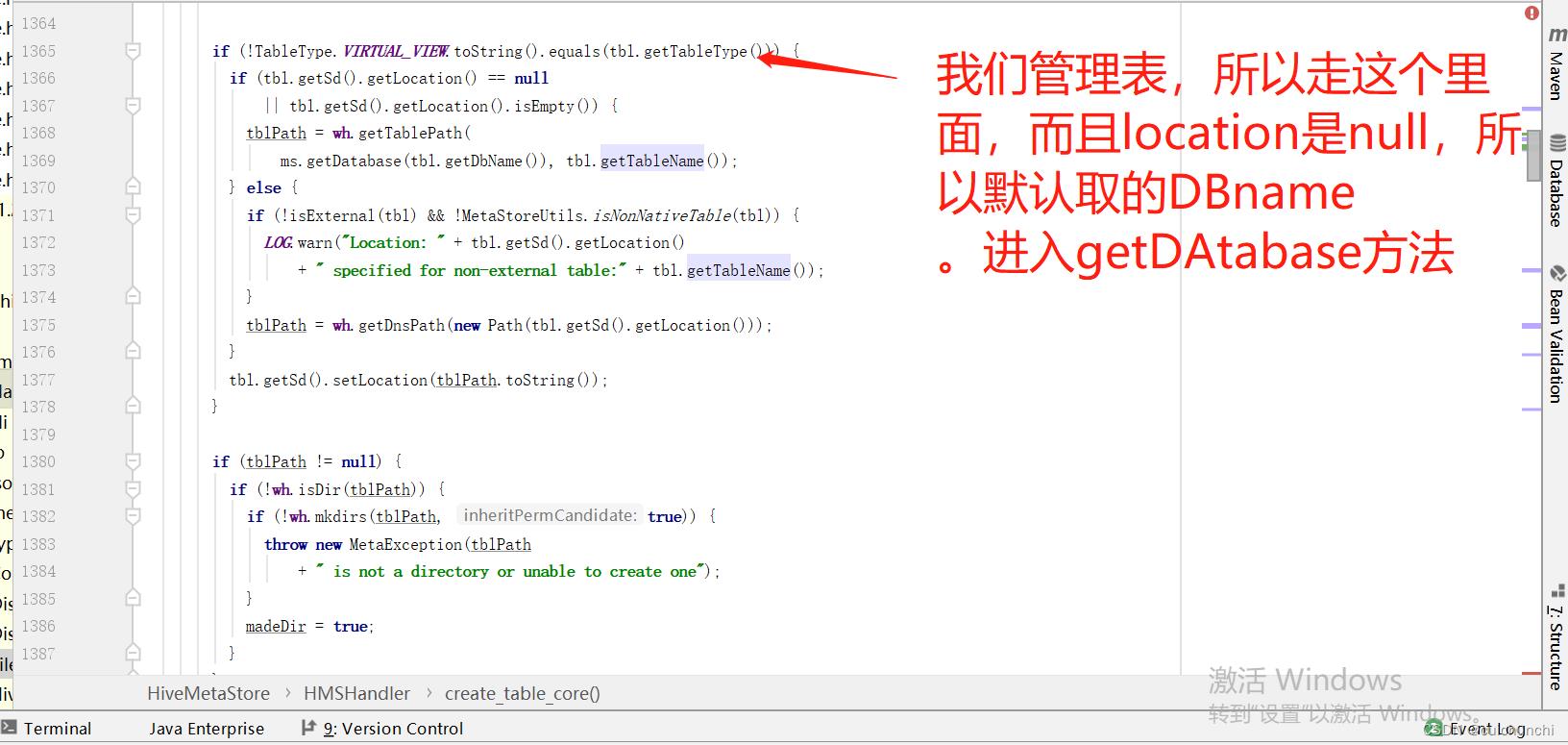

这个地方由含义就知道获取的databasepath的数据库的location。
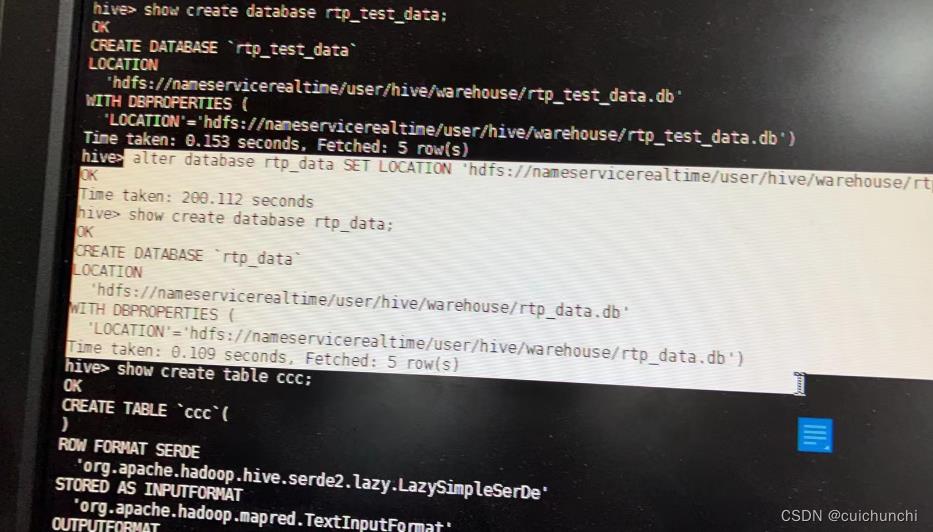
于是就去查看hive的建库语句
hive>show create database rtp_data;
显示确实是单机的地址

解决:
修改库的location地址即可:
alter database <my_db> set location '<new_hdfs_loc>';
以上是关于由于hadoop高可用状态切换,导致hive在指定数据库下建立以及读取表失败的主要内容,如果未能解决你的问题,请参考以下文章