目标检测基础学习-Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 阅读笔记
Posted wyy_persist
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测基础学习-Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 阅读笔记相关的知识,希望对你有一定的参考价值。
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
阅读笔记
//2022.1.2日 阅读总结
推荐阅读 SPPNet Fast RCNN FCN VGG-16 OverFeat
论文的主要贡献
引入了区域建议网络-RPN,该网络可以和Fast RCNN共享全图像的卷积特征(主要是在卷积层的最后一层的feature map实现共享)。
论文使用的模型方法
使用RPN找到区域建议,并引入锚,然后使用Fast RCNN在生成的区域建议中进行分类。
RPN 网络
使用全卷积神经网络(FCN)以图像作为输入,经过RPN网络之后输出区域建议(矩形框)。RPN和Fast RCNN公用一个卷积层集。下图为Faster RCNN框架结构。
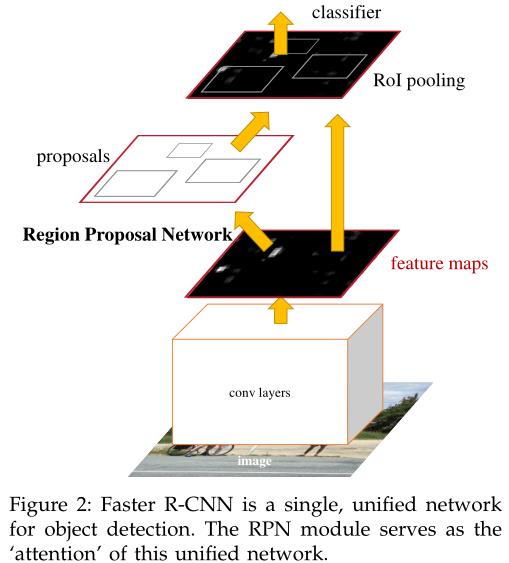
Faster RCNN框架结构
RPN的实现
在最后一个共享卷积层输出的卷积特征图上滑动一个窗口。窗口以最后一个卷积层的输出n × n空间窗口作为输入。每一个滑动窗口被映射到一个低维的特征(ZF为256-d, VGG为512-d,后面均跟着ReLu激活函数)。该特性被提供给两个同级的完全连接层——一个框回归层(reg)和一个框分类层(cls)。
对RPN中锚的解释
在每个滑动窗口的位置,作者同时预测多个地区的提议,在最大可能的提案的数量为每个位置表示为k。所以reg层输出4 k个编码来表示k个框的坐标,同时cls层输出2 k个分数估计每个区域建议为对象或不是对象的概率。这k个区域建议是相对于k个参考盒参数化的,作者称之为锚。
锚定位于所讨论的滑动窗口的中心,并与比例和宽高比相关联(如下图)。默认情况下,作者使用3个尺度和3个纵横比,在每个滑动位置提供k = 9个锚。对于大小为W × H(通常为~ 2400)的卷积feature map,总共有W H k anchor。
下图左边即为RPN网络示意图。
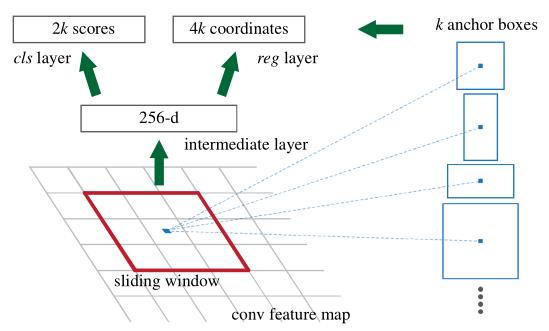
RPN网络示意图
平移不变锚
RPN中的锚具有平移不变的性质。无论是就锚点而言,还是相对于锚点的计算区域的函数而言。如果一个人在一个图像中翻译一个对象,区域建议应该平移并且相同的函数应该能够在任何位置预测区域建议。这个平移不变性质是由作者的方法保证的。作为比较,MultiBox方法使用k-means生成800个锚,这些锚不是平移不变的。因此,MultiBox不能保证在转换对象时生成相同的提案。
RPN使用锚的好处
平移不变的性质减小了模型的尺寸。MultiBox有一个(4 + 1)× 800维的全连接输出层,而作者的方法在k = 9锚的情况下有一个(4 + 2)× 9维的卷积输出层。因此,作者的输出层有2.8 × 104个参数(VGG-16为512 × (4 + 2) × 9),比MultiBox的输出层6.1 × 106个参数(MultiBox[27]中googlet[34]为1536 × (4 + 1) × 800)少两个数量级。如果考虑到特征投影层,作者的提案层的参数仍然比MultiBox6少一个数量级。作者希望他们的方法在小数据集(如PASCAL VOC)上过拟合的风险更小。
多尺度锚点作为回归参考
使用锚的方法只依赖于单一比例尺的图像和feature map,并使用单一尺寸的过滤器(feature map上的滑动窗口)。
由于锚点的设计,该方法可以使用单尺度图像上计算的卷积特征。这个是共享特征而无需额外的计算成本的关键组成部分。
Faster RCNN的损失函数
给满足以下条件的锚分配二进制标签:
- 与ground-truth box重叠程度最高的锚/锚;
- 与任何ground-truth box 的IoU重叠大于0.7的锚;
由于第二个条件可能找不到正样本,所以仍然使用第一个条件。
使用的Loss函数遵循Fast RCNN的loss function
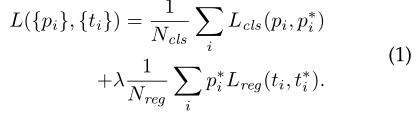
上述公式中的i是锚点在一个小batch-size处理中的索引,pi是锚点i成为一个对象的预测概率。如果锚是正的,那么Ground-truth标签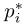 为1,,否则,标签为0。其中的ti是bounding box的四个参数化坐标,并且
为1,,否则,标签为0。其中的ti是bounding box的四个参数化坐标,并且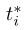 是和正锚相关联的ground-truth box的四个参数化坐标。
是和正锚相关联的ground-truth box的四个参数化坐标。
用于分类的损失函数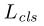 是两个类(是对象或不是对象)的log 损失函数。
是两个类(是对象或不是对象)的log 损失函数。
对区域损失函数,使用的是: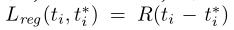 ,其中R是鲁棒损失函数(平滑L1)。其中的
,其中R是鲁棒损失函数(平滑L1)。其中的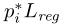 表示回归损失仅对阳性锚点激活( = 1),否则失效(= 0)。 cls和reg层的输出分别由pi和ti组成。
表示回归损失仅对阳性锚点激活( = 1),否则失效(= 0)。 cls和reg层的输出分别由pi和ti组成。
同时,上述公式中还使用Ncls和Nreg对两项进行归一化,用平衡参数λ加权。注意:上述公式中的cls项使用小批量标准化(Ncls = 256),而reg项由锚点的数量标准化(即Nreg ~ 2400)。默认情况下,作者设置λ = 10,因此cls和reg条款的权重大致相等。默认情况下,作者设置λ = 10,因此cls和reg条款的权重大致相等。
对bounding box的回归,采用以下4个参数化坐标的参数化:
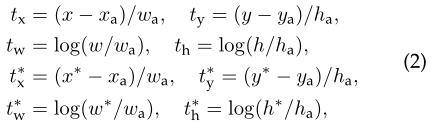
其中x、y、w和h表示盒子的中心坐标及其宽度和高度。变量x, xa和x∗分别用于预测框,锚定框和groundtruth框(同样用于y, w, h)。这可以看作从anchor box回归到附近的ground-truth box的bounding box。
上述实现bounding box回归的方式不同于以往基于RoI (Region of Interest)的方法。在以往的方法中,对从任意大小的RoI汇集的特征进行bounding box回归,回归权值由所有区域的不同尺寸所共享。在作者的公式中,用于回归的特征在feature map上具有相同的空间大小(3 × 3)。为了解释不同的大小,作者学习了一组k个限制box回归器。每个回归量负责一个尺度和一个纵横比,k个回归量不共享权重。因此,尽管功能具有固定的大小/规模,但仍有可能预测各种大小的盒子,这要归功于锚的设计。
RPN网络的训练
使用反向传播和随机梯度下降(SGD)对RPN进行端到端的训练。
从标准偏差为0.01的零均值高斯分布中提取权重来随机初始化所有新层。所有其他层(即共享卷积层)都是通过对ImageNet分类的模型进行预训练来初始化的,这是标准实践。作者调优ZF网的所有层,以及VGG网的conv3 1和以上,以节省内存。作者对PASCAL VOC数据集上的60k个小批量使用0.001的学习率,对接下来的20k个小批量使用0.0001的学习率。作者使用0.9的动量和0.0005的权值衰减。作者的实现使用Caffe。
RPN和Fast RCNN共享特征解释
两个网络使用共享特征需要采用四步交替训练实现:
第一步。训练RPN网络,使用ImageNet的预训练模型进行初始化,并同时对区域建议进行端到端的微调。
第二步,利用第一步中生成的RPN区域建议,用Fast RCNN独立训练一个检测网络。该网络同时也由ImageNet预训练模型进行初始化。
第三步,使用检测器网络来初始化RPN训练,但是修复了共享的卷积层,只微调RPN特有的层。
最后,保持共享的卷积层固定,微调Fast RCNN的特有层。
可以对上述过程进行多次迭代,但是得到的改进可以忽略。
实现过程中需要注意的地方
对跨图像边界的锚点,选择了忽略,所以不会造成损失。
对于一个典型的1000 × 600的图像,大约需要20000个锚(≈60 × 40 × 9)。在忽略跨界锚点的情况下,每幅图像大约有6000个锚点用于训练。如果在训练中不忽略跨界异常值,则会在目标中引入较大且难以修正的误差项,训练不收敛。然而,在测试过程中,作者仍然将全卷积RPN应用于整个图像。这可能会生成跨边界的建议框,作者将其剪辑到图像边界。
RPN产生重叠框的处理办法
一些RPN提案彼此高度重叠。为了减少冗余,作者根据提议区域的cls分数对提议区域采用非最大抑制(non-maximum suppression, NMS)。作者将网管的IoU阈值定在0.7,这使得作者每幅图像大约有2000个建议区域。正如作者将展示的,NMS并不会损害最终的检测精度,但会大大减少提案的数量。网管之后,作者使用排名前n的提议区域进行检测。
本阅读笔记仅作为日后复习时使用,并无他用。
以上是关于目标检测基础学习-Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 阅读笔记的主要内容,如果未能解决你的问题,请参考以下文章
深度学习和目标检测系列教程 7-300:先进的目标检测Faster R-CNN架构
MATLAB深度学习采用Faster R-CNN实现车辆目标检测