Zookeeper 集群搭建(使用 docker-compose)及基础操作
Posted JankinWu_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zookeeper 集群搭建(使用 docker-compose)及基础操作相关的知识,希望对你有一定的参考价值。
概念
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
使用 docker-compose 搭建Zookeeper 集群
作为初学者的话没有那么多虚拟机的话,可以使用docker来运行集群。
编写 docker-compose.yml
version: '3.8'
services:
zk1:
image: zookeeper:3.5.7
restart: always
container_name: zk1
hostname: zk1
networks:
- zk-net
ports:
- "2181:2181"
volumes:
- zk1-data:/data
- zk1-log:/datalog
- zk1-conf:/conf
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
zk2:
image: zookeeper:3.5.7
restart: always
container_name: zk2
hostname: zk2
networks:
- zk-net
ports:
- "2182:2181"
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
zk3:
image: zookeeper:3.5.7
restart: always
container_name: zk3
hostname: zk3
networks:
- zk-net
ports:
- "2183:2181"
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
volumes:
zk1-data:
external: false
zk1-log:
external: false
zk1-conf:
external: false
networks:
zk-net:docker-compose 文件解释
- zoo1-data:/data结合下方的zoo1-data:(换行) external: false的意思就是,将/data挂载在zoo1-data上,同时external: false将指定不一定要使用现成的卷(不存在则创建名为project_name_zoo1-data的卷,project_name默认为文件夹名,默认创建位置为/var/lib/docker/volumes此处为zookeeper_zoo1-data)(external: true意思是必须使用现成的卷)。
networks: 指定了网络名,最终的网络名可能为"project_name_network_name",不指定network模式的情况下,默认是bridge模式
ports: p1:p2 指定将宿主机上的p1端口映射到容器的p2端口,映射关系可在docker-compose ps中查看
运行zookeeper集群
# 一定要在与 docker-compose.yml 同级目录下运行命令才可以
docker-compose up -d配置文件解读
进入/var/lib/docker/volumes/zookeeper_zk1-conf/_data文件夹中,使用vim zoo.cfg可以看到配置文件的内容,如下:
dataDir=/data
dataLogDir=/datalog
tickTime=2000
initLimit=5
syncLimit=2
autopurge.snapRetainCount=3
autopurge.purgeInterval=0
maxClientCnxns=60
standaloneEnabled=true
admin.enableServer=true
server.1=zk1:2888:3888;2181
server.2=zk2:2888:3888;2181
server.3=zk3:2888:3888;2181dataDir:保存Zookeeper数据的目录
dataLogDir: 保存Zookeeper日志的目录
tickTime:通信心跳时间
initLimit:Leader 和 Follower 初始连接时能容忍的最多心跳数
syncLimit:Leader和 Follower 同步通信时限,Leader和Follower之间通信时间如果超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer
autopurge.purgeInterval:这个参数指定了清理频率,单位是小时,需要填写一个1或更大的整数,默认是0,表示不开启自己清理功能。
autopurge.snapRetainCount:这个参数和上面的参数搭配使用,这个参数指定了需要保留的文件数目。默认是保留3个。
maxClientCnxns:单个客户端与单台服务器之间的连接数的限制,是ip级别的,默认是60,如果设置为0,那么表明不作任何限制。
standaloneEnabled:standaloneEnabled 默认值 true,可以在独立模式或分布式模式下运行ZooKeeper。这些是独立的实现栈,在运行时在它们之间切换是不可能的。默认情况下(为了向后兼容),standaloneEnabled被设置为true。使用此默认值的结果是,如果以单个服务器启动,那么集合将不允许增长;如果以多个服务器启动,那么集合将不允许收缩,以包含少于两个参与者。
admin.enableServer:是否启用 AdminServer。 默认情况下启用 AdminServer。
server.A=B:C:D;E
A:myid 的值,表示这个是第几号服务器
B:服务器地址,因为都是本地环境搭建的,就是127.0.0.1
C:这个服务器 Follower 与集群中的 Leader 服务器交换信息的端口
D:是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
E:客户端连接端口,通常不做修改。
选举机制
SID:服务器ID。用来唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和myid一致。
ZXID:事务ID。致使ZooKeeper节点状态改变的每一个操作都将使节点接收到一个Zxid格式的时间戳,并且这个时间戳全局有序。也就是说,也就是说,每个对节点的改变都将产生一个唯一的Zxid。如果Zxid1的值小于Zxid2的值,那么Zxid1所对应的事件发生在Zxid2所对应的事件之前。
Epoch:每个Leader任期的代号。没有Leader时同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加
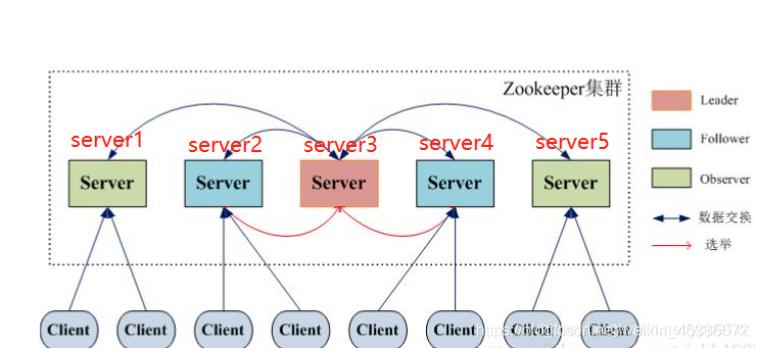
初始化
当启动初始化集群的时候,server1的myid为1,zxid为0 server2的myid为2,zxid同样是0,以此类推。此种情况下zxid都是为0。先比较zxid,再比较myid
服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking(选举状态)。
服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的myid大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的myid最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的myid大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
服务器5启动,后面的逻辑同服务器4成为小弟
当选举机器过半的时候,已经选举出leader后,后面的就跟随已经选出的leader,所以4和5跟随成为leader的server3所以,在初始化的时候,一般到过半的机器数的时候谁的myid最大一般就是leader
非第一次启动
(1) 当zookeeper集群中的一台服务器出现以下两种情况之一时,就会开始进入leader选举:
服务器初始化启动。
服务器运行期间无法和leader保持连接。
(2) 当一台机器进入leader选举流程时,当前集群也可能会处于以下两种状态:
集群中本来就已经存在一个leader。在这种情况下,机器试图去选举leader时,会被告知当前服务器的leader信息,对于该机器来说,仅仅需要和leader机器建立连接,并进行状态同步即可。
集群中确实不存在leader。假设zookeeper由5台服务器组成,SID分别为1、2、3、4、5,ZXID分别为8、8、8、7、7,并且此时SID为3的服务器是leader,某一时刻,3和5服务器出现故障,因此开始进行leader选举。
SID为1、2、4的机器投票情况(epoch,ZXID,SID):(1,8,1)、(1,8,2)、(1,7,4)。
选举leader规则:
1)epoch大的直接胜出。
2)epoch相同,事务id大的胜出。
3)事务id相同,服务器id大的胜出。
Zookeeper 客户端命令
开启一个容器用来访问集群
docker run -it --rm \\
--link zk1:zk1 \\
--link zk2:zk2 \\
--link zk3:zk3 \\
--net zookeeper_zk-net \\
zookeeper:3.5.7 zkCli.sh -server zk1:2181,zk2:2181,zk3:2181注意此处zookeeper_zoo-net的格式为project_name_network_name,project_name 默认为文件夹名,network_name 默认为 docker-compose.yml 中指定的名字。docker-compose 启动集群时会为其分配专门的网络,可在docker network ls中查看。
命令行语法
# 显示所有操作命令
help
# 客户端断开连接
quit
# 查看子节点
# 比如 ls / 表示查看根节点下的子节点
ls 父节点全路径或相对路径
# 创建子节点(默认是持久化节点)
# 比如 create /jobs 表示在 / 下创建 jobs 子节点
# 可以给节点存储数据,也可以不存储数据
# 比如 create /jobs perfect 表示在 / 下创建 jobs 子节点并存储的数据为 perfect
create 子节点全路径或相对路径 [数据内容]
# 获取节点的数据
# 比如 get /jobs 表示获取 jobs 节点中存储的数据,应该会获取到 perfect
get 节点全路径或相对路径
# 设置或修改节点的数据值
# 比如 set /jobs greate 表示将 jobs 节点的数据设置为 greate
set 节点全路径或相对路径 [数据内容]
# 删除单个节点
# 比如 delete /test 表示删除 / 下面的 test 节点
# 但是如果 test 节点下面有子节点的话,该命令就无法删除 test 节点了
delete 节点全路径或相对路径
# 删除单个节点及其下面的所有包含的节点
# 比如 deleteall /test 表示删除 / 下面的 test 以及 test 下的所有节点
deleteall 节点全路径或相对路径
# 创建临时节点,增加 -e 参数
# 当客户端断开与 zookeeper 的拦截后,所创建的临时节点会自动被删除掉
create -e 子节点全路径或相对路径 [数据内容]
# 创建顺序节点,增加 -s 参数
# 创建的节点名称,会自动被添加上数字编号
# 比如多次运行 create -s /aaa 后,通过 ls / 查看 / 下面的子节点列表
# 会发现类似 /aaa0000000001 /aaa0000000002 /aaa0000000003 的顺序节点
create -s 子节点全路径或相对路径 [数据内容]
# 创建临时顺序节点,增加 -es 参数
# 临时顺序节点,兼有临时节点和顺序节点的特性,常用于分布式所的应用场景
create -es 子节点全路径或相对路径 [数据内容]
# 查看一个节点的详细信息
ls -s 节点全路径或相对路径
# 获取到的内容如下:
# czxid:节点被创建的事务ID
# ctime:节点的创建时间
# mzxid:最后一次被更新的事务ID
# mtime:节点的修改时间
# pzxid:子节点列表最后一次被更新的事务ID
# cversion:子节点的版本号
# dataversion:数据版本号
# aclversion:权限版本号
# ephemeralOwner:用于临时节点,表示临时节点的事务ID
# dataLength:节点存储的数据的长度
# numChildren:当前节点的子节点个数节点类型
PERSISTENT 持久化目录节点:客户端与zookeeper断开连接后,该节点依旧存在,只要不手动删除该节点,他将永远存在
PERSISTENT_SEQUENTIAL 持久化顺序编号目录节点:客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
EPHEMERAL 临时目录节点:客户端与zookeeper断开连接后,该节点被删除
EPHEMERAL_SEQUENTIAL 临时顺序编号目录节点:客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
Container 节点:3.5.3 版本新增,如果Container节点下面没有子节点,则Container节点 在未来会被Zookeeper自动清除,定时任务默认60s 检查一次
TTL 节点:默认禁用,只能通过系统配置 zookeeper.extendedTypesEnabled=true 开启,不稳定。
以上是关于Zookeeper 集群搭建(使用 docker-compose)及基础操作的主要内容,如果未能解决你的问题,请参考以下文章
使用 Docker 一步搞定 ZooKeeper 集群的搭建