让Transformer的推理速度提高4.5倍,这个小trick还能给你省十几万
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了让Transformer的推理速度提高4.5倍,这个小trick还能给你省十几万相关的知识,希望对你有一定的参考价值。
丰色 发自 凹非寺
量子位 报道 | 公众号 QbitAI
最近,NLP明星公司Hugging Face发布了一个叫做Infinity的产品,可以以1ms延时完成Transformer的推理,性能相当高了。
但是,厉害归厉害,还是有点贵——1年至少要十几万块 (2万美元)。
那有没有什么平替的方法呢?
有的!还是开源的、“不费吹灰之力”就可以达到Infinity一些公共基准的那种。

并且现在,通过在该方法上施加一个小trick,将Transformer的推理速度提高4.5倍!

那么,一个“平替”到底为什么能达到“付费”的效果呢?
一个trick让Transformer推理速度提高4.5倍
先来认识一下这个方法:Transformer-deploy。
它可以用一行命令优化和部署Hugging Face上的Transformer模型,并支持大多数基于Transformer编码器的模型,比如Bert、Roberta、miniLM、Camembert、Albert、XLM-R、Distilbert等。

Transformer-deploy推理服务器用的是Nvidia Triton。
推理引擎为Microsoft ONNX Runtime(用于CPU和GPU推理)和Nvidia TensorRT(仅限 GPU)。
如果想在GPU上获得一流的性能,Nvidia Triton+Nvidia TensorRT这样的组合无疑是最佳选择。
虽然TensorRT用起来有点难,但它确实能比用Pytorch快5~10倍。

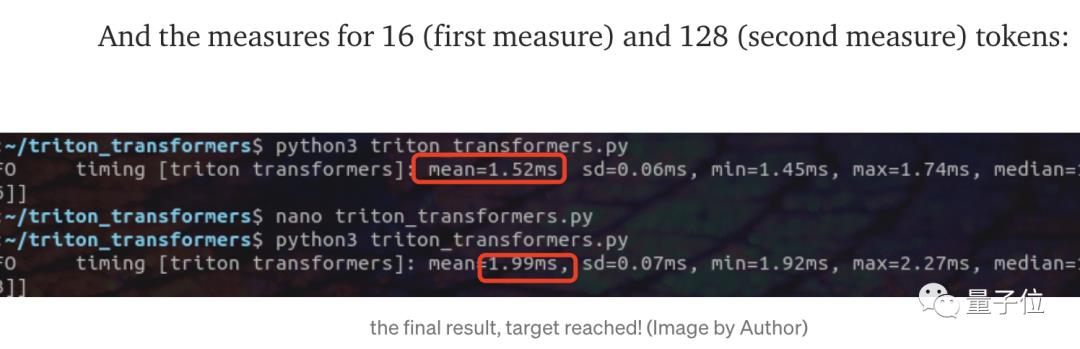
在实际性能测试中,Transformer-deploy在batch size为1、token分别为16和128的输入序列中的推理速度,都比付费的Hugging Face Infinity要快:
Transformer-deploy在token为16时要1.52ms,Infinity则需要1.7ms;token为128时需要1.99ms,Infinity则需要2.5ms。
那前面说的能让Transformer的推理性能进一步提高的小trick是什么呢?
GPU量化(quantization)。
作者表示:
据我所知,目前任何OOS云服务都还没用到过这个方法。
不过执行GPU量化需要修改模型源代码(需在矩阵乘法等代价高昂的操作上添加一些叫做QDQ的特定节点),既容易出错,又很无聊,并且还需自己维护修改后的代码。
因此作者已经为多个基于Transformer的模型手动完成了这项工作。
后来,他们又发现似乎只需修补模型模块的抽象语法树 (AST)也可以自动完成。
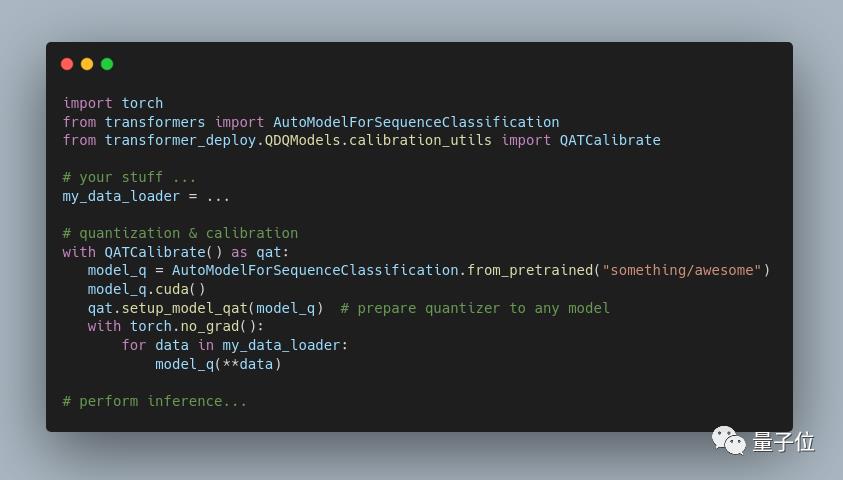
在用户端,在GPU上执行模型的基本量化类似这样:
最终,该方法在Roberta-base模型和MNLI数据集(分类任务)上实现了4.53倍的推理速度。
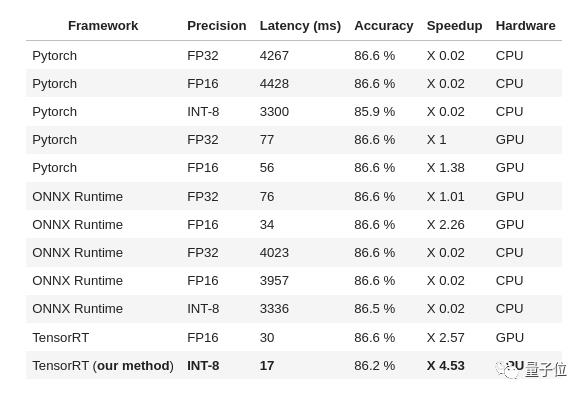
当然这也牺牲了0.4个点的精度;如果一点不牺牲的话,也可以加速3.2倍左右。
作者表示,与Transformer-deploy原来的版本相比,这已经是一个很大的改进了,毕竟原版本的加速成本需要超过1个点的精确度。
最终他们用Albert、Bert(包括miniLM)、Distilbert、Roberta(包括 Camembert、XLM-R、DistilRoberta等)、Electra测试了该trick。
结果是对于任何可以导出为ONNX格式的Transformer模型,都可以“开箱即用”。
参考链接:
https://www.reddit.com/r/MachineLearning/comments/rr17f9/p_45_times_faster_hugging_face_transformer/
以上是关于让Transformer的推理速度提高4.5倍,这个小trick还能给你省十几万的主要内容,如果未能解决你的问题,请参考以下文章
两行代码自动压缩ViT模型!模型体积减小3.9倍,推理加速7.1倍