Hive进阶-- Hive SQLSpark SQL和 Hive on Spark SQL
Posted highfei2011
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive进阶-- Hive SQLSpark SQL和 Hive on Spark SQL相关的知识,希望对你有一定的参考价值。
1.Hive SQL
1.1 基本介绍
概念
Hive由Facebook开发,用于解决海量结构化日志的数据统计,于2008年贡献给 Apache 基金会。
Hive是基于Hadoop的数据仓库工具,可以将结构化数据映射为一张表,提供类似SQL语句查询功能
本质:将Hive SQL转化成MapReduce程序。
与关系型数据库的对比
项目 | Hive | 关系型数据库 |
数据存储 | HDFS | 磁盘 |
查询语言 | HQL | SQL |
处理数据规模 | 大 | 小 |
分区 | 支持 | 支持 |
扩展性 | 高 | 非常有限 |
数据写入 | 支持批量导入/单条写入 | 支持批量导入/单条写入 |
索引 | 0.7版本后添加了索引(不怎么使用) | 支持复杂索引 |
执行延迟 | 高 | 低 |
数据加载模式 | 读时模式(快) | 写时模式(慢) |
应用场景 | 海量数据查询 | 实时查询 |
PS:
读时模式: Hive 在加载数据到表中的时候不会校验.
写时模式: mysql 数据库插入数据到表的时候会进行校验.适用场景
Hive只适合用来做海量离线的数据统计分析,也就是数据仓库。
1.2 架构
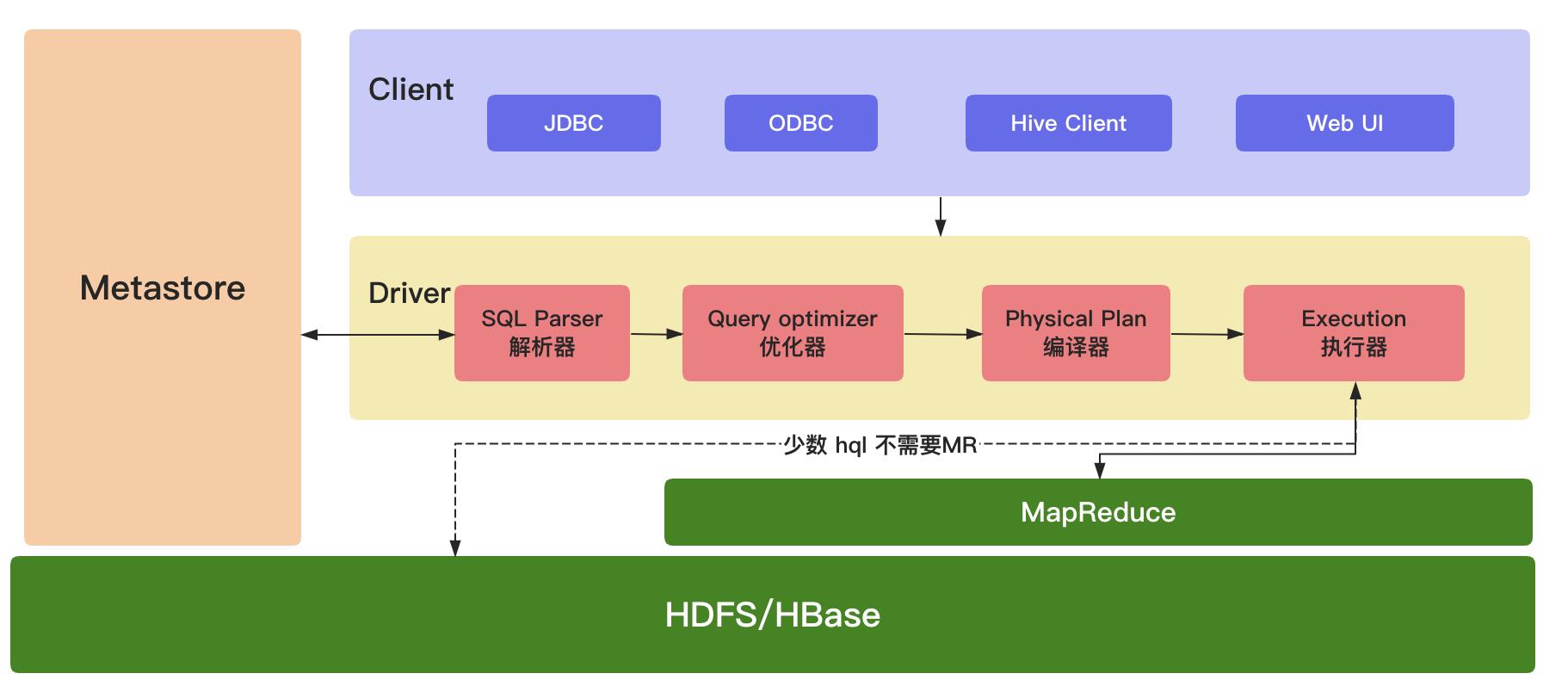
(1)Client(用户接口)
JDBC(java访问Hive);ODBC(Open Database Connectivity);Client(hive shell);WEBUI(浏览器访问Hive)
(2)元数据(MetaStore)
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段,标的类型(表是否为外部表)、表的数据所在目录。这是数据默认存储在Hive自带的derby数据库中,推荐使用MySQL数据库存储MetaStore。
(3)Hadoop/HBase集群
使用 HDFS 进行存储数据,使用 MapReduce 进行计算。
(4)Driver(驱动器)
解析器(SQL Parser):将SQL字符串换成抽象语法树AST,对AST进行语法分析,判断表是否存在、字段是否存在、SQL语义是否有误。
优化器(Query Optimizer):将逻辑计划进行优化。
编译器(Physical Plan):将AST编译成逻辑执行计划。
执行器(Execution):把执行计划转换成可以运行的物理计划。对于Hive来说默认就是Mapreduce任务。PS:从 hive-0.10.x开始,少数 Hql 不需要执行 MR,但是需要开启参数:
hive.fetch.task.conversion = more添参数后,简单的查询,如select,不带count,sum,group by的 SQL,都不走map/reduce,直接读取hdfs文件进行filter过滤。
2.Spark SQL
2.1 基本介绍
概念
Spark SQL主要用于结构型数据处理,它的前身为Shark,在Spark 1.3.0版本后才成长为正式版,可以彻底摆脱之前Shark必须依赖HIVE的局面。与过去的Shark相比,一方面Spark SQL提供了强大的DataFrame API,另一方面则是利用Catalyst优化器,并充分利用了Scala语言的模式匹配与quasiquotes,为Spark提供了更好的查询性能。
在Databricks工程师撰写的论文《Spark SQL: Relational Data Processing in Spark》中,给出了Spark SQL与Shark以及Impala三者间的性能对比,如下图所示:
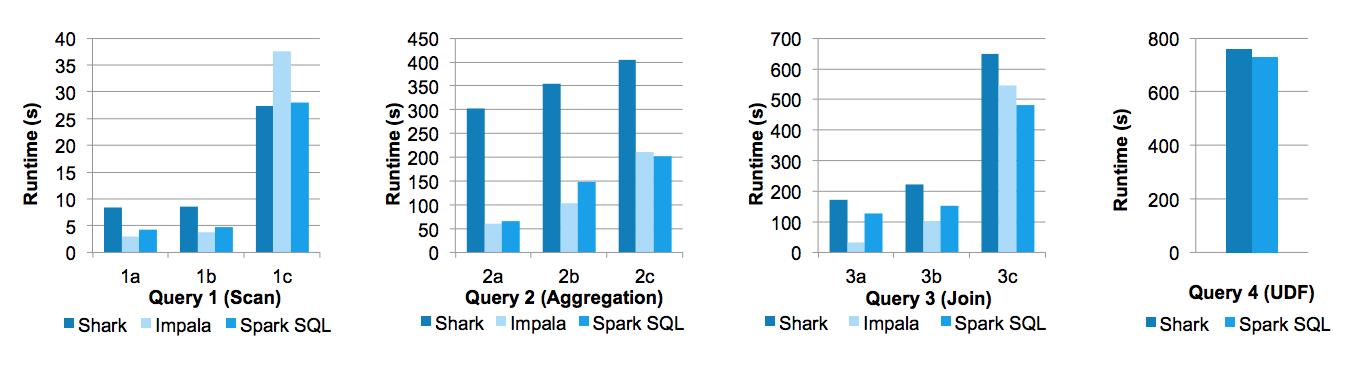
Michael Armbrust、Yin Huai等人写的博客《Deep Dive into Spark SQL’s Catalyst Optimizer》简单介绍了Catalyst的优化机制。
特点
与 Spark 集成
Spark SQL 查询与 Spark 程序集成。Spark SQL 允许我们使用 SQL 或可在 Java、Scala、Python 和 R 中使用的 DataFrame API 查询 Spark 程序中的结构化数据。要运行流式计算,开发人员只需针对 DataFrame / Dataset API 编写批处理计算, Spark 会自动增加计算量,以流式方式运行它。这种强大的设计意味着开发人员不必手动管理状态、故障或保持应用程序与批处理作业同步。相反,流式作业总是在相同数据上给出与批处理作业相同的答案。
统一数据访问
DataFrames 和 SQL 支持访问各种数据源的通用方法,如 Hive、Avro、Parquet、ORC、JSON 和 JDBC。这将连接这些来源的数据。这对于将所有现有用户容纳到 Spark SQL 中非常有帮助。
Hive兼容性
Spark SQL 对当前数据运行未经修改的 Hive 查询。它重写了 Hive 前端和元存储,允许与当前的 Hive 数据、查询和 UDF 完全兼容。
标准连接
连接是通过 JDBC 或 ODBC 进行的。JDBC和 ODBC 是商业智能工具连接的行业规范。
性能和可扩展性
Spark SQL 结合了基于成本的优化器、代码生成和列式存储,在使用 Spark 引擎计算数千个节点的同时使查询变得敏捷,提供完整的中间查询容错。Spark SQL 提供的接口为 Spark 提供了有关数据结构和正在执行的计算的更多信息。在内部,Spark SQL 使用这些额外信息来执行额外优化。Spark SQL 可以直接从多个来源(文件、HDFS、JSON/Parquet 文件、现有 RDD、Hive 等)读取。它确保现有 Hive 查询的快速执行。
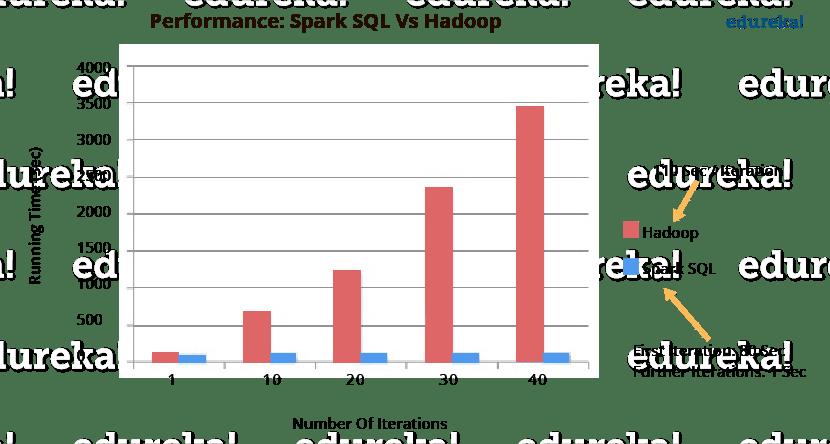
下图描述了 Spark SQL 与 Hadoop 相比的性能。Spark SQL 的执行速度比 Hadoop 快 100 倍。
适用场景
实时计算 & 离线批量计算。
2.2 架构
3.Hive on Spark SQL
3.1基本介绍
Hive on Spark是由Cloudera发起,由Intel、MapR等公司共同参与的开源项目,其目的是把Spark作为Hive的一个计算引擎,将Hive的查询作为Spark的任务提交到Spark集群上进行计算。
通过该项目,可以提高Hive查询的性能,同时为已经部署了Hive或者Spark的用户提供了更加灵活的选择,从而进一步提高Hive和Spark的普及率。
参考:https://www.cnblogs.com/wcwen1990/p/7899530.html
3.2 架构

参考:http://people.csail.mit.edu/matei/papers/2015/sigmod_spark_sql.pdf
4.Hive SQL和 Spark sql 的区别
相同点
都支持ThriftServer服务,为JDBC提供解决方案
都支持静态分区、动态分区
都支持多种文件存储格式:text、parquet、orc等
都支持 UDF 函数不同点
Spark SQL 是 Spark 的一个库文件
Spark SQL 中 schema 是自动推断的
Spark SQL 支持标准 SQL 语句,也支持 HQL 语句等(即支持SQL方式开发,也支持HQL开发,还支持函数式编程(DSL)实现SQL语句)
Spark SQL 支持 Spark Datasets 和 Spark DataFrames 的操作,而 Hive SQL 仅支持 Hive 表的操作。
Spark SQL 支持使用 Spark API 和 SQL 同时进行数据处理,而 Hive SQL 仅支持 SQL 操作。
Hive中必须有元数据,一般由 MySql 管理,必须开启 metastore 服务
Hive 中在建表时必须明确使用 DDL 声明 schema以上是关于Hive进阶-- Hive SQLSpark SQL和 Hive on Spark SQL的主要内容,如果未能解决你的问题,请参考以下文章