用YOLOv5ds训练自己的数据集——同时检测和分割
Posted 2021黑白灰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用YOLOv5ds训练自己的数据集——同时检测和分割相关的知识,希望对你有一定的参考价值。
非常感谢作者midasklr的开源项目!
源码地址:
关于作者:
CSDN:MidasKing的博客_CSDN博客-目标检测,python,opencv领域博主
GitHub:midasklr (github.com)
参考博文:
yolov5ds/READMECH.md at main · midasklr/yolov5ds (github.com)
Yolov5同时进行目标检测和分割分割_MidasKing的博客-CSDN博客_yolov5实例分割
用YOLOv5ds训练自己的数据集,注意点!_用猪头过日子.的博客-CSDN博客
0、配置环境
不在赘述,跟YOLOv5差不多
1、下载预训练模型——推荐
在yolov5ds-main根目录新建weights文件夹
下载yolov5预训练模型Releases · ultralytics/yolov5 · GitHub放到weights文件夹中
我下载的是yolov5s.pt,下面均以yolov5s.pt为例
2、准备数据集——非常关键
在yolov5ds-main根目录新建paper_data文件夹
paper_data文件夹下新建det和seg两个文件夹
det文件夹存放检测数据集
seg文件夹存放分割数据集
2-1、det文件夹下
Annotations文件夹下存放xml文件
images文件夹下存放图像
注:xml文件应和对应图像名称相同
det文件夹下新建一个生成.py文件,使用下面代码生成ImageSets,里面有一个Main文件夹,Main文件夹里包括test.txt、train.txt、trainval.txt、val.txt四个文本文档
trainval.txt包含你数据集里所有图像名称
train.txt为数据集的训练集,为总数据集的90%
val.txt为数据集的验证集,为总数据集的10%
test.txt文件里是空的不用担心,因为没有划分测试集
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改xml一般存放在Annotations下
parser.add_argument('--xml_path', default='/home/dell/yolov5ds-main/paper_data/det/Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='/home/dell/yolov5ds-main/paper_data/det/ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
在det文件夹下新建一个voc_labels.py文件,使用下面的程序将xml转换为yolo用的txt格式数据集
注意修改数据集路径、类别,注意自己的图像是jpg还是png格式
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["feed", "person", "railing", "obstacle", "road", "cow"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('/home/dell/yolov5ds-main/paper_data/det/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('/home/dell/yolov5ds-main/paper_data/det/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
# difficult = obj.find('difficult').text
difficult = obj.find('difficult').text###
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('/home/dell/yolov5ds-main/paper_data/det/labels/'):
os.makedirs('/home/dell/yolov5ds-main/paper_data/det/labels/')
image_ids = open('/home/dell/yolov5ds-main/paper_data/det/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('./%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/images/%s.png\\n' % (image_id))
convert_annotation(image_id)
list_file.close()
运行之后会在det目录下生成train.txt、test.txt、val.txt三个文件,对应的图像名称前加入了绝对路径
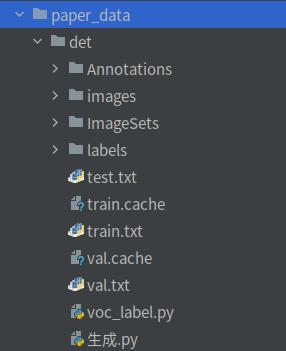
这是det文件夹结构
2-2、seg文件夹下
images存放图像
labels存放分割图像,类似下面这种图
注:labels图像应和images对应图像名称相同,包括格式,包括前面的det文件夹里的图像,要么都是001.png要么都是001.jpg


这种图是用labelme标注后,使用labelme里自带的一个程序生成,具体操作自行百度
可以参考一下下面这个,就类似 用maskrcnn训练自己的数据集 这种博文一般都会教给你
用自己的数据集训练maskrcnn_沙雅云的博客-CSDN博客_maskrcnn训练自己的数据集
images和labels文件夹分别新建train、val两个文件夹
这里的train和val里的图 要与 上述提到的det/Main/train.txt和val.txt里分好的相对应
我的样本量不大,是自己一个一个对应拖进去的
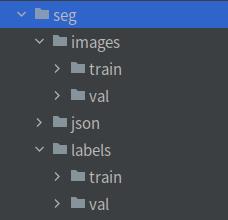
这是seg文件夹结构(忽略那个json文件夹,那里面存放的为json文件,训练模型用不上)
到这里检测和分割数据集就做好了
3、配置文件参数修改
3-1、models/segheads.yaml
segnc改为自己的类别数
3-2、data/voc.yaml
train改为自己det文件夹下train.txt路径
val改为自己det文件夹下val.txt路径
road_seg_train改为自己seg文件夹下images/train文件夹路径
road_seg_val改为自己seg文件夹下images/val文件夹路径
nc改为自己的类别数
segnc改为自己的类别数
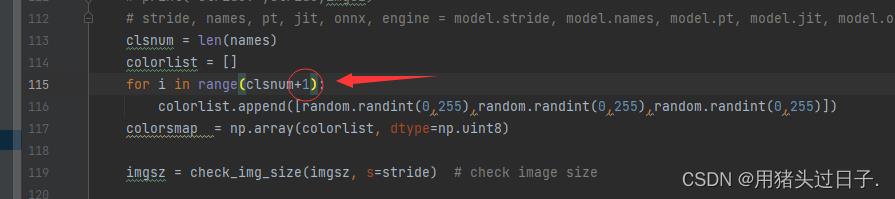
segnc改为自己的类别数+1也可以(会导致预测失败,解决:detectds.py 121行clsnum改为clsnum+1)
参考:用YOLOv5ds训练自己的数据集,注意点!_用猪头过日子.的博客-CSDN博客
3-3、models/yolov5s.yaml
nc改为自己的类别数
3-4、trainds.py
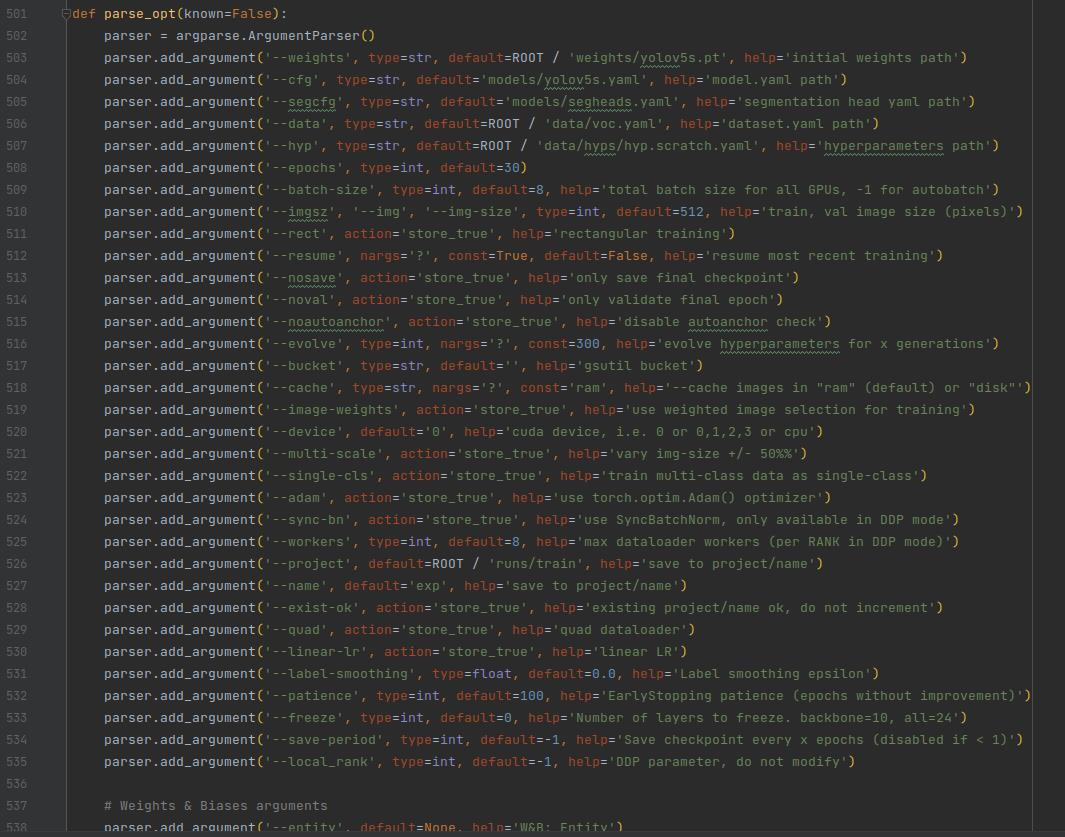
parse_opt函数下(501行)修改对应default里面的内容
--weights weights/yolov5s.pt
--cfg models/yolov5s.yaml
--segcfg models/segheads.yaml
--data data/voc.yaml
--epochs 一般为300
--device 0
--batch-size 根据显卡算力设置,训练提醒显存分配不够或无法找到有效cuDnn时,减小数值报错参考:
1、AttributeError: 'NoneType' object has no attribute 'flatten':可以检查一下自己的图像是不是都为png或jpg
2、评论区
 https://blog.csdn.net/sadjhaksdas/article/details/125762260
https://blog.csdn.net/sadjhaksdas/article/details/125762260RuntimeError: Unable to find a valid cuDNN algorithm to run convolution_2021黑白灰的博客-CSDN博客 https://blog.csdn.net/qq_57076285/article/details/123842670?spm=1001.2014.3001.5501RuntimeError: weight tensor should be defined either for all or no classes_2021黑白灰的博客-CSDN博客https://blog.csdn.net/qq_57076285/article/details/123698025?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_57076285/article/details/123842670?spm=1001.2014.3001.5501RuntimeError: weight tensor should be defined either for all or no classes_2021黑白灰的博客-CSDN博客https://blog.csdn.net/qq_57076285/article/details/123698025?spm=1001.2014.3001.5501
下面是我的配置参数,仅供参考
4、开始训练
python trainds.py5、检测
配置参数修改类似trainds.py,如遇报错可评论区
python detectds.py常见错误:RuntimeError: Input type (torch.cuda.HalfTensor) and weight type (torch.HalfTensor)
解决:model = ckpts['model']的下一行加入model.cuda()
如果还有其他问题:
参考:
以上是关于用YOLOv5ds训练自己的数据集——同时检测和分割的主要内容,如果未能解决你的问题,请参考以下文章