模型推理那些事
Posted shichaog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型推理那些事相关的知识,希望对你有一定的参考价值。
模型推理那些事
目前主流的深度学习框架有目前越来越多的深度学习框架、工具集以及定制化硬件使得构建、部署和跨框架管理深度学习越来越复杂。常用的深度学习框架有TensorFlow、Pytorch、MXNet和CNTK,因为训练最为耗时,所以常使用GPU、FPGA、TPU和ASIC等硬件加速模块缩短训练耗时,这些定制化的硬件需要使用定制化的驱动和库以便和深度学习框架交互。NVIDIA CUDA/cuDNN和Intel的OneDNN是这种情况的两个例子。当训练结束得到最终模型之后,部署阶段的平台可以是公有云、电脑、手机以及嵌入式设备等,为了加速前向计算,常用不同的AI加速器,如NVIDIA Jetson家族,Intel Movidius and Myriad VPU, Google Edge TPU and Qualcomm Adreno GPU 等,和训练端类似,需要使用专用的驱动包以便使用这些硬件,如NVIDIA JetPack, Intel OpenVINO Toolkit, Google TensorFlow Lite and Qualcomm Neural Processing SDK 。训练的模型一般要经过优化以便充分利用硬件和软件包。
由于硬件和软件的差异性使得模型之间的互操作性、训练和部署的一致性不够友好,比如使用Tensorflow训练的模型对于PyTorch开发者。
模型训练常基于python,常用框架包括TensorFlow,pytorch,
从执行效率上来讲,汇编是最快耗资源最合理的,c语言次之,python在次之,从开发效率上来讲,python最高,c语言次之,汇编最差;编译器和解释器平衡了开发效率和执行效率。在深度学习领域,倾向于使用高级语言python做为开发,以便模型的快速迭代,在部署领域,倾向于使用c/c++语言做应用部署。通常编译好的c语言比python快10到100倍,python是更高层次的编程语言,其处理了和计算机相关的内存管理、指针等。但是c语言的开发时间比python长很多,因此绝大多数深度学习的项目使用python开发和训练模型,使用c/c++在生产环境部署模型(运算资源和存储资源紧张)。c语言在编译时就被编译成了机器码,运行的时候直接执行机器码,而python是在运行时解释的。其它解释性语言,如java字节码或者.NET字节码比python快的原因是其通常包含了JIT编译器,其在运行时将字节码编译成机器码。由于python的动态特性使得给CPython编写JIT编译器非常困难。
在一些深度学习部署框架里,通常采用JIT(或者私有化的小型JIT)以充分使用硬件资源来加速深度学习计算运算符,如卷积运算等。
所以在模型生产环境(也称部署环境),通常使用c/c++实现一个深度学习计算库,TensorFlow lite采用了先用flatbuffer技术序列化freeze的模型(减小模型size),然后使用被称为深度学习引擎的模块反序列化并执行模型,这在桌面和移动平台比较常见,如笔记本电脑、智能手机等;在嵌入式IOT场景等一些场景,也有直接导出模型参数并根据模型使用的对应c/c++运算符直接实现这一功能的,这在嵌入是场景比较场常见,如MCU,DSP等。
IOT场景由于运算单元的硬件特性通常比较少,因而手动逐个运算符优化以达到最优,对于移动桌面等场景,为保证一定的灵活性,使用c/c++实现的深度学习计算库,同一个模型会运行在硬件特性差异较大的处理器上,如CPU,GPU,CPU的SIMD特性差异等,这时会使用JIT技术,在运行时针对耗时的运算符(或者调用次数较多的运算符)进行一次性优化。大多数的开源深度学习库是提供这些特性的。
pytorch模型部署的常用torchscript/libtorch,Caffe2,ONNX。
运行时格式Onnxruntime,Glow,TensorRT,TVM。
pytorch 模型部署
使用torch script部署模型的步骤如下:
1.将pytorch模型转换成Torch Script格式;
2.将script化模型序列化到文件;
3.使用c++加载序列化的script模型;
4.在c++中执行加载的脚本;
pytorch lightning 模型部署
pytorch lightning提供导出到ONNX的函数,这是得部署时可以完全脱离pytorch。为了将模型导出为ONNX格式,需要使用to_onnx函数,
filepath = 'model.onnx'
model = SimpleModel()
input_sample = torch.randn((1, 64))
model.to_onnx(filepath, input_sample, export_params=True)
如果example_input_array在LightningModule已经设置,则这里可以不需要input_sample。一旦模型导出成功,则可以使用下述方法调用ONNX计算。
ort_session = onnxruntime.InferenceSession(filepath)
input_name = ort_session.get_inputs()[0].name
ort_inputs = input_name: np.random.randn(1, 64).astype(np.float32)
ort_outs = ort_session.run(None, ort_inputs)
导出到TorchScript,TorchScript可以序列化模型使其可以在非python环境中被调用,*to_torchscript()*函数用于将LightningModule导出为TorchScript格式。
model = SimpleModel()
script = model.to_torchscript()
# save for use in production environment
torch.jit.save(script, "model.pt")
ONNX
主要目的是解决从开发到部署之间的鸿沟。其支持TensorFlow,Pytorch,Caffe2等各种深度学习框架,由于其支持硬件加速特性,因而用于前向计算的效率较高。官网地址https://github.com/onnx/
人工智能工具之间需要更大的互操作性,许多人都在开发优秀的工具,但开发人员往往被一个框架或生态系统所束缚。ONNX是通过允许这些工具可以共享模型,是工具间能协同工作的第一步。ONNX提供了可扩展计算图定义、内置运算符和标准数据类型定义。
每一个计算数据流图都被构造成一个无环图的节点列表。节点有一个或多个输入和一个或多个输出。每个节点都是对运算符的调用。计算数据流图还包含元数据,以帮助记录其用途,如记录作者信息等。
操作符是在计算数据流图外部实现的,但是内置操作符集可以跨框架移植,每个支持ONNX的框架都将在其适用的数据类型上实现这些操作符。
JIT
编译器属于AOT(Ahead of Time)范畴,即在程序执行之前就确定了最终的机器码,CPU指令并不是瞬间执行完毕的,其要经过取指令、译码、执行、结果回写。为了执行效率,后一条指令不会等到前一条执行结果回写完成才进行取指,使用流水线技术在前一条指令在译码时,后一条执行就在在取指了,为了效率流水的层级会增加,核心执行单元也会增加,所以在遇到for语句时,其边界判断条件(无法执行前确定的变量值)不满足时会打断流水线,如果for内的语句连续执行较多次(理论上越多越好)再打断流程,那么效率上这种是最优的,编译器编译出来的代码就是这样的,但是如果这个无法执行前确定的变量边界条件使得for内循环语句执行较少的次数流水就会被打断,那么代码的执行效率就不高。在深度学习领域,卷积核的大小通常不多,channel数也不多,NCHW,多重循环导致流水打断的次数太多而效率低,为了提升效率,使用JIT(Just In Time)技术减少流程被打算的次数,即在执行时根据确定的边界值执行优化。很多深度学习部署库都使用这一技术。
看下面一段代码,摘自https://blog.quarkslab.com/easyjit-just-in-time-compilation-for-c.html
static void kernel(const char* mask, unsigned mask_size, unsigned mask_area,
const unsigned char* in, unsigned char* out,
unsigned rows, unsigned cols, unsigned channels)
unsigned mask_middle = (mask_size/2+1);
unsigned middle = (cols+1)*mask_middle;
for(unsigned i = 0; i != rows-mask_size; ++i)
for(unsigned j = 0; j != cols-mask_size; ++j)
for(unsigned ch = 0; ch != channels; ++ch)
long out_val = 0;
for(unsigned ii = 0; ii != mask_size; ++ii)
for(unsigned jj = 0; jj != mask_size; ++jj)
out_val += mask[ii*mask_size+jj] * in[((i+ii)*cols+j+jj)*channels+ch];
out[(i*cols+j+middle)*channels+ch] = out_val / mask_area;
上述可以看成是图像处理的代码,rows和cols分别标识图像的行和列,而channels表示的是RGB通道数,这通常取决于硬件,偶尔改变,mask,mask_sizeandmask_area参数取决于输入,这取决于硬件和用户感兴趣的区域,通常这些参数偶尔改变,然而在编译时却无法确定该值,如果事先知道这些值,那么编译器就可以进行优化以提高执行效率,如果上述边界条件在首次执行时能确定,那么编译器可以展开循环以避免流水线被打断,深度学习中,部署模型一旦确定,那么模型每层的运算就唯一确定了,JIT的机制是在模型首次计算时,确定这些这些参数,并且根据这些确定的参数调用编译器优化后续的执行效率。
编写JIT例子
解释器(以brainf*ck 语言为例)该语言和c的对照是:
| brainfuck command | C equivalent |
|---|---|
| (Program Start) | char ptr[30000] = 0; |
| > | ++ptr; |
| < | –ptr; |
| + | ++*ptr; |
| - | –*ptr; |
| . | putchar(*ptr); |
| [ | while (*ptr) |
| ] |
++++++++ #将cell0 赋值8,+是增加一的意思
>++++++ #将cell1赋值6, >是将指针右移动1(cell1),然后对赋值6(共6个+)
[<+.>-] #loop循环,每一个循环先增加cell0的值然后打印该值,然后减少cell1减一,并检查其结果,是0则终止循环
struct program
std::string instructions;
program paser_from_stream(std::istream & stream)
program program;
for(std::string line; std::getline(stream, line);)
for(auto c : line)
if(c == '>' || c == '<' || c == '+' || '-' || c=='.' || c== ',' ||
c == '[' || c == ']')
program.instructions.push_back(c);
return program;
JIT主要包括运行时创建机器码和运行时运行机器码两个部分。
https://github.com/sol-prog/x86-64-minimal-JIT-compiler-Cpp
https://github.com/spencertipping/jit-tutorial
void (*func)();
12 // Cast the address of our generated code to a function pointer and call the function
13 func = (void (*)()) mem;
14 func();
Intel公司(oneDNN)
oneAPI Deep Neural Network Library(oneDNN)是Intel开源的跨平台高性能计算库,该库针对Intel CPU,Intel GPU进行了优化,并且集成了Arm Compute Library 以提高ARM64(目前的1.7版本还处在试验阶段)平台应用程序的性能。使用OneDNN能够提升深度学习应用和框架的计算速度和效率。OneDNN在运行时会检测指令集ISA(Instruction Set Architecture)并且为支持ISA的指令生成优化的代码。OneDNN官方参考文档链接。
oneDNN的编译
#download source
git clone https://github.com/oneapi-src/oneDNN.git
#Linux或macOS平台
mkdir -p build && cd build
#原生平台编译
cmake .. <extra build options>
#交叉编译,Intel是主机,编译AArch64架构
export CC=aarch64-linux-gnu-gcc
export CXX=aarch64-linux-gnu-g++
cmake .. \\
-DCMAKE_SYSTEM_NAME=Linux \\
-DCMAKE_SYSTEM_PROCESSOR=AARCH64 \\
-DCMAKE_LIBRARY_PATH=/usr/aarch64-linux-gnu/lib \\
<extra build options>
#交叉编译,使用Arm Compute Library编译
export ACL_ROOT_DIR=<path/to/Compute Library>
cmake .. \\
-DDNNL_AARCH64_USE_ACL=ON \\
<extra build options>
#编译和安装
make -j8
make doc
make install
成功生成镜像之后的内容如下:

可以使用测试命令ctest测试编译的正确性。

链接到OneDNN
g++ -std=c++11 -I$DNNLROOT/include -L$DNNLROOT/lib simple_net.cpp -ldnnl
clang++ -std=c++11 -I$DNNLROOT/include -L$DNNLROOT/lib simple_net.cpp -ldnnl
oneDNN编程模型
OneDNN 编程的术语包括原语(Primitives),引擎( Engines), Streams,和 内存对象(Memory Objects),本质上,oneDNN编程模型包括执行一个或多个原语来处理一个或多个内存对象中的数据,处理在引擎中完成。下图展示了它们之间的关系,方块内容是是OneDNN的对象,箭头显示了对象间的依赖关系。
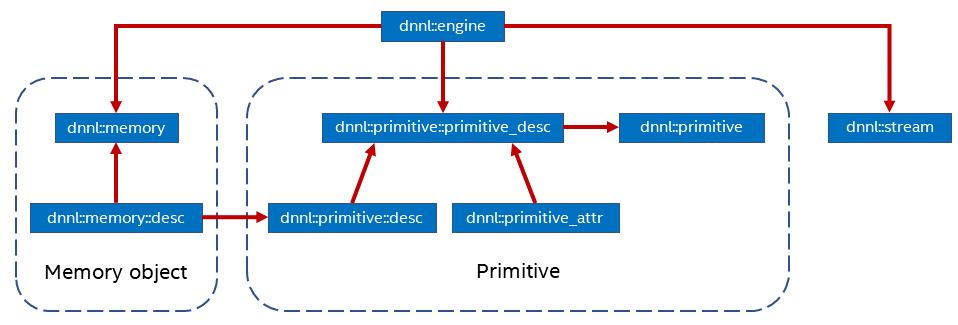
- 原语
OneDNN是围绕原语(dnnl::primitive)的概念建城的,原语是封装了如前向卷积、反向LSTM或者数据变换之类计算的函数对象,使用原语属性(dnnl::primitive_attr)可以级联简单的原语,如前向卷积之后加一个ReLU计算,原语和函数的最大差别是原语可以保存状态。
- 引擎
引擎(dnnl::engine)是一个抽象的计算资源,如CPU、GPU等,除了reorder原语用于两个引擎间传递数据外,其它引擎都是在特定的引擎上执行。
- 流对象
流(dnnl::stream)将计算的上下文和特定的引擎关联起来,
- 内存对象
内存对象dnnl::memory封装了分配给特定引擎的内存管理方法。
oneDNN使用实例
在使用oneDNN时需要包含公共的头文件dnnl.hpp头文件,在debug模式下,可以dnnl_debug.h头文件。所有的内存和原语对象是和特定的引擎关联的(dnnl::engine),原语是针对具体硬件优化过的,内存对象也是和特定引擎相关的,所以针对某一引擎创建的额内存和原语对象是不能用于另一个对象的。
引擎和流
创建引擎时需要指定引擎的类型和所使用处理单元的索引,引擎的类型使用dnnl::engine::kind 类型定义,可以是CPU、GPU或者任何类型,
engine eng(engine_kind, 0);
引擎关联的原语要执行需要用到dnnl::stream ,该类封装了执行的上下文并和特定的引擎绑定,流的创建较为简单。
stream engine_stream(eng);
oneDNN 内存对象
以NCHW类型的卷积为例,可以将其认为是图片数据,这些数据在进行卷积计算时,需要封装到dnnl::memory对象以便可以将其传送到原语里,dnnl::memory对象的创建包括dnnl::memory::desc 结构体(仅包含数据信息而不包括实质上的数据)初始化和dnnl::memory自身创建。
//创建内存信息对象
auto src_md = memory::desc(
N, C, H, W, // logical dims, the order is defined by a primitive
memory::data_type::f32, // tensor's data type
memory::format_tag::nhwc // memory format, NHWC in this case
);
//根据引擎和内存信息对象,创建内存对象
// src_mem contains a copy of image after write_to_dnnl_memory function
auto src_mem = memory(src_md, eng);
write_to_dnnl_memory(image.data(), src_mem);
// For dst_mem the library allocates buffer
auto dst_mem = memory(src_md, eng);
src_md描述的数据信息,包括维度次序、排布方式和数据类型,不同的原语数据的维度信息会不一样,但是这一枚举类型都定义好了,image.data()是原始图像数据存放地址。
原语对象
接下来是原语创建,不同的深度学习OP对应的原语是有区别的,创建分三个步骤,分别是初始化操作描述符、初始化原语描述符、和原语创建,这里以ReLU为例, dnnl::eltwise_forward::desc是描述了具体运算的操作描述符,dnnl::eltwise_forward::primitive_desc)是原语描述符,dnnl::eltwise_forward是创建的原语的类型。代码段如下:
// ReLU op descriptor (no engine- or implementation-specific information)
auto relu_d = eltwise_forward::desc(
prop_kind::forward_inference, algorithm::eltwise_relu,
src_md, // the memory descriptor for an operation to work on
0.f, // alpha parameter means negative slope in case of ReLU
0.f // beta parameter is ignored in case of ReLU
);
// ReLU primitive descriptor, which corresponds to a particular
// implementation in the library
auto relu_pd
= eltwise_forward::primitive_desc(relu_d, // an operation descriptor
eng // an engine the primitive will be created for
);
// ReLU primitive
auto relu = eltwise_forward(relu_pd); // !!! this can take quite some time
oneDNN使用_md后缀标识内存描述符(memory descriptor),_d标识描述符,_pd标识原语描述符,原语自身无后缀。
执行原语
输入输出内存对象通过<tag, memory>映射将其传递给execute()方法,所有的原语都需要输入和输出内存对象,所有的原语都是在stream中得到执行,execute()函数的第一个参数指定stream对象,stream对象的不同,执行可以分为阻塞和非阻塞方式,这就意味着在获取结果前要调用nnl::stream::wait等待计算的完成。
// Execute ReLU (out-of-place)
relu.execute(engine_stream, // The execution stream
// A map with all inputs and outputs
DNNL_ARG_SRC, src_mem, // Source tag and memory obj
DNNL_ARG_DST, dst_mem, // Destination tag and memory obj
);
// Wait the stream to complete the execution
engine_stream.wait();
获取计算结果
计算的结果存放在`dst_mem`内存对象中,可以通过[dnnl::memory::get_data_handle()](https://oneapi-src.github.io/oneDNN/structdnnl_1_1memory.html#a1b81db911a391cefc31e35bbe9ca95fe) 获取指向结果的c++数据指针。
oneDNN内存拓扑
内存拓扑对于深度学习应用程序的性能至关重要,理解oneDNN内存拓扑是理解oneDNN必备内容。卷积和內积原语在为输入输出使用占位符内存格式dnnl::memory::format_tag::any 分配时选择内存格式。内存格式根据不同的情况选择,如硬件和卷积参数。因为卷积是计算密集型运算推荐使用占位符内存格式。对于支持AVX512+指令集的CPU会排列成nChw16c 格式,而对于只支持 SSE4.1+指令集的CPU会排列为nChw8c** 格式。

offset_nChw8c(n, c, h, w) = n * CHW
+ (c / 8) * HW*8
+ h * W*8
+ w * 8
+ (c % 8)
如果c不是8或者16的倍数时,使用补零的方式以满足矢量计算。

对于elementwise运算,则不需要重新排列数据。
oneDNN线程池
线程池接口定义于include/dnnl_threadpool_iface.hpp文件之中,
#include "dnnl_threadpool_iface.hpp"
class threadpool : public dnnl::threadpool_iface
private:
// Change to Eigen::NonBlockingThreadPool if using Eigen <= 3.3.7
std::unique_ptr<Eigen::ThreadPool> tp_;
public:
explicit threadpool(int num_threads = 0)
if (num_threads <= 0)
num_threads = (int)std::thread::hardware_concurrency();
tp_.reset(new Eigen::ThreadPool(num_threads));
int get_num_threads() override return tp_->NumThreads();
bool get_in_parallel() override
return tp_->CurrentThreadId() != -1;
uint64_t get_flags() override return ASYNCHRONOUS;
void parallel_for(
int n, const std::function<void(int, int)> &fn) override
for (int i = 0; i < n; i++)
tp_->Schedule([i, n, fn]() fn(i, n); );
;
充分利用硬件特性
oneDNN集成了最新的硬件矢量特性,oneDNN就使用了Intel DL Boost 特性,比如VPDPBUSD这一指令是在DL Boost加入的,该指令可用于四个s8和u8数据乘累加运算。该指令不会产生溢出和饱和,如下代码实现,在无DL Boost时,需要使用VPMADDUBSW, VPMADDWD, VPADDD指令实现这一功能。
// Want to compute:
// c_s32 += sumi=0..3(a_u8[i] * b_s8[i])
int32_t u8s8s32_compute_avx512_dl_boost(
uint8_t a_u8[4], int8_t b_s8[4], int32_t c_s32)
// Compute using VPDPBUSD:
c_s32 +=
(int32_t)a_u8[0] * (int32_t)b_s8[0] +
(int32_t)a_u8[1] * (int32_t)b_s8[1] +
(int32_t)a_u8[2] * (int32_t)b_s8[2] +
(int32_t)a_u8[3] * (int32_t)b_s8[3];
return c_s32;
由于不同CPU的特性并不一致,有的只支持SSE4.1,有的支持到AVX2,有的还支持DL Boost,oneDNN会根据CPU硬件特性和深度学习OP选择合适的SIMD指令,这通过JIT方式实现,这可以使得在每颗处理器上性同时达到最优。
苹果公司(CoreML)
相对于PC而言,由于可以购买ARM核IP,androidOS也是开源的,所以移动平台的技术含量和门槛比PC端低很多,这就使得芯片的种类和特性随厂商不同而差异,苹果、高通、华为、三星等都自研手机芯片,苹果在A11处理器(Iphone8)引入了Apple Neural Engine (ANE)硬件模块,资料显示ANE在A12上可以加速9倍,能耗约为之前的十分之一,并用于FaceID和Anmoji。现在苹果的机器学习框架Core ML3可以访问这一硬件单元,处理器在A12及以上,系统在 ios 12及以上,可以使用ANE模块。Core ML是在Metal 和 Accelerate等底层之上的封装(这些底层库是对CPU、ANE、GPU等硬件调用),所以Core ML充分利用了CPU、GPU以及ANE硬件综合性能,以提供更为简单效率更高的API以运行模型的推理计算。MPS(Metal Performance Shaders)是基于Metal的高性能GPU加速库,用于图像处理,线下代数计算、光线追踪和机器学习,苹果对其优化之后使其可以在移动和桌面等各平台上获得最佳性能。
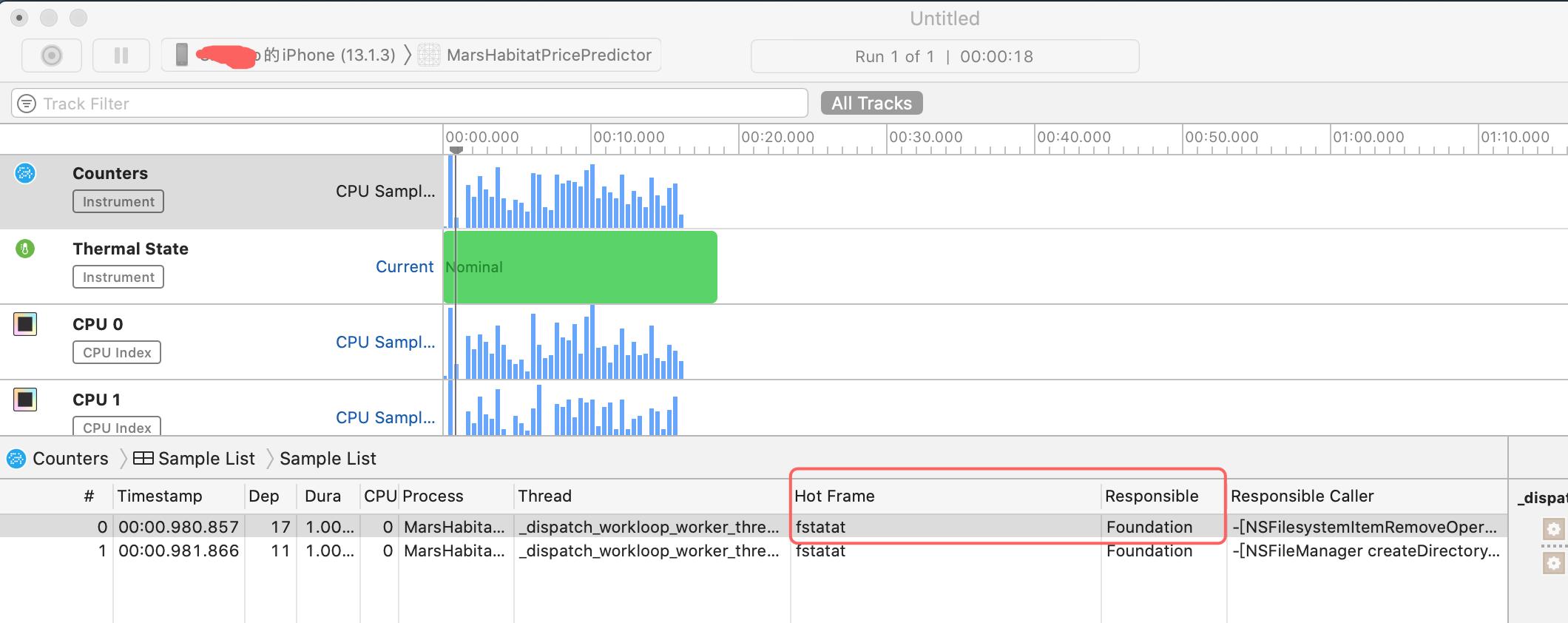
使用苹果公司官网自带的例子,首先编译并将程序下载到iphone11手机上,然后按图调出instrument中的counter(模拟器目前无法模拟ANE模块,只能上硬件),然后使用counters跟踪调用的模块。
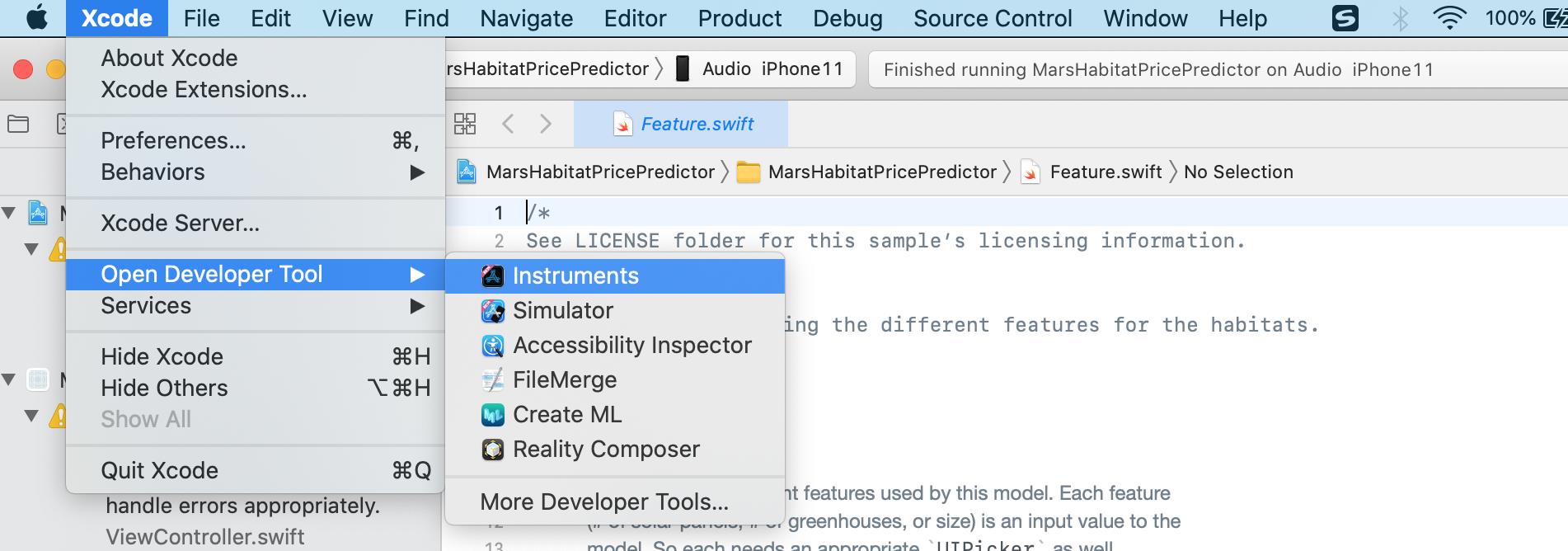
Counters工具跟踪了应用程序方法调用的硬件单元,红色1是启动记录按钮,2指向了设备和进程,这张图是iphone11,3是采样列表,默认以树的形式展现,4是过滤器。

接下来点击采集,并且在屏幕上滑动,让模型计算跑起来,
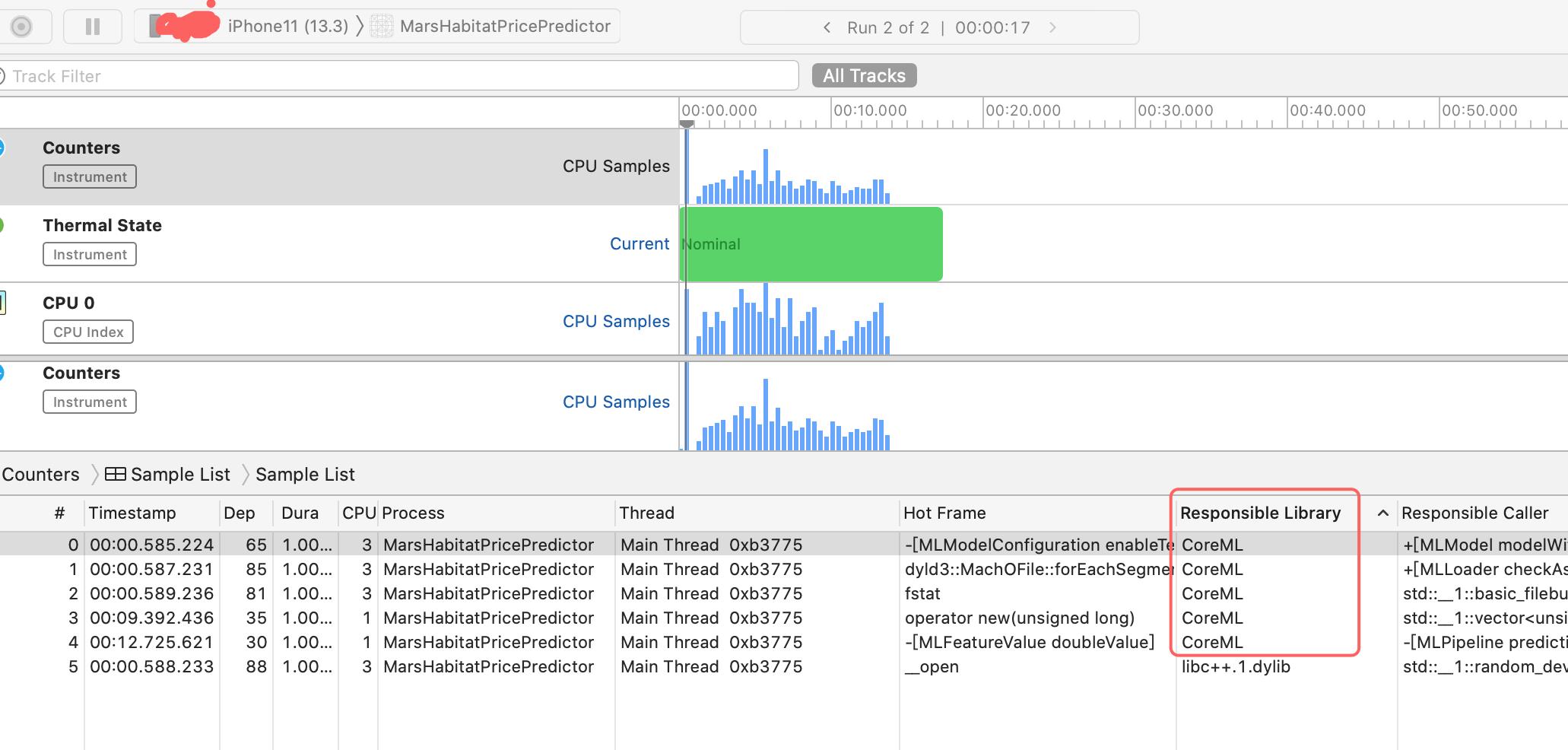
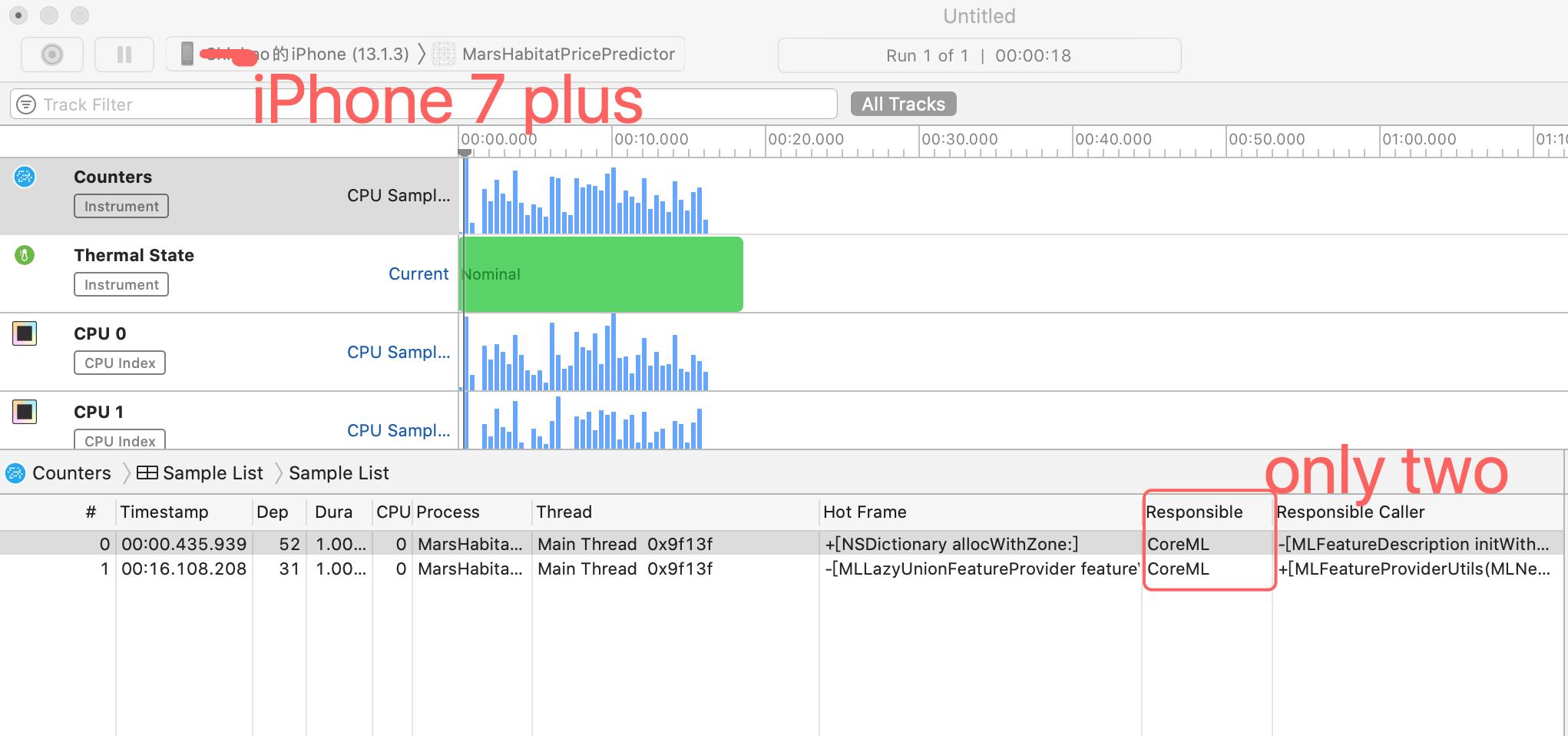
在iphone11可以看到这个线程的fstat使用的是Core ML API实现的(硬件加速器),而在iphone中是有Foundation实现的(CPU上运行),可以看出调用Core ML时,会根据手机选择合适的API运行。
Apple公司使用CoreML为深度学习提供统一的接口,Core ML APIs进行部署。可以使用Core ML Tools 工具将模型转换为 Core ML 格式以便在设备上进行推理计算。Core ML在减少内存和功耗的同时,利用CPU、GPU和Neural Engine优设备上的性能。Core ML建立在低级原语(如Accelerate 和 BNNS)和Metal Performance Shaders之上。 BNNS 库提供了构建训练和推理的函数集,可以用于macOS iOS, tvOS, 和 watchOS系统,其主要是优化了CPU上特性。Accelerate库针对大规模数学和图像计算,其特点是利用CPU的矢量处理特性,Metal Performance Shaders是针对Metal GPU优化的深度学习库。
从iPhone8开始,采用的处理器A11就包括了Neural Engine处理器单元,
BNNS是针对CPU优化的高性能低功耗深度学习训练和推理的计算框架,支持MacOS,iOS,tvOS和watchOS。Accelerate是利用CPU的矢量计算特性对高性能的计算库,
获得CoreML模型
Core ML支持各种类型的机器学习模型,Core ML APIs只支持Core ML模型格式(.mlmodel扩展名),Core ML模型格式转换使用 coremltools,
python -m venv coremltools-venv
# Activate and install coremltools
source coremltools-venv/bin/activate
pip install --upgrade coremltools
TensorFlow 1转换
import coremltools as ct
import tensorflow as tf
tf.__version__
mlmodel = ct.convert("mobilenet_forzen_graph.pb", inputs=[ct.ImageType(bias=[-1,-1,-1], scale1/127)], classifier_config=ct.ClassifierConfig("labels.txt"))
mlmodel.save("mlmobilenet.mlmodel")
TensorFlow 2转换
import coremltools as ct
import tensorflow as tf
tf.__version__
tf_model = tf.keras.applications.MobileNet()
mlmodel = ct.convert(tf.model)
Pytorch 转换
import torch
import torchvison
torch_model = torchvision.models.mobilenet_v2()
#torch script or tracing method to export to core ML format
torch_model.eval()
example_input = torch.rand(1, 3, 256, 256)
traced_model = torch.jit.trace(torch_model, example_input)
mlmodel = ct.convert(traced_model, inputs=[ct.TensorType(shape=example_input)])
#print(mlmodel)
语音识别DeepSpeech 例子
https://github.com/mozilla/DeepSpeech/releases
https://github.com/mozilla/DeepSpeech/releases/download/v0.7.1/deepspeech-0.7.1-checkpoint.tar.gz
https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deepspeech-0.9.3-checkpoint.tar.gz
git clone --branch v0.9.1 https://github.com/mozilla/DeepSpeech
python3 -m venv $HOME/tmp/deepspeech-train-venv/
source $HOME/tmp/deepspeech-train-venv/bin/activate
pip3 install --upgrade pip==20.2.2 wheel==0.34.2 setuptools==49.6.0
pip3 install --upgrade -e .
sudo apt-get install python3-dev
python DeepSpeech.py --export_dir tmp --load_checkpoint_dir ./deepspeech-0.7.1-checkpoint --alphabet_config_path=data/alphabet.txt --scorer_path=deepspeech-0.7.1-models.scorer >/dev/null 2>&1
pip install deepspeech==0.7.1
cd tensorflow
ln -s ../DeepSpeech/native_client ./
$ bazel build --verbose_failures --config=ios_x86_64 --workspace_status_command="bash native_client/bazel_workspace_status_cmd.sh" --config=monolithic -c opt //native_client:libdeepspeech.so --define=runtime=tflite --copt=-DTFLITE_WITH_RUY_GEMV
$ cp -f bazel-bin/native_client/libdeepspeech.so ../native_client/swift/libdeepspeech.so
Build for arm64:
$ bazel build --verbose_failures --config=ios_arm64 --workspace_status_command="bash native_client/bazel_workspace_status_cmd.sh" --config=monolithic -c opt //native_client:libdeepspeech.so --define=runtime=tflite --copt=-DTFLITE_WITH_RUY_GEMV
$ cp -f bazel-bin/native_client/libdeepspeech.so ../native_client/swift/libdeepspeech.so
## generate framework --config=ios_sim for simulation
bazel build --verbose_failures --config=ios_arm64 --workspace_status_command="bash native_client/bazel_workspace_status_cmd.sh" --config=monolithic -c opt //native_client:deepspeech_ios --define=runtime=tflite --copt=-DTFLITE_WITH_RUY_GEMV
bazel build --verbose_failures --config=ios_arm64 --workspace_status_command="bash native_client/bazel_workspace_status_cmd.sh" --apple_bitcode=embedded --copt=-fembed-bitcode --config=monolithic -c opt //native_client:deepspeech_ios --define=runtime=tflite --copt=-DTFLITE_WITH_RUY_GEMV
低精度转换
这通常是为了计算效率和存储空间的考虑,在模型训练完成之后,Core ML可以把23bit浮点数(FP32)转变成FP16,8bit,7bit一直可以到1bit,量化的位数越少损失精度越大,不同模型损失的精度可以有差异。量化的输入文件是MLModel模型文件,quantize_weights处理量化。
from coremltools.models.neural_network import quantization_utils
# allowed values of nbits = 16, 8, 7, 6, ...., 1
quantized_model = quantization_utils.quantize_weights(model, nbits)
16bit 量化
通常这是最安全的量化方式,因为其对准确率影响最小,会将模型size压缩为之前的一半。
import coremltools as ct
from coremltools.models.neural_network import quantization_utils
# load full precision model
model_fp32 = coremltools.models.MLModel('model.mlmodel')
model_fp16 = quantization_utils.quantize_weights(model_fp32, nbits=16)
量化到1~8bit
量化为8bit,可以使模型size变为之前的四分之一,但这会影响精度,所以量化之后应用测试集测试下模型的准确性。根据模型的类型不同,不同的量化位数准确性下降的并不一样。
# quantize to 8 bit using linear mode
model_8bit = quantize_weights(model_fp32, nbits=8)
# quantize to 8 bit using LUT kmeans mode
model_8bit = quantize_weights(model_fp32, nbits=8,
quantization_mode="kmeans")
# quantize to 8 bit using linearsymmetric mode
model_8bit = quantize_weights(model_fp32, nbits=8,
quantization_mode="linear_symmetric")
ONNX转为Core ML
ONNX(Open Neural Network eXchange)是神经网络共享的文件格式,可以使用下面的代码转为Core ML格式。
import coremltools as ct
# Convert from ONNX to Core ML
model = ct.converters.onnx.convert(model='my_model.onnx')
TFLite
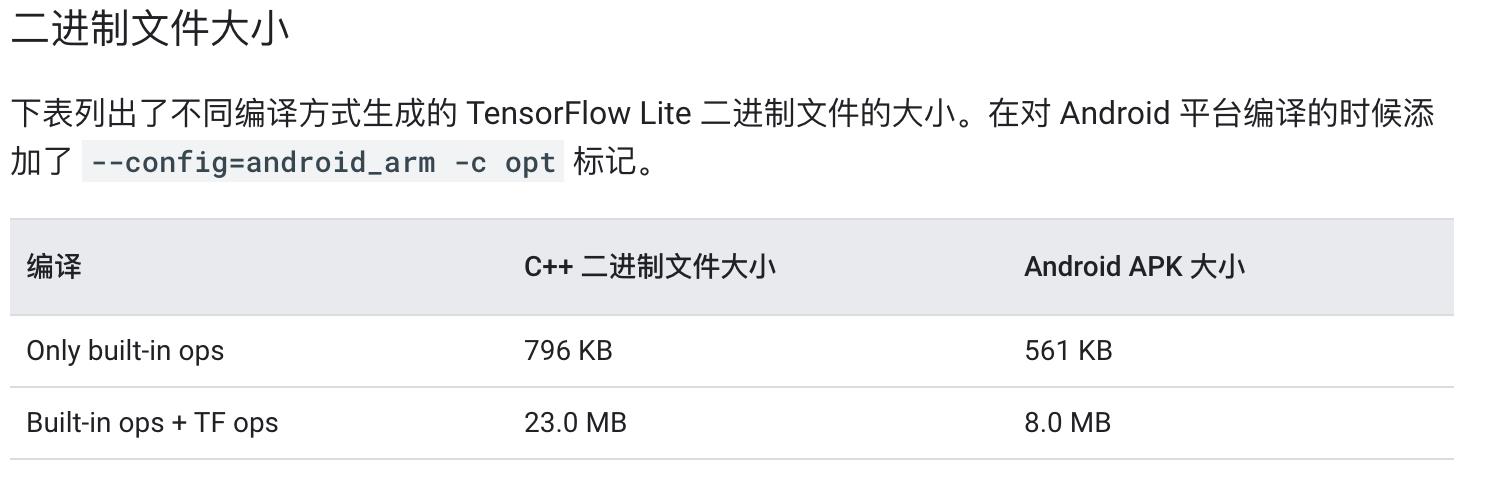
TensorFlow lite是用于移动端、嵌入式和IoT设备场景的推理计算框架,优点是跨平台性好,二进制文件小。

从上可以看到server端先将TensorFlow框架训练的模型转换为TFLite数据格式,然后将这个格式文件输入TFLite解释器运行,这样端上设备主要工作集中在推理计算,最终的image大小将分为interpreter + .tflite两部分。
Keras model to tflite

根据TensorFlow官网建立以Keras的分类为例说明,
# TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
# Helper libraries
import numpy as np
print(tf.__version__)
# Load datasets
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
#normalization dataset, since NN input is float point
train_images = train_images / 255.0
test_images = test_images / 255.0
#Build model layer
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10)
])
# Compile model
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
#Train model
model.fit(train_images, train_labels, epochs=10)
net_save_path = "mnist/"
tf.saved_model.save(model, net_save_path)
#test model
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\\nTest accuracy:', test_acc)
## Convert the model.
#converter = tf.lite.TFLiteConverter.from_keras_model(model)
#tflite_model = converter.convert()
#if saved model
converter = tf.lite.TFLiteConverter.from_saved_model(net_save_path)
tflite_model = converter.convert()
# Save the model.
with open('model.tflite', 'wb') as f:
f.write(tflite_model)
这时可以使用netro查看转换好的model.tflite模型
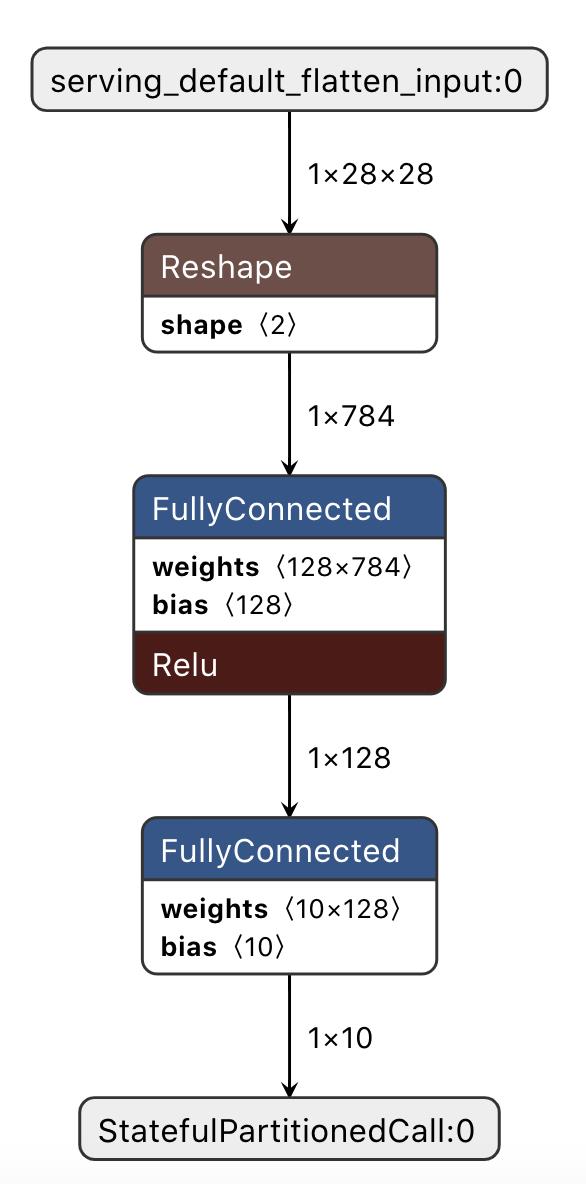
推理相关文件大小
如上小节,模型的参数量=(128*784+128+10*128+10)=101770,每个参数是float型占4字节,即大小为407080字节;
而上述模型通过上节转换之后的大小是:408548字节,这还包括了三种op操作。
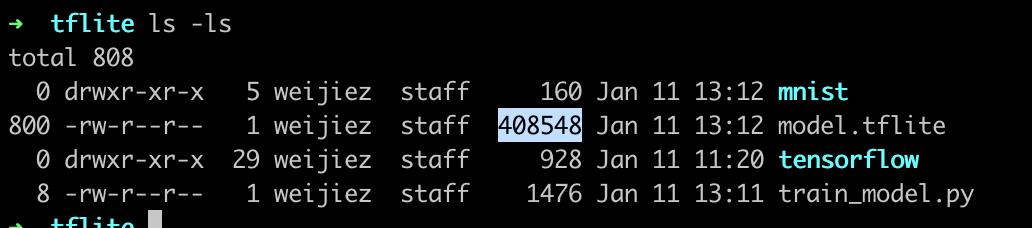
如上可见,flatbuffer格式的.tflite和纯手工二进制文件,并不会带来很大的增加,在微控制器上,可以做到100KB大小。
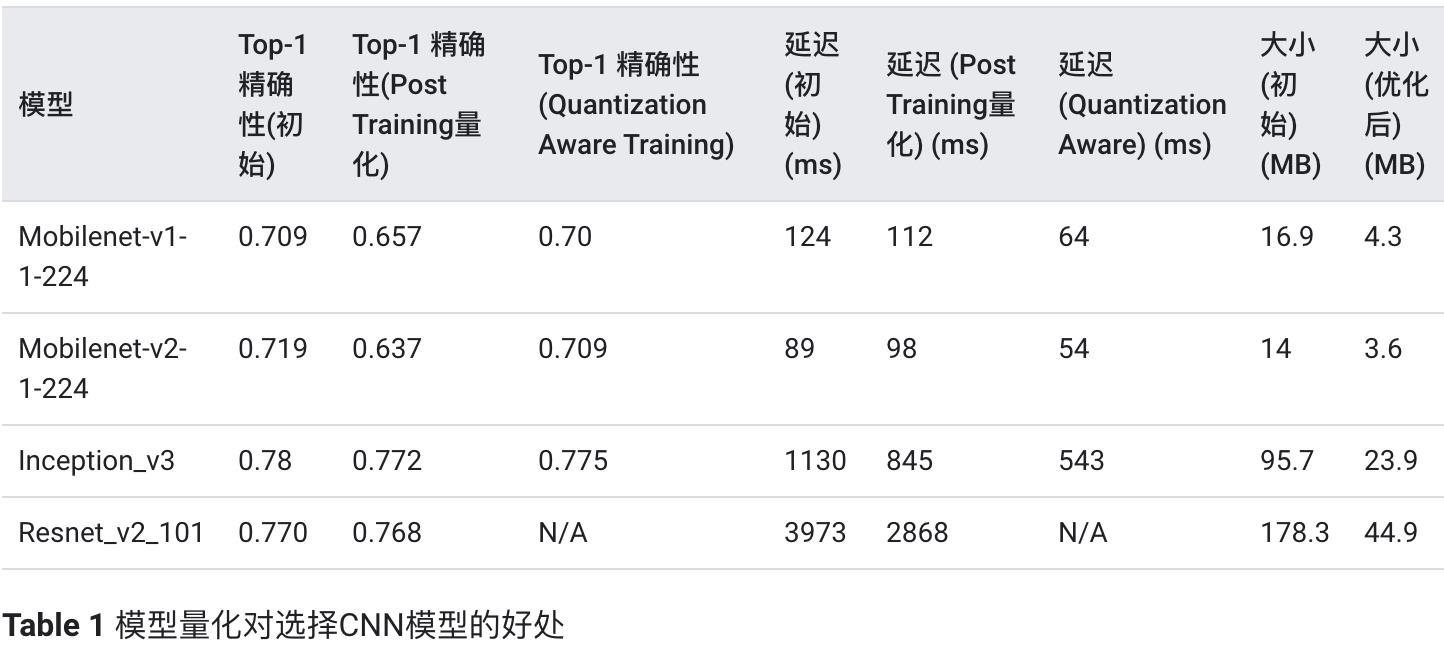
model quantization
tensorflow/lite/tools/make/download_dependencies.sh
TFLite库编译
##编译ios
xcode-select --install
brew install automake
brew install libtool
#这会从网上获取库和数据的拷贝,并安装在tensorflow/lite/downloads目录
tensorflow/lite/tools/make/download_dependencies.sh
#使用 tensorflow/lite 中的 makefile 来构建不同版本的库,然后调用 lipo 将它们捆绑到包含 armv7, armv7s, arm64, i386, 和 x86_64 架构的通用文件中。生成的库在: tensorflow/lite/tools/make/gen/lib/libtensorflow-lite.a
tensorflow/lite/tools/make/build_ios_universal_lib.sh
#编译macOS
bazel build -c opt //tensorflow/lite:libtensorflowlite.dylib
bazel build -c opt --cpu=darwin //tensorflow/lite:libtensorflowlite.so
-r-xr-xr-x 1 weijiez wheel 3.8M Jan 12 16:05 libtensorflowlite.dylib
-r-xr-xr-x 1 weijiez wheel 3.8M Jan 12 16:09 libtensorflowlite.so
#directory structure
tensorflow
├── demo
│ ├── libtensorflowlite.dylib
│ ├── libtensorflowlite.so
│ └── model.tflite
├── demo.bin
├── demo.cpp
├── models.BUILD
├── tensorflow
│ ├── BUILD
│ ├── __init__.py
│ ├── api_template.__init__.py
│ ├── api_template_v1.__init__.py
│ ├── c
│ ├── cc
...
g++ demo.cpp -std=c++11 -I/Users/XXX/tflite/tensorflow -I/Users/XXX/tflite/tensorflow/tensorflow/lite/tools/make/downloads/flatbuffers/include/ -L/Users/XXX/tflite/tensorflow/demo -ltensorflowlite -ldl -pthread -o demo.bin && ./demo.bin
TFLite 推理
#python method
import numpy as np
import tensorflow as tf
# Load TFLite model and allocate tensors.
interpreter = tf.lite.Interpreter(model_path="converted_model.tflite")
interpreter.allocate_tensors()
# Get input and output tensors.
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# Test model on random input data.
input_shape = input_details[0]['shape']
input_data = np.array(np.random.random_sample(input_shape), dtype=np.float32)
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
# The function `get_tensor()` returns a copy of the tensor data.
# Use `tensor()` in order to get a pointer to the tensor.
output_data = interpreter.get_tensor(output_details[0]['index'])
print(output_data)
//C++ method
// Load the model
std::unique_ptr<tflite::FlatBufferModel> model =
tflite::FlatBufferModel::BuildFromFile(filename);
// Build the interpreter
tflite::ops::builtin::BuiltinOpResolver resolver;
std::unique_ptr<tflite::Interpreter> interpreter;
tflite::InterpreterBuilder(*model, resolver)(&interpreter);
// Resize input tensors, if desired.
interpreter->AllocateTensors();
float* input = interpreter->typed_input_tensor<float>(0);
// Fill `input`.
interpreter->Invoke();
//output data
float* output = interpreter->typed_output_tensor<float>(0);
TFLite 推理性能评估工具
桌面性能评估方法
#编译性能评估
bazel build -c opt tensorflow/lite/tools/benchmark:benchmark_model
#运行tflite计算图
bazel-bin/tensorflow/lite/tools/benchmark/benchmark_model --graph=../model.tflite --num_threads=4 use_xnnpack=true
bazel-bin/tensorflow/lite/tools/benchmark/benchmark_model --graph=../DeepSpeech/native_client/deepspeech-0.9.3-models.tflite --num_threads=4 use_xnnpack=true
评估deepspeech性能
# Create and activate a virtualenv
virtualenv -p python3 $HOME/tmp/deepspeech-venv/
source $HOME/tmp/deepspeech-venv/bin/activate
# Install DeepSpeech
pip3 install deepspeech
# Download pre-trained English model files https://github.com/mozilla/DeepSpeech/releases
curl -LO https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deepspeech-0.9.3-models.pbmm
curl -LO https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deepspeech-0.9.3-models.scorer
# Download example audio files
curl -LO https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/audio-0.9.3.tar.gz
tar xvf audio-0.9.3.tar.gz
# Transcribe an audio file
deepspeech --model deepspeech-0.9.3-models.pbmm --scorer deepspeech-0.9.3-models.scorer --audio audio/2830-3980-0043.wav
调用TFLite
(tf-lite) ➜ tensorflow git:(master) bazel-bin/tensorflow/lite/tools/benchmark/benchmark_model --graph=../DeepSpeech/native_client/deepspeech-0.9.3-models.tflite --num_threads=4 use_xnnpack=true --num_runs=1000
STARTING!
Unconsumed cmdline flags: use_xnnpack=true
Log parameter values verbosely: [0]
Min num runs: [1000]
Num threads: [4]
Graph: [../DeepSpeech/native_client/deepspeech-0.9.3-models.tflite]
#threads used for CPU inference: [4]
Loaded model ../DeepSpeech/native_client/deepspeech-0.9.3-models.tflite
The input model file size (MB): 47.3318
Initialized session in 1.761ms.
Running benchmark for at least 1 iterations and at least 0.5 seconds but terminate if exceeding 150 seconds.
count=8 first=100907 curr=62159 min=57650 max=100907 avg=63802.8 std=14093
Running benchmark for at least 1000 iterations and at least 1 seconds but terminate if exceeding 150 seconds.
^@^@^@count=1000 first=66276 curr=57677 min=56781 max=182217 avg=60391 std=9213
Inference timings in us: Init: 1761, First inference: 100907, Warmup (avg): 63802.8, Inference (avg): 60391
(tf-lite) ➜ tensorflow git:(master) bazel-bin/tensorflow/lite/tools/benchmark/benchmark_model --graph=../DeepSpeech/native_client/deepspeech-0.9.3-models.tflite --num_threads=4 --num_runs=1000
STARTING!
Log parameter values verbosely: [0]
Min num runs: [1000]
Num threads: [4]
Graph: [../DeepSpeech/native_client/deepspeech-0.9.3-models.tflite]
#threads used for CPU inference: [4]
Loaded model ../DeepSpeech/native_client/deepspeech-0.9.3-models.tflite
The input model file size (MB): 47.3318
Initialized session in 21.154ms.
Running benchmark for at least 1 iterations and at least 0.5 seconds but terminate if exceeding 150 seconds.
count=7 first=187833 curr=58117 min=56976 max=187833 avg=76247.3 std=45556
Running benchmark for at least 1000 iterations and at least 1 seconds but terminate if exceeding 150 seconds.
^@^@count=1000 first=67009 curr=64672 min=56388 max=136243 avg=59875.9 std=5459
Inference timings in us: Init: 21154, First inference: 187833, Warmup (avg): 76247.3, Inference (avg): 59875.9
(tf-lite) ➜ tensorflow git:(master) bazel-bin/tensorflow/lite/tools/benchmark/benchmark_model --graph=../DeepSpeech/native_client/deepspeech-0.9.3-models.tflite --num_threads=4 use_coreml=true --num_runs=1000
STARTING!
Unconsumed cmdline flags: use_coreml=true
Log parameter values verbosely: [0]
Min num runs: [1000]
Num threads: [4]
Graph: [../DeepSpeech/native_client/deepspeech-0.9.3-models.tflite]
#threads used for CPU inference: [4]
Loaded model ../DeepSpeech/native_client/deepspeech-0.9.3-models.tflite
The input model file size (MB): 47.3318
Initialized session in 1.807ms.
Running benchmark for at least 1 iterations and at least 0.5 seconds but terminate if exceeding 150 seconds.
count=8 first=102195 curr=57292 min=57292 max=102195 avg=63709.4 std=14570
Running benchmark for at least 1000 iterations and at least 1 seconds but terminate if exceeding 150 seconds.
^@^@count=1000 first=67351 curr=57137 min=55905 max=176197 avg=62857.8 std=12665
Inference timings in us: Init: 1807, First inference: 102195, Warmup (avg): 63709.4, Inference (avg): 62857.8
(tf-lite) ➜ tensorflow git:(master) bazel-bin/tensorflow/lite/tools/benchmark/benchmark_model --graph=../DeepSpeech/native_client/deepspeech-0.9.3-models.tflite --num_threads=4 use_gpu=true --num_runs=1000
STARTING!
Unconsumed cmdline flags: use_gpu=true
Log parameter values verbosely: [0]
Min num runs: [1000]
Num threads: [4]
Graph: [../DeepSpeech/native_client/deepspeech-0.9.3-models.tflite]
#threads used for CPU inference: [4]
Loaded model ../DeepSpeech/native_client/deepspeech-0.9.3-models.tflite
The input model file size (MB): 47.3318
Initialized session in 1.503ms.
Running benchmark for at least 1 iterations and at least 0.5 seconds but terminate if exceeding 150 seconds.
count=8 first=93764 curr=57439 min=56257 max=93764 avg=62895.6 std=11771
Running benchmark for at least 1000 iterations and at least 1 seconds but terminate if exceeding 150 seconds.
^@^@count=1000 first=64978 curr=56703 min=55952 max=198133 avg=58903.3 std=8921
Inference timings in us: Init: 1503, First inference: 93764, Warmup (avg): 62895.6, Inference (avg): 58903.3
使用TFLite代理加速
通常使用TFLite将TensorFlow模型转换为TFLite格式,然后使用TFLite解释器在设备上运行,默认使用优化的NEON指令在CPU上进行推理计算,然而很多芯片有GPU、DSP、ASIC等加速单元,所以TFLite引入了delegate机制,delegate介于TFLite运行环境和底层加速API之间,比如NNAPI delegate调用andorid平台NNAPI,GPU delegate用OpenCL和OpenGL,NPU,XNNPACK是一个开源的delegate底层实现,在有些情况下推理计算比TFLite默认实现快十倍,并且可以支持X64芯片,其支持了AVX-512指令,之所以使用这些加速单元是处于计算效率、功耗等方面的考虑。

####XNNPACK
针对浮点运行进行了优化,对于ARM平台使用NEON优化,常用OP如卷积、全连接等使用了汇编优化;对于x86-64 平台使用了SSE2, SSE4, AVX, AVX2, and AVX512指令集进行了优化;并且还提供了OP融合优化,如将卷积和padding优化一次运算;XNNPACK支持Windows, macOS, and Linux 系统。该库已经在Google 的生产环境中使用。

以上是关于模型推理那些事的主要内容,如果未能解决你的问题,请参考以下文章