Pandas库:从入门到应用
Posted Hub-Link
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pandas库:从入门到应用相关的知识,希望对你有一定的参考价值。
一、Pandas 行列数据选取
1.1、获取列数据
1.1.1、获取单列数据
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.random.randint(1,151,size=(10,3)),
columns=['Python','Math','Chinese'])
df[['Python']] #获取Python列数据,输出为DataFrame类型
print(type(df[['Python']])) # class 'pandas.core.frame.DataFrame'
df['Python'] #获取Python列数据,输出为Series类型
df.Python #获取Python列数据,输出为Series类型
print(type(df['Python'])) # class 'pandas.core.series.Series'
1.1.2、获取多列数据
df[['Python','Chinese']] # 通过列索引值直接获取Python,Chinese列数据,类型是DataFrame
df[df.columns[0:2]] #通过列索引的切片 来获取列,输出类型是DataFrame
1.2、获取行数据
1.2.1、根据索引获取行
-
获取前三行
df[:3] df[0:3] #前开后闭
-
获取第2行到第4行
df[1:4] #前开后闭
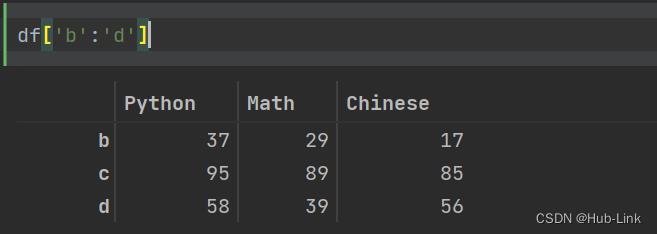
df['b':'d'] #通过行索引来获取
-
获取特定行数据
df[[True,False,False,True,False,False,False,False,False,False]] ## 为True显示改行数据,为Flase不显示

1.2.2、根据条件获取行
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.random.randint(1,151,size=(10,3)),
columns=['Python','Math','Chinese'],
index=list('abcdefghij'))
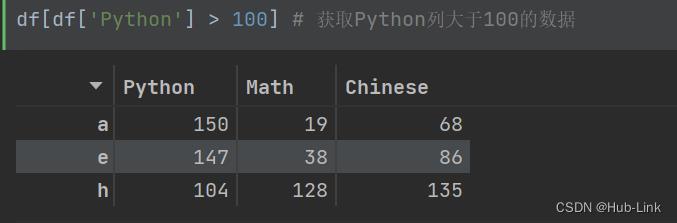
df[df['Python'] > 100] # 获取Python列大于100的数据
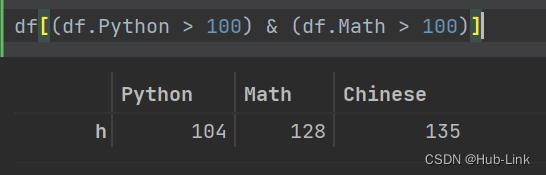
df[(df.Python > 100) & (df.Math > 100)] # 获取Python列和Math都大于100的数据
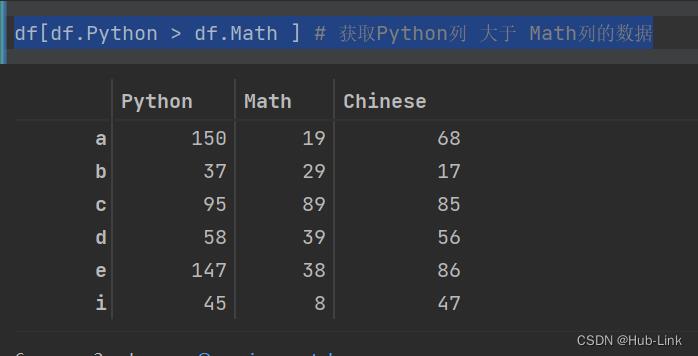
df[df.Python > df.Math ] # 获取Python列 大于 Math列的数据
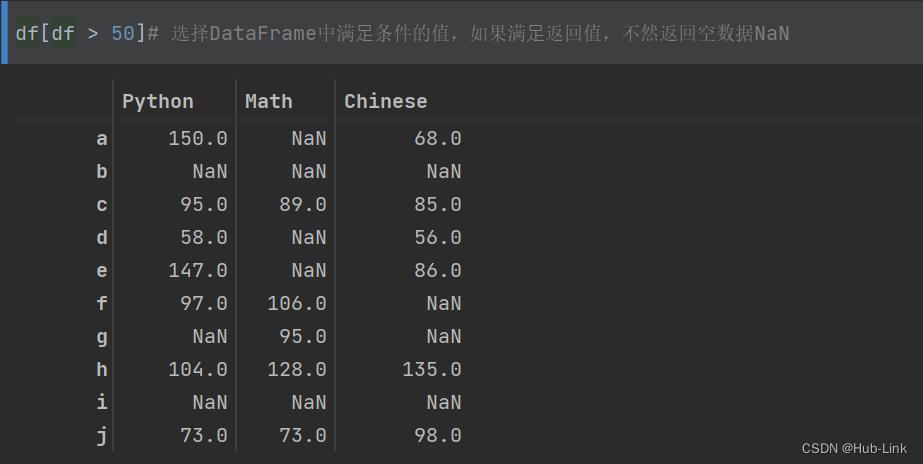
df[df > 50]# 选择DataFrame中满⾜条件的值,如果满⾜返回值,不然返回空数据NaN
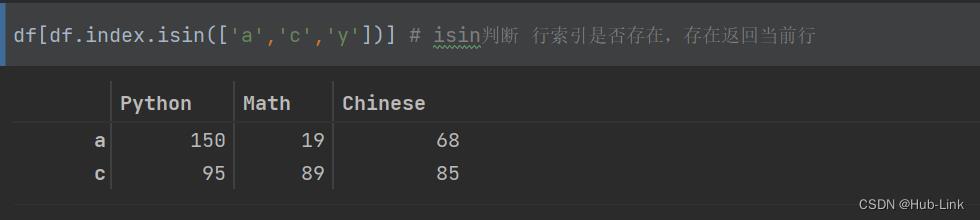
df[df.index.isin(['a','c','y'])] # isin判断 行索引是否存在,存在返回当前行
二、Pandas 区域数据选取
- df.loc[] 只能使用标签索引,不能使用整数索引,通过便签索引切边进行筛选时,前闭后闭。
- df.iloc[] 只能使用整数索引,不能使用标签索引,通过整数索引切边进行筛选时,前闭后开。
- df.ix[]既可以使用标签索引,也可以使用整数索引。
2.1、标签索引获取数据
2.1.1、获取列数据
-
获取单列数据
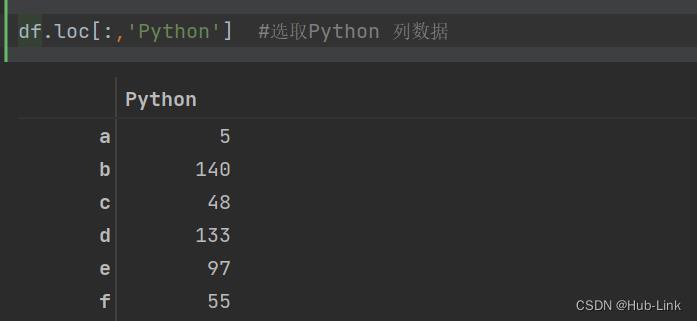
import numpy as np import pandas as pd df = pd.DataFrame(data=np.random.randint(1,151,size=(10,3)), columns=['Python','Math','Chinese'], index=list('abcdefghij')) df.loc[:,'Python'] #选取Python 列数据
-
获取多列数据
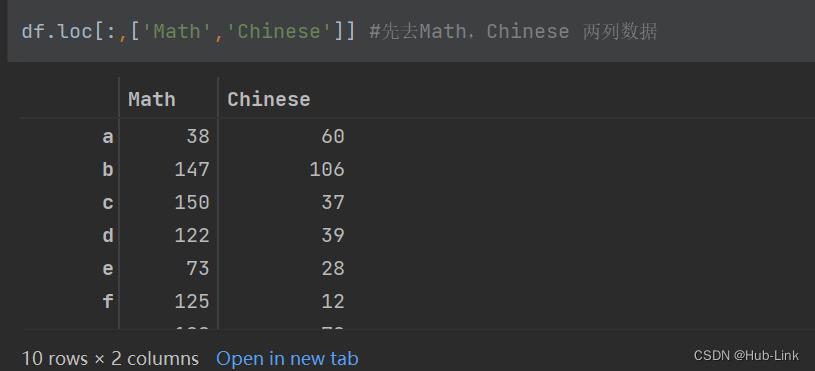
df.loc[:,['Math','Chinese']] #先去Math,Chinese 两列数据
-
获取连续列数据
df.loc[:,'Python':'Chinese'] #先去Python到Chinese 列的全部数据

2.1.2、获取行数据
-
获取单行数据
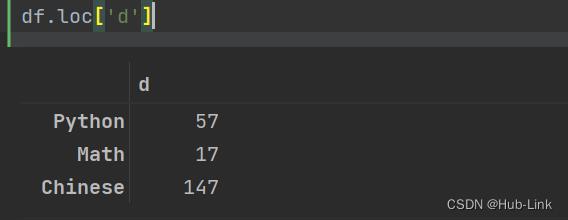
import numpy as np import pandas as pd df = pd.DataFrame(data=np.random.randint(1,151,size=(5,3)), columns=['Python','Math','Chinese'], index=list('abcde')) df.loc['d'] #获取d行数据
-
获取多行数据
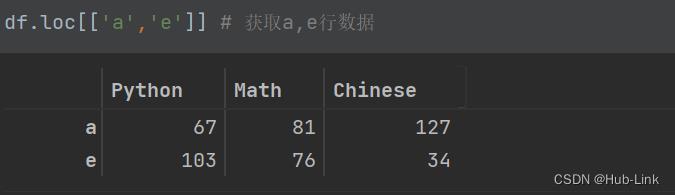
df.loc[['a','e']] # 获取a,e行数据 df.loc[['a', 'e'], :] # 获取a,e行数据 df[[True, False, False, False, True]]# 获取a,e行数据
- 获取连续行数据
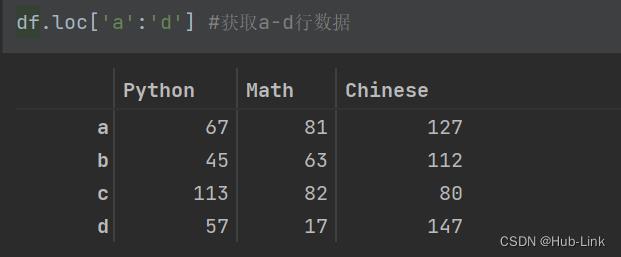
df.loc['a':'d'] #获取a-d行数据
-
根据条件获取数据
df.loc[df.Chinese > 100] #获取Chinese分数大于100的行数 df.loc[df.Chinese > 100 ,:] #获取Chinese分数大于100的行数据

2.1.3、同时获取行列数据
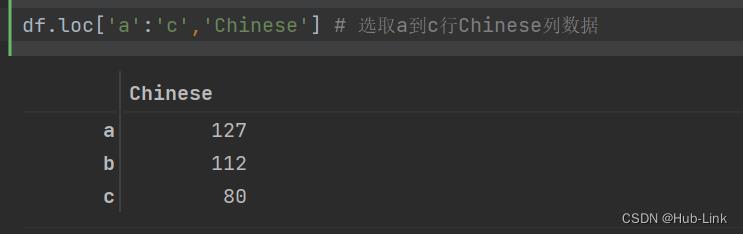
df.loc['a':'c','Chinese'] # 选取a到c行Chinese列数据
2.1.4、行列数据赋值
- 行数据赋值
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.random.randint(1,151,size=(5,3)),
columns=['Python','Math','Chinese'],
index=list('abcde'))
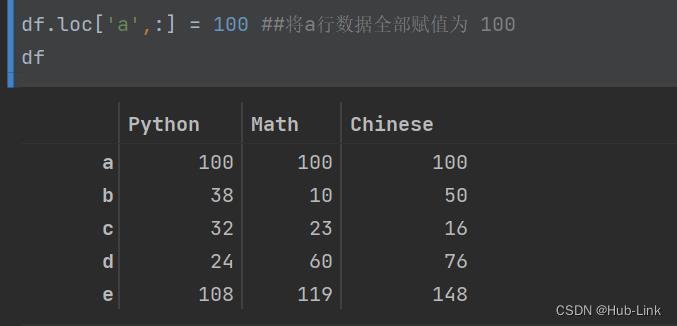
df.loc['a',:] = 100 ##将a行数据全部赋值为 100
df
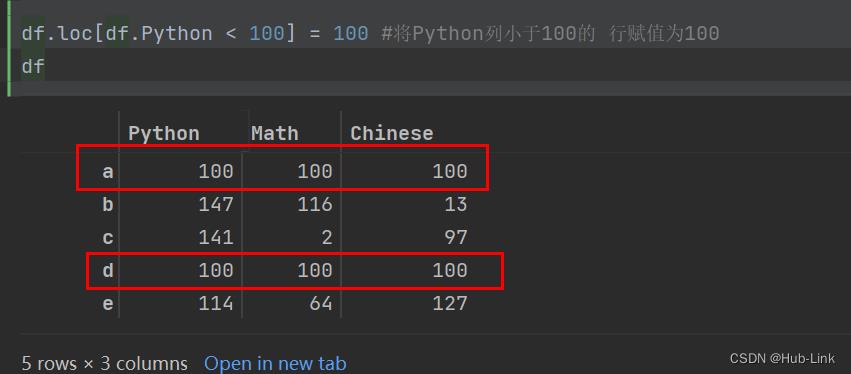
df.loc[df.Python < 100] = 100 #将Python列小于100的 行赋值为100
df
-
列数据赋值
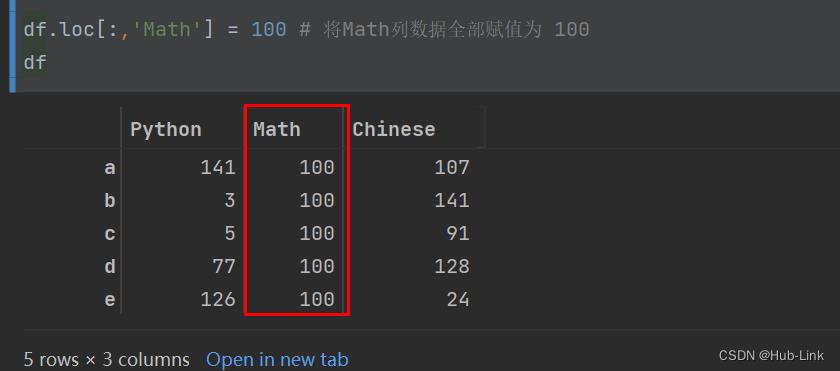
df.loc[:,'Math'] = 100 # 将Math列数据全部赋值为 100 df
df.loc[df.Python < 100] = 100 #将Python列小于100的赋值为100
df
- 行列数据同时赋值
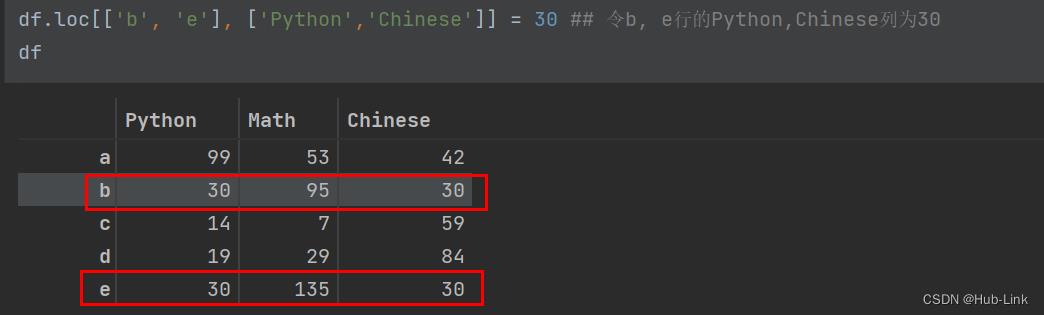
df.loc[['b', 'e'], ['Python','Chinese']] = 30 ## 令b, e行的Python,Chinese列为30
df
2.2、位置获取数据
2.2.1、获取列数据
-
获取单行数据
import numpy as np import pandas as pd df = pd.DataFrame(data=np.random.randint(1,151,size=(5,3)), columns=['Python','Math','Chinese'], index=list('abcde')) df.iloc[1] # 获取第二行数据 返回的是Series 数据格式 df.iloc[1, :] # 获取第二行数据 返回的是Series 数据格式
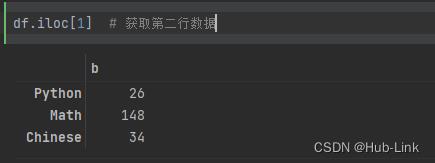
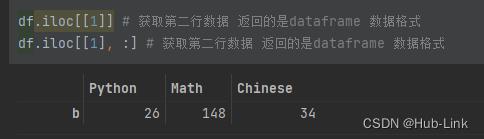
df.iloc[[1]] # 获取第二行数据 返回的是dataframe 数据格式
df.iloc[[1], :] # 获取第二行数据 返回的是dataframe 数据格式
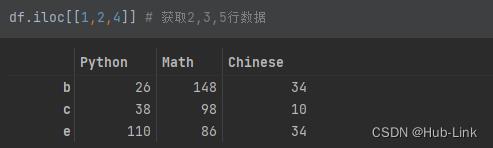
- 获取多行数据
df.iloc[[1,2,4]] # 获取2,3,5行数据
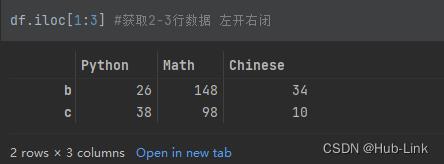
- 获取连续多行数据
df.iloc[1:3] #获取2-3行数据 左开右闭
2.2.2、获取列数据
- 获取单列数据
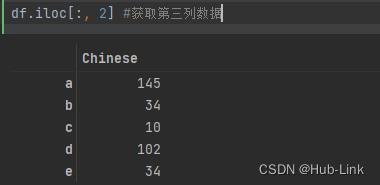
df.iloc[:, 2] #获取第三列数据
- 获取多列数据
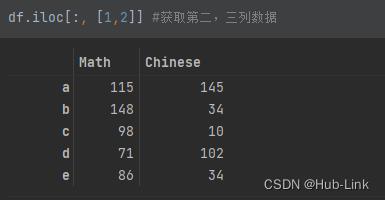
df.iloc[:, [1,2]] #获取第二,三列数据
- 获取连续多列数据
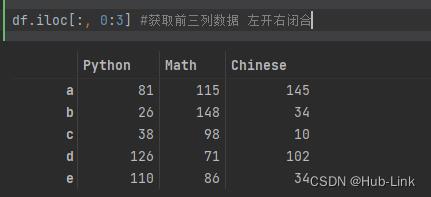
df.iloc[:, 0:3] #获取前三列数据 左开右闭合
2.2.3、同时获取行列数据
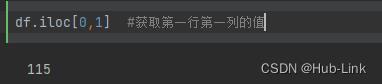
df.iloc[0,1] #获取第一行第二列的值
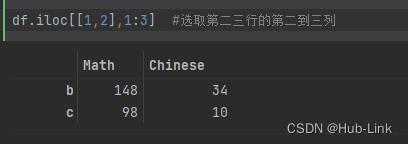
df.iloc[[1,2],1:3] #选取第二三行的第二到三列
2.2.4、行列数据赋值
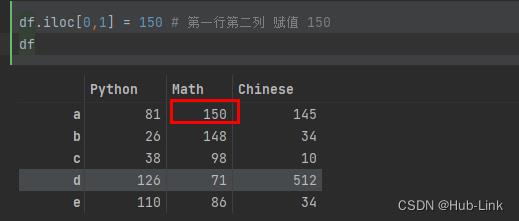
df.iloc[0,1] = 150 # 第一行第二列 赋值 150
以上是关于Pandas库:从入门到应用的主要内容,如果未能解决你的问题,请参考以下文章