CUDA加速计算的基础C/C++
Posted 帝王铠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CUDA加速计算的基础C/C++相关的知识,希望对你有一定的参考价值。
本文是Nvidia 90美金的课程笔记
无论是从出色的性能,还是从易用性来看,CUDA计算平台都是加速计算的制胜法宝。CUDA 提供了一种可扩展 C、C++、Python 和 Fortran 等语言的编码范式,该范式能够在世界上性能超强劲的并行处理器 NVIDIA GPU 上运行经加速的大规模并行代码。CUDA 可以毫不费力地大幅加速应用程序,具有适用于DNN、BLAS、图形分析和FFT等更多运算的高度优化库生态系统,并且还附带功能强大的命令行和可视化性能分析器。
CUDA 支持以下领域
概念
https://www.nvidia.com/en-us/gpu-accelerated-applications/
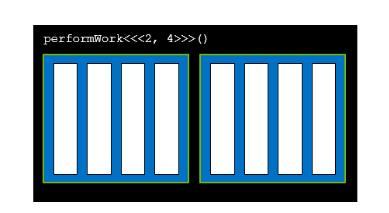
gridDim.x 网格中的块数,图中为2
blockIdx.x网格中块的索引,图中为0,1
blockDim.x块中线程数 图中为4
threadIdx.x块中线程的索引,图中为,0,1,2,3
流多处理器(Streaming Multiprocessors)
统一内存(UM)
nsight-sys
命令示例
nvcc -o vector-add-no-prefetch 01-vector-add/01-vector-add.cu -run
nsys profile --stats=true -o vector-add-no-prefetch-report ./vector-add-no-prefetch
示例一
包含
使用跨网格循环来处理比网格更大的数组
CUDA错误处理功能
#include <stdio.h>
#include <assert.h>
inline cudaError_t checkCuda(cudaError_t result)
if (result != cudaSuccess)
fprintf(stderr, "CUDA Runtime Error: %s\\n", cudaGetErrorString(result));
assert(result == cudaSuccess);
return result;
void initWith(float num, float *a, int N)
for(int i = 0; i < N; ++i)
a[i] = num;
__global__
void addVectorsInto(float *result, float *a, float *b, int N)
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
result[i] = a[i] + b[i];
void checkElementsAre(float target, float *array, int N)
for(int i = 0; i < N; i++)
if(array[i] != target)
printf("FAIL: array[%d] - %0.0f does not equal %0.0f\\n", i, array[i], target);
exit(1);
printf("SUCCESS! All values added correctly.\\n");
int main()
const int N = 2<<20;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
checkCuda( cudaMallocManaged(&a, size) );
checkCuda( cudaMallocManaged(&b, size) );
checkCuda( cudaMallocManaged(&c, size) );
initWith(3, a, N);
initWith(4, b, N);
initWith(0, c, N);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = (N + threadsPerBlock - 1) / threadsPerBlock;
addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N);
checkCuda( cudaGetLastError() );
checkCuda( cudaDeviceSynchronize() );
checkElementsAre(7, c, N);
checkCuda( cudaFree(a) );
checkCuda( cudaFree(b) );
checkCuda( cudaFree(c) );
示例二
包含
查询设备信息
异步内存预取
cudaMemPrefetchAsync(pointerToSomeUMData, size, deviceId);
cudaMemPrefetchAsync(pointerToSomeUMData, size, cudaCpuDeviceId);
将内存预取回CPU
#include <stdio.h>
void initWith(float num, float *a, int N)
for(int i = 0; i < N; ++i)
a[i] = num;
__global__
void addVectorsInto(float *result, float *a, float *b, int N)
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
result[i] = a[i] + b[i];
void checkElementsAre(float target, float *vector, int N)
for(int i = 0; i < N; i++)
if(vector[i] != target)
printf("FAIL: vector[%d] - %0.0f does not equal %0.0f\\n", i, vector[i], target);
exit(1);
printf("Success! All values calculated correctly.\\n");
int main()
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
printf("Device ID: %d\\tNumber of SMs: %d\\n", deviceId, numberOfSMs);
const int N = 2<<24;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c, size);
/*
* Prefetching can also be used to prevent CPU page faults.
*/
cudaMemPrefetchAsync(a, size, cudaCpuDeviceId);
cudaMemPrefetchAsync(b, size, cudaCpuDeviceId);
cudaMemPrefetchAsync(c, size, cudaCpuDeviceId);
initWith(3, a, N);
initWith(4, b, N);
initWith(0, c, N);
cudaMemPrefetchAsync(a, size, deviceId);
cudaMemPrefetchAsync(b, size, deviceId);
cudaMemPrefetchAsync(c, size, deviceId);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = 32 * numberOfSMs;
cudaError_t addVectorsErr;
cudaError_t asyncErr;
addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N);
addVectorsErr = cudaGetLastError();
if(addVectorsErr != cudaSuccess) printf("Error: %s\\n", cudaGetErrorString(addVectorsErr));
asyncErr = cudaDeviceSynchronize();
if(asyncErr != cudaSuccess) printf("Error: %s\\n", cudaGetErrorString(asyncErr));
/*
* Prefetching can also be used to prevent CPU page faults.
*/
cudaMemPrefetchAsync(c, size, cudaCpuDeviceId);
checkElementsAre(7, c, N);
cudaFree(a);
cudaFree(b);
cudaFree(c);
示例三
包含CUDA并发流
cudaStream_t stream; // CUDA流的类型为 cudaStream_t
cudaStreamCreate(&stream); // 注意,必须将一个指针传递给 cudaCreateStream
someKernel<<<number_of_blocks, threads_per_block, 0, stream>>>(); // stream 作为第4个EC参数传递
cudaStreamDestroy(stream); // 注意,将值(而不是指针)传递给 cudaDestroyStream
流用于并行进行数据初始化的核函数
#include <stdio.h>
__global__
void initWith(float num, float *a, int N)
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
a[i] = num;
__global__
void addVectorsInto(float *result, float *a, float *b, int N)
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
result[i] = a[i] + b[i];
void checkElementsAre(float target, float *vector, int N)
for(int i = 0; i < N; i++)
if(vector[i] != target)
printf("FAIL: vector[%d] - %0.0f does not equal %0.0f\\n", i, vector[i], target);
exit(1);
printf("Success! All values calculated correctly.\\n");
int main()
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
const int N = 2<<24;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c, size);
cudaMemPrefetchAsync(a, size, deviceId);
cudaMemPrefetchAsync(b, size, deviceId);
cudaMemPrefetchAsync(c, size, deviceId);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = 32 * numberOfSMs;
cudaError_t addVectorsErr;
cudaError_t asyncErr;
/*
* Create 3 streams to run initialize the 3 data vectors in parallel.
*/
cudaStream_t stream1, stream2, stream3;
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
cudaStreamCreate(&stream3);
/*
* Give each `initWith` launch its own non-standard stream.
*/
initWith<<<numberOfBlocks, threadsPerBlock, 0, stream1>>>(3, a, N);
initWith<<<numberOfBlocks, threadsPerBlock, 0, stream2>>>(4, b, N);
initWith<<<numberOfBlocks, threadsPerBlock, 0, stream3>>>(0, c, N);
addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N);
addVectorsErr = cudaGetLastError();
if(addVectorsErr != cudaSuccess) printf("Error: %s\\n", cudaGetErrorString(addVectorsErr));
asyncErr = cudaDeviceSynchronize();
if(asyncErr != cudaSuccess) printf("Error: %s\\n", cudaGetErrorString(asyncErr));
cudaMemPrefetchAsync(c, size, cudaCpuDeviceId);
checkElementsAre(7, c, N);
/*
* Destroy streams when they are no longer needed.
*/
cudaStreamDestroy(stream1);
cudaStreamDestroy(stream2);
cudaStreamDestroy(stream3);
cudaFree(a);
cudaFree(b);
cudaFree(c);
示例四
手动内存管理CUDA API 调用的代码。
手动分配主机和设备内存
使用流实现数据传输和代码的重叠执行
核函数和内存复制回主机重叠执行
int *host_a, *device_a; // Define host-specific and device-specific arrays.
cudaMalloc(&device_a, size); // device_a is immediately available on the GPU.
cudaMallocHost(&host_a, size); // host_a is immediately available on CPU, and is page-locked, or pinned.
initializeOnHost(host_a, N); // No CPU page faulting since memory is already allocated on the host.
// cudaMemcpy takes the destination, source, size, and a CUDA-provided variable for the direction of the copy.
cudaMemcpy(device_a, host_a, size, cudaMemcpyHostToDevice);
kernel<<<blocks, threads, 0, someStream>>>(device_a, N);
// cudaMemcpy can also copy data from device to host.
cudaMemcpy(host_a, device_a, size, cudaMemcpyDeviceToHost);
verifyOnHost(host_a, N);
cudaFree(device_a);
cudaFreeHost(host_a); // Free pinned memory like this.
#include <stdio.h>
__global__
void initWith(float num, float *a, int N)
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
a[i] = num;
__global__
void addVectorsInto(float *result, float *a, float *b, int N)
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
result[i] = a[i] + b[i];
void checkElementsAre(float target, float *vector, int N)
for(int i = 0; i < N; i++)
if(vector[i] != target)
printf("FAIL: vector[%d] - %0.0f does not equal %0.0f\\n", i, vector[i], target);
exit(1);
printf("Success! All values calculated correctly.\\n");
int main()
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
const int N = 2<<24;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
float *h_c;
cudaMalloc(&a, size);
cudaMalloc(&b, size);
cudaMalloc(&c, size);
cudaMallocHost(&h_c, size);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = 32 * numberOfSMs;
cudaError_t addVectorsErr;
cudaError_t asyncErr;
/*
* Create 3 streams to run initialize the 3 data vectors in parallel.
*/
cudaStream_t stream1, stream2, stream3;
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
cudaStreamCreate(&stream3);
/*
* Give each `initWith` launch its own non-standard stream.
*/
initWith<<<numberOfBlocks, threadsPerBlock, 0, stream1>>>(3, a, N);
initWith<<<numberOfBlocks, threadsPerBlock, 0, stream2>>>(4, b, N);
initWith<<<numberOfBlocks, threadsPerBlock, 0, stream3>>>(0, c, N);
for (int i = 0; i < 4; ++i)
cudaStream_t stream;
cudaStreamCreate(&stream);
addVectorsInto<<<numberOfBlocks/4, threadsPerBlock, 0, stream>>>(&c[i*N/4], &a[i*N/4], &b[i*N/4], N/4);
cudaMemcpyAsync(&h_c[i*N/4], &c[i*N/4], size/4, cudaMemcpyDeviceToHost, stream);
cudaStreamDestroy(stream);
addVectorsErr = cudaGetLastError();
if(addVectorsErr != cudaSuccess) printf("Error: %s\\n", cudaGetErrorString(addVectorsErr));
asyncErr = cudaDeviceSynchronize();
if(asyncErr != cudaSuccess) printf("Error: %s\\n", cudaGetErrorString(asyncErr));
checkElementsAre(7, h_c, N);
/*
* Destroy streams when they are no longer needed.
*/
cudaStreamDestroy(stream1);
cudaStreamDestroy(stream2);
cudaStreamDestroy(stream3);
cudaFree(a);
cudaFree(b);
cudaFree(c);
cudaFreeHost(h_c);
练习作业
https://yangwc.com/2019/06/20/NbodySimulation/
以上是关于CUDA加速计算的基础C/C++的主要内容,如果未能解决你的问题,请参考以下文章
GPUNvidia CUDA 编程基础教程——使用 CUDA C/C++ 加速应用程序