Flink学习笔记概述
Posted 缘来如此09
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink学习笔记概述相关的知识,希望对你有一定的参考价值。
一、什么是Flink
1.Flink是一个分布式流处理框架,它能够在大规模的数据流上进行实时计算和批处理。Flink支持丰富的API,包括DataStream API和DataSet API,可以在多种计算场景中使用,例如实时数据处理、批处理、图形计算和机器学习等。Flink还具有高可用性、低延迟、高吞吐量和高扩展性等特点,是近年来非常流行的数据处理框架之一。
二、flink的使用场景有哪些
-
实时数据处理:Flink可用于处理来自各种来源的实时数据,包括传感器、移动设备、日志数据、交易数据等。
-
流式数据分析:Flink能够实时地对数据进行分析和计算,支持各种数据分析算法和模型,包括机器学习、实时推荐等。
-
实时报警和监控:Flink可以实时地对数据进行监控和报警,通过实时分析数据来检测异常和错误,及时采取行动。
-
实时数仓:Flink能够将实时数据转化为有价值的信息,可以将数据流转化为数据仓库,并进行OLAP操作,支持实时报表和可视化分析。
5.金融行业:Flink可用于处理金融交易数据,实现实时交易风险监控、实时交易报告生成等。
6.物联网:Flink可用于处理来自物联网设备的实时数据,支持设备状态监控、实时控制等
三、flink架构分析:
·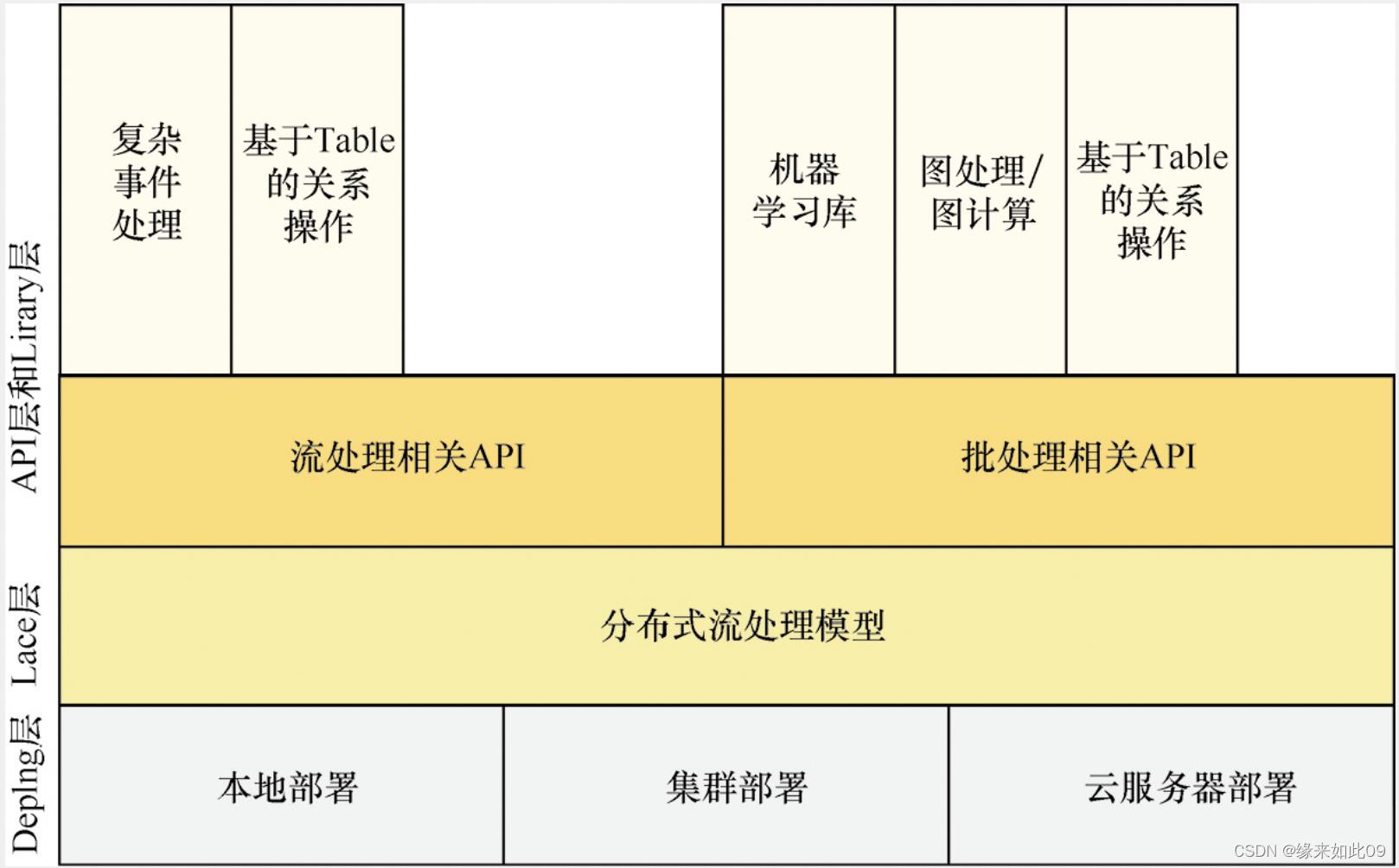
flink分为四层架构,包括:应用层、API层、运行时层和物理层。
-
Deploy层:该层主要涉及Flink的部署模式,Flink支持多种部署模式——本地、集群(Standalone/YARN)和云服务器(GCE/EC2)
-
运行时层(lace):负责执行应用程序,包括任务管理、资源管理、状态管理和容错机制等。
-
API层:提供批处理和流处理的API,包括DataSet API、DataStream API和Table API等。
-
library层:该层也被称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。面向流处理支持CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作);面向批处理支持FlinkML(机器学习库)、Gelly(图处理)、Table 操作。
四、flink的基本组件:
Flink中提供了3个组件,包括DataSource、Transformation和DataSink
1.DataSource:表示数据源组件,主要用来接收数据,目前官网提供了readTextFile、socketTextStream、fromCollection以及一些第三方的Source。
2.Transformation:表示算子,主要用来对数据进行处理,可以将数据流转换成另一个数据流或者聚合成一个数据流,转换算子可以将一个数据流转换成另一个数据流,聚合算子则可以将多个数据流聚合成一个数据流。常用的算子有map、filter、flatMap、keyBy、reduce、window等。这些算子可以被组合在一起形成复杂的数据处理任务
3.DataSink:表示输出组件,主要用来把计算的结果输出到其他存储介质中,比如writeAsText以及Kafka、Redis、Elasticsearch等第三方Sink组件。
因此,想要组装一个Flink Job,至少需要这3个组件。
Flink Job=DataSource+Transformation+DataSin
五、与其他流式计算框架对比:
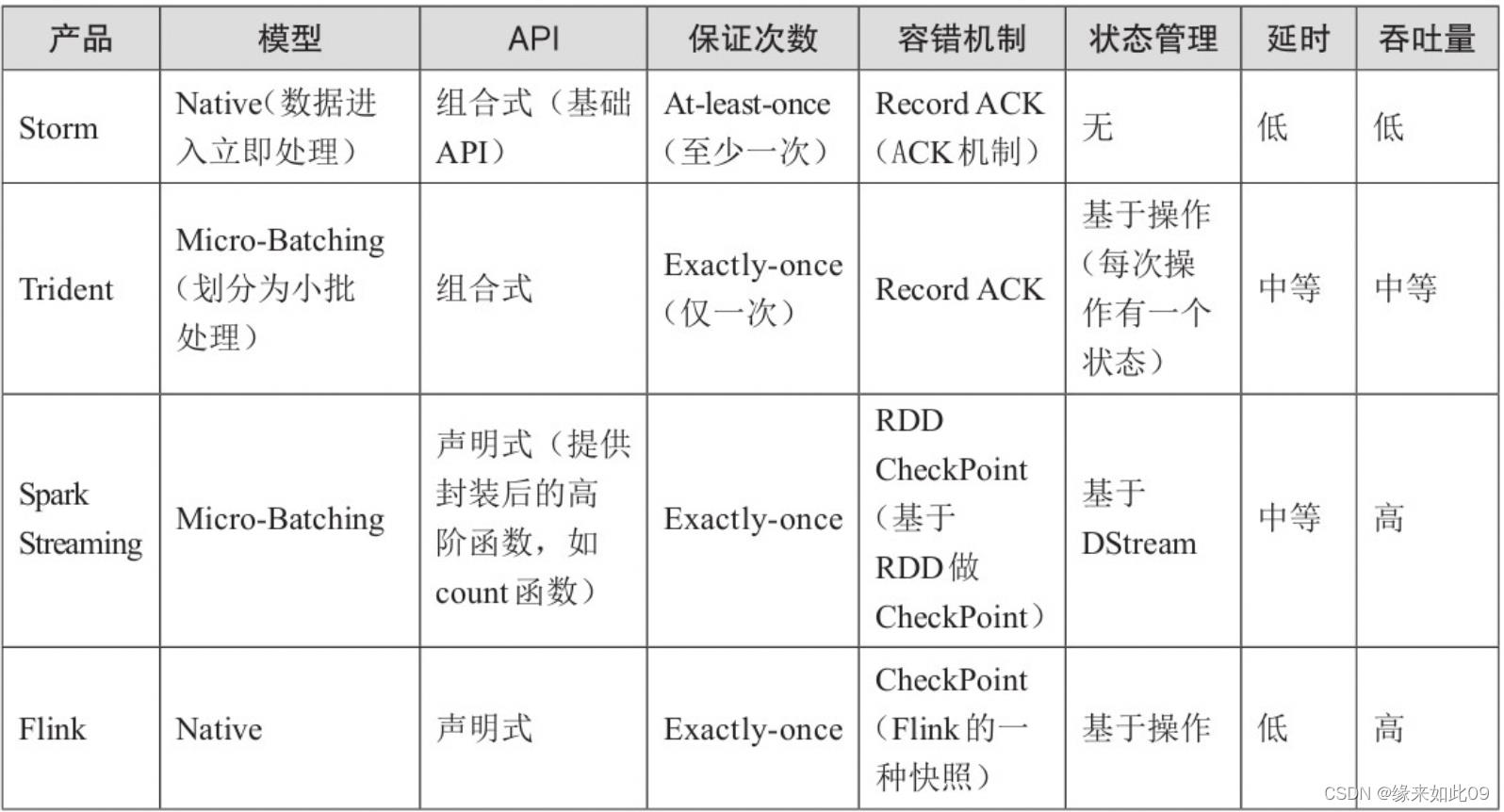 1.Flink的优点:
1.Flink的优点:
1.低延迟和高吞吐量:Flink的批处理和流处理都可以实现低延迟和高吞吐量,而且能够处理大规模数据。
2.内存管理:Flink通过内存管理来优化性能,可以在处理大量数据时减少GC负担。
3.稳定性:Flink的容错机制非常强大,可以处理各种故障和错误。
4.扩展性:Flink可以扩展到数千个节点,以处理大规模数据。
5.丰富的API:Flink提供了丰富的API,包括流处理和批处理API,可以满足各种场景的需求。
2.Flink的缺点:
-
学习曲线较陡峭:Flink相对于其他流式计算框架来说,学习曲线较陡峭,需要花费更多的时间来学习和理解。
-
集群配置较复杂:Flink的集群配置较复杂,需要更多的经验和技术支持。
-
运行环境要求较高:Flink需要较高的硬件要求和运行环境,对于一些小规模的项目来说可能有些过度设计。
3.如何选择实时计算框架
需要关注流数据是否需要进行状态管理,如果是,那么只能在Trident、SparkStreaming和Flink中选择一个。
需要考虑项目对At-least-once(至少一次)或者Exactly-once(仅一次)消息投递模式是否有特殊要求,如果必须要保证仅一次,也不能选择Storm。
对于小型独立的项目,并且需要低延迟的场景,建议使用Storm,这样比较简单。
如果你的项目已经使用了Spark,并且秒级别的实时处理可以满足需求的话,建议使用Spark Streaming
要求消息投递语义为Exactly-once;数据量较大,要求高吞吐低延迟;需要进行状态管理或窗口统计,这时建议使用Flink。
以上是关于Flink学习笔记概述的主要内容,如果未能解决你的问题,请参考以下文章